
作者介绍
农行研发中心“数风云”团队,一支朝气蓬勃、快速成长的技术团队,始终致力于农行大数据、数据库和云计算等领域的应用实践与技术创新,探索数据赋能,勇攀数据云巅,为企业数字化转型和金融科技发展不断贡献力量。
导读
随着科技的发展,我行的零售业务系统正在进行分布式和微服务化改造,数据库也从单体部署的DB2数据库分拆到多套基于Oracle数据库的分布式系统,各系统通过ADG技术对主备库的数据进行实时同步,采用分库分表方式存储业务数据。同时采用了基于Hadoop集群的Sqoop组件来进行数据采集,从Oracle获取全量和增量业务数据,形成了一套完整的数据采集流程,实现了数据采集和数据预处理的无缝衔接。
一、建设背景
随着我行零售业务的转型升级,各业务系统逐步分拆为独立模块,各应用系统独立部署,有独立的数据库,为保证高可用,各业务系统采用数据库集群的方式存储业务数据,并采用分库分表的方式对逻辑表进行拆分。
如下图1所示,为从原单体系统获取增量业务数据的流程图,数据库采用主备方式,每天采用日切的方式将主库的数据镜像同步到备库,因此,备库是一个稳定的数据环境,能保证数据是一致的。通过在数据交换中心为每一张表设置增量提取规则(通常是SQL语句Where子句后的条件),再通过专用的数据抽取模块,获取单体数据库中每张表的增量数据,通过落地为压缩数据文件,再提供给需要消费数据的下游各个应用系统。
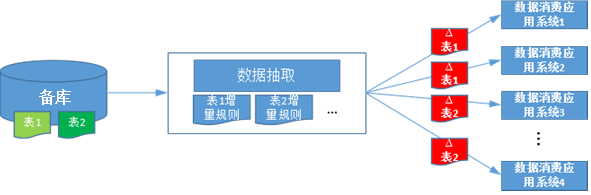
图 1 单体数据源架构的增量数据获取流程
如下图2所示,为当前单体系统逐步分拆后,各独立系统采用Oracle数据库,通过ADG技术对主备库的数据进行实时同步,相对于原单体数据源架构,这种架构存在以下的难点:
通过分库分表的方式存储同一张逻辑表数据,为方便多个下游使用,需要对逻辑表进行聚合输出;
每张表的增量数据获取过分依赖增量规则,若规则设定有误,或表设计本身存在问题,另外,业务运营过程中经常出现数据变更,将无法获取表的准确增量数据;(原来的单体数据源也存在这个问题)
主备数据库间存在实时数据同步,而下游需要获取一个一致性的数据。
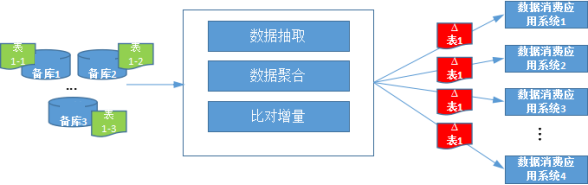
图 2 分布式数据源架构的增量数据获取流程
二、工具选型
在我行进行架构调整前,单体数据库采用的是JDBC连接SQL语句的方式采集数据,但是由于有些库表的数据量过于庞大,性能成为了数据采集的瓶颈问题,因此针对以上的需求场景,挑选了下面5种常用的导出工具进行了性能测试,性能比对情况如下表所示:

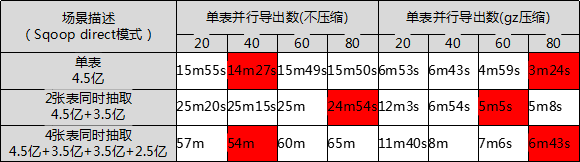
通过比对测试,发现通过Hadoop生态圈的Sqoop组件效率最高,且该组件针对Oracle和Mysql数据库有优化,支持快速模式(详见第4部分具体描述)。同时,Sqoop导出的数据直接保存在HDFS上,节省了从本地磁盘上传到HDFS的环节,便于后期预处理的数据加载。
针对Sqoop的快速模式,也对是否使用数据压缩及不同并发数进行比对,可见压缩的方式能减少网络开销,极大的提升采集效率,具体情况如下表所示:
三、技术架构
Sqoop数据采集模块,部署于Hadoop分布式计算环境,负责对分拆后各子系统的Oracle备库进行数据采集,将采集的数据文件压缩并上传至HDFS,为下游数据应用类系统提供源系统数据。

四、关键技术描述
SqoopV1.4.6针对Oracle数据库提供快速导入Hadoop的方式,参考如下:

快速模式能利用Oracle数据库自身特点,满足高效的数据导出性能,底层调用Oracle数据库的系统函数计算某张表在底层数据块的位置,在并发的直接顺序读取该表对应的各数据块,不依赖表的索引情况,因此不支持抽取条件和字段筛选。具体执行代码如下:
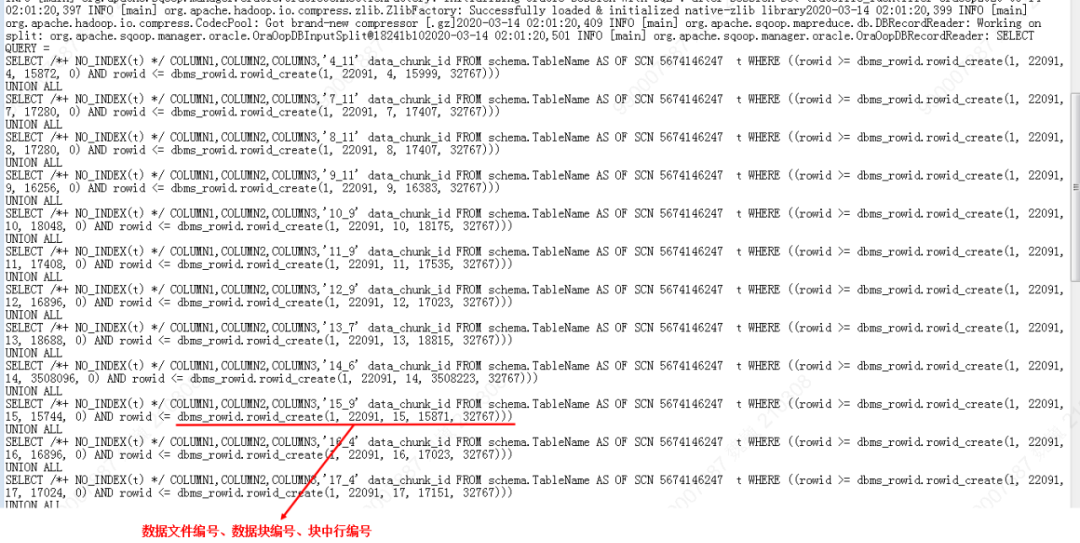
因Sqoop采集的数据库可能不是静态环境,在数据采集执行的过程中还存在表的数据更新,而有些场景需要保障数据抽取过程中数据的一致性,可以采取Sqoop提供的一致性保障,该方案底层采用Oracle数据库的闪回查询技术,需要结合表的大小配合Oracle数据库的参数调优(undo_retention等),不然会导致ORA-01555快照过旧的错误。具体如下图所示:

Sqoop direct模式需要在数据库中设置相关权限,以Oracle数据库为例:
(1)新建Oracle ADG库的Sqoop专用用户(假定为B),要求密码不能包含@,$和单双引号;
(2)Oracle抽取用户额外赋权限:
create session
alter session
select on v_$instance
select on dba_tables
select on dba_tab_columns
select on dba_objects
select on dba_extents
select on dba_tab_subpartitions
select on dba_segments
select on dba_constraints
select on v_$database
select on v_$parameter
(3)为专用用户赋予表执行权限,因库表均为产品用户(假定为A)创建,需要DBA为B用户赋予查询A所属表的权限,即:
Grant select on A.Tab_A to B或Grant select on any table to B。
另外,若有数据一致性要求,还需要为B用户赋予A所属表的闪回(flashback)查询权限,即:
Grant flashback on A.Tab_A to B或Grant flashback on any table to B。
Sqoop默认只能设置单字符作为列分隔符,行分隔符默认为换行,这样当数据内容包括分隔符时,容易造成下游获取的数据不可用。可通过以下方式进行强化:
(1)修改该表自动生成的代码,并重新编译打包
Sqoop的import命令执行时会根据每个表A的情况,自动生成A.java的文件,再编译打包至Hadoop的数据节点执行抽取任务。此过程也可以分步骤执行,即先通过codegen命令先生成A.java文件,然后对该部分代码片断进行修改,强化行和列分隔符功能,再将该java文件编译打包成.jar文件,然后再通过指定jar包的方式执行import命令,具体如下:
修改行和列分隔符,自定义列分隔符需修改toString()函数中的第2行(下图第851行,将fieldDelim修改为执行的String),自定义行分隔符可修改该函数第1220行,将指定的行分隔符添加进去。
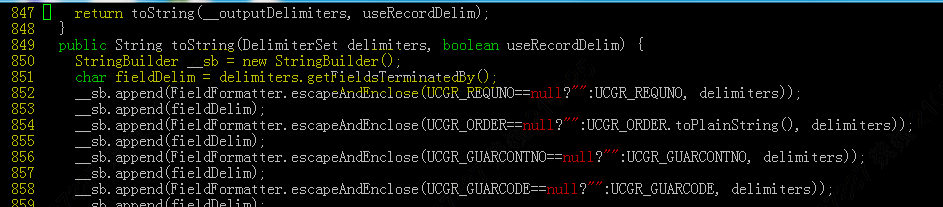
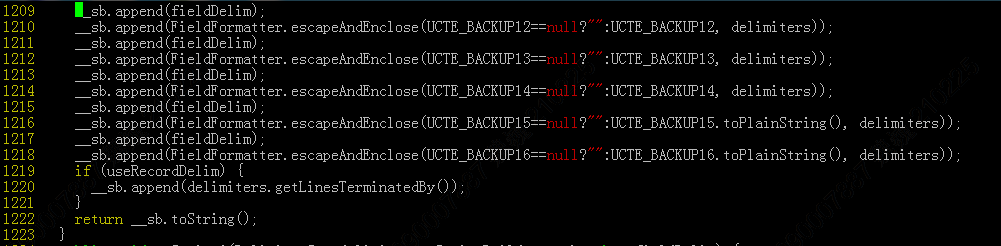
(2)import命令通过指定jar和class类执行

由于Sqoop direct模式的全量数据获取效率高(具体原理参见前面描述),因此为获取某张表准确的增量数据提供了另外一种方案,即每日获取该表的全量数据,然后通过主键关联,进行全字段比对,获取该表的技术增量数据,该方法可以达到100%的准确度。特别是当数据源的数据表没有设置更新日期字段、存在物理删除、需要多表关联、存在数据频繁数据治理等情况时,采用此方案能在原系统不做任何修改的情况下,还能获取到100%准确的增量数据。
下图是从原单体DB2数据源,切换到Oracle数据源后,选取若干大表进行了前后比对情况,平均抽取性能提升在50%以上。
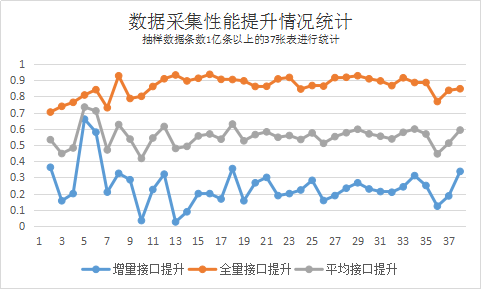
由于Sqoop的功能比较单一,并且数据采集后分片存储在HDFS上,因此方便基于Hadoop技术栈扩展数据预处理能力,我行的具体场景包括:分库分表数据合并、敏感字段内容过滤、编码字段解码、数据切分等。
五、总结
实践证明Sqoop direct模式在基于Hadoop的生态中对关系型数据库Oracle的采集效率值得肯定,解决了之前通过JDBC连接SQL语句方式采集数据的性能瓶颈,实现了采集数据与预处理功能的平滑对接,提升了下游消费数据的时效,为行内的数据平台建设奠定了基础。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721