

现在的互联网领域张口机器学习,闭口神经网络,三句不离深度学习(Oh,oh,oh!AI、DeepLearning更容易把人唬住),外行人或甚至干了十多年的资深开发人员都会觉得触不可及,可能的原因大概是对人工智能认知的问题,大部分人都以为人工智能是指计算机真的像科幻片似的具有了像人类一样的思维意识,其实不然,而且永远也不会实现。读完本文对人工智能误解就会得到释疑。事实上,人工智能都是传统的IT技术,只是大家都不愿意戳穿这薄薄的一层纸,公司需要这个噱头争取补助资金,员工需要这个噱头拿到高工资,正所谓“江湖千金诀,点破不值钱”。
一、前言
依稀记得,鄙人2010刚从学校毕业时,当时物联网之火烧得直冲云宵,大学的教师、教授,一夜之间全部都成了物联网专家。良知和对科学态度的坚贞,鄙人实在不敢苟同这种风气。今天这种现像再次上演,教授、导师、硕士、博士的简历上几乎被深度学习的字样占据一空,像计算机、软件、数学等专业,至少可以胡拉硬扯地沾个边连,但机械专业、化学专业、医学专业的人都能瞬间变成人工智能的专家,鄙人实在佩服地无话可说。”
某度公司,天天高举“All in AI”的大旗,号称无人驾驶汽车5年内可上路,事实是深度学习大牛陆奇从“某度公司”离职时,强烈批判了“某度公司”只有口号,没有任何实质性的东西。依鄙人掌握的信息,最看重AI的科技巨头苹果公司早已完全裁撤了整个无人驾驶团队。
鄙人拙见,无人机有今天的成功是因为在天上,天上没有人,不会出事故,而无人驾驶汽车30年内不可能上路,因为路上到处都是人和车,系统稍有偏差就有可能发生重大交通事故。高举AI大旗无非是为了巨额的扶持资金。从交大“汉芯事件”,到南阳加水就能跑的“氢能神车”,难道我国人真的没学过初中物理?
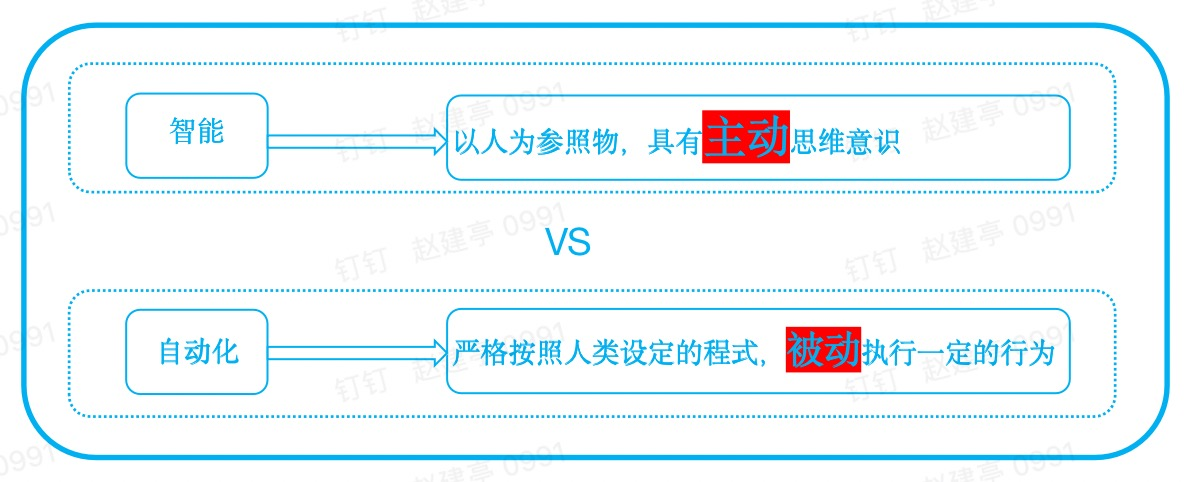
二、智能和自动化的区别
智能和自动化有着本质的区别,人类是目前唯一的智慧生物。人类之所以是智能的,是因为人类所有的行为都是主动的选择的,即人类具有主动思维意识。而计算机所有的行为都是严格按照人类设定的程式,被动的执行一定的行为,都属于自动化。
三、机器学习
1)穷举
言归正传,现在开始讲解机器学习、神经网络、深度学习到底是什么神秘的东东。
机器学习是指机器具有自动学习知识进化的能力,神经网络、深度学习、人工智能都是机器学习的分支,只是采用的手段不同而已。那么到底什么是机器学习呢?如果点破这层薄薄的面纱,机器学习的本质是穷举。请看下面的文氏图:

正所谓:尺有所短,寸有所长。计算机的根本功能就是计算、也只能计算,无论图像、音频播放、视频播放、游戏等,都是一次又不一地执行简单的算术命令。对人类来说,识别一张图片的物体非常容易,但对计算机来说是非常困难的,但是如果要计算11223496448484884 * 89753939393968的结果,对人类来说并非易事,但对计算机来说非常简单。如何让计算机识别图片这类问题,就是人工智能所探讨的核心难题。
2)线性回归
现在我们来看下机器学习最经典的算法之一:线性回归(也称为预测机),通过本例就可以了解机器学习的本质。我们要解决,输入平方米输出亩:
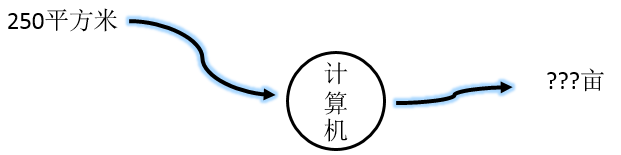
假设,我们只知道两者之间是线性关系,不知道平方米和亩的计算公式。这个问题本质就变为了求解线性方程的系数C问题:Y=CX,X是我们的输入,Y是输出。如果没有其它资料,是无法求解出参数C的,怎么办呢?我们去找一些正确的 平方米/亩 的示例:
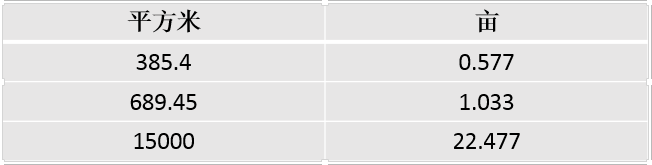
现在假设C=0.6,然后让计算机去式:
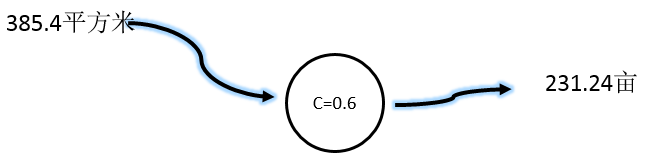
计算机给出的答案(我们称为预测值)是:231.24亩,真实答案是:0.577。预测值比真实值大多了。预测值与真实值的差值,我们称为误差即:
误差值 = 真实值 - 预测值 = 0.577 - 231.24 = -230.663
我们知道,C值取取得大了,现在把C值减小取C=0.05 ,并换一个输入值:
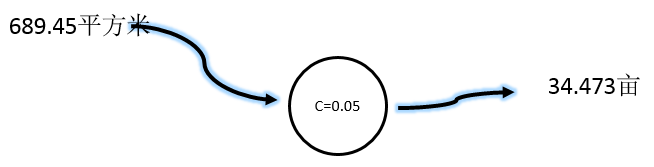
误差值 = 1.033 - 34.473 = -33.44
预测值还是大了,但误差更小了,继续减小C值,取C=0.0018:
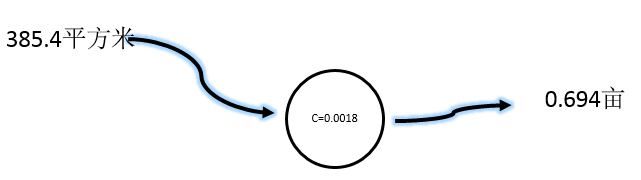
误差值 = 0.577 - 0.694 = -0.117
已经非常接近真实值了,如果继续微调,就可以无限接近真实值,虽然一般无法求得最优解,但现实中只是误差可以接受就可以了。通过现有的数据或资料,称为样本,通过尝试求解参数(局部最优解)的过程,就是机器学习的核心内容。误差值是用来控制每次调整参数的幅度。
上述线性回归解决的是线性问题,但有些问题是非线性的,例如要下图中的黑点和红点分开,是找不到这样的一条直线的,但两条直线就可以,这就启示我们可以用多个分类器一起工作:

1)神经元
如果初中生物没忘完,我们知道人类的大脑是由无数个神经元协同工作的,人类的神经元是将电信号从一端传输到另一端,沿着轴突,将电信号从树突传到树突。然后,这些信号从一个神经元传递到另一个神经元。这就是我们人类感知光、声、热等信号的机制。一般认为,人类大脑有1000亿个神经元。人类的神经元结构如下:
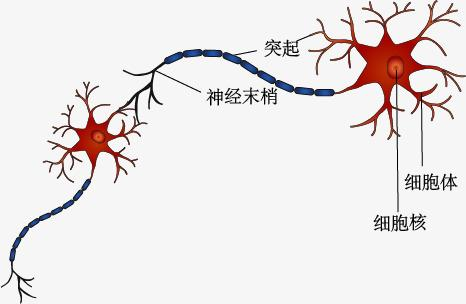
受此启发,计算机学家们认为线性回归分类器就是一个神经元,那么多个分类器一起工作就模拟了人类的神经系统,也就可以解决非线性问题了,这就是神经网络的核心概念。我们知道,神经元接受大信号后不会立即反应而是抑制输放,直到信号强度达到一个阈值,才会产生输出,激活函数就是为了模仿神经元的这个功能。下图是神经网络中的神经元,称之为节点。

2)激活函数
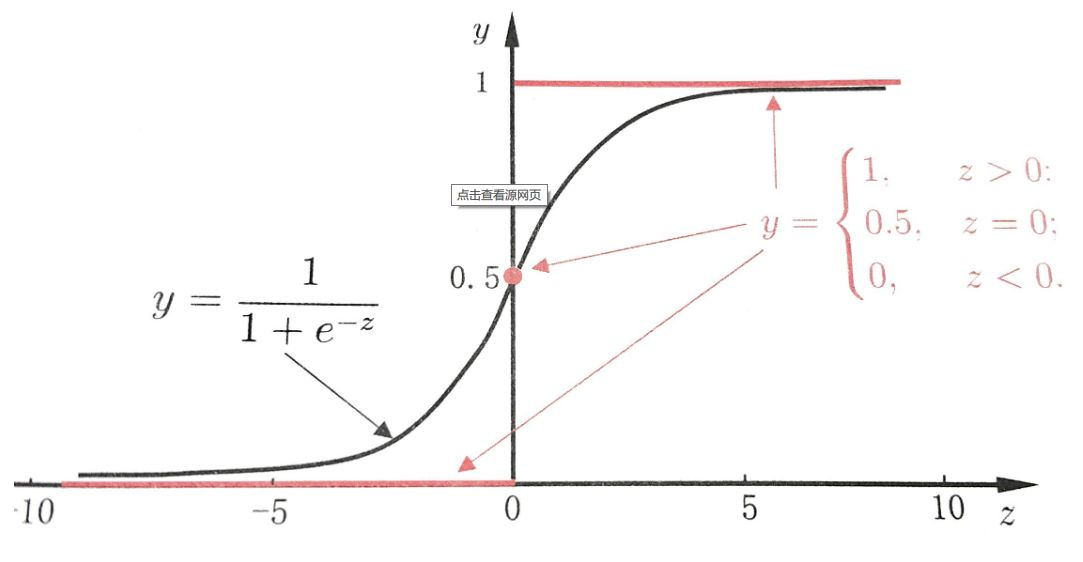
神经元可以接受多个输入,然后对它们相加,作为激活函数的输入,激活函数最后给出输出。这就是神经网络的核心神经元的主要原理。激活函数现在有好多个,我们采用S函数,图像如下:
3)神经网络结构
神经网络结构如下:
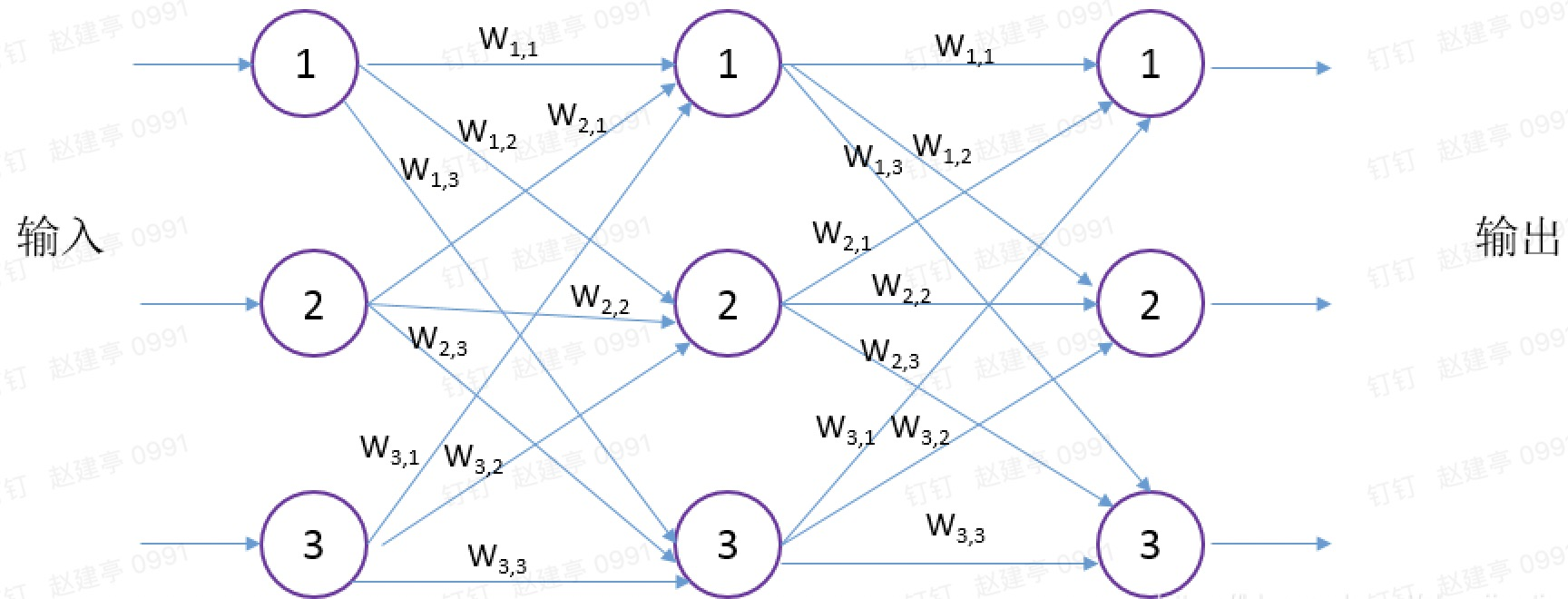
上图就是一个三层神经网络,每层包括三个神经元,神经网络就是由分成多层的多个神经元组成。每个层中的每个神经元都与其前后层的神经元互连,这种网络结构称全连接神经网络,这是经典的神经网络。当然后面又了出现了卷积神经网络,也就是吹得神乎其神的深度学习,下面会作讲解。神经网络中间层,上一层输出就是下一层的输入,第一层的输入是原始输入,最后一层的输出就是最终结果。每个神经元的间的连接都有都有一个权重Wm,n较大的权重给加大输入,较小的会弱化输入。
4)神经网络的计算过程
开始的时候,随机生成参数Wm,n,然后根据样本数据,计算样本真实值和预测值的误差值,调整Wm,n,多次以后就可以找到误差可以接受的局部最优解,这就是神经网络的本质,与传统的机器学习,像线性回归之类的算法并无本质区别。下图展示了三层神网络的计算过程,每层的输入和输出结果:

现在我们来讲解整个计算过程。输入、参数、输出,我们均用矩阵表示,为什么在此处可以应用矩阵运算,其实纯属巧合,因为输入、参数、输出刚好符合矩阵的运算规律而已,其它的说法都是扯蛋。假设入输入为:
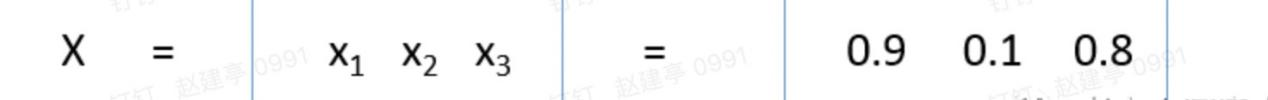
也就是第一层第一个节点输放为0.9,第一层第二个节点输放为0.1,第一层第三个节点输放为0.8
刚开始随机生成,第一层和第二层的连接权重为0.9,也就是第一层第一个节点和第二层第二个节点连连权重为0.9,其它同理,第一层参数矩阵:

第二层和第三层的连接权重为:

最后的输出为:
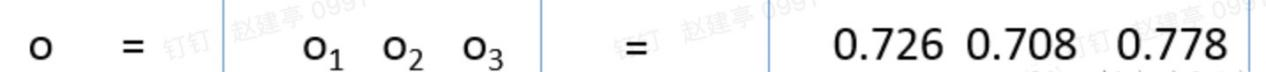
下面我们来分析下0.726是怎么计算出来的。下面再看下带权重的神经元结构:
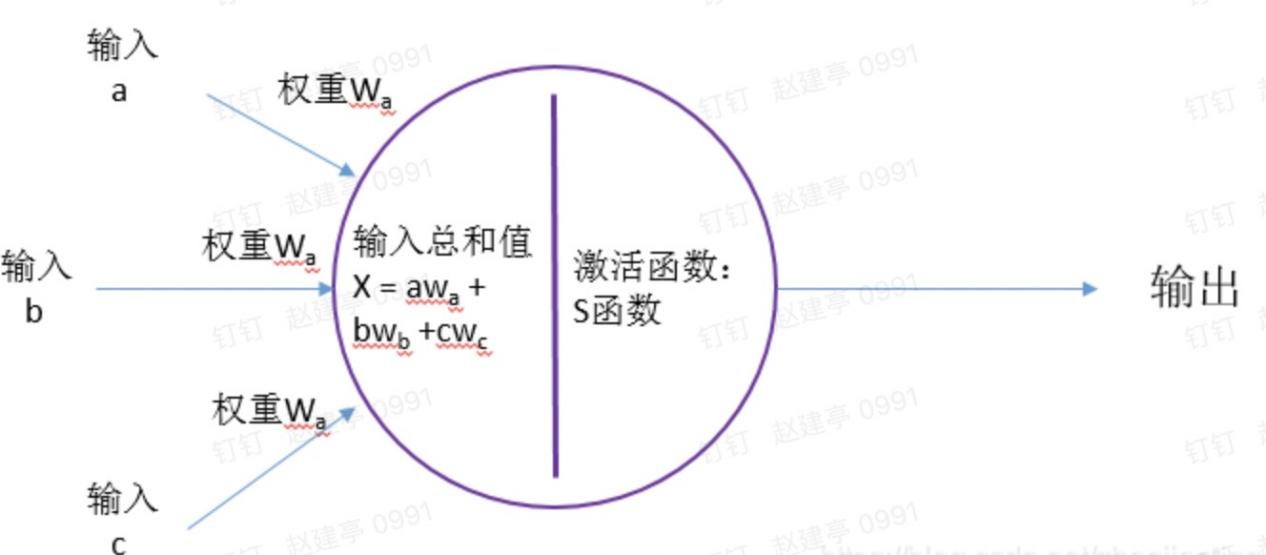
这是a=0.9,b=0.1,c=0.8,Wa=0.9,Wb=0.3,Wc=0.4,也就是x=0.90.9+0.10.3+0.8*0.4=1.16,然后应用激活函数S,即y=S(X)=1/(1+exp(-1.16)) = 0.761,同理可计算第二层其它两个节点的输出,最后第二层的输放为:OH=

第三层的输放计算方法和上面第二层的是一样的。下面看下应用矩阵的计算公式,我们分析下隐藏层和输出层各们结果的计算结果正好符合下面的矩阵乘法公式(真是无巧不成书,科学就是在巧合中一步步前进),矩阵乘法完成后,然后对每一个元素应用激活函数即可:
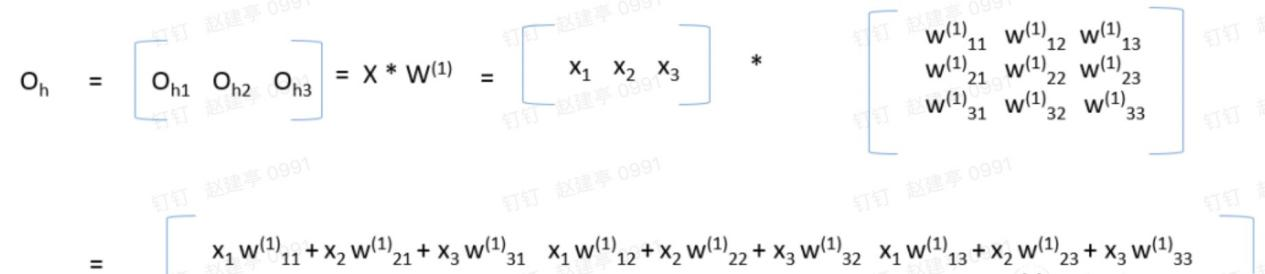
第三层的输出也是同样的道理,第三层的输入为隐藏层的输出,矩阵乘法完成后,再对每一个元素应用激活函数即可:
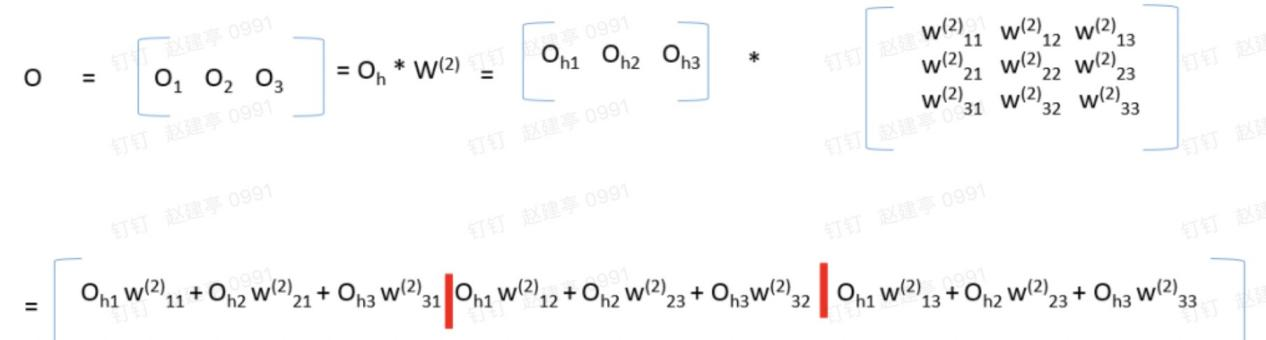
第一层称为输入层,最后一层称为输出层,中间层统称为隐藏层,无论神经网络有多少层,计算方法和上面介绍的是一样的。一开始随机得到w权重矩阵,最后根据样本一步步优化w权重矩阵。下面给出Python的代码:
import numpy# python中sigmoid函数是 scipy.special.expitimport scipy.special#三层神经网络结构定义class neuralNetwork:# 初始化函数,#inputnodes输入层节点数目#hiddennodes隐藏层节点数目#outputnodes输出层节点数目#learningrate学习率,在训练时会用到,关于学习率的设置后面的文章再讨论def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):self.inodes = inputnodesself.hnodes = hiddennodesself.onodes = outputnodes# wih代表输入层和隐藏层间的连接矩阵# who代表隐藏层和输出层间的连接矩阵#权重矩阵一般随机得到,但不要初始化为0和相同的值,具体的初始化方法后面会讨论self.wih = numpy.random.normal(0.0, pow(self.inodes, -0.5), (self.hnodes, self.inodes))self.who = numpy.random.normal(0.0, pow(self.hnodes, -0.5), (self.onodes, self.hnodes))self.lr = learningrate# 激活函数y=1/(1+exp(-x))self.activation_function = lambda x: scipy.special.expit(x)pass# 查询函数,也就是由输入给出输出#input_list是输入层的矩阵,注意格式和维度要正确def query(self, inputs):# 输入有#下面两行是计算隐藏层的输出hidden_inputs = numpy.dot(inputs, self.wih)hidden_outputs = self.activation_function(hidden_inputs)#下面两行是计算最后的输出final_inputs = numpy.dot(hidden_outputs, self.who)final_outputs = self.activation_function(final_inputs)return final_outputs
深度学习的深指的就是神经网络的层数,所以深度学习就是深层神经网络,一般3层以上就称为深度学习。目前深度学习只在图像识别领域得到有限的应用(看清楚是有限),凡是鼓吹自动驾驶、语音识别、自然语言处理等纯属扯蛋,目前这些领域都是以规则为主。深度学习之所以在图像识别领域得到应用,也是纯属巧合,而且卷积运算应用于图像领域是很早之前的事了(以前是人工来计算),只是现在变成计算机来运算了。
卷积运算最早是应用了信号领域,在图像领域的运算并不是严格的卷积运算,而是矩阵的点积,通过下面一张动图来形像理解卷积运算的过程:
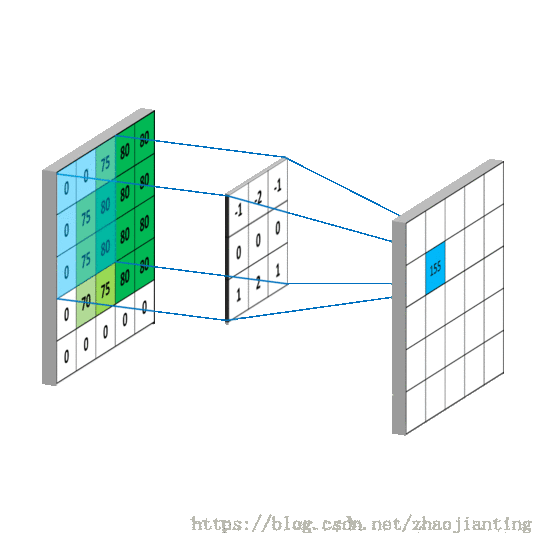
上面动图应用于图像的效果如下:

目的是把不重要像素弱化,像背景,重要的像素部分加深,主要是轮廓。这就是神乎其神的深度学习、AI、DL、图像识别。现在你应该更能理解为什么深度学习目前只适合图像识别,因为图像本身就是一个像素矩阵,运用卷积运算后,刚好可以提取图片的主要特征。目前火热的人工智能其实就是指图像识别。
四、小结
现在的人工智能都是严格按照人类所设定的程序来执行的,没有任何的思维能力,甚至没有主动能力,它永远也不可能形成自我意识。所谓的“计算机的意识”其实就是反复地尝试、自己调整参数而已,它仍然是在做加法。通过这节课大家应该都明白了:其实根本没有智能,都是自动化,现在没有,以后也不会有。
获取本期PPT,请添加群秘微信号:dbachen
↓点这里可回看本期直播
阅读原文








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721