
华智,携程高级研发经理,现负责数据仓库技术架构、性能优化、数仓规范制定、数据模型设计以及数据应用开发。
随着大数据技术的飞速发展,海量数据存储和计算的解决方案层出不穷,生产环境和大数据环境的交互日益密切。数据仓库作为海量数据落地和扭转的重要载体,承担着数据从生产环境到大数据环境、经由大数据环境计算处理回馈生产应用或支持决策的重要角色。
数据仓库的主题覆盖度、性能、易用性、可扩展性及数据质量都是衡量数据仓库解决方案好坏的重要指标。携程机票部门数据仓库也在不断摸索向着这些目标砥砺前行。
携程机票部门的数据仓库建设主要基于公司公共部门的大数据基础环境及数据调度平台,辅以部分自运维的开源存储引擎和基于开源组件二次开发的数据同步工具和运维工具。
机票部门的数据仓库源于2008年,当时生产环境数据落地主要使用SQLServer,数据仓库处理的目标数据体量不大,因此选择的SQLServer、Informaticas、Kettle这样的数据仓库方案,数据模型设计及报表定制使用SAP的商用平台BO。
随着机票业务系统的日益复杂,特别是生产环境引入消息中间件Kafka存储日志数据后,这套方案不可扩展性的缺点日趋明显,SQLServer的存储和计算能力很大程度上限制了数仓数据的主题覆盖度及性能。
在2014年,公司公共部门hadoop集群部署上线,并且引入了zeus调度平台及DataX同步工具,各个BU的数据仓库开始逐步转为基于Hive建设。
随着生产业务对实时监控、流量回放的需求增强,2016年机票部门部署了ElasticSearch,用以实时落地从Kafka同步的各个主流程服务日志,并通过统一的交易标识 (transactionID) 串联用户的一次完整的搜索、下单等行为,用于生产排障和流量回放。基于Hive的搜索性能一直被广泛诟病,特别是针对adhoc查询,机票部门在2016年调研并部署了Facebook开源的基于内存和Pipeline的查询引擎Presto,在没有享受到local数据获取的前提下,查询性能较原生的Hive引擎或者Spark引擎都有很大的提升。
在2018年,为了支持数仓数据的可视化运营平台,我们先后引入了ClickHouse和CrateDB作为后台的存储和查询引擎,特别是引入CrateDB以后,亿级体量的表四个维度的聚合耗时P90下降到了4秒。
实时数据处理技术也经过了Esper、Storm、Spark Streaming和Flink的迭代,并慢慢收敛到Flink。总体的技术演进历史如图1所示。

图1 数仓技术演进历史
生产环境的数据可以大致分成三类:
1)业务数据,主要存储在MySQL和SQLServer,在这些关系型数据库里面有数以万计的表承接着各种生产服务的业务数据写入;
2)基础数据,也是存储在MySQL和SQLServer中,生产应用时一般会建立一层中心化缓存(如Redis)或者本地缓存;
3)日志数据,这类数据的特点是”append only”,对已经生成的数据不会有更新的操作,考虑到这类数据的高吞吐量,生产环境一般会用消息队列Kafka暂存;
数据仓库在实施数据同步时,会根据需求在实时、近实时以及T+1天等不同的频率执行数据同步,并且在大数据环境会用不同的载体承接不同频率同步过来的数据。在携程机票,实时同步的目标载体是ElasticSearch、CrateDB或者HBase,近实时(一般T+1小时)或者T+1天的目标载体是Hive。
从生产的数据载体来讲,主要包括DB和消息队列,他们的数据同步方案主要是:
1)生产DB到Hive的同步使用taobao开源的DataX,DataX由网站运营中心DP团队做了很多扩展开发,目前支持了多种数据源之间的数据同步。实时同步的场景主要在MySQL,使用DBA部门使用Canal解析并写入至消息队列的bin log。
2)从Kafka到Hive同步使用Camus,但是由于Camus的性能问题及消费记录和消费过期较难监控的问题,我们基于spark-sql-kafka开发了hamal,用于新建的Kafka到Hive的同步;Kafka实时同步的载体主要是ElasticSearch或者CrateDB,主要通过Flink实施。
生产数据被同步数据仓库后,会在数仓内完成数据清洗、信息整合、聚合计算等数据扭转流程,最终数据出仓导入到其它载体,这一系列的流程调度由公司DP团队运维的调度平台Zeus完成。
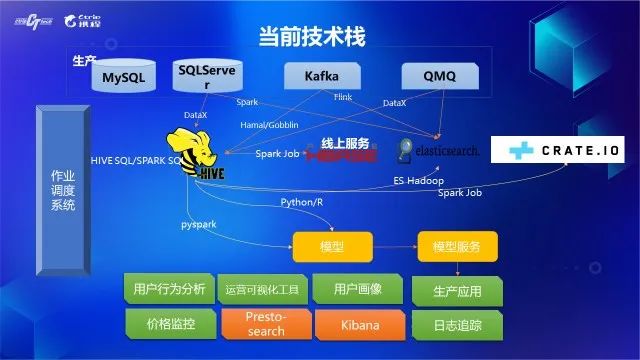
图2 携程机票数仓技术栈
当前机票部门的数据仓库建设主要基于离线数据,一方面跟OTA销售产品不属于快消品相关,实时当前并不是刚需;另一方面实时处理场景下需要对计算资源、存储资源稳定性有更高的要求,保持数据一致性的代价很大。结合两方面,如果业务对实时需求不高就铺开做实时数仓,ROI很难达标。
当然,随着携程业务体量的增长,数据使用方对数据实时性要求日益增高,我们团队在2020年也会探索实时数据仓库的实施方案,并在一两个重要的数据主题域上先行试点。
从团队职能上来讲,数据仓库团队需要负责从生产环境同步数据,在内部完成各层级的扭转计算,参与所有数仓流程及报表的运维,并基于数仓公共数据层和应用数据层数据开发相关应用。
为了保持数仓数据主题覆盖足够全面,我们部门几乎将所有生产表和Kafka topics都同步到了Hive。以下会对同步最常见的两种场景DB->Hive和Kafka->Hive相关的实践做介绍。
1)DB同步到Hive
特别对生产表到Hive的同步,人工配置脚本的方式显然不能处理数以万计的表,因此需要一个自动化的同步方案。自动同步方案需要不仅仅要解决自动创建表脚本、创建对应的同步脚本问题,还需要在当表结构发生变更的时候,能够自动地感知表结构的变化,并且修改表结构和对应的同步脚本。
DB到Hive同步需要依赖两个数据源,1)Schema表的元数据信息,简单地包括各个字段信息、字段类型及主键定义;2)统计数据,它主要描述的是这个表在数据产生后有没有UPDATE和DELETE,这个决定着后续表的分区方式。
对业务型数据,一条数据生成后可能会有Update,因为在数仓里绝大部分场景需要用到数据的最新状态,所以我们会用一个分区存放所有历史数据的最新状态,这类表我们称之为历史切片表。对日志型数据,生产上数据产生后就不会有任何修改,我们会选择使用增量分区,每个分区会放当天的增量数据。对基础数据,整个表的数据增加、更新的频率都非常低,在ods层我们会每天全量同步一份到最新数据分区,并且会建立一个无分区的下游维表,将数据状态为有效的数据放到这张下游无分区维表中方便流程使用。
有了上述这两个数据源以后,我们会根据DBA Schema服务返回的元数据信息生成Hive表的脚本,并调度执行生成新的Hive表,再依据统计数据决定表的分区方式,进而生成对应新建表的同步脚本。当表创建或者表结构发生变更的时候,通过Schema服务两天输出的比对,我们会发现表结构的变更并映射到对应Hive表结构变更,同时可以改变对应的同步脚本。还有一种思路是可以通过DB发布系统的日志,获知每天DB创建、表创建以及表结构变化的增量。

图3 生产DB到Hive的同步
有一个坑点就是生产物理删除,如果出现了物理删除并且需要在Hive表里将删除数据识别并标记出来,当前可能需要通过全量同步的方法(考虑到从生产环境取数的代价,全量同步业务主键字段即可)解决,特别对SQLServer。因此可以跟生产的开发协商尽量使用逻辑删除,这样数仓对删除数据的感知代价会小很多。
2)Kafka同步到Hive
当前我们非实时同步主要在使用Linkedin很久以前的一个工具Camus,当然DP团队经过优化和企业本地化二次开发。但从使用感受来看,Camus会有如下可能不足的地方:
基于mapreduce,mapreduce在yarn集群上抢占资源的能力较弱,在资源竞争高峰会有同步变慢的情况发生;
消费记录存储在HDFS各个文件里,这样对消费记录的获取和针对消费过期的监控都很不方便;
Kafka Topic和Hive表的血缘关系获取不方便;
因此,我们基于spark-sql-kafka开发hamal,旨在解决如上痛点并且让配置更加的简洁。实现的过程大概包括,spark-sql-kafka会根据输入的任务从Kafka各个Partition消费出payload数据,对每条payload执行解编码、解压、magic code等操作,此时会将payload数据转化成json字符串,这个json字符串可以直接作为一个字段写入到Hive表里,也可以根据事先配置提取出对应的节点和值作为列和列值写入到Hive中,甚至可以通过Json的Schema推断出Hive表结构,并将Json各节点对应写到Hive表的各列中。
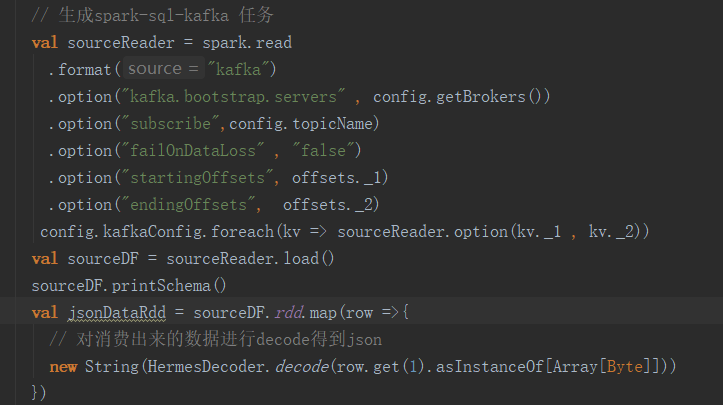
图4 转化为json字符串RDD代码示例
如果选择推断的模式,实现的时候可以使用sampling的方式,类似spark jsonRDD第二个参数,比如说0.001,Hamal可以直接指定采样数据条数,从Kafka topic中拉取出来,通过jsonRDD推断出StructType,并映射成Hive建表语句。对于建好的表,通过表的字段匹配获取数据,最终写入Hive表,最后会提交消费记录到一张Hive的ConsumerRecord表里面。这样其实基于这个表,我们既可以获取Kafka topic和Hive表的血缘,也可以方便地监控每次同步的数据量。
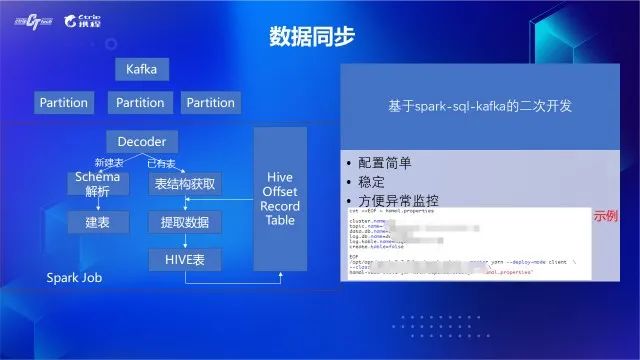
图5 Kafka同步至Hive Hamal设计
分层设计主要参考公司推行的数据规范,将数据仓库的流程分成了生产镜像层(ods)、中间层(edw)、公共数据层(cdm)及应用数据层(adm)。在中间层对ods表做异常数据剔除、NULL值处理、枚举值统一等数据清理和绑定维表信息工作,在公共数据层对中间层表进行进一步的整合,丰富表主题的维度和度量,一般以宽表的形式呈现,用以后续的adhoc取数、报表。
根据机票本身的业务特点,我们将数据划分成流量、产量、收益、生产KPI、业务考核等几大主题域,对数据表的业务分类和有效管理有重要意义。
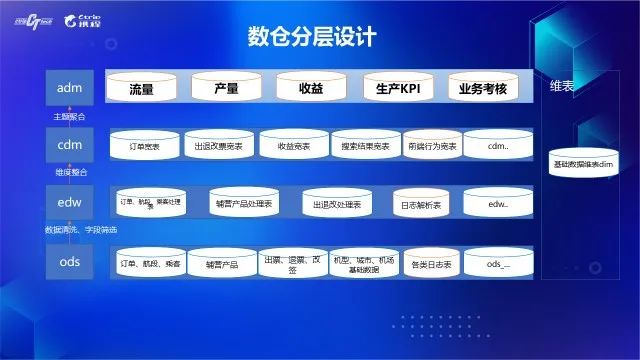
图6 数仓分层设计
数据在同步至数据ods层后,产品经常会提的一个需求是将ods层某个含报文字段的表按照字段设计展开,如果要支持此类需求,数据开发就需要了解生产上这个表各个字段含义及报文字段的契约定义,而这些对应表的写入开发非常熟悉。因此,为了提高整体的工作效率,我们开发了一套数据解析框架,对业务开发封装了大数据组件的API调用及相关参数调整,让业务开发更高效地完成熟悉的单条数据解析开发。

图7 数据解析框架
数据仓库拥有所有生产表的镜像表、数以万计的生产数据同步流程、数据扭转流程以及后续报表,对如此规模的数仓实体的管理和运维需要一个不断迭代的系统支持,从而可以大幅度提高数据工程师的效率。
我们根据数仓建设中遇到的一些费力度较高且需要重复做的操作,开发了一套运维工具集合,目前还在持续迭代中。运维工具集功能主要包括数据实体通用搜索,报表收件人批量变更,维表导入,Oncall录入,脚本模板生成,序列化与反序列化等等。工具开发难度不大,但对提高效率的帮助很大。
对庞大的数据仓库实体建设完善的数据质量监控体系,光靠人工one by one设置检验规则是不够的,需要对几乎所有的实体建立相应的监控,并且不能给大数据集群带来很多额外的计算代价。当这样的覆盖面很广的监控完善后,配合着元数据信息,就有可能在故障的Root Cause点第一时间发现故障,并可以清晰地知晓故障的影响范围以及故障恢复的流程优先级调度。
因此,建立完善的数据质量体系需要完善元数据管理,建立轻量的覆盖面广的质量监控,并且对特别重要的流程,需要增加额外的业务相关校验。
在生产环境和大数据环境存在多种实体,这些实体包括应用、各类表(如SQLServer、MySQL、MongoDB的表等)、消息队列topic、ElasticSearch的index、Hive的表等等,这些实体相互关联,共同支撑着线上的系统,线下的分析。对这些信息的治理,实体的元数据管理至关重要。
在数仓体系中,元数据主要包含基础信息、血缘关系以及标签。基础信息跟数据表相关,具体包括表的字段、存储、分区类型等;血缘会涉及到各类的实体,表、流程、报表、邮件推送等,这些实体之间存在着上下游调用与被调用关系,成体系地管理好这些实体之间的关系,可以清晰地了解到数仓边界,使得对故障的Root Cause追溯以及该Root Cause带来的影响面评估非常便捷。标签是对实体的分类描述,如层级是属于哪一层,安全是否有涉密,重要等级,是否有非常重要的流程在上面,业务标签是属于订单、前端还是订后。
数据质量的问题其实一般可以在流程执行的日志中看出端倪,因为人工排查故障的时候,除了常规通过SQL查询验证表的增量、业务主键、某些字段值是否正常,另外一个有效手段就是分析运行日志。
从运行日志中可以获取以下信息,流程的开始时间、截止时间流程执行时间、完成状态、每天增量的字节数、增量条数,引擎执行的参数,在用Spark或者MapReduce执行时消耗资源的情况等等一系列特征。通过对各类计算引擎产生日志的分析,可以获得各类引擎下记录日志数据的pattern,从而提取出相关的特征信息。遇到特殊的流程或者引擎,可以借用其他手段补齐特征数据,如用SQL,用Hadoop的命令。

图8 数据质量相关特征
这是我们简单的一个日志输出,第一张是Spark的执行日志,下面一张是MapReduce的执行日志。
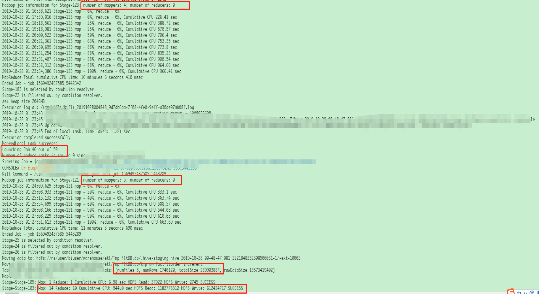
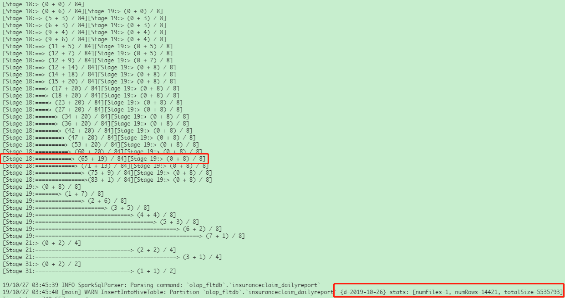
图9 MR和Spark引擎执行日志示例
有了数据质量特征提取的逻辑,实时流程异常发现可以如下实施:我们可以将质量特征数据计算分成两块,一块是实时的针对单个流程日志的解析出相关特征,一块是离线的基于历史特征数据的统计。我们从消息队列中消费实时获取执行完成的流程id和actionid,通过运维团队提供的详情日志查询接口获取完整日志,通过特征解析逻辑,解析出实时的流程质量相关特征,匹配历史数据,应用规则。当满足异常规则,可以通过元数据信息中的血缘判断影响的范围,推送告警信息。
图10 实时流程异常监控实施方案
携程作为平台方,对机票价格没有定价权,价格由产品提供方来提供。在每年航班计划换季的时候,产品提供方会有一小部分概率将价格录入错。错误的运价,特别是很低的错误运价会让航司或供应商蒙受超大的损失。本着公平交易的原则,携程作为销售平台,做了机票价格监控系统。上线至今,发现了数十起价格异常事件。
在生产的消息队列中,我们落地了用户查询返回的所有航班组合和价格信息,数据仓库完成近实时同步,将数据解析处理成异常价格相关特征集,每天的增量在百亿级别。我们从Kafka实时消费两类日志数据,一类是查询日志,一类是下单日志,建立匹配,建立规则集发现可疑的低价交易标识,并且进一步监控跟交易标识是否进入下单流程。当某个疑似异常特征带来的订单超过一定阈值时,系统会对这疑似异常特征对应的查询进行自动禁售。
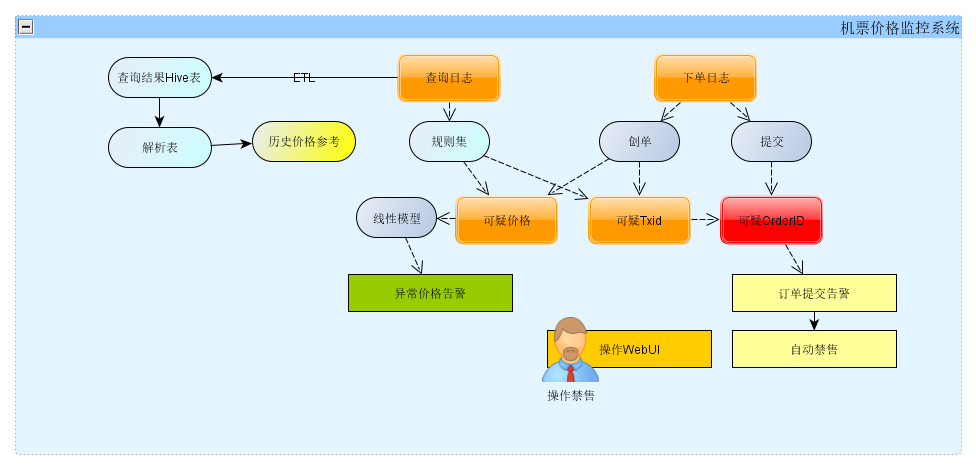
图11 价格监控系统
一套完整的数据仓库实施方案应该包括但不局限于上面介绍的数据同步方案、数据存储方案、数据规范、元数据建设、数据质量体系、运维工具等,每个实施团队应该根据面临的实际情况选择针对每个点的具体技术方案。
携程机票数据仓库团队也正朝着建设全面、规范、易用、高效、精准的数仓路上探索前行,当前在数据同步、数仓数据扭转以及出仓应用方面的实践方案还在随着需求的变化而迭代。接下来,我们团队会着重在数据仓库规范彻底落地以及实时数仓实施这些方向上努力。
近年来大数据技术发展迅速,并且不断推陈出新来适应新时代的海量数据处理需求。但随着技术的更迭,每次演进都需要耗费大量人员的精力与时间,以往的数据治理模式已经摇摇欲坠,此时DataOps应运而生。来和Gdevops全球敏捷运维峰会北京站一起看看联通大数据背后的DataOps体系建设:
《数据智能时代:构建能力开放的运营商大数据DataOps体系》中国联通大数据基础平台负责人/资深架构师 尹正军
本次研究目标是让大家了解联通大数据背后的DataOps平台整体架构演进,包括数据采集交换加工过程、数据治理体系、数据安全管控、能力开放平台运营和大规模集群治理等核心实践内容。那么2020年9月11日,我们在北京不见不散。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721