

引擎体验期:伴随业务快速发展,引擎的选择、版本的选择,机型的选择、部署架构的设计,复盘来看是早期稳定性工作的关键抓手。
引擎发展期:随着引擎用户规模的增长,日常运营过程中的问题答疑、最佳实践落地、线上问题诊断消耗团队60%+的精力,亟需大数据PaaS层建设,降低用户引擎技术学习、应用、运维门槛,提升用户自助服务能力。
引擎突破期:随着集群规模的膨胀、业务场景的多元,势必触碰开源引擎的能力边界,亟需构建基于开源引擎的内部迭代机制,既需要与开源社区紧密协同,平滑版本升级,享受社区的技术红利,又需要在开源引擎的基础上进行BUG FIX与企业特性增强。
引擎治理期:随着PaaS平台的构建,引擎版本的快速迭代,会衍生三大类问题:未区分SLA场景的混用、超出引擎能力边界的误用、没有成本意识的滥用。导致引擎服务口碑低、资源(机器+人力)ROI业务价值低,亟需基于元数据驱动的引擎治理体系建设。
解决特定技术问题的开源引擎众多,比如消息队列有Kafka、Pulsar、RocketMQ等,技术选型对于服务的SLA、运维保障至关重要,严重影响幸福感与价值感。
1)引擎选择
要综合考虑社区的Star数、Contributor数,国内是否有PMC或Committer;应用的广泛度,有无众多大厂生产实践背书,线下Meetup是否频繁,线上问题答疑响应速度,线上最佳实践资料是否丰富,部署架构是否放精简等多种因素。
2)机型选择
业务从应用场景上可以分为IOPS场景与TPS场景,开源引擎可以分为CPU密集型、IO密集型、混合型。以分布式搜索引擎Elasticsearch为例,企业级搜索场景,随机IO频繁,对磁盘的IOPS能力要求高,SSD磁盘是刚需;CPU消耗需要根据查询复杂度、QPS来评估此业务场景对CPU的诉求;推荐的做法是模拟业务场景做BenchMark,摸底引擎在特定场景下的性能表现,为机型选择提供依据,下图是滴滴Elasticsearch引擎在做机型选择时的压测验证:

基于引擎原理与业内最佳实践建议,结合应用场景与压测结果,根据当下可选机型做选择,理想状态是CPU、磁盘容量、网络IO、磁盘IO资源均衡使用,尽量让CPU成为瓶颈。另外随着引擎的不断优化,软硬件基础设施的发展,机器过保置换是常态,最佳机型选择是一个动态演进的过程,滴滴运维保障团队2020年进行了新一轮机型优化与场景的调优,Elasticsearch日志集群成本降低了一半,CPU峰值平均利用率达到了50%。
3)部署选择
以Elasticsearch为例,最小高可用部署集群是3个节点,单节点承担Master Node、Client Node、 Data Node三种角色。一般3到5个节点集群规模影响不大,一旦到几十个节点,写入吞吐量达到百MB/S,节点网络处理线程池、内存资源竞争突显,元数据处理与索引数据处理资源未隔离,会导致集群元信息出现同步性能或一致性问题,进而诱发集群不可用,所以达到了一定体量后,需要考虑分角色部署。
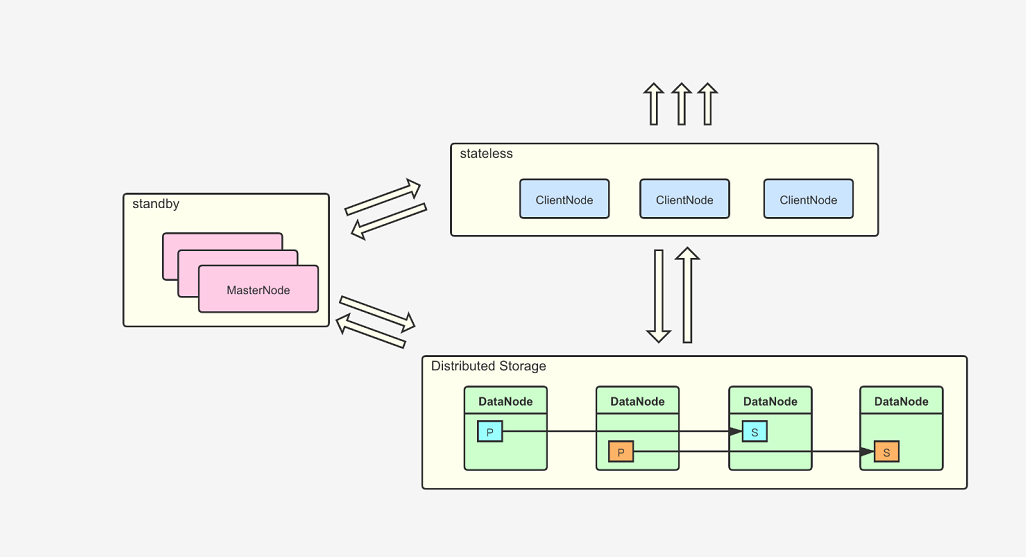
随着引擎服务业务方的持续增长,集群个数(10+)与集群规模快速增长(100+)。一方面会遇到用户咨询与答疑量激增的问题,有引擎上手门槛高的原因,更多的是资源申请、Schema变更等高频用户操作未平台化赋能有关;另一方面会触碰到运维保障能力边界,指标体系不完备,问题诊断低效,缺乏降级、限流、安全、跨AZ高可用的服务体系支撑,运维人员疲于奔命 。这个阶段需要做好两个方面的工作,一方面亟需提升引擎用户、运维保障人员的工作效率,将高频的变更或操作平台化实现,另一方面需要补足开源引擎在运维友好性上的短板,构建引擎的指标体系,高可用体系,进行服务架构升级。
1)引擎PaaS平台建设
以滴滴Kafka PaaS云平台Logi-KafkaManager为例介绍平台建设理念,具体设计参见:滴滴开源Logi-KafkaManager 一站式Kafka监控与管控平台,已开源https://github.com/didi/Logi-KafkaManager。
2)引擎服务架构升级
在Elastic Proxy层承接企业特性的拓展如安全、限流、高可用,突破大数据引擎的集群规模扩展瓶颈,用户既能享受多租户共享集群、独享集群、独立集群不同SLA保障等级的服务模式,又不用关心底层物理集群与资源的细节,构建了一套全托管的服务形态。

跨大版本升级,不管是存储格式、通讯协议、数据模型、都有许多不兼容的点,可以依托于Proxy架构实现跨大版本平滑升级,以下是滴滴2019年从ES2.3跨版本升级6.6.1的架构实践,详情参见:滴滴ElasticSearch平台跨版本升级以及平台重构之路
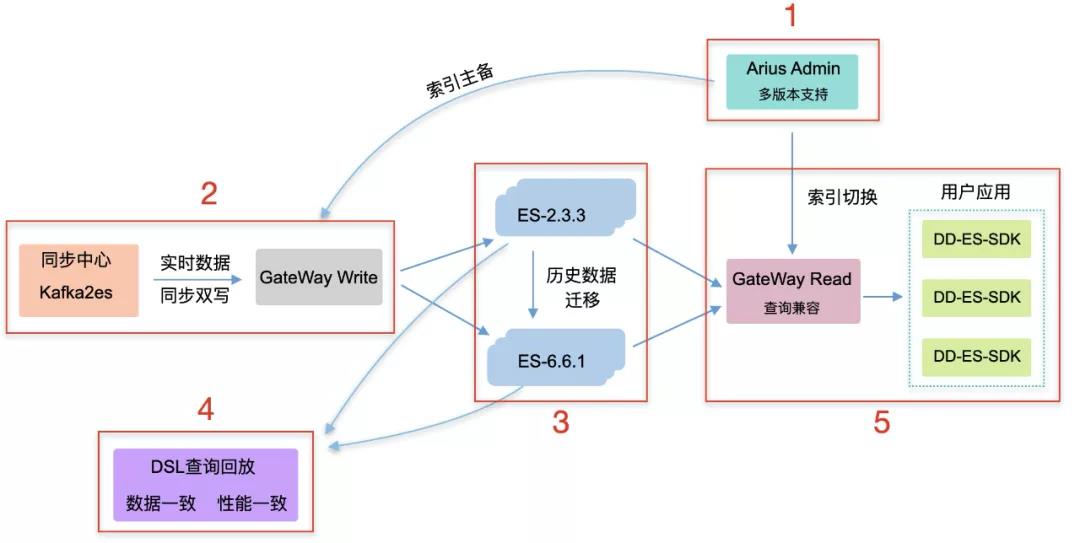
3、引擎突破期
随着业务的快速发展,实时峰值流量达到GB/S,离线数据增量达TB/天,不论是数据吞吐量还是集群规模都达到了开源引擎的能力边界。一方面低频故障场景比如磁盘故障、机器死机、Linux内核问题,在集群实例达到数百近千规模时频出;另一方面引擎在极端场景的BUG高概率被触发。都需要对引擎有深度的掌控力,能进行日常Bug Fix与内部版本的迭代,最终做到对引擎的自主与可控。
1)引擎原理深度掌控
快速熟悉开源代码,需要搭建本地调测环境,熟悉打包、编译、部署各个环节,跑通测试用例,学会基于测试用例进行功能调试,熟读官方用户与开发文档:https://kafka.apache.org

熟悉引擎的启动与日常运行日志,熟悉功能模块的主干流程与运行原理。

定期开展引擎原理分享与源码交流,参加社区Meetup,跟进社区Issue列表。
线上问题复盘:熟读源码有利于建立引擎整体的宏观认知,线上问题才是最好的学习场地。线上故障深追Root Cause及时复盘,探寻引擎每个细节,是将知识点变成认知的高效途径。引擎同学看到问题应该像看到金子一样,眼睛发光,追根究底,才能提升引擎的掌控力。

展开混沌工程,梳理引擎各异常场景,结合异常运行日志与监控指标,掌握该场景引擎的运行原理,明确引擎能力边界,做好稳定性保障的预案。

2)引擎内部分支迭代
线上引擎Bug:一般有两种解法,一种是社区有对应的Issue/Feature已解决,我们合并对应的Patch到本地维护的分支版本,进行Bug修复;另一种我们向社区提交Issue,提出解决方案,按照社区Patch提交流程进行测试与Review,最终合并到当前版本。滴滴每年累计向Apache社区包括Hadoop,Spark,Hive,Flink,HBase, Kafka,Elasticsearch,Submarine,Kylin开源项目贡献150+Patches。


引擎治理的核心目标是向上透传业务价值,向下索要技术红利,核心是通过数据看清问题,找到ROI最高的切入点,同时配套推动业务改造的核心抓手,讲清引擎服务的长期价值,保障技术持续的投入和价值创造!
1)透传业务价值
随着引擎服务业务方的增多,业务方应用场景持续动态演进,一方面我们可以通过资源利用率看清资源ROI情况,另一方通过用户对RT的敏感度,服务运行稳定性关注度,应用场景的重要程度,定期Review分级保障体系。
2)索要技术红利
服务运营通常都满足2-8原则,20%的业务特别核心,分级保障机制运营合理,对于服务运营方压力可控,在保障核心业务价值基本面的情况下,需要对剩下的80%的业务方,在资源、性能、成本、稳定性上,从平台层面进行统一治理与优化,结构化降低服务成本,提升服务质量,打造一个人人为我,我为人人的正向服务口碑体系建设,基于完善的指标体系,我们可以洞察出开源系统的软件瓶颈,根据ROI分阶段优化与创新,具体案例可以参考,我们在ES上的几个技术创新:

↓点这里可回看本期直播
阅读原文








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721