
下面我将探索的过程记录下来,一是分享下自己的经历,二是希望跟同行交流,还望轻拍。
业务背景
我公司业务场景跟市面上大部分 Flink 使用场景不太一样的地方在于以下几点:
1.表单类数据比较多
要处理的数据里,日志类型的数据很少,基本上都是表单类的业务数据,这类数据会经常变化。
2.数据更新周期长
一条业务数据可能需要几天或者几个月后,才有一条更新操作,所以不能更好地利用 Flink 的窗口,而 Flink 更适合于那种插入后很快就会有更新的情况。
3.维表数据变化时,历史统计结果数据也要跟着变
维表数据如果变了,统计结果数据都要跟着变,这也是传统业务中常见要求。
4.数据准确度要求非常高
因为是金融业务,多数场景都和金钱相关,所以要求计算出的数据准确。
以上几条都是我们传统金融业务中比较特别的场景。
另外,由于现有人员多数是精通 SQL 的开发人员,而精通 Java、Scala 开发的并不多,所以决定尽量不使用 Flink API 的方式开发 Flink 实时计算。所以自研了一个基于 Flink 的实时计算平台,主要功能有使用 Flink SQL 创建各类 Source和Sink的 Flink 表、创建 Flink 任务、提交 Flink 任务到 Yarn 上执行、任务监控等,另外也可以基于 Flink API 开发,将 jar 表上传到实时计算平台上执行。
以上是大致背景。接下来是我们具体的探索和实践过程。
实时数据处理流程
我们根据业务需求,决定把Flink作为实时计算平台。前面通过Kafka收集和传输数据,通过Flink计算平台处理好之后,把数据扔到MySQL、ES、HBase等存储落地,或者继续扔到Kafka中等待下一步计算。
以此,我们就可以画出实时数据处理的整体流程:
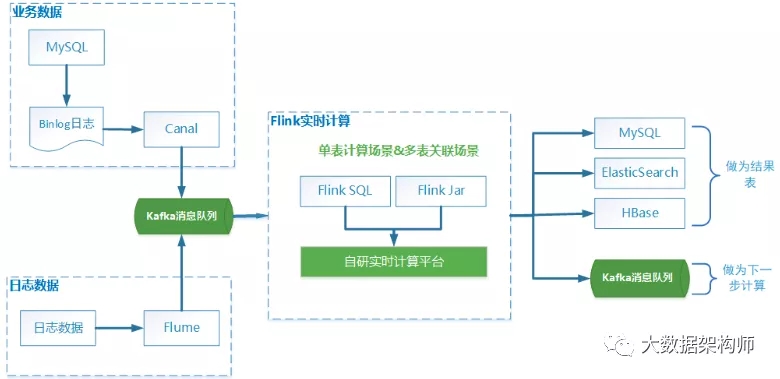
数据来源有两类:一类是业务数据,绝大部分来源于 MySQL,这部分数据通过 Canal 将 Binlog 数据实时写入 Kafka中;另外一类是少量的日志数据,这些数据通过 Flume 实时采集后,也写入 Kafka中。
在实时计算平台上,通过 Flink SQL 定义好 source 表、sink 表,指定 Kafka 来源和要写入的目标库。
或者是将开发的 Flink 程序打成 jar 包后上传到实时计算平台上。
在实时计算平台上创建任务,运行各种业务计算。
如果计算结果为最终数据,就 sink 到 MySQL、ES、HBase 等存储中用于展示,如果计算结果数据还需要进行下一步计算,那么就 sink 到 Kafka 中。
应用场景一:基于单表计算
业务背景:以金融业务中常见的还款计划表为例。比如有一张客户还款计划表,里面每一条数据是一期要还款的记录,每个单号有多行数据,主要字段有:主键、单号、期号、计划还款日期、实际还款日期、应还金额、是否逾期、还款状态等。
具体业务需求是:通过实时计算,统计出每个单号的首期月供、首期还款日期、首次逾期日期、当前期号、实际已还金额、剩余金额等统计数据,每个单号一行结果。
大体需求如下:
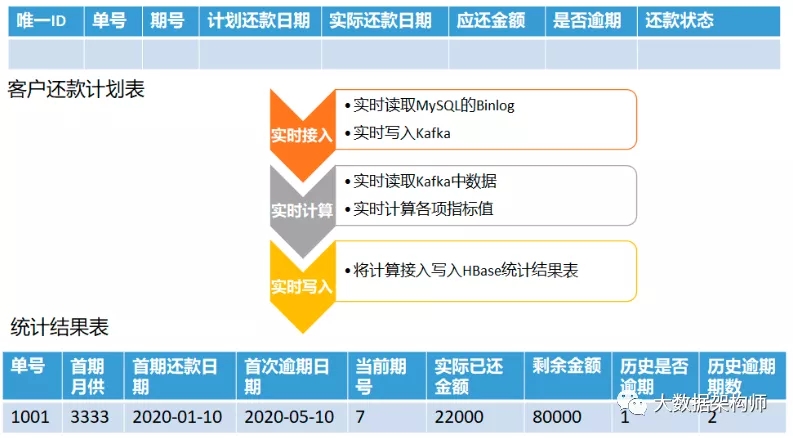
这个需求使用 Flink Java API 来实现,程序大体流程如下:

简单来说:
一共设计了两张 HBase 表:保存所有明细数据的 HBase 表、保存实时统计结果的 HBase 表;
对于 Kafka 传递过来的每一条 binlog 日志,不管是 insert 还是 update,都在窗口内保存到 Flink 的状态里,并进行合并,只保留每个单子最新一条 binlog 日志的全量字段值;
当窗口关闭的时候,从明细 HBase 表中读取相应单号的数据,和 Flink 状态中的最新数据进行合并,并将合并后的最新数据更新到 HBase 明细表中,完成实时同步;
同时对这个窗口 Flink 状态中涉及到的单号,使用最新的数据进行统计,然后将统计结果 Sink 到 HBase 结果表中。
代码总体逻辑如下:
public static void main(String[] args) throws Exception {
//定义一个Flink Stream执行环境对象
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//设置checkpoint
env.enableCheckpointing(600 * 1000);
//设置状态后端
String chkpointPath = "hdfs://ha/xxx/checkpoint";
StateBackend backend = new RocksDBStateBackend(chkpointPath);
env.setStateBackend(backend);
//设置事件时间 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//Kafka的ip和要消费的topic
String kafkaIPs = "********";
String topic = "plan_topic";
//Kafka设置
Properties props = new Properties();
props.setProperty("bootstrap.servers", kafkaIPs);
props.setProperty("group.id", "group.cyb.1");
FlinkKafkaConsumer<KafkaData<List<CustPlanSource>>> consumer =
new FlinkKafkaConsumer<KafkaData<List<CustPlanSource>>>(topic, new KafkaDeserializationScheme(), props);
//设置水位线 AssignerWithPeriodicWatermarks<KafkaData<List<CustPlanSource>>> watermarks =
new PeriodicTsAndWmarks<>();
consumer.assignTimestampsAndWatermarks(watermarks);
consumer.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<KafkaData<List<CustPlanSource>>>(Time.seconds(5)) {
@Override
public long extractTimestamp(KafkaData<List<CustPlanSource>> element) {
return element.getTs();
}
});
//传入参数,指定从哪个时间戳开始消费Kafka
long startTs = Long.parseLong(args[0]);
//设置从指定时间戳开始消费
consumer.setStartFromTimestamp(startTs);
SingleOutputStreamOperator<ResultInfo> ds = env
//指定Source
.addSource(consumer)
//筛选数据,只是保留指定表的数据
.filter(f -> f.getTable().toLowerCase().equals("plan_cust") && !f.getIsDdl())
//因为kafka里的一条数据可能包括多条insert、update、delete记录,所以binlog日志是一对多的结构
//这里进行打平,一条kafka日志输出多条记录
.flatMap(new DataFlatMap())
//根据单号进行分组
.keyBy(RepayPlanCustOut::getApply_no)
//定义窗口分配器,根据EventTime进行滚动。
.window(TumblingEventTimeWindows.of(Time.seconds(20)))
//增量聚合
//.aggregate(new CustAggregateFunction())
//延迟指定时间后,窗口才释放
//.allowedLateness(Time.seconds(5))
//对每个窗口内的所有元素执行函数操作
.process(new CustProcessWindowFun())
//指定并行度
.setParallelism(15)
//因为使用了lamada表达式,所以需要指定返回类型
.returns(new TypeHint<ResultInfo>() {
});
//输出到自定义的Sink
ds.writeUsingOutputFormat(new SinkOutFormat())
//指定并行度
.setParallelism(15);
//提交执行Flink任务,指定任务名称
env.execute("planMain-1");
}
数据初始化和数据测试的流程如下:
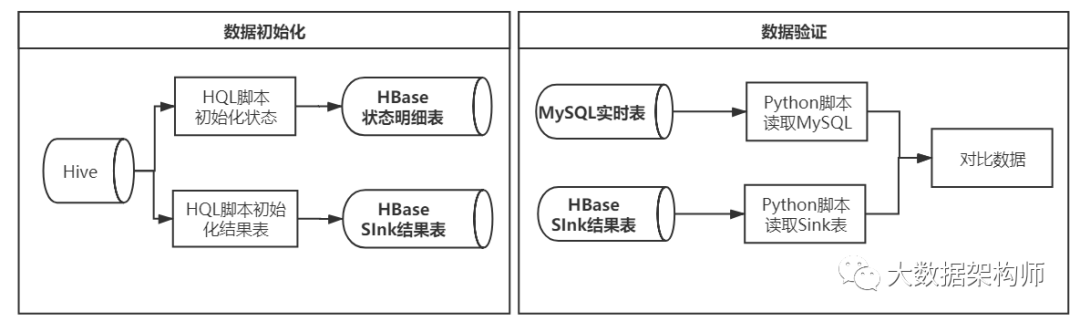
数据初始化
不像常见 Flink 实时计算场景那样,上线时不用考虑历史数据问题,我这个业务场景中,在程序首次上线或者迭代上线的时候,需要将历史数据也做初始化,初始化工作包括将历史数据同步到 HBase 明细表中、将统计结果数据初始化到 HBase 统计结果表中。
数据初始化采取的方案是:使用 Hive 中的历史数据同步到 HBase 表中。
一是创建一个 HBase Hive 外部表,将明细数据 Insert 到 HBase 明细表中;
二是使用 Hive 写同样的 统计脚本,将统计结果 Insert 到 HBase 统计结果表中;
数据测试
对于统计结果的测试,使用一个 Python 脚本,分别读取 MySQL 业务备库中的数据、HBase 统计结果中的数据,然后进行自动对比。
以上就是对于单表实时计算的介绍,下面来介绍更为复杂的多表关联场景。
应用场景二:基于多表关联计算
存储在 MySQL 业务库中的好几张业务表,包括:合同主表、客户信息表、产品方案表等等,基于这些表,需要实时进行关联,得到的结果如下图所示:
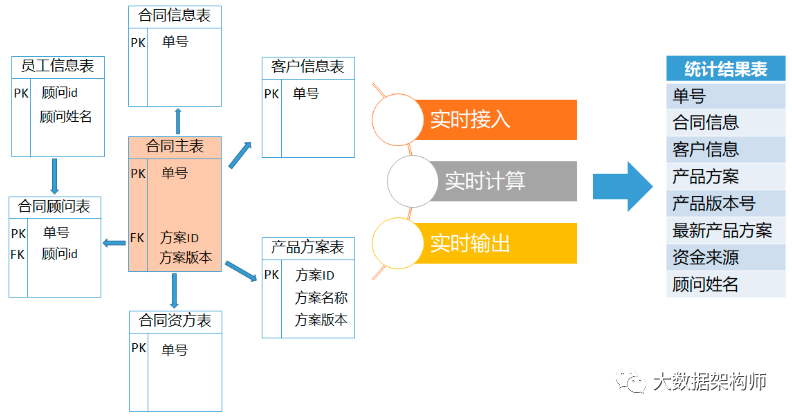
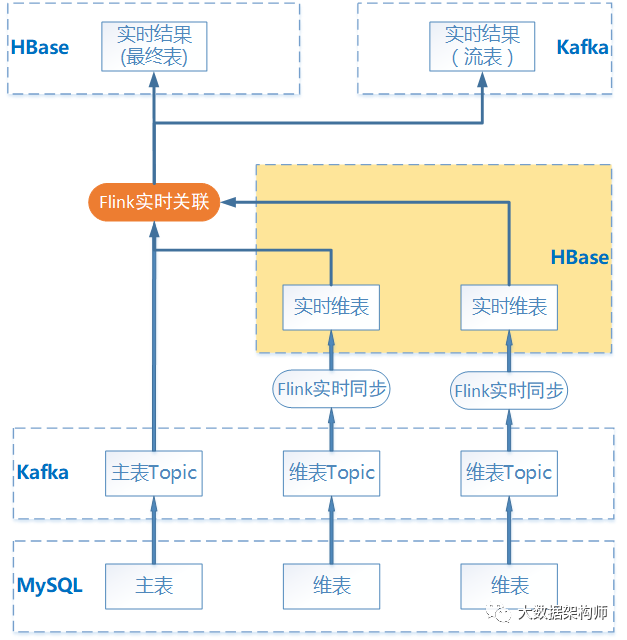
首先想到的最简单的方式就是这样,涉及到的每个从表都使用 Flink 做实时同步到 HBase 中,关联键为 RowKey。然后 Flink 对于主表的每一条 binlog 日志进行读取后,关联 HBase 中的每个从表,得到的结果写入 HBase 结果表或者传递给下游 Kafka。
这个方案优点是逻辑简单,缺点是维表数据有延迟、要创建很多 HBase表,尤其是有多种关联方式时。

方案一中使用 HBase 当维表是因为当时使用的 Flink 1.5 中不支持 MySQL 当维表,后来实时计算平台的 Flink 升级到了 1.10后,可以使用 MySQL 当维表,抛弃了 HBase 那就简单多了,程序处理流程变为了上面的样子。
只有主表实时接入到Topic。
Flink读取主表Topic数据,实时关联MySQL中维表。
将关联结果写入MySQL结果表中。
可以同时将关联结果写入Kafka,用做下一步计算。
Flink 实时计算程序直接读取 MySQL 主表和维表进行计算,这样维表的更新没有了延迟。
但是后来发现有个问题,就是当维表数据更新时,不能触发计算,不能更新结果。
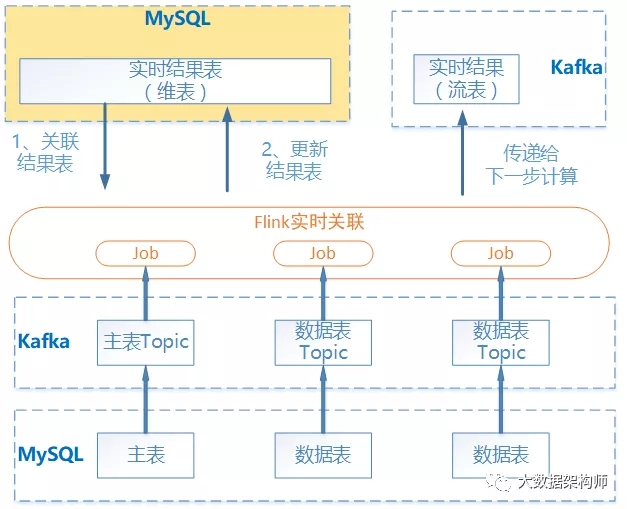
由于方案二中有个致命问题,就是由于 Flink 是事件驱动的,只有主表更新时才触发计算,而维表数据变化时,也需要更新历史老数据(这个估计是传统业务场景中的特有的要求),所以形成了方案三,如上图所示:
所有表都实时接入到 Topic;
每个表的接入都要触发计算,用结果表当维表;
将关联结果写入 MySQL 结果表中;
可以同时将关联结果写入 Kafka ,用做下一步计算。
这样主表、维表数据更新都可以触发计算,但是还有个缺点,就是结果表每次都是对全部字段读取后,再全部字段更新,效率低。
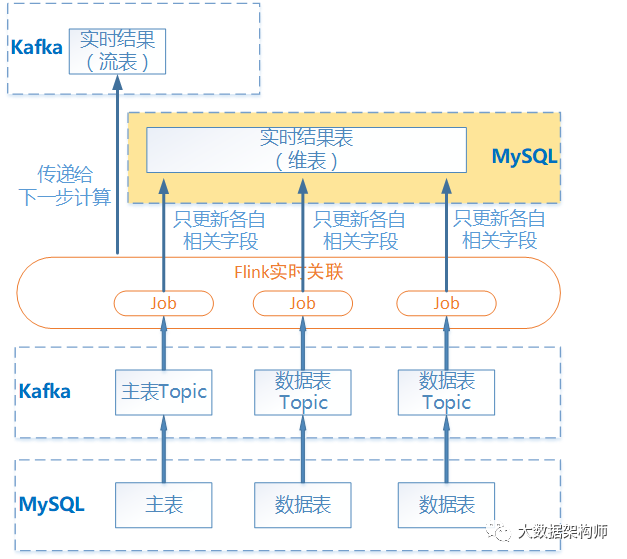
怎么解决方案三中效率低的问题呢,然后就有了方案四:
所有表都实时接入到 Topic ;
每个表的接入都要触发计算,用结果表当维表关联,更新结果表。只更新各自相关字段;
将关联结果写入 MySQL 结果表中;
这样主表、维表数据更新都可以触发计算,提高了执行效率,但是呢也是有问题的,就是步骤较多,程序复杂。
总结
Flink总体使用体感还是很舒服的,速度很快,跟其他组件对接也很顺畅,尤其是对于事件时间、有状态的计算等特性非常好用。
但是我们的一些场景也不太符合Flink的特性,比如数据更新周期特别长、数据准确的要求非常高等,所以我们也只是在部分场景进行了尝试性的探索。
对于单表计算场景,我们用canal实时读取MySQL的BinLog,经由Kafka输入到Flink中进行计算,最后写入HBase的结果表中。这个体验还是非常舒服的。
对于多表关联计算场景,我们先后尝试了4种解决方案,各有利弊。
最早的方案是所有需要关联的表都在Flink中做实时关联,然后存到HBase中。当时用的是Flink1.5,不支持MySQL当维表,所以还用Flink实时同步数据到HBase,做成实时维度。这个方案看上去简单,但是维表数据经常延迟,关联不上。
然后我们把Flink更新到1.10,直接用MySQL的表当维表,比早期的方案更简化了,维表也没有延迟的问题。但是随之发现维表更新的时候,不能触发计算。这是因为Flink是事件驱动,只有主表更新时才会触发,维表更新的时候就不动了,这个比较恼火。
因为这个缺陷严重影响业务,所以我们又做了一次尝试,把所有表都放到Kafka中,然后再到Flink中进行多表关联。这样每个表更新都可以触发计算。这样基本上需求就都能满足了。
但是上面的方案依然有缺点,结果表每次都会读取全面字段后再进行更新,效率不够高。
于是我们再次调整方案,依然是把结果表当维表关联,但是每个任务只更新自己相关的字段,这样就规避了前面说的效率问题。
整个过程看下来,Flink能解决咱的业务场景的问题,实时性也非常好。但是一旦到了某个具体的场景中,就会有无数问题等着你,解决一个,又来一个,考验的不仅是你对Flink的熟悉程度,还有遇到问题解决问题的能力,更考验架构的能力。
这不正如我们的人生么?总是有一个有一个的挑战等着我们。只要你持续精进,终归是能找到解决办法的。加油!








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721