
沈辉,毕业于北京邮电大学,就职于字节跳动基础架构,主要参与负责消息队列服务的开发与维护。
本文分享大纲:
今日头条的业务背景
为什么选择 RocketMQ
RocketMQ 在头条的落地实践
头条的容灾系统建设
一、业务背景
今日头条的服务大量使用微服务,容器数目巨大,业务线繁多, Topic 的数量也非常多。另外,使用的语言比较繁杂,包括 Python,Go, C++, Java, JS 等,对于基础组件的接入,维护 SDK 的成本很高。
引入 RocketMQ 之前采用的消息队列是 NSQ 和 kafka , NSQ 是纯内存的消息队列,缺少消息的持久性,不落盘直接写到 Golang 的 channel 里,所以在并发量高的时候 CPU 利用率非常高,其优点是可以无限水平扩展;
再加上,由于不需要保证消息的有序性,集群单点故障对可用性基本没有影响,所以具有非常高的可用性。
我们也用到了 Kafka ,它的主要问题是在业务线和 Topic 繁多,其写入性能会出现明显的下降,拆分集群又会增加额外的运维负担;并且在高负载下,其故障恢复时间比较长。
所以,针对当时的状况和业务场景的需求,我们进行了一些调研,期望选择一款新的 MQ 来比较好的解决目前的困境,最终选择了 RocketMQ 。
二、为什么选择 RocketMQ
这是一个经过阿里巴巴多年双11验证过的、可以支持亿级并发的开源消息队列,是值得信任的。
首先关注一下它的特性。RocketMQ 具有高可靠性、数据持久性,和 Kafka 一样是先写 PageCache ,再落盘,并且数据有多副本。
并且它的存储模型是所有的 Topic 都写到同一个 Commitlog 里,是一个append only 操作,在海量 Topic 下也能将磁盘的性能发挥到极致,并且保持稳定的写入时延。
其次就是他的性能,经过我们的 benchmark ,采用一主两从的结构,单机 qps 可以达到 14w , latency 保持在 2ms 以内。对比之前的 NSQ 和 Kafka,Kafka 的吞吐非常高,但是在多 Topic 下, Kafka 的 PCT99毛刺会非常多,而且平均值非常长,不适合在线业务场景。
另外 NSQ 的消息首先经过 Golang 的 channel ,这是非常消耗 CPU 的,在单机 5~6w 的时候 CPU 利用率达到 50~60% ,高负载下的写延迟不稳定。
此外,RocketMQ 对在线业务特性支持是非常丰富的,支持 retry , 支持并发消费,死信队列,延时消息,基于时间戳的消息回溯。
最后是消息体支持消息头,这个非常有用,可以直接支持实现消息链路追踪,不然就需要把追踪信息写到 message 的 body 里,还支持事务的消息。
综合以上特性我们团队最终选择了 RocketMQ 。
三、RocketMQ 在头条的落地实践
下面简单介绍下,今日头条的部署结构,如图所示:
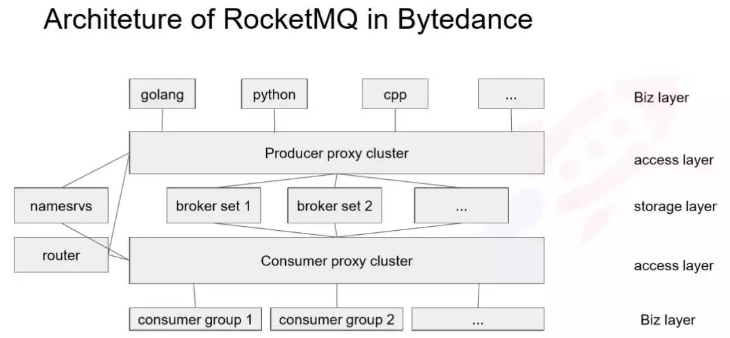
由于生产者种类繁多,我们倾向于保持客户端简单,因为推动 SDK 升级是一个很沉重的负担,所以我们通过提供一个 Proxy 层,来保持生产端的轻量。Proxy 层是通过一个标准的 gRpc 框架来实现,也可以用 thrift ,当然任何 RPC 都框架都可以实现。
Producer 的 Proxy 相对比较简单,虽然在 Producer 这边也集成了很多,比如路由管理、监控等其他功能,但是 SDK 只需实现发消息的请求,所以 SDK 非常轻量、改动非常少,在迭代过程中也不需要一个个推业务去升级 SDK 。
SDK 通过服务发现去找到一个 Proxy 实例,然后建立连接发送消息,Proxy 的工作是根据 RPC 请求的消息转发到对应的 Broker 集群上。
Consumer Proxy 实现的是 pull 和二次 reblance 的逻辑,这个后面会讲到,相当于把 Consumer 的 pull 透传给 Brokerset ,Proxy 这边会有一个消息的 cache ,一定程度上降低对 broker page cache 的污染。
这个架构和滴滴的 MQ 架构有点相似,他们也是之前做了一个 Proxy ,用 thrift 做 RPC ,这对后端的扩容、运维、减少 SDK 的逻辑上来说都是很有必要的。
四、在容器以及微服务场景下为什么要做 Porxy ?
有以下几点原因:
① SDK 会非常简单轻量
② 很容易对流量进行控制
Proxy 可以对生产端的流量进行控制,比如我们期望某些Broker压力比较大的时候,能够切一些流量或者说切流量到另外的机房,这种流量的调度,多环境的支持,再比如有些预发布环境、预上线环境的支持,我们 Topic 这边写入的流量可以在 Proxy 这边可以很方便的完成控制,不用修改 SDK 。
③ 解决连接的问题
特别是解决 Python 的问题, Python 实现的服务如果要获得高并发度,一般是采取多进程模型,这意味着一个进程一个连接,特别是对于部署到 Docker 里的 Python 服务,它可能一个容器里启动几百个进程,如果直接连到 Broker ,这个 Broker 上的连接数可能到几十上百万,此时 CPU 软中断会非常高,导致读写的延时的明显上涨。
④ 支持更高的并发度
通过 Proxy ,多了一个代理,在消费不需要顺序的情况下,我们可以支持更高的并发度, Consumer 的实例数可以超过 Consume Queue 的数量。
⑤ 可以无缝的继承其他的 MQ
中间有一层 Proxy ,后面可以更改存储引擎,这个对客户端是无感知的。
⑥ 最小程度的减少 rebalance
在 Conusmer 在升级或 Restart 的时候, Consumer 如果直接连 broker 的话,rebalance 触发比较频繁, 如果 rebalance 比较频繁,且 Topic 量比较大的时候,可能会造成消息堆积,这个业务不是太接受的;
如果加一层 Proxy 的话, rebalance 只在 Proxt 和 Broker 之间进行,就不需要 Consumer 再进行一次 rebalance , Proxy 只需要维护着和自己建立连接的 Consumer 就可以了。当消费者重启或升级的时候,可以最小程度的减少 rebalance 。

以上是我们通过 Proxy 接口给 RocketMQ 带来的好处。但是因为多了一层,也会带来额外的 Overhead ,如下:
① 会消耗 CPU
会消耗 CPU,Proxy 那一层会做RPC协议的序列化和反序列化。
如下是 Conusme Proxy 的结构图,它带来了消费并发度的提高。由于我们的 Broker 集群是独立部署的,考虑到broker主要是消耗包括网卡、磁盘和内存资源,对于 CPU 的消耗反而不高,这里的解决方式直接进行混合部署,然后直接在新的机器上进行扩,但是 Broker 这边的 CPU 也是可以得到利用的。
② 延迟问题
经过测试,在 4Kmsg、20W Tps 下,延迟会有所增加,大概是 1ms ,从 2ms 到 3ms 左右,这个时延对于业务来说是可以接受的。
接下来再看下 Consumer 这边的逻辑,如下图所示。
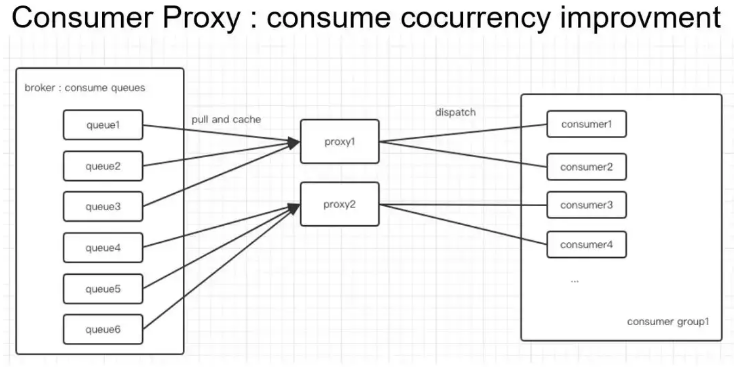
比如上面部署了两个 Proxy , Broker,左边有 6 个 Queue ,对于顺序消息来说,左边这边 rebalance 是一个相对静态的结果, Consumer 的上下线是比较频繁的。对于顺序消息来说,左边和之前的逻辑是保持一致的, Proxy 会为每个 Consumer 实例分配到合适的数量的 Queue ;
对于不关心顺序性的消息,Proxy 会把所有的消息都放到一个队列里,然后从这个队列 dispatch 到各个 Consumer ,对于乱序消息来说,理论上来说 Consumer 数量可以无限扩展的;相对于和普通 Consumer 直连的情况,Consumer 的数量如果超过了Consume Queue的数量,其中多出来的 Consumer 是没有办法分配到 Queue 的,而且在容器部署环境下,单 Consumer 不能起太多线程去支撑高并发;
在容器这个环境下,比较好的方式是多实例,然后按照 CPU 的核心数,启动多个线程,比如 8C 的启动 8 个线程,因为容器是有 Quota 的,一般是 1C,2C,4C,8C 这样,这种情况下,如果线程数超过了 CPU 的核心数,其实对并发度并没有太大的意义。
接下来是做这个接入方式的时候遇到的一些问题。
① 消息大小的限制
因为这里有一层 RPC ,在 RPC 请求过程中会有单次请求大小的限制;另外一方面是 RocketMQ 的 producer 里会有一个 MaxMessageSize 方法去控制消息不能超过这个大小;
Broker 里也有一个参数,是 Broker 启动的配置,这个需要Broker重启,不然修改也不生效,它里面有一个 DefaultAppendMessage 配置,是在启动的时候传进去对的参数,如果仅 NameServer 在线变更是不生效的,而且超过这个大小会报错。
因为现在 RocketMQ 默认是 4M 的消息,如果将 RocketMQ 作为日志总线,可能消息体大小不是太够, 所以Procuer 和 Broker 是都需要做变更的。
② 多连接的问题
如果看 RocketMQ 源码会发现,多个 Producer 是共享一个底层的 MQ Client 实例的,因为一个 socket 连接吞吐是有限的,所以只会和Broker建立一个socket连接。
另外,我们也有 socket 与 socket 之间是隔离的,可以通过 Producer 的 setIntanceName ,当与 DefaultI Instance 的 name 不一样时会新启动一个 Client 的,其实就是一个新的 socket 连接,对于有隔离需求的、连接池需求的等,这个参数是有用的,在 4.5.0 上新加了一个接口是指定构造的实例数量。
③ 超时设置
因为多了一层 RPC ,那一层是有一个超时设置的,这个会有点不一样,因为我们的 RPC 请求里会带上超时设置的,客户端到 Proxy 有一个 RTT ,然后 Producer 到 Broker 的发送消息也是有一个请求响应延时,需要给 SDK 一个正确的超时语义。
④ 如何选择一个合适的 reblance 算法
如何选择一个合适的 reblance 算法,我们遇到这个问题是在双机房同城容灾的背景下,会有一边 Topic 的 MessageQueue 没有写入。
这种情况下, RocketMQ 自己默认的是按照平均分配算法进行分配的,比如有 10 个 Queue , 3 个 Proxy 情况, 1、2、3 是对应 Proxy1;4、5、6 是对应 Proxy2;7、8、9、10 是对应 Proxy3 ,如果在双机房同城容灾部署情况下,一般有一半 Message Queue 是没有写入的,会有一大部分 Consumer 是启动了,但是分配到的 Message Queue 是没有消息写入的。
然后另外一个诉求是因为有跨机房的流量,所以他其实直接复用开源出来的 Consumer 的实现里就有根据 MachineRoom 去做 reblance ,会就近分配 MessageQueue。
⑤ 在 Proxy 这边需要做一个缓存,特别是拉消息的缓存
特别提醒一下, Proxy 拉消息都是通过 Slave 去拉,不需要使用 Master 去拉, Master 的 IO 比较重;还有 Buffer 的管理,我们是遇到过这种问题的,如果只考虑 Message 数量的话,会导致 OOM ,所以要注意消息 size 的设置,
⑥ 端到端压缩
因为 RocketMQ 在消息超过 4k 的时候, Producer 会进行压缩。如果不在客户端做压缩,这还是涉及到 RPC 的问题, RPC 一般来说, Byte 类型,就是 Byte 数组类型它是不会进行压缩的,只是会进行一些常规的编码,所以消息体需要在客户端做压缩。如果放在 Proxy 这边做, Proxy 压力会比较大,所以不如放在客户端去承载这个压缩。

五、头条的容灾系统建设
前面大致介绍了我们这边如何接入 RocketMQ ,如何实现这么一套 Proxy ,以及在实现这套 Proxy 过程中遇到的一些问题。下面看一下灾难恢复的方案,设计之初我们也参考了一些潜在相关方案。
第一种方案:扩展集群,扩展集群的方案就像下图所示:
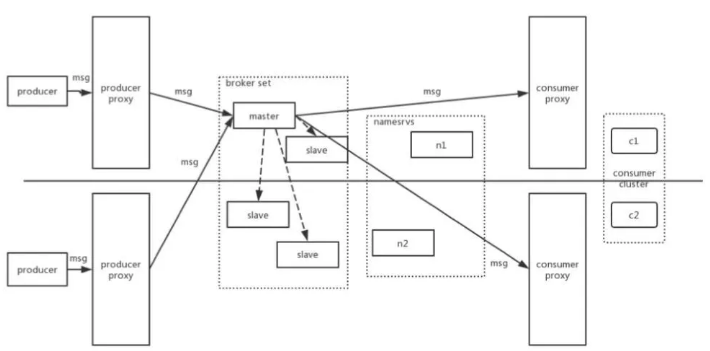
这是 master 和 slave 跨机房去部署的方式。因为我们有一层 proxy ,所以可以很方便的去做流量的调度,让消息只在一个主机房进行消息写入,不需要一个类似中控功能的实体存在。
第二种方案:类似 MySQL 和 Redis 的架构模式,即单主模式,只有一个地方式写入的,如下图所示。数据是通过 MySQL Matser/Slave 方式同步到另一个机房。这样 RocketMQ 会启动一个类似 Kafka 的 Mirror maker 类进行消息复制,这样会多一倍的冗余,实际上数据还会存在一些不一致的问题。
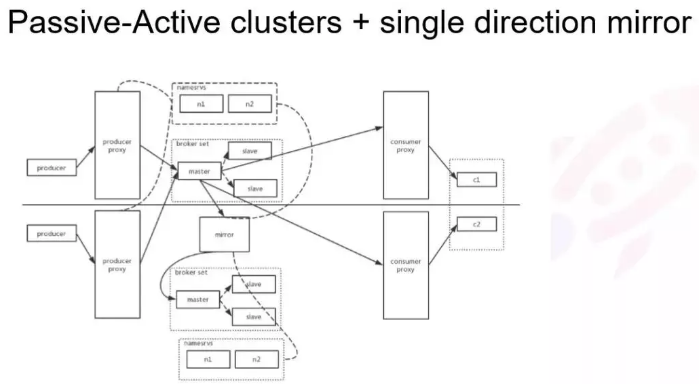
第三种方案:双写加双向复制的架构。这个结构太复杂不好控制,尤其是双向复制,其中消息区回环的问题比较好解决,只需针对在每个正常的业务消息,在 Header 里加一个标志字段就好,另外的 Mirror 发现有这个字段就把这条消息直接丢掉即可。
这个链路上维护复杂而且存在数据冗余,其中最大问题是两边的数据不对等,在一边挂掉情况下,对于一些无法接受数据不一致的是有问题的。
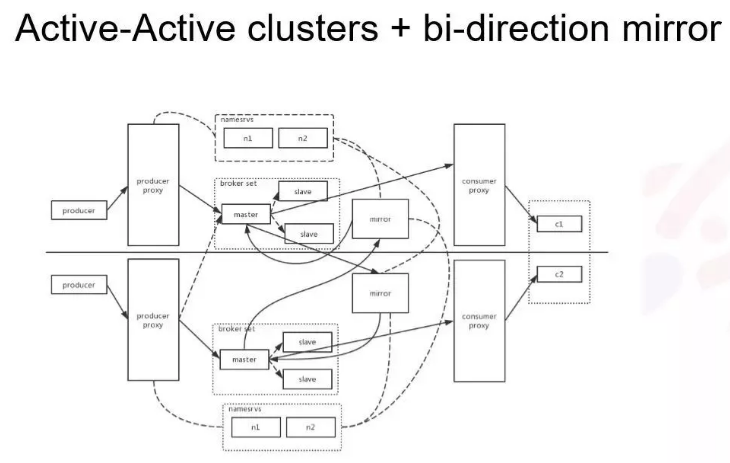
双写都是没有 Mirror 的方案,如下图所示:
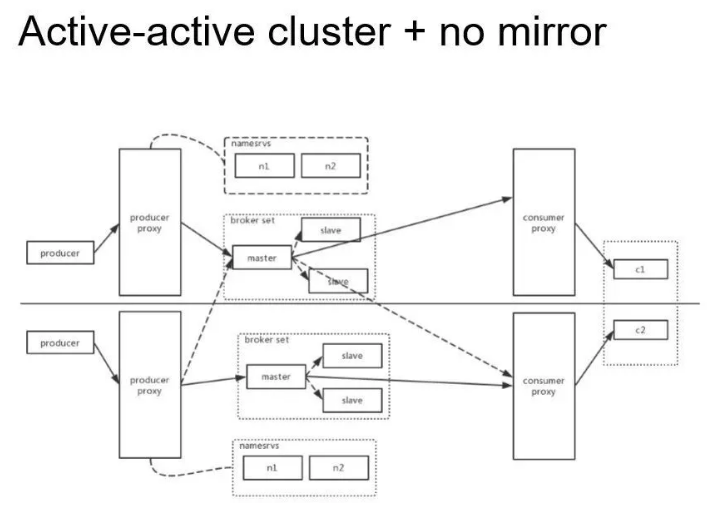
这也是我们最终选择的方案。我们对有序消息和无序消息的处理方式不太一样,针对无序消息只需就近写本机房就可以了,对于有序消息我们还是会有一个主机房,Proxy 会去 NameServer 拉取 Broker 的 Queue 信息, Producer 将有序消息路由到一个指定主机房,消费端这一侧,就是就近拉取消息。
对于顺序消息我们会采取一定的调度逻辑保证均衡的分担压力获取消息,这个架构的优点是比较简单,缺点是当集群中一边挂掉时,会造成有序消息的无序,这边是通过记录消息 offset 来处理的。
此外,还有一种独立集群部署的,相当于没有上图中间的有序消息那条线,因为大多数有序消息是整体体系的,服务要部署单元化,比如某些 uid 、订单 Id 的消息或请求只会落到一边机房的,完全不用担心消息来得时候是否需要按照某些 key 去指定 MessageQueue ,因为过来的消息必定是隶属于这个机房的,也就是说中间有序消息那条线可以不用关心了,可以直接去掉。
但是,这个是和整个公司部署方式以及单元化体系有关系的,对于部分业务我们是直接做到两个集群,两边的生产者、消费者、Broker 、Proxy 全部是隔离的,两边都互不发现,就是这么一套运行方式,但是这就需要业务的上下游要做到单元化的程度才可行。
以上就是 RocketMQ 在头条的落地实践以及头条的容灾系统建设分享,谢谢。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721