
采用新的框架总是会带来很多惊喜。当你花了几天时间去排查为什么服务运行异常,结果发现只是因为某个功能的用法不对或者缺少一些简单的配置。
在 Contentsquare[1],我们需要不断升级数据处理任务,以满足越来越多的数据上的苛刻需求。这也是为什么我们决定将用于会话[2]处理的小时级 Spark 任务迁移到 Flink[3] 流服务。这样我们就可以利用 Flink 更为健壮的处理能力,提供更实时的数据给用户,并能提供历史数据。不过这并不轻松,我们的团队在上面工作了有一年时间。同时,我们也遇到了一些令人惊讶的问题,本文将尝试帮助你避免这些陷阱。
一、并行度设置导致的负载倾斜
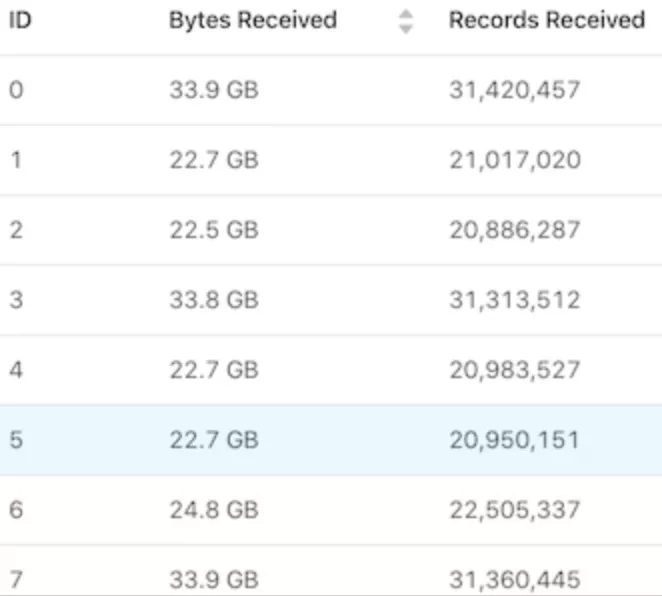
每个子任务的工作负载并不均衡
这表明每个子任务的算子没有收到相同数量的 Key Groups,它代表所有可能的 key 的一部分。如果一个算子收到了 1 个 Key Group,而另外一个算子收到了 2 个,则第二个子任务很可能需要完成两倍的工作。查看 Flink 的代码,我们可以找到以下函数:
public static int computeOperatorIndexForKeyGroup( int maxParallelism, int parallelism, int keyGroupId) { return keyGroupId * parallelism / maxParallelism; }
其目的是将所有 Key Groups 分发给实际的算子。Key Groups 的总数由 maxParallelism 参数决定,而算子的数量和 parallelism 相同。这里最大的问题是 maxParallelism 的默认值,它默认等于 operatorParallelism + (operatorParallelism / 2) [4]。假如我们设置 parallelism 为10,那么 maxParallelism 为 15 (实际最大并发度值的下限是 128 ,上限是 32768,这里只是为了方便举例)。这样,根据上面的函数,我们可以计算出哪些算子会分配给哪些 Key Group。
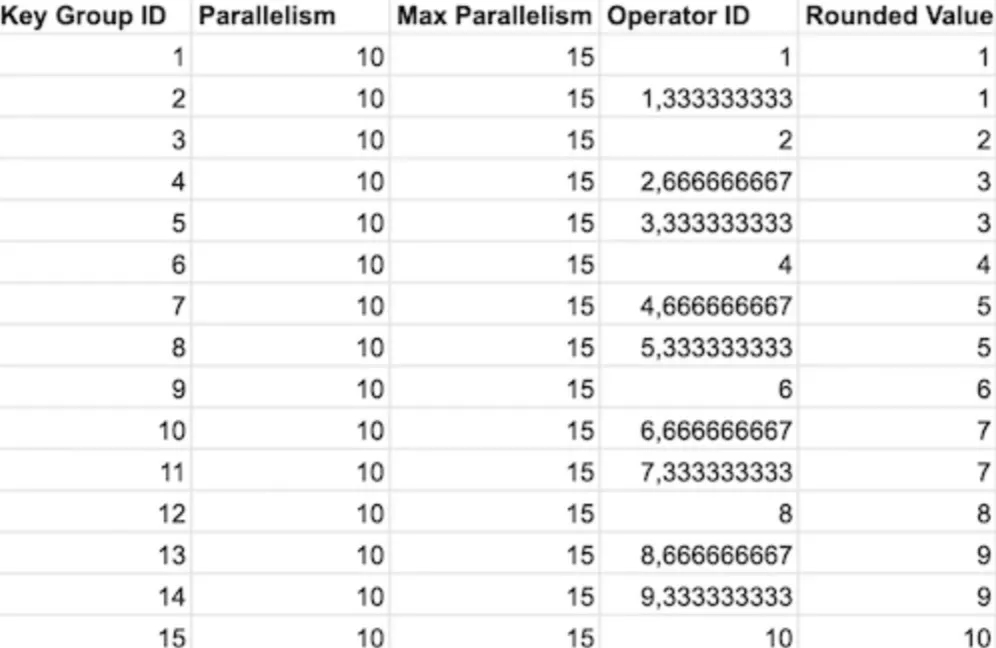
在默认配置下,部分算子分配了两个 Key Group,部分算子只分配了 1 个
解决这个问题非常容易:设置并发度的时候,还要为 maxParallelism 设置一个值,且该值为 parallelism 的倍数。这将让负载更加均衡,同时方便以后扩展。
二、注意 mapWithState & TTL 的重要性
如果你的 keyed 状态包含在某个 Flink 的默认窗口中,则将是安全的:即使未使用 TTL,在处理窗口的元素时也会注册一个清除计时器,该计时器将调用 clearAllState 函数,并删除与该窗口关联的状态及其元数据。
如果要使用 Keyed State Descriptor [5]来管理状态,可以很方便地添加 TTL 配置,以确保在状态中的键数量不会无限制地增加。
但是,你可能会想使用更简便的 mapWithState 方法,该方法可让你访问 valueState 并隐藏操作的复杂性。虽然这对于测试和少量键的数据来说是很好的选择,但如果在生产环境中遇到无限多键值时,会引发问题。由于状态是对你隐藏的,因此你无法设置 TTL,并且默认情况下未配置任何 TTL。这就是为什么值得考虑做一些额外工作的原因,如声明诸如 RichMapFunction 之类的东西,这将使你能更好的控制状态的生命周期。
三、从检查点还原和重新分区
在使用大状态时,有必要使用增量检查点(incremental checkpointing)。在我们的案例中,任务的完整状态约为 8TB,我们将检查点配置为每 15 分钟做一次。由于检查点是增量式的,因此我们只能设法每 15 分钟将大约 100GB 的数据发送到对象存储,这是一种更快的方式并且网络占用较少。这对于容错效果很好,但是在更新任务时我们也需要检索状态。常用的方法是为正在运行的作业创建一个保存点(savepoint),以可移植的格式包含整个状态。
但是,在我们的情况下,保存点可能需要几个小时才能完成,这使得每次发布版本都是一个漫长而麻烦的过程。相反,我们决定使用保留检查点(Retained Checkpoints[6])。设置此参数后,我们可以通过从上一个作业的检查点恢复状态来加快发布速度,而不必触发冗长的保存点!
此外,尽管保存点比检查点具有更高的可移植性,但您仍然可以使用保留的检查点来更改作业的分区(它可能不适用于所有类型的作业,所以最好对其进行测试)。这与从保存点重新分区完全一样,但是不需要经历 Flink 在 TaskManager 之间重新分配数据的漫长过程。当我们尝试这样做时,大约花了 8 个小时才完成,这是不可持续的。幸运的是,由于我们使用的是 RocksDB 状态后端,因此我们可以在这步中增加更多线程以提高其速度。这是通过将以下两个参数从 1 增加到 8 来完成的:
state.backend.rocksdb.checkpoint.transfer.thread.num:8
state.backend.rocksdb.thread.num:8
使用保留的检查点,并增加分配给 RocksDB 传输的线程数,能将发布和重新分区时间减少 10 倍!
四、提前增加日志记录
这一点可能看起来很明显,但也很容易忘记。开发作业时,请记住它将运行很长时间,并且可能会处理意外的数据。发生这种情况时,你将需要尽可能多的信息来调查发生了什么,而不必通过再次回溯相同的数据来重现问题。
我们的任务是将事件汇总在一起,并根据特定规则进行合并。这些规则中的某些规则在大多数情况下性能还可以,但是当有数据倾斜时却要花费很长时间。当我们发现任务卡住了 3 个小时,却不知道它在做什么。似乎只有一个 TaskManager 的 CPU 可以正常工作,因此我们怀疑是特定数据导致我们的算法性能下降。
最终处理完数据后,一切恢复正常,但是我们不知道从哪开始检查!这就是为什么我们为这些情况添加了一些预防性日志的原因:在处理窗口时,我们会测量花费的时间。只要计算窗口所需的时间超过 1 分钟,我们就会记录下所有可能的数据。这对于准确了解导致性能下降的倾斜是非常有帮助的,并且当再次发生这种情况时,我们能够定位到合并过程处理慢的部分原因。假如收到的是重复的数据,则可能确实需要几个小时。当然,重要的是不要过多地记录信息,因为这会降低性能。因此,请尝试找到仅在异常情况下才显示信息的阈值。
五、如何找出卡住的作业实际上在做什么
首先,将此属性添加到我们的 flink-conf.yaml 中
env.java.opts: "-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.port=1099 -Dcom.sun.management.jmxremote.rmi.port=1099 -Djava.rmi.server.hostname=127.0.0.1"
然后,将本地端口 1099 转发到 TaskManager 的 pod 中的端口
kubectl port-forward flink-taskmanager-4 1099
最后,打开 jconsole
jconsole 127.0.0.1:1099
这使您可以轻松地在 JVM 上查看目标 TaskManager 的信息。对于卡住的作业,我们以正在运行的唯一一个 TaskManager 为目标,分析了正在运行的线程:
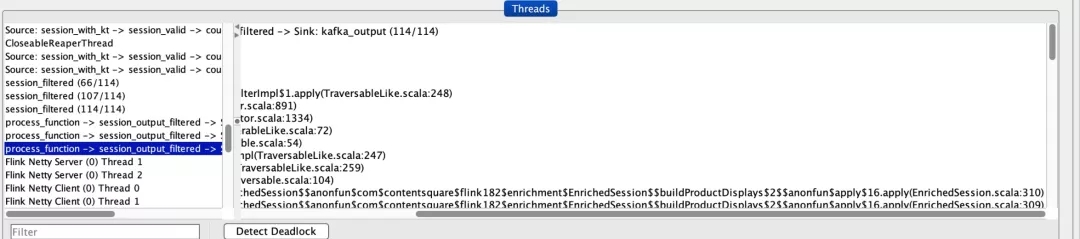
JConsole 向我们展示了每个线程当前正在做什么
深入研究,我们可以看到所有线程都在等待,除了其中一个(在上面的屏幕截图中已突出显示)。这使得我们能够快速发现作业是卡在哪个方法调用里面的,并轻松修复!
六、将数据从一种状态迁移到另一种状态的风险
根据你的实际情况,可能需要保留两个具有不同语义的不同状态描述符。例如,我们通过 WindowContent 状态为进行中的会话累积事件,接着将处理后的会话移动到称为 HistoricalSessions 的 ValueState 中。第二个状态为了防止后面需要用到会保留几天,直到 TTL 过期丢弃它为止。
我们做的第一个测试运行良好:我们可以发送额外的数据到已处理的会话,这将为相同的键创建一个新窗口。在窗口的处理过程中,我们会从 HistoricalSessions 状态中获取数据,以将新数据与旧会话合并,并且结果会话是历史会话的增强版本,这也正是我们所期望的。
在执行此操作时,我们遇到过几次内存问题。经过几次测试后,我们了解到 OOM 仅在将旧数据发送到 Flink 时才发生(即,发送数据的时间戳早于其当前水印)。这使得我们发现了当前处理方式中的一个大问题:当接收到旧数据时,Flink 将其与旧窗口合并,而旧窗口的数据仍在 WindowContent 状态内(这可以通过设置 AllowedLateness 实现)。然后结果窗口会与 HistoricalSessions 内容合并,该内容还包含旧的数据。最终我们得到的是重复的事件,在同一会话中收到一些事件后,每个事件都将有数千条重复,从而导致了 OOM。
这个问题的解法非常简单:我们希望 WindowContent 在将其内容移至第二个状态之前自动清除。我们使用了 Flink 的 PurgingTrigger 来达到这个目的,当窗口触发时,该消息会发送一条清除状态内容的消息。具体代码如下所示:
// Purging the window's content allows us to receive late events without merging them twice with the old session val sessionWindows = keyedStream .window(EventTimeSessionWindows.withGap(Time.minutes(30))) .allowedLateness(Time.days(7)) .trigger(PurgingTrigger.of(EventTimeTrigger.create()))
七、Reduce VS Process
如上所述,我们对 Flink 的使用依赖于累积给定键的数据,并将所有这些数据合并在一起。这可以通过两种方式完成:
将数据存储在 ListState 容器中,等待会话结束,并在会话结束时将所有数据合并在一起;
使用 ReducingState 在每个新事件到达时,将其与之前的事件合并。
使用第一种还是第二种状态取决于你在 WindowedStream 上运行的功能:使用 ProcessWindowFunction 的 process 调用将使用 ListState,而使用 ReduceFunction 的 reduce 调用则将使用 ReducingState。
ReducingState 的优点非常明显:不存储窗口处理之前的所有数据,而是在单个记录中不断地对其进行聚合。这通常会导致状态更小,取决于在 reduce 操作期间会丢弃多少数据。对我们来说,它在存储方面几乎没有改善,因为与我们为历史会话存储的 7 天数据相比,该状态的大小可以忽略不计。相反,我们注意到通过使用 ListState 可以提高性能!
原因是:每次新事件到来时,连续的 reduce 操作都需要对数据进行反序列化和序列化。这可以在 RocksDBReducingState[7] 的 add 函数中看到,该函数会调用 getInternal[8],从而导致数据反序列化。
但是,当使用 RocksDB 更新 ListState 中的值,我们可以看到没有序列化发生[9]。这要归功于 RocksDB 的合并操作能让 Flink 可以将数据进行追加而无需反序列化。
最后,我们选择了 ListState 方法,因为性能提升有助于减少延迟,而存储的影响却很小。
八、不要相信输入数据!
让我们快速定义几个关键术语,供后面使用:
“网页浏览(PV)事件”是我们接收到的主要信息。当访问者在客户端加载 URL 以及 userId、sessionNumber 和 pageNumber 等信息时,就会触发它;
“会话”代表用户在不离开网站的情况下进行的所有互动的总和。它们是由 Flink 通过汇总 PV 事件和其他信息计算得出的。
为了保护我们的任务,我们已尽可能的增加前置过滤。我们必须遵守的规则是,尽可能早地在流中过滤掉无效数据,以避免在中后期造成不必要的昂贵操作。例如,我们有一个规则,对于给定的会话,最多只能发送 300 个 PV 事件。每个 PV 事件都用一个递增的页码标记,以指示其在会话中的位置。当我们在一个会话中接收到超过 300 个 PV 事件时,我们可以通过以下方法来过滤它们:
计算一个给定窗口过期时的 PV 事件的数量;
丢弃页码超过 300 的事件。
第一个方案似乎更可靠,因为它不依赖于页码的值,但是我们要在状态中累积 300 多个 PV 事件,然后才能排除它们。最终我们选择了第二个方案,该方案在错误数据进入 Flink 时就进行了排除。
除了这些无状态过滤器之外,我们还需要根据与每个键相关的指标排除数据。例如,每个会话的最大大小(以字节为单位)设置为 4MB。选择此数字是出于业务原因,也是为了帮助解决 Flink 中 RocksDB 状态的一个限制。事实上,如果 Flink 使用的 RocksDB API 的值超过 2 ^ 31 字节[10],那么它就会失败。因此,如果你像上面解释的那样使用一个 ListState,则需要确保你永远不要累积太多的数据。
当你只有关于新消费的事件的信息时,就不可能知道会话的当前大小,这意味着我们不能使用与处理页码相同的技巧。我们所做的只是将 RocksDB 中的每个键(即每个会话)的元数据存储在一个单独的 ValueState 中。此元数据在 keyBy 算子之后,但在开窗之前使用和更新。这意味着我们可以保护 RocksDB 避免在其 ListState 中积累太多数据,因为基于此元数据,我们知道何时停止接受给定键的值!
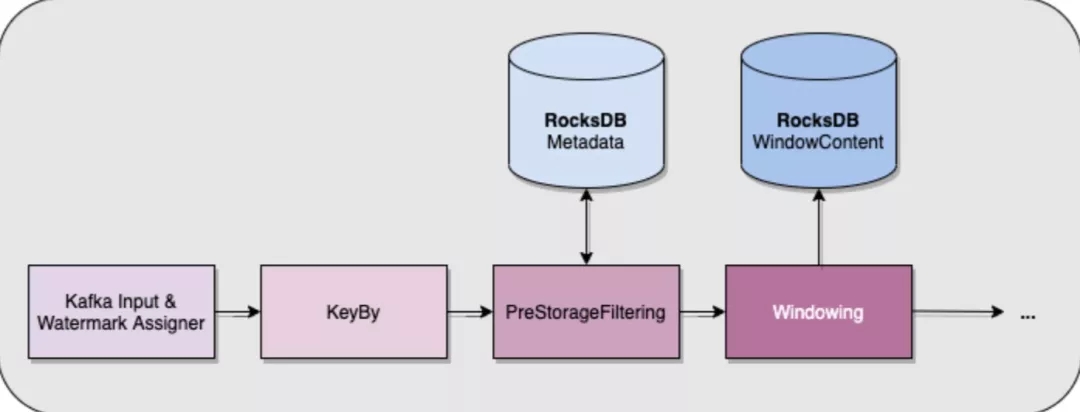
九、事件时间的危险性
这个组件(称为 Asimov)是一个简单的 Akka 流程序,该程序读取 Kafka topic,解析 JSON 数据,将其转换为 protobuf,然后将其推送到另一个 Kafka topic,这样Flink就可以处理这个 protobuf。Asimov 的输入在每个分区中应该是有序的,但是由于分区不是与输出 topic 一对一映射,因此当Flink最终处理消息时,可能会出现一些乱序。这样也没啥问题,因为 Flink 能通过延迟水印来支持乱序。
问题是,当 Asimov 读取一个分区的速度比其他分区慢时:这意味着 Flink 的水印将随着最快的 Asimov 输入分区(而不是 Flink 的输入,因为所有分区都正常前进)前进,而慢的分区将发出具有更旧时间戳的记录。这最终会导致 Flink 将这些记录视为迟来的记录! 这可能没问题,但是在我们的作业中,我们使用特定的逻辑来处理晚到的记录,需要从 RocksDB 获取数据并生成额外的消息来执行下游的更新。这意味着,每当 Asimov 因为某种原因在几个分区上落后时,Flink 就需要做更多的工作。
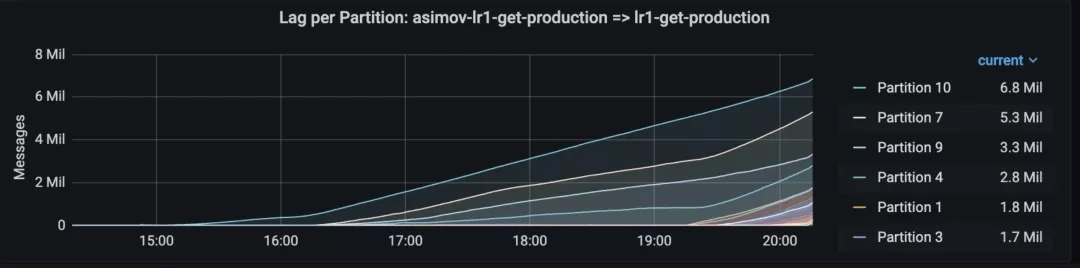
在有 128 个分区的 topic 中,只有 8 个分区累积延迟,从而导致 Flink 中的数据晚到。
我们发现了两种解决此问题的方法:
我们可以按照与它的输出 topic 相同的方式(通过 userId)对 Asimov 的输 入 topic 进行分区。这意味着,当 Asimov 滞后几个分区,Flink输入中的相应分区也滞后,从而导致水印前进得更慢:
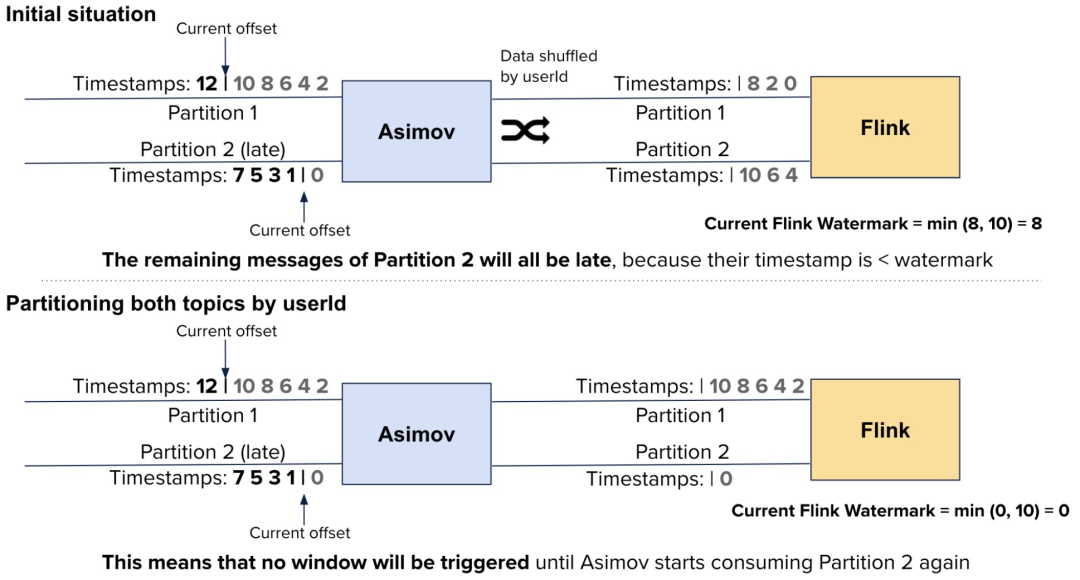
我们决定不这样做,因为如果我们在 Asimov 之前就有晚到的数据,这个问题仍然会存在,这迫使我们得以相同的方式来给每个 topic 划分分区。但这在很多情况下是不能做的。
另一个解决方案依赖于攒批处理晚到的事件:如果我们可以推迟对晚到事件的处理,我们可以确保每个会话最多产生一个更新,而不是每个事件产生一个更新。
我们可以通过使用自定义触发器,以避免出现晚到事件到达时就触发窗口,从而实现第二种解决方案。正如你在默认的 EventTimeTrigger 实现中所看到的,晚到事件在特定情况下不会注册计时器。在我们的方案中,无论如何我们都会注册一个计时器,并且不会立即触发窗口。因为我们的业务需求允许以这种方式进行批量更新,所以我们可以确保当上游出现延迟时,我们不会生成数百个昂贵的更新。
十、 避免将所有内容存储在 Flink 中
如果对状态的访问是性能需求中的关键部分,那么将它存储在Flink中绝对是值得的。但是,如果你可以忍受额外的延迟,那么将它存储在具有复制功能和支持对给定记录快速访问的外部数据库中,这将为你节省很多麻烦。对于我们的用例,我们选择将 WindowContent 状态保留在 RocksDB 中,但我们将 HistoricalSessions 数据移入了 Aerospike[11]中。由于状态较小,这使得我们的 Flink 作业更快,更容易维护。我们甚至还受益于这样一个事实:存储在 Flink 中的剩余数据足够小,可以都放入内存,这让我们无需使用 RocksDB 和本地 SSD。
十一、结尾
总而言之,使用 Flink 是一次很棒的经历:尽管有时我们无法理解框架的行为,但最终它总是有道理的。我强烈推荐订阅 Flink 用户邮件列表[12],从这个非常有用和友好的社区获得额外的提示!
作者丨Robin
翻译丨周凯波








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721