
一、迁移背景
Spark自从2010年面世,到2020年已经经过十年的发展,现在已经发展为大数据批计算的首选引擎,在滴滴Spark是在2015年便开始落地使用,不过主要使用的场景是更多在数据挖掘和机器学习方向,对于数仓SQL方向,主要仍以Hive SQL为主。
下图是当前滴滴内部SQL任务的架构图,滴滴各个业务线的离线任务是通过一站式数据开发平台DataStudio调度的,DataStudio把SQL任务提交到HiveServer2或者Spark两种计算引擎上。两个计算引擎均依赖资源管理器YARN和文件系统HDFS。
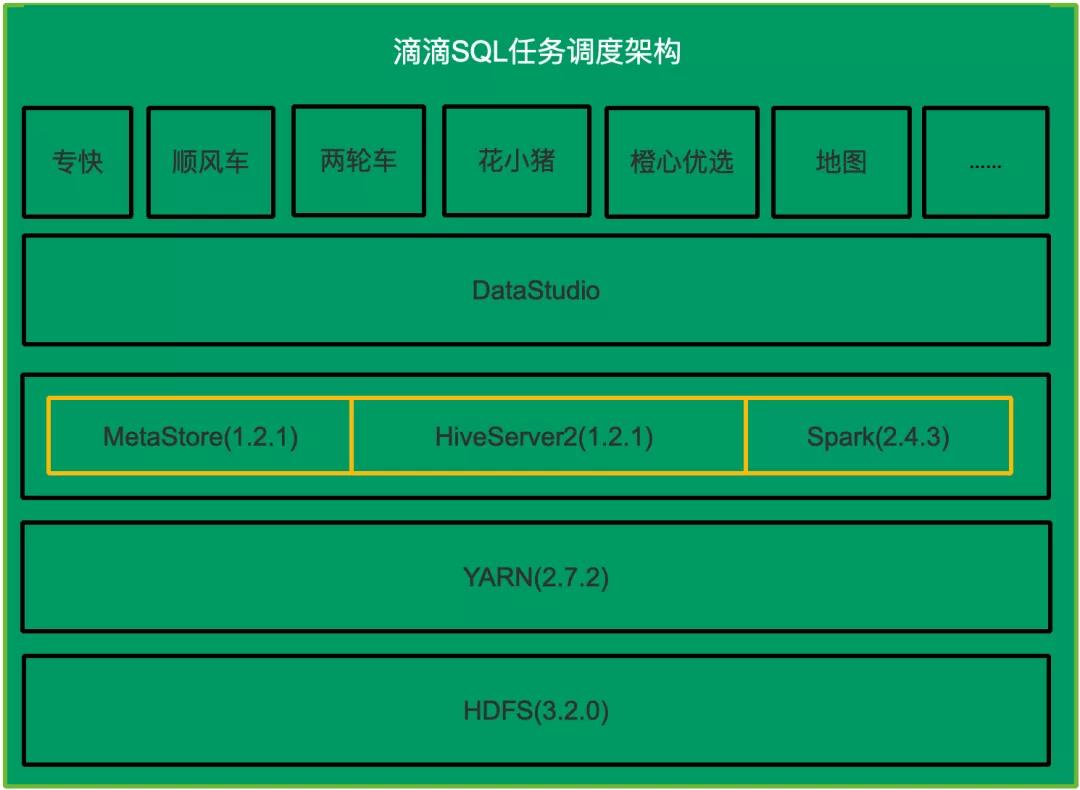
在迁移之前我们面临的主要问题有:
SQL任务运行慢:迁移前SQL任务运行的平均时间是20分钟,主要原因是占比高达83%的Hive SQL任务运行时间长,Hive任务执行过程中会启动多个MR Job,Job间的中间结果存储在HDFS,所以同一个SQL, Hive比Spark执行的时间更长;
Hive SQL稳定性差:一个HS2会同时执行多个用户的Hive SQL任务,当一个异常任务导致HS2进程响应慢甚至异常退出时,运行在同一个实例的SQL任务也会运行缓慢甚至失败。而异常任务场景各异。我们曾经遇到的异常任务有多个大SQL加载过多的分区元数据导致HS2 FullGC,加载UDF时导致HS2进程core dump,UDF访问HDFS没有关闭流导致HS2机器端口被打满,这些没有通用解法, 问题很难收敛;
人力分散:两个引擎需要投入双倍的人力,在人员有限的情况下,对引擎的掌控力会减弱;
所以为了SQL任务运行更快,更稳,团队人力聚焦,对引擎有更强的掌控力,我们决定把Hive SQL迁移到Spark SQL。
二、迁移方案概要设计
Hive SQL迁移到Spark SQL后需满足以下条件:
保证数据一致性,也就是相同的SQL使用Spark和Hive执行的结果应该是一样的;
保证用户有收益,也就是使用Spark执行SQL后应该节省资源,包括时间,cpu和memroy;
迁移过程对用户透明;
为了满足以上三个条件, 一个很直观的思路就是使用两个引擎执行用户SQL,然后对比每个引擎的执行结果和资源消耗。
为了不影响用户线上数据,使用两个引擎执行用户SQL有两个可选方案:
复用现有的SQL任务调度系统,再部署一套SQL任务调度系统用来迁移,这个系统与生产环境物理隔离;
开发一个SQL双跑工具,可以支持使用两个引擎执行同一个SQL任务;
下面详细介绍这两个方案:
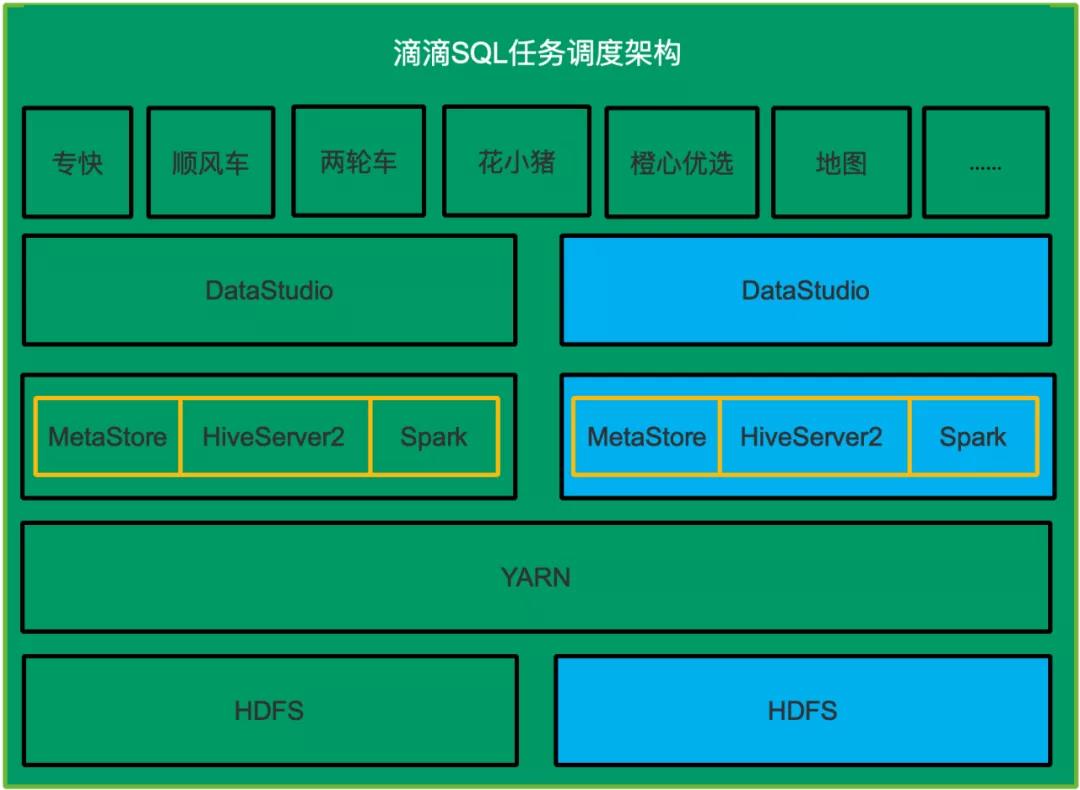
再部署一套SQL任务执行系统用来使用Spark执行所有的SQL,包括HDFS,HiveServer2&MetaStore和Spark,DataStudio。新部署的系统需要周期性从生产环境同步任务信息,元数据信息和HDFS数据,在这个新部署的系统中把Hive SQL任务改成Spark SQL类型任务,这样一个用户的SQL在原有系统中使用Hive SQL执行,在新部署的系统中使用Spark执行。如下图所示,蓝色的表示需要新部署的子系统。
SQL双跑工具,可以线下使用两个引擎执行用户的SQL,具体流程如下:
SQL收集:用户的SQL是在HS2上执行的,所以理论上通过HS2可以收集到所有的SQL;
SQL改写:执行用户原始SQL会覆盖线上数据,所以在执行前需要改写SQL,把SQL的输出的库表名替换为用来迁移测试的的库表名;
SQL双跑:分别使用Hive和Spark执行改写后的SQL;
1)方案一
① 优势
隔离性好,单独的SQL执行系统不会影响生产任务,也不会影响业务数据;
② 劣势
需要的资源多:运行多个子系统需要较多物理资源;
部署复杂:部署多个子系统,需要多个不同的团队相互配合;
容易出错:子系统间需要周期性同步,任何一个子系统同步出问题,都可能导致执行SQL失败;
2)方案二
① 优势
非常轻量,不需要部署很多系统,而且对物理资源需要不高;
② 劣势
与生产公共一套环境,回放时有影响用户数据对风险;
需要开发SQL收集,SQL改写和SQL双跑系统;
经过权衡, 我们决定采用方案二, 因为:
通过HiveServer收集所有SQL,SQL改写和SQL双跑逻辑清晰,开发成本可控;
创建超读帐号,对所有库表有读权限,但只对用户迁移的测试库有写权限,可以避免影响用户数据的风险;
三、迁移方案详细设计
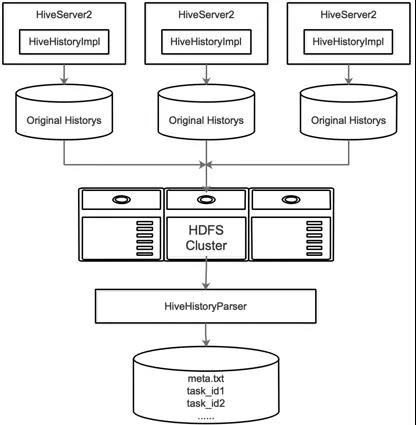
Hive SQL提取包括以下步骤:
改造HiveHistoryImpl,每个session内执行的所有SQL和command保存到HiveServer2的一个本地文件中,这些文件按天组织,每天一个目录
定时将前一天的History目录上传到hdfs
开发HiveHistoryParser
Hive History Parser的主要功能是:
每天从HDFS下载所有HiveServer2的History文件;
SQL去重:DataStudio上的一个SQL任务可能一天执行多次(比如小时任务),任务执行一次会生成一个新的执行Id,只保留一天中最大的执行Id的SQL;
合并SQL:一个shell任务可能建立多个session执行SQL,为了后面迁移shell任务,需要把多个session的SQL合并到一起;
输出Parse结果:包括多个SQL文件和meta文件:
每个任务执行的SQL保存到一个文件中,文件名是任务名称加执行Id,我们称作原始SQL文件;
meta文件包含SQL文件路径,任务名称,项目名称,用户名;
SQL改写会对上一步生成的每个原始SQL文件执行以下步骤:
使用Spark的SessionState对SQL文件逐行分析,识别是否包含以下两类子句:
insert overwrite into
create table as select
如果包含上面的两类子句,则提取写入的目标库表名称;
在测试库中创建与目标库表schema完全一致的两个测试表;
分别使用上一步创建的测试库表替换原始SQL文件中的库表名生成用于回放的SQL文件,一个原始SQL文件改写后会生成两个SQL文件,用于后面两个引擎分别执行;
SQL双跑步骤如下:
并发的使用Spark和Hive执行上一步生成的两个SQL文件;
记录使用两种引擎执行SQL时启动的Application和运行时间;
输出回放结果到文件中,执行每个SQL文件对会生成一条结果记录, 包括Hive 和Spark 执行SQL的时间,启动的Application列表,和输出的目标库表名称等, 如下图所示:

结果对比时会遍历每个回放记录,统计以下指标:
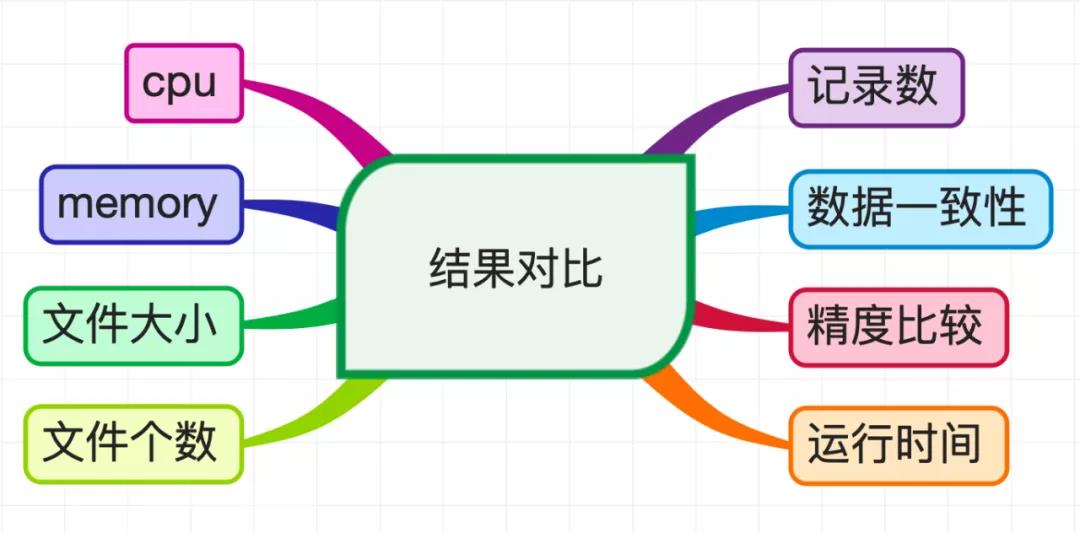
具体流程如下:
查询Spark SQL和Hive SQL输出的库表的记录数;
查询两种引擎输出的HDFS文件个数和大小;
对比两种引擎的输出数据;
分别对Spark和Hive的产出表执行以下SQL,获取表的概要信息
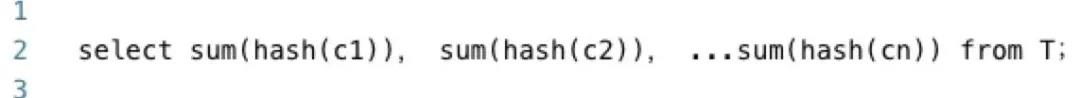
比较两张表的概要信息:
如果所有对应列的值相同则认为结果一致;
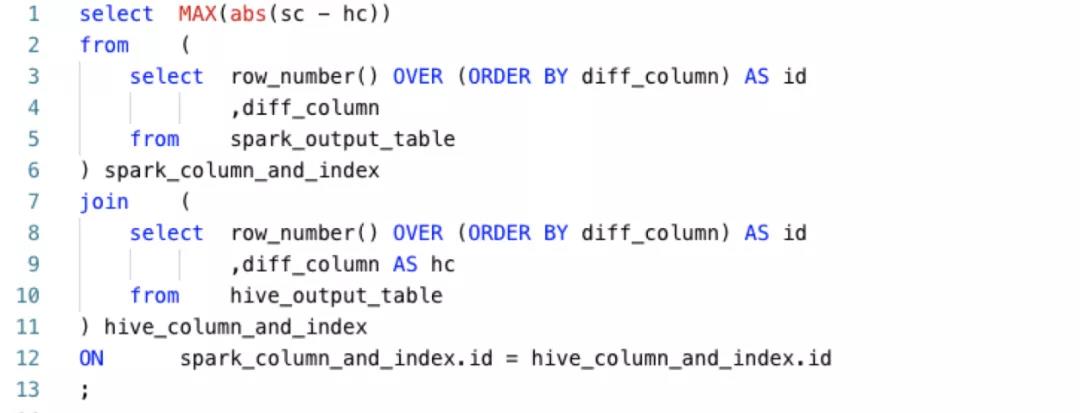
如果存在不一致的列,如果该列是数值类型,则对该列计算最大精度差异, SQL如下:
统计两种引擎启动的Application消耗的vcore和memory资源;
输出对比结果, 包括运行时间, 消耗的vcore和memory,是否一致,如果不一致输出不一致的列名以及最大差异;
汇总数据结果,并对回放的SQL分为以下几类:
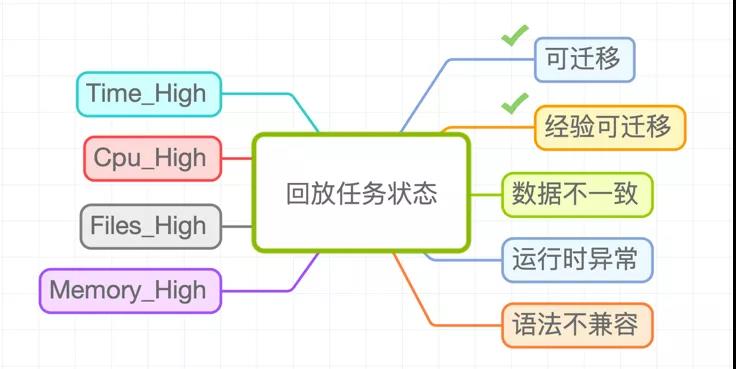
可迁移:数据完全一致, 并且使用Spark SQL执行使用更少资源,包括运行时间,vcore和memory以及文件数;
经验可迁移:在排查不一致时发现有些是逻辑正确的 (比如collect_set结果顺序不一致),如果有些任务符合这些经验,则认为是经验可迁移;
数据不一致:两种引擎产出的结果存在不一致的列,而且没有命中经验;
Time_High:两种引擎产出的结果完全一致,但是Spark执行SQL的运行时间大于Hive执行SQL的时间;
Cpu_High:两种引擎产出的结果完全一致,但是Spark执行SQL消耗的cpu资源大于Hive执行SQL消耗的cpu资源;
Memory_High:两种引擎产出的结果完全一致,但是Spark执行SQL消耗的memory资源大于Hive执行SQL消耗的memory资源;
Files_High:两种引擎产出的结果完全一致,但是Spark执行SQL产生的文件数大于Hive执行SQL产生的文件数;
语法不兼容:在SQL改写阶段解析SQL时报语法错误;
运行时异常:在双跑阶段,Hive SQL或者Spark SQL在运行过程中失败;
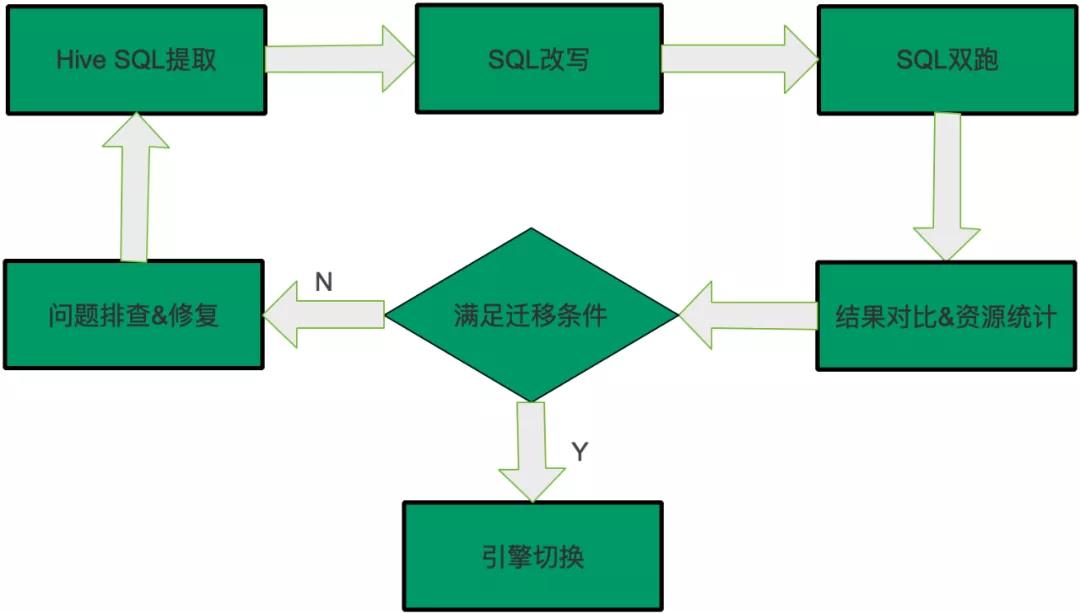
迁移比较简单, 步骤如下:
整理迁移任务列表以及对应的配置参数;
调用DataStudio接口把任务类型修改为SparkSQL类型;
重跑任务;
如果SQL是“可迁移”或者“经验可迁移”,可以执行迁移,其它的任务需要排查,这部分是最耗时耗力的,迁移过程中大部分时间都是在调查和修复这些问题。
修复之后再执行从头开始,提取最新任务的SQL,然后SQL改写和双跑,结果对比,满足迁移条件则说明修复了问题,可以迁移,否则继续排查,因此迁移过程是一个循环往复的过程,直到SQL满足迁移条件,整体过程如下图所示:
四、引擎差异
在迁移的过程中我们发现了很多两种引擎不同的地方,主要包括语法差异,UDF差异,功能差异和性能差异。
有些Hive SQL使用Spark SQL执行在语法分析阶段就会出错,有些语法差异我们在内部版本已经修复,目前正在反馈社区,正在和社区讨论,还有一些目前没有修复。
1)用例设计
UDTF新版initialize接口支持,对齐Hive SQL [SPARK-33704]
Window Function 不支持没有order by子句的场景
Join 子查询支持rand 随机分布条件,增强语法兼容
Orc/Orcfile 存储类型创建语句屏蔽ROW FORMAT DELIMITED限制 [SPARK-33755]
`DB.TB` 识别支持,对齐Hive SQL [SPARK-33686]
支持CREATE TEMPORARY TABLE
各类Hive UDF的支持调用,主要包括get_json_object,datediff,unix_timestamp,to_date,collect_set,date_sub [SPARK-33721]
DROP不存在的表和分区,Spark SQL报错,Hive SQL 正常 [SPARK-33637]
删除分区时支持设置过滤条件 [SPARK-33691]
2)未修复
Map类型字段不支持GROUP BY操作
Operation not allowed:ALTER TABLE CONCATENATE
在排查数据不一致的SQL过程中,我们发现有些是因为输入数据的顺序不同造成的, 这些差异逻辑上是正确的,而有些是UDF对异常值的处理方式不一致造成的,还有需要注意的是UDF执行环境不同造成的结果差异。
1)顺序差异
这些因为输入数据的顺序不同造成的结果差异逻辑上是一致的,对业务无影响,因此在迁移过程中可以忽略这些差异,这类差异的SQL任务属于经验可迁移。
① collect_set
假设数据表如下:
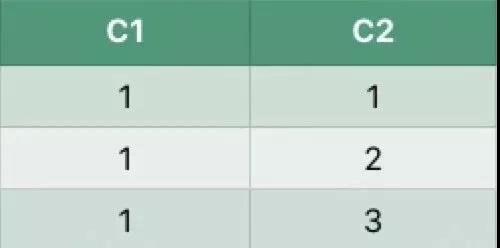
执行如下SQL:

执行结果:
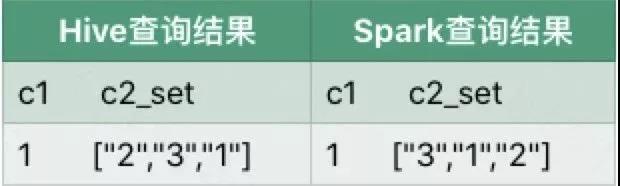
差异说明:
collect_set执行结果的顺序取决于记录被扫描的顺序,Spark SQL执行过程中是多个任务并发执行的,因此记录被读取的顺序是无法保证的。
② collect_list
假设数据表如下:
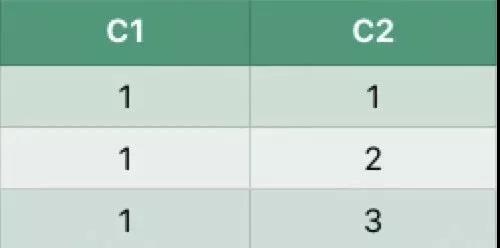
执行如下SQL:

执行结果:
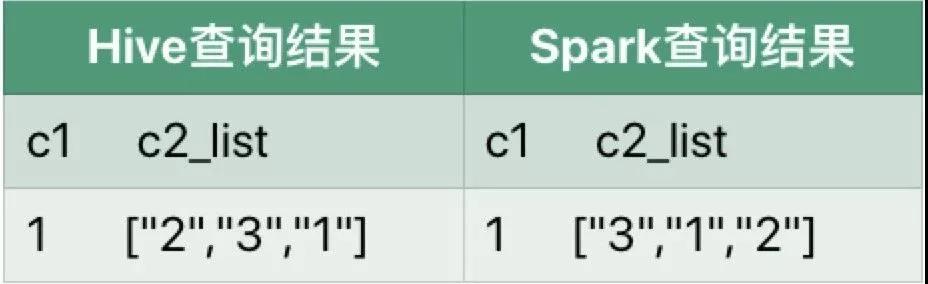
差异说明:
collect_list执行结果的顺序取决于记录被扫描的顺序,Spark SQL执行过程中是多个任务并发执行的,因此记录被读取的顺序是无法保证的。
③ row_number
假设数据表如下:
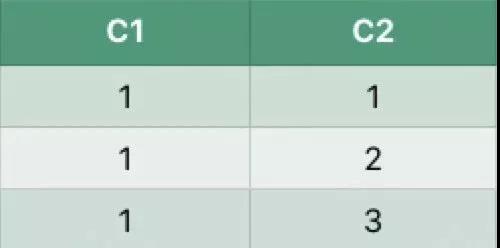
执行如下SQL:

执行结果:
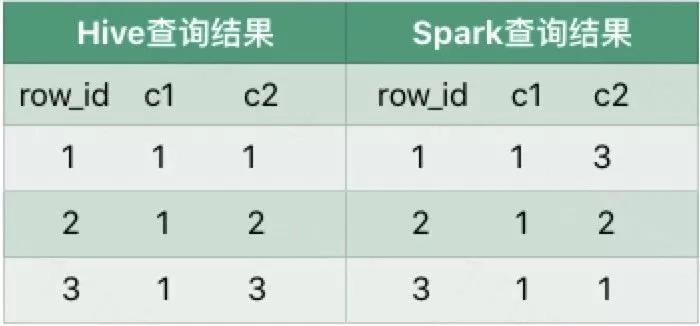
差异说明:
执行row_number时,在一个分区内部,可以保证order by字段是有序的,对于非分区非order by字段的顺序是没有保证的。
④ map类型字段读写
数据表建表语句:

假设数据表如下:

执行如下SQL:
执行结果:

差异说明:
Map类型是无序的,同一份数据,在query时显示的各个key的顺序会有变化。
⑤ sum(double/float)
假设数据表如下:

执行如下SQL:

执行结果:

差异说明:
这是由float/double类型的表示方式决定的,浮点数不能表示所有的实数,在执行运算过程中会有精度丢失,对于几个浮点数,执行加法时的顺序不同,结果有时就会不同。

⑥ 顺序差异解决方案
由以上UDF造成的差异可以忽略,相关任务如果在资源方面也有节省,那么最终的状态是经验可迁移状态,符合迁移条件。
2)非顺序差异
下面几个日期/时间相关函数,当有异常输入是Spark SQL会返回NULL,而Hive SQL会返回一个非NULL值。
① datediff
对于异常日期,比如0000-00-00执行datediff两者会存在差异。

② unix_timestamp
对于24点Spark认为是非法的返回NULL,而Hive任务是正常的,下表时执行unix_timestamp(concat('2020-06-01', ' 24:00:00'))时的差异。

③ to_date
当月或者日是00时Hive仍然会返回一个日期,但是Spark会返回NULL。

④ date_sub
当月或者日是00时Hive仍然会返回一个日期,但是Spark会返回NULL。

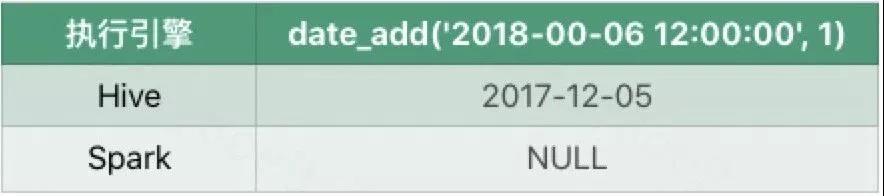
⑤ date_add
当月或者日是00时Hive仍然会返回一个日期,但是Spark会返回NULL。
⑥ 非顺序差异解决方案
这些差异是是因为对异常UDF参数的处理逻辑不同造成的,虽然Spark SQL返回NULL更合理,但是现有的Hive SQL任务用户适应了这种处理逻辑,所以为了不影响现有SQL任务,我们对这类UDF做了兼容处理,用户可以通过配置来决定使用Hive内置函数还是Spark的内置UDF。
3)UDF执行环境差异
① 差异说明
基于MapReduce的Hive SQL一个Task会启动一个进程,进程中的主线程负责数据处理, 因此在Hive SQL中UDF只会在单程中执行。
而Spark 一个Executor可能会启动多个Task,如下图所示。因此在Spark SQL中自定义UDF时需要考虑线程安全问题。
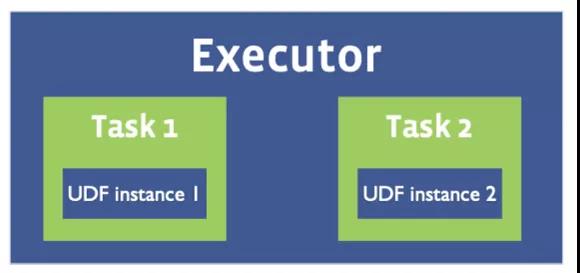
② 差异解决方案
下面是一个非线程安全的示例,UDF内部共享静态变量,在执行UDF时会读写这个静态变量。

解决方案也比较简单,一种是加锁,如下图所示:
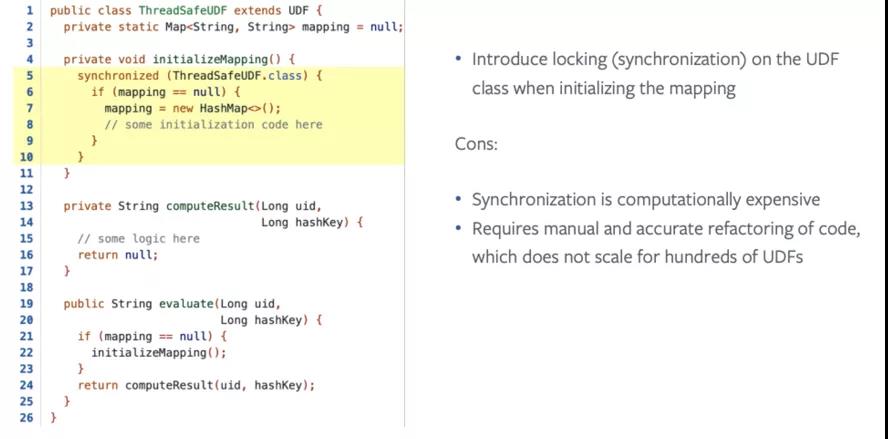
另一种是取消静态成员,如下图所示:

1)小文件合并
Hive SQL可以通过设置以下配置合并小文件,MR Job结束后,判断生成文件的平均大小,如果小于阀值,就再启动一个Job来合并文件。

目前Spark SQL不支持小文件合并,在迁移过程中,我们经常发现Spark SQL生成的文件数多于Hive SQL,为此我们参考Hive SQL的实现在Spark SQL中引入了小文件合并功能。
在InsertIntoHiveTable 中判断如果开启小文件合并,并且文件的平均大小低于阈值则执行合并,合并之后再执行loadTable或者loadPartition操作。
2)Spark SQL支持Cluster模式
Hive SQL任务是DataStudio通过beeline -f执行的,客户端只负责发送SQL语句给HS2,已经获取执行结果,因此是非常轻量的。而Spark SQL只支持Client模式,Driver在Client进程中,因此Client模式执行Spark SQL时,有时会占用很多的资源,DataStudio无法感知Spark Driver的资源开销,所以在DataStudio层面会带来以下问题:
形成资源热点,影响任务执行;
随着迁移到Spark SQL的任务越来越多,DataStudio需要越来越多的机器调度SQL任务;
Client模式日志保留在本地,排查问题时不方便看日志;
所以我们开发了Spark SQL支持Cluster模式,该模式只支持非交互式方式执行SQL,包括spark-sql -e和spark-sql -f,不支持交互式模式。
3)分区剪裁优化
迁移过程中我们发现大部分任务的分区条件包括concat, concat_ws, substr等UDF, HiveServer2会调用MetaStore的getPartitionsByExpr方法返回符合分区条件的有效分区,避免无效的扫描, 但是Spark SQL的分区剪裁只支持由Attribute和Literal组成key/value结构的谓词条件,这一方面导致无法有效分区剪裁,会查询所有分区的数据, 造成读取大量无效数据,另一方面查询所有分区的元数据,导致MetaStore对MySQL查询压力激增,导致mysql进程把cpu打满。我们在社区版本的基础上迭代支持了多种场景的分区联合剪裁,目前能够覆盖生产任务90%以上的场景。
concat/concat_ws联合剪裁场景

substr 联合剪裁场景

concat/concat_ws&substr组合场景

目前已经反馈社区,正在讨论中,具体可参考[SPARK-33707][SQL] Support multiple types of function partition pruning on hive metastore
五、迁移结果
经过6个多月的团队的努力,我们迁移了1万多个Hive SQL任务到Spark SQL,在迁移过程中,随着spark SQL任务的增加,SQL任务的执行时间在逐渐减少,从最初的1000+秒下降到600+秒如下图所示:

迁移后Spark SQL任务占比85%,SQL任务运行时间节省40%,计算资源节省21%,内存资源节省49%,迁移的收益是非常大的。
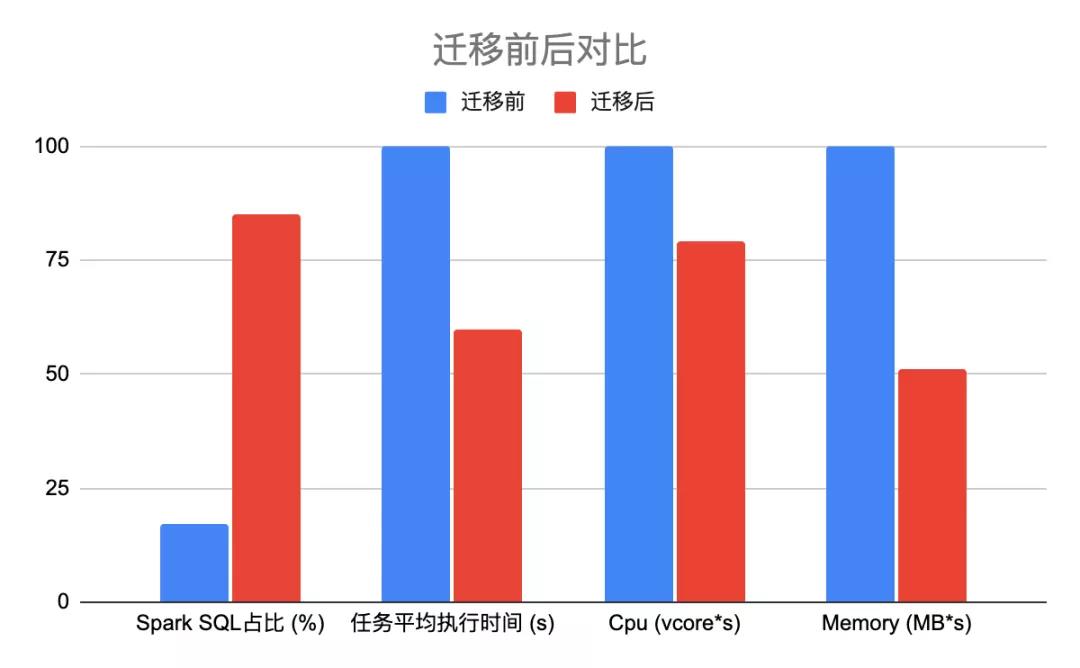
六、下一步计划
迁移之后Spark已经成为SQL任务的主流引擎,但是还有大量的shell类型任务使用Hive执行SQL,所以后续我们会迁移shell类型任务,把shell中的Hive SQL迁移到Spark SQL。
在生产环境中,有些shuffle 比较中的任务经常会因为shuffle fetch重试甚至失败,我们想优化Spark External Shuffle Service。
社区推出Spark 3.x也半年多了,在功能和性能上有很大提升,所以我们也想和社区保持同步,升级Spark到3.x版本。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721