
一、逆向处理会遇到的问题
一般业务场景如下,数据源头产生数据,进入Kafka,然后由消费者(如Flink、Spark、Kafka API)处理数据后进入到HBase。这是一个很典型的实时处理流程。流程图如下:

上述这类实时处理流程,处理数据都比较容易,毕竟数据流向是顺序处理的。但是,如果将这个流程逆向,那么就会遇到一些问题。
HBase的分布式特性,集群的横向拓展,HBase中的数据往往都是百亿、千亿级别,或者数量级更大。这类级别的数据,对于这类逆向数据流的场景,会有个很麻烦的问题,那就是取数问题。如何将这海量数据从HBase中取出来?
我们知道HBase做数据Get或者List<Get>很快,也比较容易。而它又没有类似Hive这类数据仓库分区的概念,不能提供某段时间内的数据。如果要提取最近一周的数据,可能全表扫描,通过过滤时间戳来获取一周的数据。数量小的时候,可能问题不大,而数据量很大的时候,全表去扫描HBase很困难。
二、解决思路
对于这类逆向数据流程,如何处理。其实,我们可以利用HBase Get和List<Get>的特性来实现。因为HBase通过RowKey来构建了一级索引,对于RowKey级别的取数,速度是很快的。实现流程细节如下:
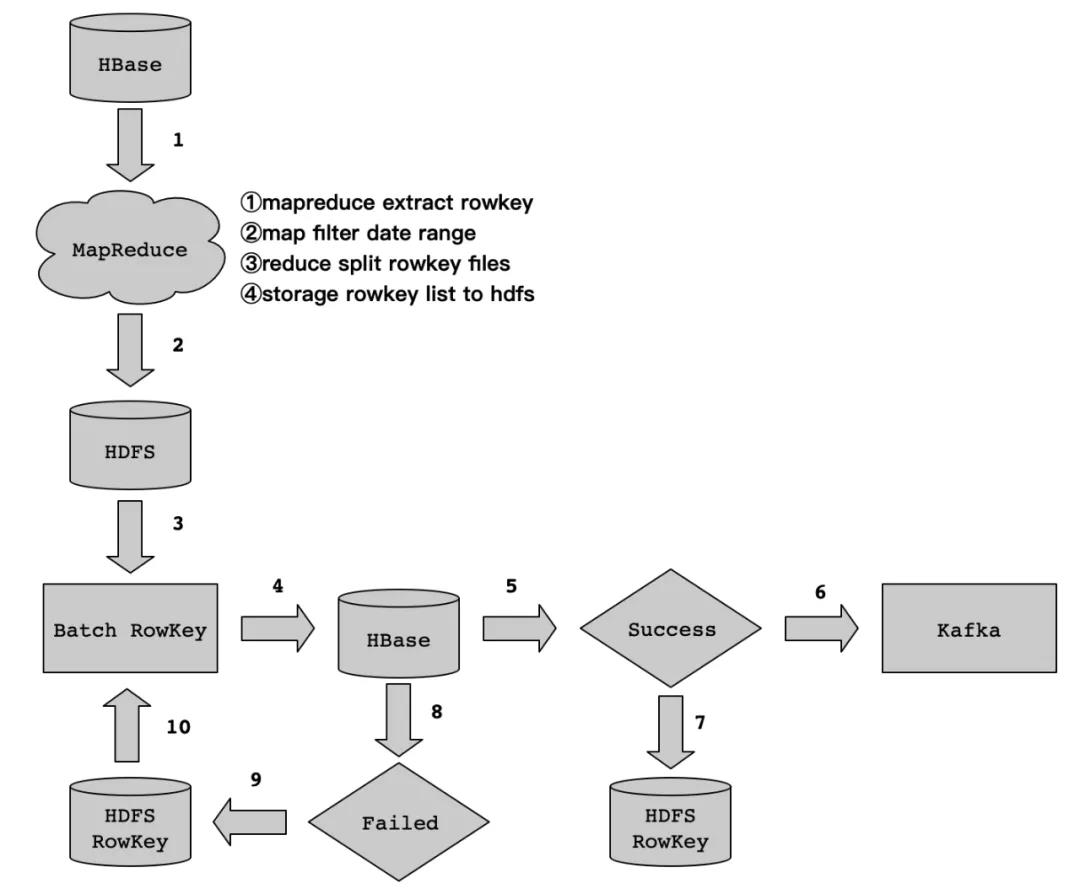
数据流程如上图所示,下面笔者为大家来剖析每个流程的实现细节,以及注意事项。
我们知道HBase针对Rowkey取数做了一级索引,所以我们可以利用这个特性来展开。我们可以将海量数据中的Rowkey从HBase表中抽取,然后按照我们制定的抽取规则和存储规则将抽取的Rowkey存储到HDFS上。
这里需要注意一个问题,那就是关于HBase Rowkey的抽取,海量数据级别的Rowkey抽取,建议采用MapReduce来实现。这个得益于HBase提供了TableMapReduceUtil类来实现,通过MapReduce任务,将HBase中的Rowkey在map阶段按照指定的时间范围进行过滤,在reduce阶段将rowkey拆分为多个文件,最后存储到HDFS上。
这里可能会有同学有疑问,都用MapReduce抽取Rowkey了,为啥不直接在扫描处理列簇下的列数据呢?这里,我们在启动MapReduce任务的时候,Scan HBase的数据时只过滤Rowkey(利用FirstKeyOnlyFilter来实现),不对列簇数据做处理,这样会快很多。对HBase RegionServer的压力也会小很多。
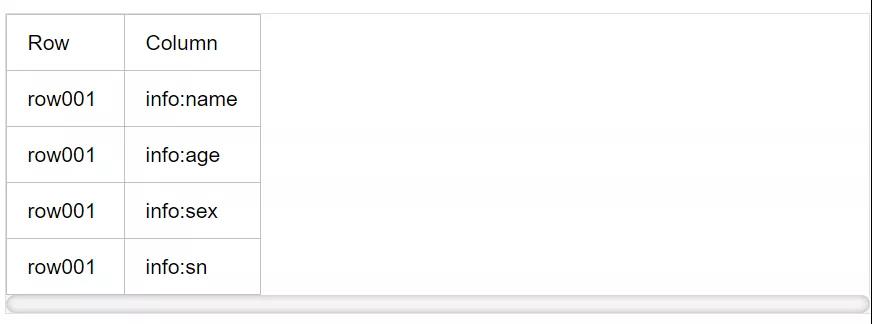
这里举个例子,比如上表中的数据,其实我们只需要取出Rowkey(row001)。但是,实际业务数据中,HBase表描述一条数据可能有很多特征属性(例如姓名、性别、年龄、身份证等等),可能有些业务数据一个列簇下有十几个特征,但是他们却只有一个Rowkey,我们也只需要这一个Rowkey。那么,我们使用FirstKeyOnlyFilter来实现就很合适了。
/**
* A filter that will only return the first KV from each row.
* <p>
* This filter can be used to more efficiently perform row count operations.
*/
这个是FirstKeyOnlyFilter的一段功能描述,它用于返回第一条KV数据,官方其实用它来做计数使用,这里我们稍加改进,把FirstKeyOnlyFilter用来做抽取Rowkey。
抽取的Rowkey如何生成,这里可能根据实际的数量级来确认Reduce个数。建议生成Rowkey文件时,切合实际的数据量来算Reduce的个数。尽量不用为了使用方便就一个HDFS文件,这样后面不好维护。举个例子,比如HBase表有100GB,我们可以拆分为100个文件。
在步骤1中,按照抽取规则和存储规则,将数据从HBase中通过MapReduce抽取Rowkey并存储到HDFS上。然后,我们在通过MapReduce任务读取HDFS上的Rowkey文件,通过List<Get>的方式去HBase中获取数据。拆解细节如下:

Map阶段,我们从HDFS读取Rowkey的数据文件,然后通过批量Get的方式从HBase取数,然后组装数据发送到Reduce阶段。
在Reduce阶段,获取来自Map阶段的数据,写数据到Kafka,通过Kafka生产者回调函数,获取写入Kafka状态信息,根据状态信息判断数据是否写入成功。
如果成功,记录成功的Rowkey到HDFS,便于统计成功的进度;如果失败,记录失败的Rowkey到HDFS,便于统计失败的进度。
通过MapReduce任务写数据到Kafka中,可能会有失败的情况,对于失败的情况,我们只需要记录Rowkey到HDFS上,当任务执行完成后,再去程序检查HDFS上是否存在失败的Rowkey文件,如果存在,那么再次启动步骤10,即读取HDFS上失败的Rowkey文件,然后再List<Get> HBase中的数据,进行数据处理后,最后再写Kafka,以此类推,直到HDFS上失败的Rowkey处理完成为止。
三、实现代码
这里实现的代码量也并不复杂,下面提供一个伪代码,可以在此基础上进行改造(例如Rowkey的抽取、MapReduce读取Rowkey并批量Get HBase表,然后在写入Kafka等)。示例代码如下:
四、总结
整个逆向数据处理流程,并不算复杂,实现也是很基本的MapReduce逻辑,没有太复杂的逻辑处理。在处理的过程中,需要注意几个细节问题:
Rowkey生成到HDFS上时,可能存在行位空格的情况,在读取HDFS上Rowkey文件去List<Get>时,最好对每条数据做个过滤空格处理。另外,就是对于成功处理Rowkey和失败处理Rowkey的记录,这样便于任务失败重跑和数据对账。可以知晓数据迁移进度和完成情况。同时,我们可以使用Kafka Eagle监控工具来查看Kafka写入进度。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721