
曾凡祥,携程金融大数据团队负责人。北京邮电大学博士、加拿大McGill大学访问学者,致力于大数据和人工智能技术在金融风控、精准营销方面的研究和应用。
本文主要分享携程金融风控算法从0到1的发展进程,以时间为主线,经历了数据样本由少到多、特征由粗到细、模型由简单到复杂、效果由坏到好的全过程,重点以申请评分模型和反欺诈模型进行阐述,是一次很好的风控模型实践报告。
一、业务介绍
模型一定是基于业务的,所以首先介绍一下携程的业务情况,即本文所提及模型的实际应用场景。携程金融主营业务有三大模块:
消费金融,包括消费分期(拿去花)和现金分期(借去花)
信用卡
供应链金融
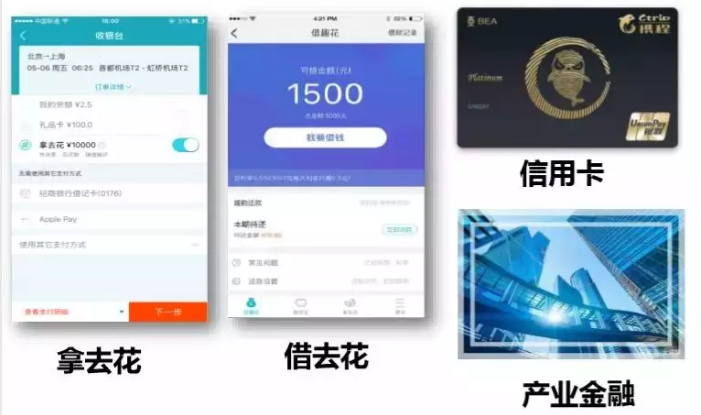
▲图1 携程金融的主要业务范围
二、数据中台
模型亦是基于完善的技术平台的,携程金融数据中台可以抽象为三个层次,底层是基础数据层,中层业务抽象模型层,以及最上层的算法模型层。

▲图2 携程金融大数据中台的抽象结构
中台这个概念早期是由美军的作战体系演化而来的,技术上所说的“中台”主要是指学习这种高效、灵活和强大的指挥作战体系。
比如电商领域,经过十几年的发展,组织庞大而复杂,业务不断细化拆分,也导致野蛮发展的系统越来越不可维护,开发和改造效率极低,也有很多新业务不得不重复造轮子,因此业界诞生了不少知名中台系统,最著名的是阿里云的数据中台建设。
在携程金融内部,大数据中台的目标是为了解决效率问题,同时降低创新成本。
中台的目标:减少沟通成本,提升协作效率。
中台的实现手段:制定标准/规范,提供高可用数据/算法/应用服务,提供统一、标准的数据研发工具。
中台的原则:数据资产的集中管控,分布式执行。
携程金融的数据中台收集了包括携程OTA整个生态环境数据,框架的最底层是计算与存储资源层,其上是数据准备层,融合多数据源,并对其做了抽取、清洗,能够提供在线与离线的服务,使其能够为用户画像、特征引擎提供基础数据,并应用于模型算法。
基础数据、用户画像、特征集市、模型服务这些内容以数据资产的形式来管理。基于这些数据资产,可以为各个业务线 - 获客,准入,经营,留存的全生命周期提供各种服务,框架图如下:

▲图3 携程金融大数据中台全景
三、风控模型体系
消费金融的风险大体可分为可控风险及不可控风险,算法能解决的主要是可控风险。
可控风险包含欺诈风险、信用风险及作业风险。
欺诈风险指的是客户在发起借款请求时即无意还款,按照人数可以分为团伙欺诈和个人欺诈,欺诈者往往通过伪造身份信息、联系方式信息、设备信息、资产信息等方式实施欺诈。
信用风险指的是借款人因各种原因未能及时、足额偿还债务或银行贷款而违约的可能性。
不可控风险包括市场风险、实质风险及名义风险。
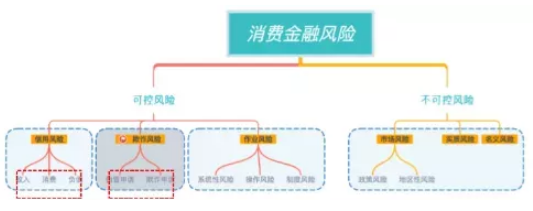
▲图4 风险基本分类
风控模型贯穿获客、准入、经营、逾期的整个客户生命周期,根据用户生命周期的不同阶段,可将风控模型分为贷前信用风险模型、贷中行为风险模型、欺诈检测及贷后催收模型。
事实上,抓住信贷审批管理就能控制80%的风险,一旦用户获得授信,后续的管理只能控制20%的风险。
除此之外,贷前、贷中、贷后不同场景,可以从不同的观测粒度进行建模与抽象。
拿携程金融的业务来讲,可以从每一笔交易角度来看,也可以从携程生态中用户账户来看,也可以从自然人概念为核心的客户级别来看。一个自然人客户与账号可以是一对多的关系,一个账号与交易也可以是一对多的关系。
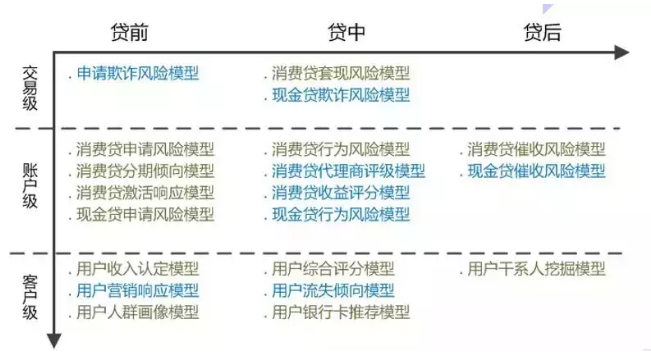
▲图5 携程金融风控模型体系
如今在银行、消费金融公司等各种贷款业务机构,普遍使用信用评分,对客户实行打分制,以期对客户的风险水平有一个准确的判断,并作为风险定价的重要手段。
行业内常用的是ABC三张评分卡。A卡、B卡、C卡分别表示:申请评分卡(Application Score Card),行为评分卡(Behavior Score Card),和催收评分卡(Collection Score Card)。
1)A卡
A卡是在获客过程中用到的信用风险模型。从模型的角度来看,它会对用户未来一定周期内的逾期风险作预测,即模型会在用户授权的情况下收集用户多维度的信息,以此来预测逾期概率。预测的逾期概率被用于风控策略或者转换成信用评分,比如国外经典的FICO评分,国内的蚂蚁信用评分、京东小白评分、携程金融的程信分等。
A卡评分除了用于决定是否通过用户的信用申请,还用于风险定价,比如额度、利率等。
2)B卡
B卡行为评分是指,用户拿到信用额度后,模型根据用户的贷中行为数据,进行风险水平的预测。本质上讲,这个模型是一个事件驱动的模型,在互联网金融领域,一般会比A卡的预测时间窗口要短,对用户的行为更为敏感。
B卡除了可以用于高风险用户的拦截,也可以作为额度、利率调整的重要参考因素。
3)C卡
C卡催收评分会判断,例如当用户出现逾期时,机构应该先催谁,或者哪些用户不用催,就自动会把钱还回来。催收模型一定程度节约催收成本,提高回催率。
四、风控模型体系之贷前信用风险模型(A卡)
贷前主要解决用户准入和风险定价问题,即面对一个新申请的进件用户,判断用户是否符合产品的放款条件及相应的放款额度、价格、期限等问题。主要包括三类问题:
反欺诈识别:根据用户提交的材料进行身份核实,确保用户不存在欺诈行为。
信用评级:与传统银行的信用评分卡原理类似,数据维度更加丰富,综合用户的社交数据、行为数据、收入数据等,判定用户的信用风险等级,评估用户的履约能力。
风险定价:根据用户的负债能力和收入稳定性,判断用户可承担的月供金额,确定用户的放款额度、偿还期限等,并根据用户风险等级确定用户的费率。
这三个问题往往是互相影响、互为前提的。举个简单的例子,对一个月收入3000的用户来说,月供在1000左右,用户可能履约良好,信用等级良好;但如果月供提高到4000,严重超出了其收入水平,即便不是有意欺诈,也可能出现断供的情况,从而得到比较差的信用等级。
本节重点阐述携程金融在信用风险建模(A卡)上的演进和一些创新工作。
A卡建模目前包括如下几方面:
确保策略的一致性,尽量减少人工干预,并利用机器学习的优势提升决策效率。
准确反映并量化用户的风险级别,策略人员可以控制和减少风险损失,因此对评分卡等级的排序能力、稳定性要求会比较高。
1、好坏用户定义
这一点可能是A卡甚至是互金大部分风控模型的最基础最核心的工作。对样本标签的定义,需要与实际业务场景、策略目标相一致,并综合考虑不同定义下的样本量。
比如在现金分期场景中,可以画一下用户回款率(或者滚动率)和逾期天数趋势分布曲线,用户逾期N天以后回款率或者滚动率便已经趋于稳定(梯度平稳),则可以N天以上逾期作为筛选坏样本的依据。
在某些场景下,如曾经的Payday Loan,由于整个业务周期只有半月或1个月,为加快模型迭代速度,有时甚至会定义7+甚至1+逾期用户为坏客户。在一些银行场景中,出于坏账计提考虑,可能定义90天以上逾期为坏客户。
总之,好坏用户的定义不能纯靠人工经验,应该以场景的数据为基础,进行数据分析之后确定。
2、样本规模与算法演进
携程金融的业务最早开始于2015年,模型进行了多个版本的迭代。下面的表格展示的是拿去花业务中,我们A卡模型的演进。
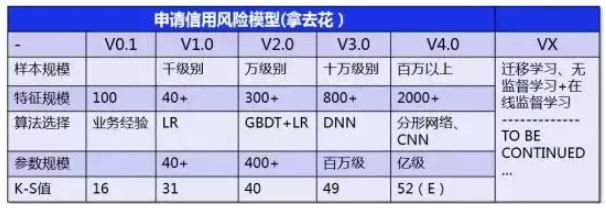
▲图6 携程金融拿去花业务A卡模型演进
业务初期,样本数据量极少,往往根据相关业务经验确定使用的特征和规则;随着数据的慢慢积累,开始采用部分精细特征,使用简单的机器学习算法训练;
当样本数据量积累到百万级以上,我们尝试采用神经网络算法进行特征自动提取或者end-to-end的风控模型训练;从18年上半年开始,我们升级到更加先进的迁移学习体系,未来会持续落地更多的前沿算法。
总之,携程金融的风控模型优化的过程,实质是紧随着业务从无到有、从小到大,数据量由少变多,特征由粗到细,模型由简单到复杂,效果由一般到突破的过程。
3、模型的评估与监控
模型建立后,需要对模型的预测能力、稳定性进行评估。看模型效果不能只看KS,KS定义是从0-1概率之间好坏样本累计概率最大差值,实际应用中一般不会直接取这个阈值(cutoff)作为策略,因为在这种cutoff下,通过率可能会很低;风控不能不管业务。
举个极端的例子,通过调整cutoff,风控几乎可以做到任意想要的逾期率,但这样通过率就很低了,业务规模可能只停留在极少数资质优秀的客户;所以评估模型时,基于风险的评估及基于业务的评估是必须的。
因此,模型评估可分为三层:
第一层:机器学习模型评估指标。信用评分模型常用的评估指标为KS、AUC等。考虑到金融业务反馈周期长的特点,除了划分训练集、测试集外,通常会预留一段训练样本覆盖时间段之外的数据集,作为OOT(跨时间)测试集,以测量模型在时间上的稳定性;
第二层:风控层面,比如在不同bucket下,预测概率的排序性能;
第三层:业务层面的拦截率,通过率,逾期表现等。
基于上面的评估分层,我们的监控也做对应的分层监控,除了包含上述三个层面,还对输入到模型中的特征进行监控,比如特征的分布、波动率等。
五、风控模型体系之贷前信用风险模型发展历程
经历过了完全靠经验的规则模型,当积累了一定数据量时,便可以用少量的维度与数据开始训练了,当数据量较少时,使用简单的LR就能达到不错的效果。
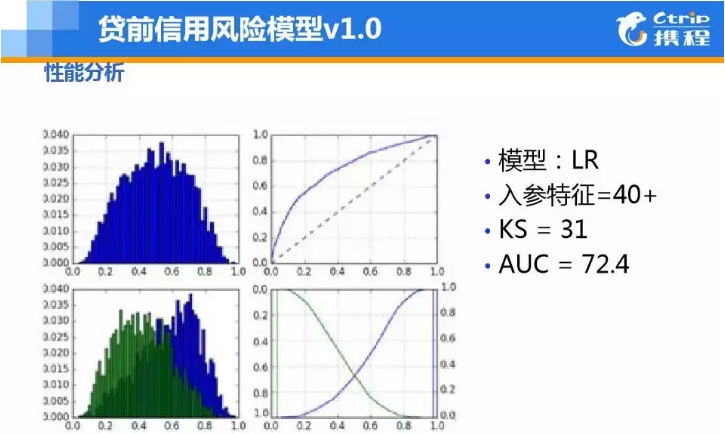
▲图7 A卡V1-LR模型
随着数据量的不断增加,慢慢构建起了身份属性、消费能力、用户关系、信用记录、出行记录等特征,GBDT+LR,RF,XGBOOOST,LightGBM等更复杂的算法便可以派上用场了。
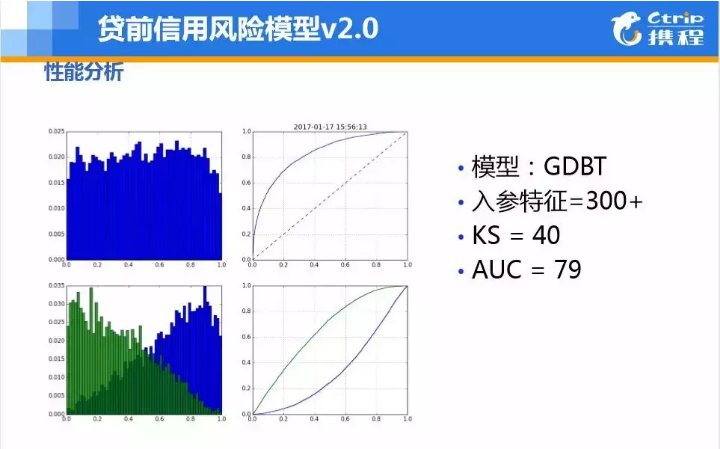
▲ 图8 A卡V2-GBDT模型
当数据达到一定规模时,采用深度学习来进行自动化表征学习或者end-to-end的风控模型学习,我们测试过DNN,这个算法在同等情况下,和GBDT之类的算法性能类似,并没有太明显的效果。
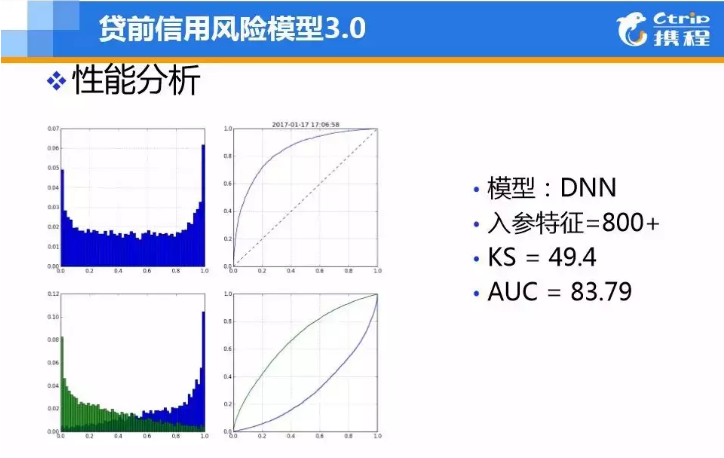
▲图9 A卡V3-DNN模型
一方面说明GBDT这类算法在处理非图像、语音、文本这类局部结构并不是特别明显的数据的优势,另一方面说明,不能直接将CV\NLP领域的算法拿来用,需要做一定的改造和优化。
因此我们陆续使用和改造了ResNet、FractalNet等网络结构,相比于DNN和GBDT模型效果有比较明显的提升;再进一步,通过分析风控这个场景,我们发现,通过审批的用户与开放自然流量的数据分布差异比较明显。
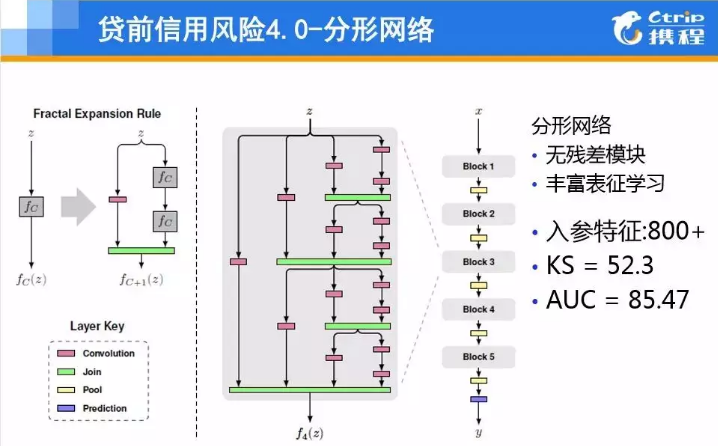
▲图10 A卡V4-分形网络模型
这一现象,基本打破了我们传统监督学习中训练集和预测集数据分布相似的假设。为解决这个问题,我们引入迁移学习框架,同等逾期条件下,通过率能明显的提升。
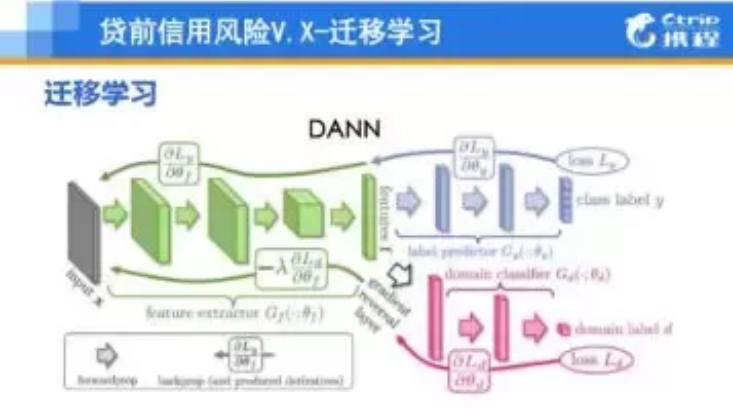
▲图11 A卡VX-迁移学习模型
六、风控模型体系之贷中反欺诈模型
贷中反欺诈按粒度可分为两类,用户级与交易级。用户级粒度相对粗一些,即断定当前客户为欺诈客户,可能的策略就是不允许欺诈用户在平台上发生交易行为;交易级是较细粒度的,即根据交易上下文、IP、设备、地域判断当前交易是否为欺诈交易,如果是,即不允许客户进行此笔交易。
贷中反欺诈有3个难点:
长尾分布:欺诈用户其实是极少的。
对抗性显著:欺诈用户会想办法找出系统及规则的漏洞。
模仿正常行为:欺诈用户会利用伪造消费流水,前期正常还款等行为等,让金融公司放松警惕,当提额到一定程度后,便开始逾期。
在反欺诈领域,我们除了使用一般的机器学习模型,也构建了一套基于社交网络的模型体系。
七、社交网络在风控模型中的应用
基于社交网络的反欺诈,基本思想其实很简单,物以类聚,人以群分。比如一个欺诈分子,可能与其有关系(在Graph上表现为有直接的边连接,这种也称之为一阶亲密度;或者通过边的游走能够触达,这种称之为多阶亲密度),那么可能这些与之有关系的用户也是欺诈分子。
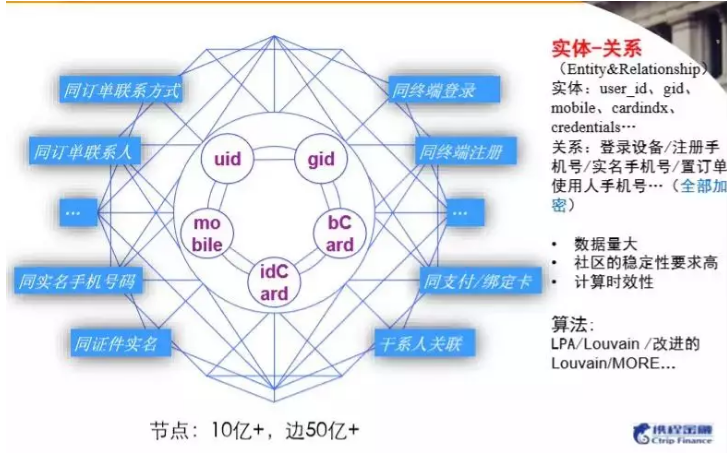
▲图12 携程金融关系网络
如图所示,通过梳理携程生态内关键实体、关系,我们首先构建了一个庞大的异构社交网络,该网络包含10亿级别的顶点,50亿级别的边。接下来是通过算法,发现社区(Community)。由于社交网络的数据量相对来讲是比较大的,因此在算法层面,对运算效率要求也是比较高的,同时对于社区划分的稳定性有一定要求。
在实际落地中采用LPA、改进的Louvain,实现T+1的社区发现。最后基于划分的社区,可以获得社区的各种属性统计,这个作为反欺诈策略的重要参考。当有一个用户到来的时候,看其属于哪个社区,根据该社区的属性确定该用户是否为欺诈用户。
目前在携程金融的实际应用中,基于社交网络的风控指标已经覆盖了贷中80%的贷款请求,同时通过社交网络,挖掘关系人一度或者多度关系,对严重的逾期行为,通过多度关系进行催收,提升回催率。
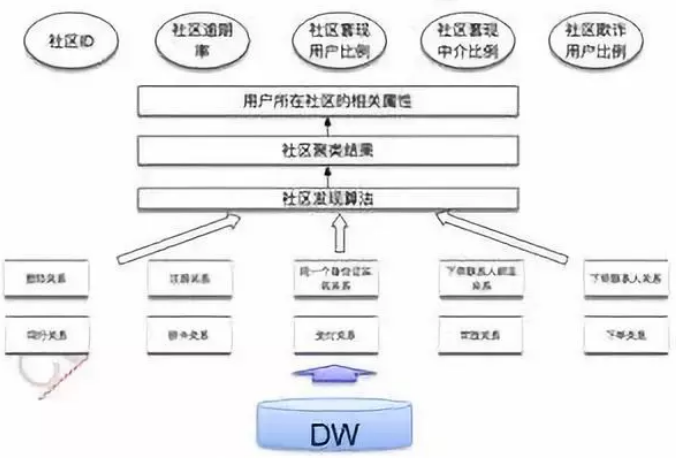
▲图13 社交网络应用的基本流程








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721