
本文根据严锁鹏老师在〖2019 DAMS中国数据智能管理峰会〗现场演讲内容整理而成。

(点击文末链接可获取完整PPT)
讲师介绍
严锁鹏,奇虎360大数据架构运维专家,具有10年基础架构与大数据开发经验。2013年加入360商业化团队,负责消息中间件开发与运维,同时涉及大数据架构、微服务架构、实时计算平台、机器学习平台、监控系统等基础设施建设,致力于为商业化团队提供稳定高效的基础服务。
大家好,我是来自360商业化的严锁鹏,今天我会向大家分享如下内容:
分享概要
1、消息队列选型
2、Kafka在360商业化的现状
3、Kafka client框架
4、数据高可用
5、负载均衡
6、鉴授权与ACL方案
7、Quota机制
8、跨IDC的数据同步
9、监控告警
10、线上问题及解决方案
一、消息队列选型
当时主要考虑以下几个维度:社区活跃度,客户端支持,吞吐量。对比几个系统下来,觉得Kafka比较符合我们的要求。现在有一个新的开源系统pulsar,我觉得也可以尝试一下。


Kafka性能和吞吐都很高,通过sendfile和pagecache来实现zero copy机制,顺序读写的特性使得用普通磁盘就可以做到很大的吞吐,相对来说性价比比较高。
Kafka通过replica和isr机制来保证数据的高可用。
Kafka集群有两个管理角色:controller主要是做集群的管理;coordinator主要做业务级别的管理。这两种角色都由Kafka里面的某个broker来担任,这样failover就很简单,只需要选一个broker来替代即可,从这个角度来说Kafka有一个去中心化的设计思想在里面, 但controller本身也是一个瓶颈,可以类比于hadoop的namenode。
CAP理论相信大家都有了解过,分布式系统实现要么是CP,要么是AP。Kafka实现比较灵活,不同业务可以根据自身业务特点来对topic级别做偏CP或偏AP的配置。
支持业务间独立重复消费,并且可以做回放。
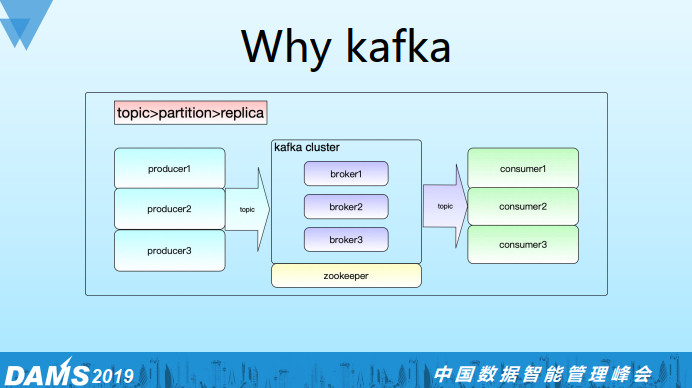
这个是Kafka的简要架构,主要分为生产端,broker端,还有消费端。日志有三个层次:
第一个层次topic;
第二个层次partition(每个partition是一个并行度);
第三个层次replica(replica表示partition的副本数)。
二、Kafka在360商业化的现状

目前集群有千亿级数据量,集群有100多台万兆机器,单topic的最大峰值60万QPS,集群的峰值大概在500万QPS。

我们的物理机配置 24Core/10G网卡/128G内存/4T*12 HDD,值得说一下的是我们采用了万兆网卡加普通磁盘4T*12的配置,测下来磁盘吞吐和网络吞吐是能够匹配上的, 再者考虑到我们的数据量比较大,SSD盘没有特别大的且成本比较高。
磁盘的组织结构我们用的是JBOD,RAID10也是很好的方案(磁盘成本会翻倍)。我们目前的Kafka版本是1.1.1,推荐大家部署0.11以上的版本会好一些,这个版本对协议做了很多优化,对于后续的2.x版本都是兼容的。
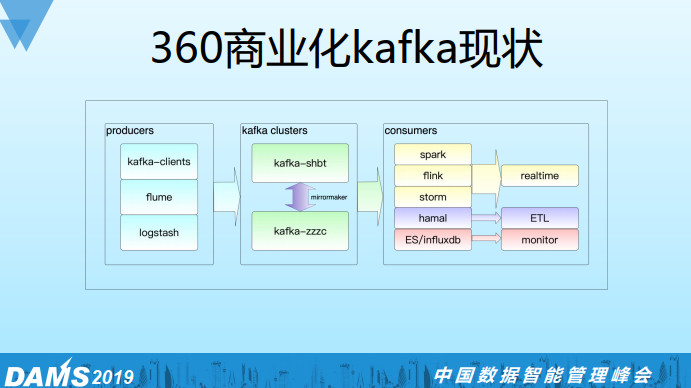
这个是我们Kafka上下游相关的组件,生产端主要是各种Kafka clients/实时服务/flume/logstash。
消费端分为实时,离线(ETL),监控三部分。实时有spark/flink/storm等主流框架, 离线部分我们基于flink自研了一个统一落地框架hamal,从Kafka消费一遍数据就可以落地到多个下游系统(hdfs、hbase、redis等),可以避免重复消费。还有部分是监控的需求,我们把ES/influxdb相关的日志打到Kafka,然后再消费出来通过grafana展示,但目前我们已经切到prometheus上了。
三、Kafka client框架
为什么要做这个框架呢?之前有很多的业务部门用裸API自己去实现Kafka client的逻辑,但是会有很多问题,有一些异常情况会catch不全,我们做这个框架是想把所有的细节屏蔽掉,然后暴露出足够简单的接口,这样可以减少业务犯错的可能性,我们要确保极端的情况下比如网络或集群异常时的可用性,如果网络或集群不可用,数据会先落到本地,等恢复的时候再从本地磁盘恢复到Kafka中。

我们实现了两个框架:LogProducer和LogConsumer。LogProducer支持at least once;LogConsumer支持at least once和exactly once两种语意,其中exactly once需要业务去实现rollback接口。
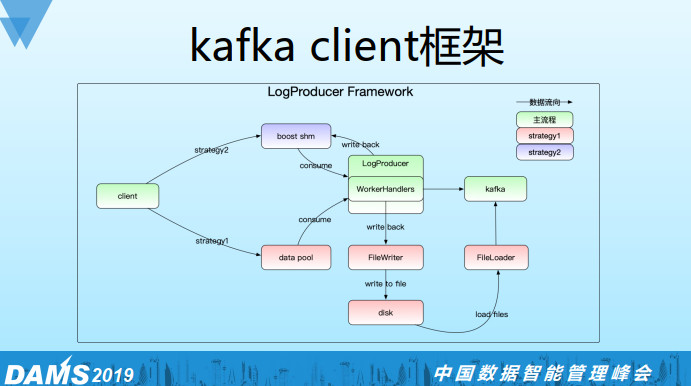
LogProducer框架的大体思路是通过内存队列将日志发送到Kafka,当Kafka或网络不可用的情况下会写本地磁盘,同时会有一个线程去实时检测Kafka或者网络的可用情况,如果恢复就会加载磁盘日志并发送到Kafka。我们还支持一种共享内存的策略来代替内存,使用共享内存是为了减少重启过程中日志的丢失数。
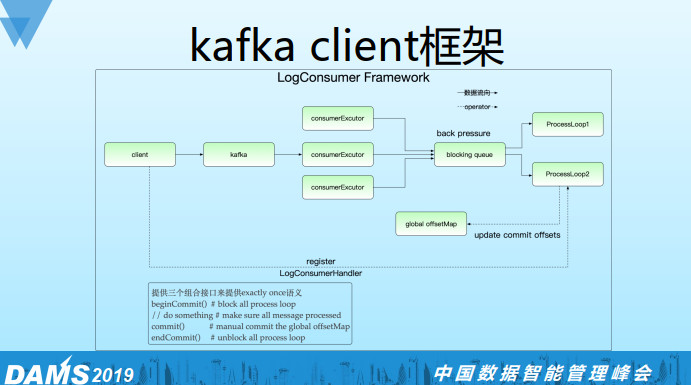
LogConsumer的框架实现,通过blocking queue将consumer线程和worker线程解耦,因为现实情况是消费逻辑很简单,但是处理逻辑会很复杂。这样就可以对consumer线程和worker线程做不同的配置,同时通过blocking queue还可以实现反压机制。比如worker处理不过来了,这时候blocking queue就会满,反压到consumer线程会停止消费。
同时我们在worker线程接口里面会提供接口让用户提交到global offsetmap, 如上图我们提供三个组合接口,如果在业务处理与commit中实现了业务端rollback逻辑, 那么就是exactly once语义,默认是at least once语义。
四、数据高可用
之前讲过Kafka本身提供replica+isr的机制来保证数据高可用,但我们觉得这个可能还不够,所以我们还要支持rack aware。比如replica=3的情况,确保三个副本在不同的物理rack上,这样我们最多能容忍两个物理机架同时出问题而数据仍可用,我们rack aware方案是与负载均衡方案一起做掉的,具体后面会讲。
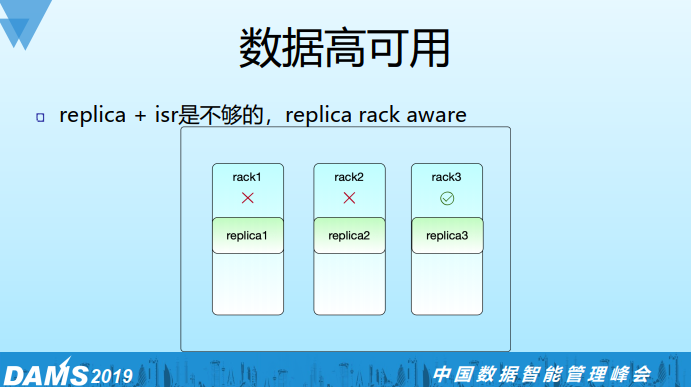
值得注意的是Kafka官方也支持rack aware,通过在broker端配置broker.rack参数可实现,但有一个限制,必须为每个rack分配数量相同的brokers,否则会导致replica分配倾斜,实际情况是IDC的rack是很多的,分配到的物理机分布也可能很随机,一个可以参考的解决思路是采用虚拟rack group的概念,比如维护3个虚拟rack group,申请到的物理机加入到这3个group中,并确保rack group间分配的物理机数量一致,当然rack group间物理机不应存在有相同物理rack的情况。
五、负载均衡
Kafka的负载均衡功能在confluent商业版本才支持,负载均衡本质上来说是replica分配均匀问题,我们一开始想通过经典一致性hash来解决如下图:
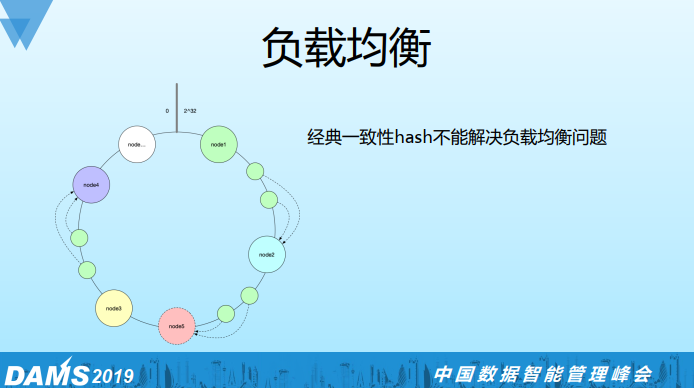
然后我们发现经典一次性hash不能满足我们的需求,比如要加一个节点node5,只能分担节点node2的部分负载,不能做全局节点的负载均衡
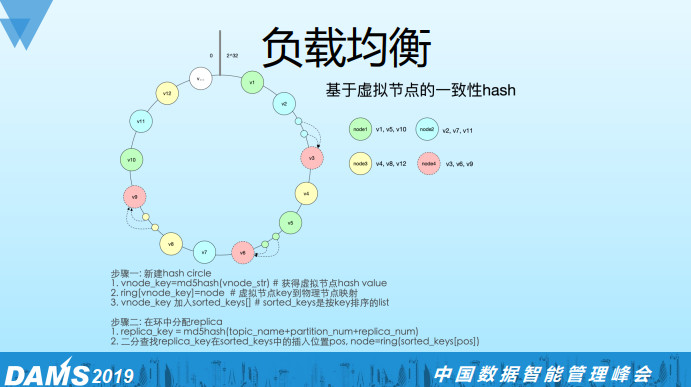
于是我们基于虚拟节点的一次性hash的算法实现了一个方案,如图所示:相同的颜色对应同一个物理机,hash环上的都是虚拟节点。这里有四个物理节点,其中node4是我们新加的节点。通过虚拟节点可以把物理节点的负载足够均衡地分散出去,所以当我把node4加到hash环上的时候,分担了所有物理机的负载。
算法实现的步骤分为两个大的步骤:
1. 新建hash circle:通过vnode_str(比如hostname-v0)做一个MD5的hash,得到虚拟节点的vnode_key,再用ring字典来保存虚拟节点到物理节点的映射,同时将vnode_key加入到sorted_keys的list中。
2. 在hash环中分配replica: 将(topic_name + partition_num + replica_num)作为key用相同的MD5 hash算法得到replica_key, 接着二分查找该replica_key在sorted_keys中的position, 最后用ring字典来映射到物理机node, 至此replica分配完成。

我们基于这个算法解决三个问题:
1)添加物理节点只需迁移很小一部分数据;
2)对不同配置的物理机做权重设置,可以支持异构集群的部署;
3)实现replica的rack aware,物理节点上面会有rack信息,在为replica分配物理节点的时候会记录已经分配的rack信息,如果有重复的情况,就会把vnode_key找到position的位置+1找下一个物理节点,我们会确保三个replica的物理rack一定是不一样的(假如replica=3)。
Leader balance
这是一种快速且成本低的负载balance方法,因为Kafka只有leader提供读写,所以通过leader切换是可以达到负载切换的效果的,由于只是leader切换不涉及数据同步,因此这个代价是比较小的。
disk rebalance
这个feature需要Kafka1.1.0版本之后才支持,Kafka提供了一些脚本和API可以做balance操作, 其本质也是生成replica plan然后做reassign。
六、鉴权、授权和ACL方案
如果是新集群比较推荐基于SASL的SCRAM方案,实施起来比较简单。如果老集群想中途施行鉴权授权机制会比较困难,需要推各个业务去修改配置,同时切换的过程也很容易出问题。
下面介绍下我们实现的一个白名单机制来解决老集群的问题,首先将老业务加入到白名单中,让新业务通过工单流程来申请topics和consumers两种资源权限并加到白名单里,定期监测非法(没有走工单)topics,consumers资源,同时将这些资源都deny掉,这样就收紧了topics和consumer读写权限的口子,同时原有业务不会有任何影响。

七、Quota机制

Quota主要是为了解决多个业务间资源抢占问题。Quota类型有两种:一种是限制网络带宽,一种是限制请求速率(限制CPU)。我们对业务做了三个优先级设置:高,中,低优先级,高优先级不做限制,中优先级可容忍lag,低优先级极端情况可停掉,通过工具可以批量限制某个优先级的所有业务,可以确保高优先级业务及集群的安全。
八、跨IDC的数据同步

首先我们为什么要做跨IDC的数据同步?没做这个同步之前业务可能对数据的读写没有一个IDC的概念,所以很容易就会有跨IDC的读写,多个业务还可能有重复consume和produce,这就造成跨IDC网络的极大浪费, 加上跨IDC的网络并不稳定,有时候会有一些异常,业务也不一定能很好处理。
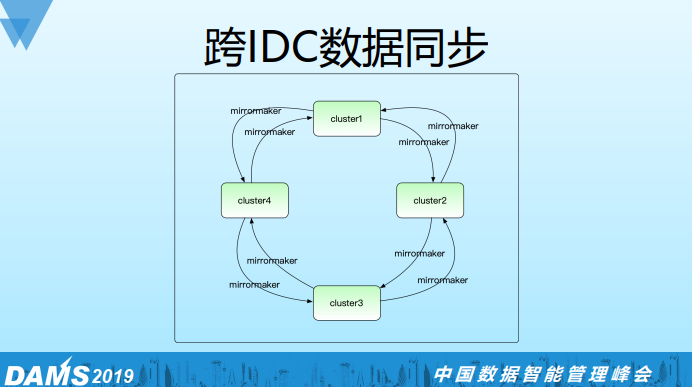
为了解决以上问题,我们统一做了跨IDC的数据同步服务,首先我们约定业务只能做本IDC的读写,不允许做跨IDC的读写,如果有跨IDC的数据需求,要向我们申请,通过mirrormaker去同步一份过来。这样做有两个好处:一是屏蔽了异常对业务的影响,二是节省了IDC之间的带宽(我们通过同步机制能保证这份数据只传输一份),我们还基于marathon/mesos对这个服务做了pass化,提高了服务的SLA。
九、监控告警

基于jmx exporter+promehteus+grafana来做图表展示,在每个broker上面部署jmx exporter, prometheus会去pull这些数据,最后通过grafana来展示。
基于Kafka manager做瞬态指标的监控。
基于burrow做consumer lag的监控。
基于wonder来做告警,这个是360内部实现的一个组件,类似zabbix。

十、线上问题及解决方案

磁盘故障:
我们通过smartctl来监测,首先状态是要passed的,其次我们会判断197 Current_Pending_Sector这个属性值不能大于100, 如果大于100这个磁盘可能有读写性能问题。
bootstrap.servers性能瓶颈:
该参数可以配置多台broker,这些broker作为proxy的角色为Kafka clients提供lookup服务,如果集群规模很大,clients很多的情况下,这些proxy角色的broker的负载会很大,为了解决这个问题,我们对bootstrap.servers参数做了vip配置。每个VIP可以绑定任意多的brokers,这样在客户端不需要修改配置的情况下可以对proxy动态扩缩容。
consumer重启不消费:
业务反馈消费停止,重启也不能够解决问题,后来定位发现是早于0.11之前版本的bug, https://issues.apache.org/jira/browse/KAFKA-5413
原因是log cleaner线程挂了导致compact停止,__consumer_offsets这个topic的量非常大,broker reload时间特别长,这段时间是停止服务的。
解决方法有两个:一是升级到Kafka 0.11+版本,二是将offset迁移到新的consumer group来解决(规避掉有问题的coordinator)。
Q&A
Q1:hamal落地系统是消费一次落地到多个组件还是消费了多次?
A:消费一次落地到多个下游组件。
Q2:在LogProducer实现中将数据存在共享内存里,这样不会丢数据,我想详细听一下。
A:不是说不丢数据,而是尽可能少丢数据,当选用共享内存策略,业务进程挂掉不会影响共享内存中的数据,重启的时候直接从共享内存恢复。
Q3:这边是通过白名单机制做了一个权限控制吗?
A:通过白名单机制我们对topic, consumer资源做了粗粒度的控制,这样可以在不影响老业务的情况下收紧口子。如果是新集群从头搭建的话推荐用SASL的SCRAM方案。
Q4:你刚才说的quota优先级别,具体实现是怎么做的?
A:在业务接入过程当中我们会给业务定级,比如这个业务是计费的,那么就是高优先级,如果只是一些track日志那么就是低优先级, 在设置quota的时候我们会根据业务当前峰值再加上一定比例buffer来设置业务的quota值。
Q5:如果集群有100个节点,客户端要配100个地址吗?
A:不需要,只需配置bootstrap.servers(proxy),proxy可以拿到所有broker的信息,它的主要工作是lookup,接收client请求返回broker地址列表,然后client再直连broker。
Q6:如果出现磁盘挂载不上这种情况下,broker节点可以正常拉起来吗?能恢复到从前那个状态吗?
A:broker可以将这块磁盘对应的目录exclude掉,然后重启就可以了,对于replica=1的topic数据会有丢失,对于replica>1的topic数据不会有丢失,因为我们做了rack aware,那么其他rack上会有副本。
PPT链接:https://pan.baidu.com/s/1d-ihPzzcOAPDTbhxllgiAw








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721