
贝壳找房DBA团队,负责链家、贝壳找房的数据库服务治理及运维,包括MySQL、Redis、Kafka、RocketMQ、TiDB等产品。为保证线上服务高效、安全、稳定运行,面向研发同学提供一站式的数据库操作平台,建设了满足99.99%标准的高可用自动化切换平台,并结合DBA丰富的运维经验和机器学习算法实现了数据库故障的自助诊断。
引言
2021 年 9 月 1 日起《中华人民共和国数据安全法》(以下简称《安全法》)正式施行,成为了规范数据处理活动,保障数据安全,促进数据开发利用,保护个人、组织的合法权益,维护国家主权、安全和发展利益的法律依据。数据脱敏技术则是对敏感数据按需进行漂白、变形、遮盖等处理,避免敏感信息泄露。数据脱敏工具使用、开发、平台建设是每家互联网公司保护用户隐私应尽的义务。
贝壳在用户隐私数据保护上也做了很多努力,严格遵守国家法律要求,本文将分享一款由贝壳 DBA 团队开发的数据脱敏工具,即 d18n,它是 data-desensitization 的 Numeronym 缩写,即使用 18 代替中间的 18 个字母。下面将拆解 d18n 的技术实现,让大家了解数据安全背后的故事。
一、数据脱敏场景

从上图可见敏感信息脱敏其实已经融入到生活的方方面面,我们看的电影,读的小说,听的新闻都会用到信息脱敏。以下列举三个互联网公司常见的三种数据脱敏场景。
线上数据库服务做了严格的权限控制和资源隔离,非授权用户无法获取任何数据。测试环境为了尽量仿真生产环境有时会提出使用获取线上数据样本的需求,但测试环境的权限控制相对较宽松,因此不可将未脱敏的数据直接导入测试环境。
随着大数据应用在互联网的不断落地,大数据分析能够辅助公司进行产品决策,准确分析用户行为。直接使用生产数据进行数据分析,未经管控和数据脱敏,敏感数据泄露的风险的几率将大大增加。
政府与企业,企业与企业,企业内应用与应用之间都有数据交换和信息共享的需求。针对不同级别的数据共享需求,要制定不同的数据脱敏方案。在保护好公司核心数据资产的情况下,为政企合作、企业合作、服务迭代提供数据安全保障。
二、跨平台数据脱敏

d18n 工具使用 Go 语言开发,在设计选型时它特意避开了部分依赖 CGO 的数据库驱动,因此它是完全跨平台的,可以直接在 Windows、Linux、Mac 系统中使用,即使是最新的 Apple Silicon MacBook Pro 也可功能无损支持。
由于 d18n 开发时 Go 1.16 已经支持了 embed 功能,它原生支持将静态资源与二进制程序一起打包。在数据脱敏和敏感信息识别时需要使用的语料包已经被 d18n 打包封装好了,因此无需再下载任何其他静态资源文件,真正做到开箱即用。这一点对于目前流行的容器化环境来说也是特别友好的。
d18n 的跨平台不仅体现在操作系统级别的跨平台上,它对数据库平台的支持也是多样化的。除了互联网公司最常使用的 MySQL 数据库,d18n 还支持 Oracle、SQL Server、PostgreSQL 等等多种关系型数据库。可以说,只要是使用 SQL 语言的数据库,只要它有 Pure Go 驱动,d18n 都能支持。很多同学甚至直接把 d18n 当作一个简单的数据库命令行查询工具使用,带来跨平台一致性的用户体验。
d18n 支持导出、导入的文件类型相对也比较丰富,有绝大多数人都熟悉的 Excel, TXT,也有对应用程序友好的 CSV、JSON、SQL、HTML 等文件格式。无论是交给人用肉眼阅读,还是交给程序做自动化处理,d18n 都应付得来。
三、敏感数据识别
前面讲了很关于多跨平台的友好性,一款数据脱敏工具用户真正看重的是它对敏感数据的识别和处理能力上,这一节开始将进入硬核知识介绍。
关系型数据库敏感数据识别常用的算法有“关键字匹配”和“正则匹配”。d18n 当然也不能免于俗套,这两项技术也是妥妥的支持。更有诚意的是,d18n 还一并提供了敏感信息识别使用的通用规则库。对于想“偷懒”的同学,它能让你开箱即用;对于“勤奋”的同学,你也可以参照模板进行深度自定义且无需修改源码。
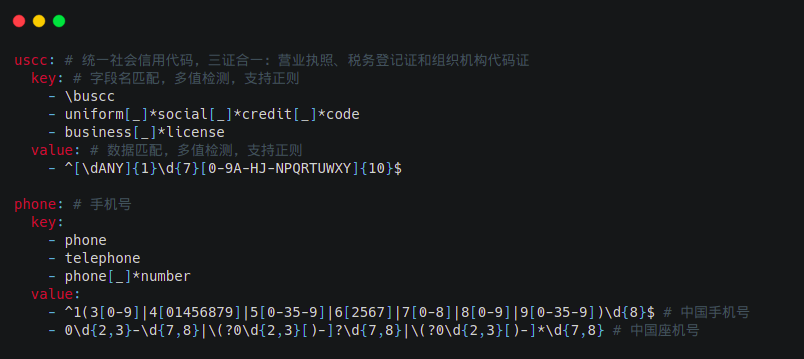
在传统技术基础之上,为了进一步提高敏感数据发现能力,d18n 还引入了自然语言处理包 (gse),它将语料库转化成 Trier 数据结构,通过有穷自动机算法 (DFA) 来匹配经过自动分词的数据。
自然语言处理识别敏感数据的核心难点是如何生成精准有效的语料库,一个有效语料库通常是针对真实的数据集进行机器学习训练得到的。d18n 中提供的关于地址、姓名的语料库模板并非真实数据训练得到仅供用户参考。下面是 d18n 中应用自然语言处理来识别敏感信息的测试用例。

敏感信息存储主动申报已经深深的融入到了贝壳的各项流程制度中,机器识别做为一个有效的补充可以帮助业务查缺补漏,及时发现可能存在的隐患。
四、数据脱敏导出
有了全平台的敏感数据信息,接下来就是如何做好数据脱敏工作,综合整理法律合规以及来自不同业务方的需求,主要有以下几点。
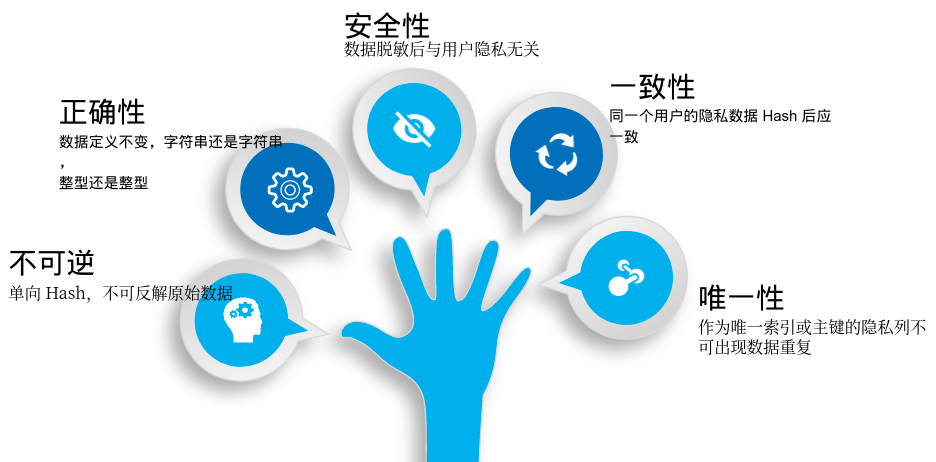
为了满足上面五点需求,本文从六个维度出发(即:无效化、随机化、数据替换、加密替换、差分隐私、偏移取整)分别介绍数据脱敏算法实现。
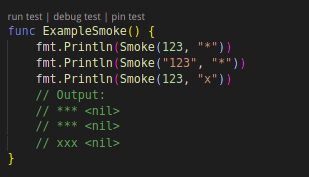
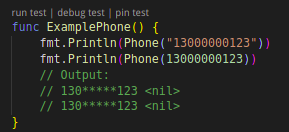
首先是“无效化”,在处理待脱敏的数据时,通过对字段数据值进行截断、加密、隐藏等方式让敏感数据脱敏,使其不再具有利用价值。一般采用特殊字符(*等)代替真值。以下是 d18n 中 smoke 和 phone 两个算法的测试用例展示。
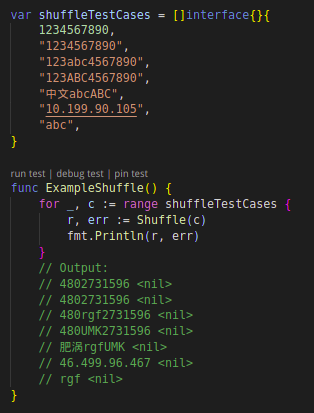
其次是“随机化”,随机值替换,字母变为随机字母,数字变为随机数字,这种方案可以在一定程度上保留原有数据的格式,且不可打破数据的唯一性约束。d18n 中内置了常用汉字的语料库,中文默认也可以做随机化替换。
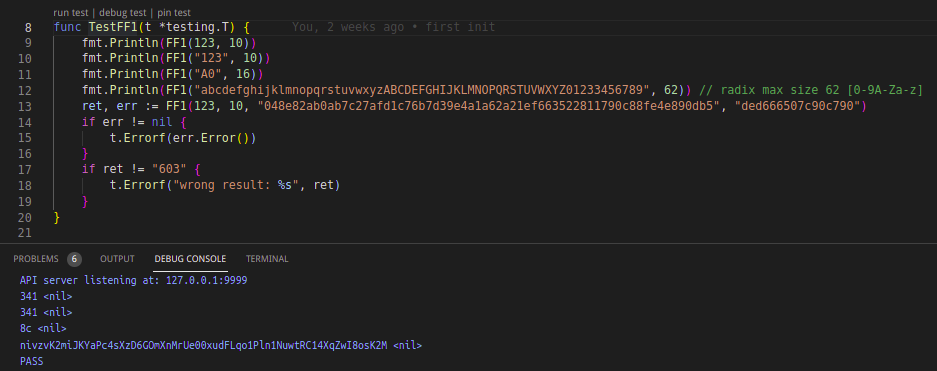
对于 ASCII 码表中的字符,d18n 还集成了先进的 FPE(Format Preserving Encryption) 算法,进一步保证了数据的“不可逆”性。
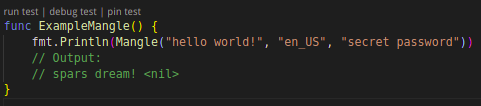
除了单个字符的随机化,d18n 还支持单词级别的随机化替换,可保持语句长度及标点符号不变。根据用户生成的语料库不同,支持不同语言的单词替换。下面是一个英文替换的例子。
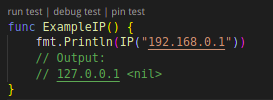
第三是“数据替换”,数据替换与“无效化”方式比较相似,不同的是这里不以特殊字符进行遮挡,而是用一个设定的虚拟值替换真值。比如说将 IP 统一设置成 “127.0.0.1”。
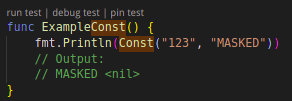
第四是“加密替换”,d18n 支持对称加密算法和非对称加密算法。数据加密是一种特殊的可逆脱敏方法,通过密钥和算法对敏感数据进行加密,已知密钥和算法可解密恢复原始数据,要注意密钥的安全性。虽然 d18n 也支持 RSA,ECC 等数据加密算法,但 d18n 不会生成密钥文件、也不保留加密密钥,更不提供解密支持。

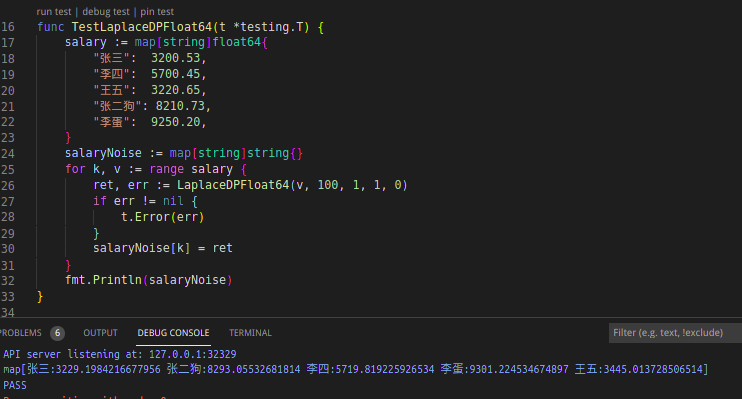
第五是“差分隐私”,它是密码学中的词汇,旨在提供一种当从统计数据库查询时,最大化数据查询的准确性,同时最大限度减少识别其记录的机会。d18n 使用了 Google 开源的 github.com/google/differential-privacy 包实现了这部分能力。
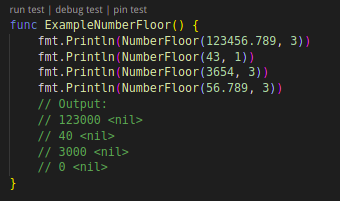
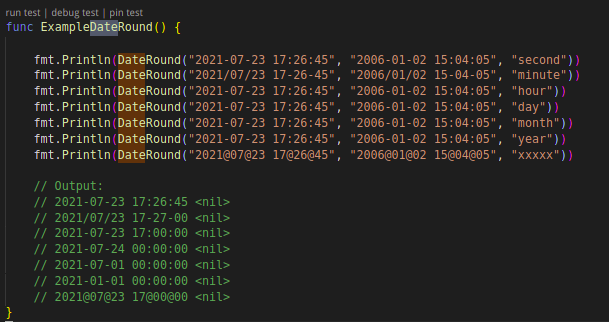
第六是“偏移取整”,这种方式通过数据移位去除隐私信息,偏移取整在保持了数据的安全性的同时保证了范围的大致真实性,比之前几种方案更接近真实数据。下面两个例子分别是对数值类型取整和对时间类型取整。
五、数据脱敏导入
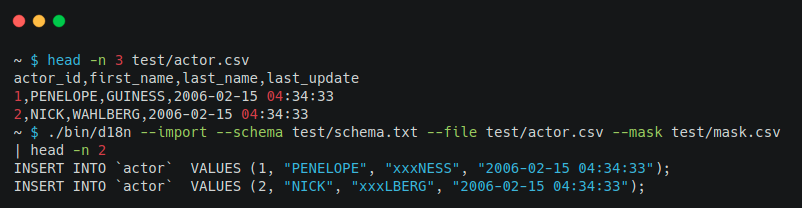
至此仅实现了把数据库中的数据脱敏后共享给使用方的需求,如果有同学给了一份未脱敏的数据文件让你导入到测试环境呢?d18n 也支持对 Excel、TXT、CSV、HTML、JSON 等格式的文件进行二次脱敏生成 SQL,可生成 SQL 文件,也可直接连接数据库导入至数据库中查看。
总结
d18n 中引入了很多优秀的第三方开源 Library,它虽然是一个命令行工具,但作者们更想把它作为一个 Library 来开发,这样可以更好的回馈给开源社区,也给 d18n 带来更多的可能。命令行工具提供的是静态数据脱敏能力,可以用于日常学习、测试。基于 d18n 这个 Library 相信你也不难实现适用各家公司自己的动态数据脱敏平台。保护用户隐私数据每一个人都责无旁贷,期待社区能够涌现更多优秀的产品共同提高数据安全水平。
开源地址
【项目文档】https://github.com/LianjiaTech/d18n/blob/main/doc/toc.md
【Github地址】https://github.com/LianjiaTech/d18n
【Issue 反馈】https://github.com/LianjiaTech/d18n/issues
参考文章
大厂也在用的 6 种数据脱敏方案,严防泄露数据的 “内鬼”
https://www.cnblogs.com/chengxy-nds/p/14107671.html
科普|静态数据脱敏应用场景
https://www.freebuf.com/company-information/235082.html








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721