
在58的业务场景中,HBase扮演重要角色。例如帖子信息等公司基础数据都是通过HBase进行离线存储,并为各个业务线提供随机查询及更深层次的数据分析。同时HBase在58还大量用于用户画像、搜索、推荐、时序数据和图数据等场景的存储和查询分析。
HBase在58的应用架构:
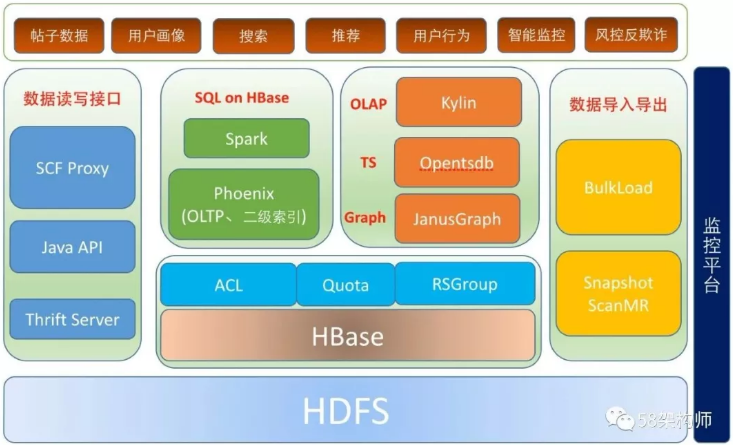
HBase在58的应用架构如上图所示,主要内容包括以下几个部分:
多租户支持:包括SCF限流、RSGroup、RPC读写分离、HBase Quota 、ACL;
数据读写接口:包括SCF 代理API、原生Java API以及跨语言访问Thrift Server;
HBase数据导入导出:包括数据批量导入工具BulkLoad,数据批量导出工具SnapshotMR;
OLAP:多维分析查询的Kylin平台;
时序数据库:时序数据存储和查询的时序数据库Opentsdb;
图数据库:图关系数据存储和查询的图数据库JanusGraph;
SQL on HBase:支持二级索引和事务的Phoenix,以及Spark SQL等;
HBase在58的应用业务场景包括:全量帖子数据、用户画像、搜索、推荐、用户行为、智能监控以及风控反欺诈等的数据存储和分析;
监控平台:HBase平台的监控实现。
本文将从多租户支持、数据读写接口、数据导入导出和平台优化四个方面来重点讲解58 HBase平台的建设。
说明:下文中所有涉及到RegionServer的地方统一使用RS来代替。
一、HBase多租户支持
HBase在1.1.0版本之前没有多租户的概念,同一个集群上所有用户、表都是同等的,导致各个业务之间干扰比较大,特别是某些重要业务,需要在资源有限的情况下保证优先正常运行,但是在之前的版本中是无法保证的。从HBase 1.1.0开始,HBase的多租户特性逐渐得到支持,我们的HBase版本是1.0.0-cdh5.4.4,该版本已经集成了多租户特性。
以下是58用户访问HBase的流程图:
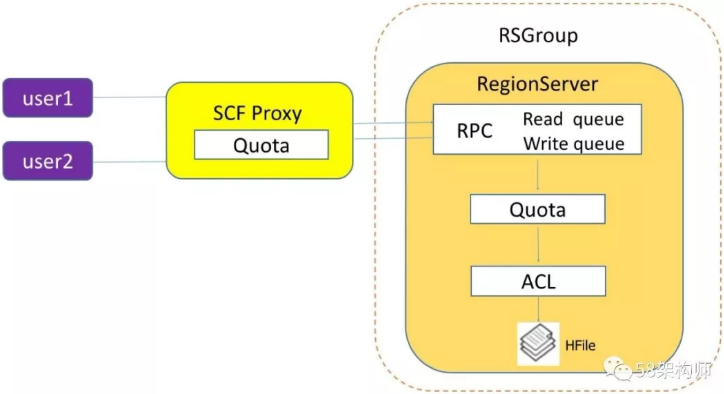
我们从多个层面对HBase多租户进行了支持,主要分为以下两个大的方面:
资源限制:
SCF Quota;
HBase Quota。
资源隔离:
云计RS RPC读写分离;
HBase ACL权限隔离;
RSGroup物理隔离。
1)SCF Quota
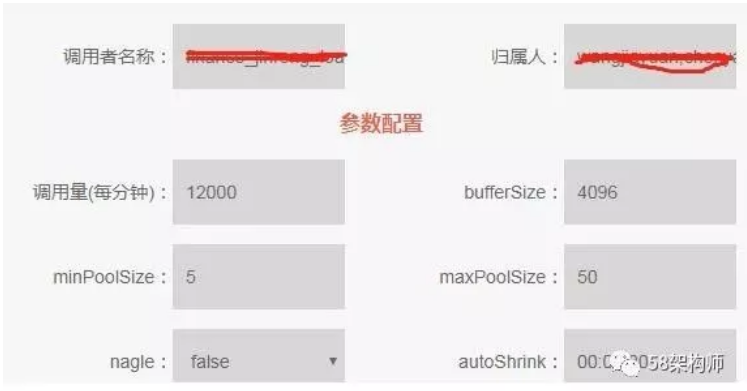
SCF是公司自研的RPC框架,我们基于SCF封装了原生HBase API,用户根据应用需要申请HBase SCF服务调用时,需要根据应用实际情况填写HBase的每分钟调用量(请求次数),在调用量超限时,SCF管理平台可以实现应用级的限流,这是全局限流。缺点是只能对调用量进行限制,无法对读写数据量大小限制。
云计以下是用户申请HBase SCF服务调用时需要填写的调用量:
2)HBase Quota
HBase的Quota功能可以实现对用户级、表级和命名空间级的资源进行限制。这里的资源包括请求数据量大小、请求次数两个维度,这两个维度基本涵盖了常见的资源限制。
目前HBase的Quota功能只能限制到RS这一级,不是针对整个集群的。但是因为可以对请求的数据量大小进行限制,一定程度上可以弥补了SCF Proxy应用级限流只能对请求次数进行限制的不足。
开启Quota的配置如下:

在开启了HBase的Quota后,Quota相关的元数据会存储到HBase的系统表hbase:quota中。
在我们的HBase集群中之前遇到过个别用户读写数据量过大导致RS节点带宽被打满,甚至触发RS的FGC,导致服务不稳定,影响到了其他的业务,但是应用级的调用量并没有超过申请SCF时设置的值,这个时候我们就可以通过设置HBase Quota,限制读写表级数据量大小来解决这个问题。
以下是设置HBase Quota信息,可以通过命令行进行设置和查看:

1)RS RPC读写分离
默认场景下,HBase只提供一个RPC请求队列,所有请求都会进入该队列进行优先级排序。这样可能会出现由于读问题阻塞所有handler线程导致写数据失败,或者由于写问题阻塞所有handler线程导致读数据失败,这两种问题我们都遇到过,在后续篇幅中会提到,这里不细述。
通过设置参数hbase.ipc.server.callqueue.handler.factor来设置多个队列,队列个数等于该参数 * handler线程数,比如该参数设置为0.1,总的handler线程数为200,则会产生20个独立队列。
独立队列产生之后,可以通过参数 hbase.ipc.server.callqueue.read.ratio 来设置读写队列比例,比如设置0.6,则表示会有12个队列用于接收读请求,8个用于接收写请求;另外,还可以进一步通过参数 hbase.ipc.server.callqueue.scan.ratio 设置get和scan的队列比例,比如设置为0.2,表示2个队列用于scan请求,另外10个用于get请求,进一步还将get和scan请求分开。
RPC读写分离设计思想总体来说实现了读写请求队列资源的隔离,达到读写互不干扰的目的,根据HBase集群服务的业务类型,我们还可以进一步配置长时scan读和短时get读之间的队列隔离,实现长时读任务和短时读任务互不干扰。
2)HBase ACL权限隔离
HBase集群多租户需要关注的一个核心问题是数据访问权限的问题,对于一些重要的公共数据,或者要进行跨部门访问数据,我们只开放给经过权限申请的用户访问,没有权限的用户是不能访问的,这就涉及到了HBase的数据权限隔离了,HBase是通过ACL来实现权限隔离的。
基于58的实际应用情况,访问HBase的用户都是Hadoop计算集群的用户,而且Hadoop用户是按部门分配的,所以HBase的用户也是到部门而不是到个人,这样的好处是维护的用户数少了,便于管理,缺点是有的部门下面不同子部门之间如果也要进行数据权限隔离就比较麻烦,需要单独申请开通子部门账号。
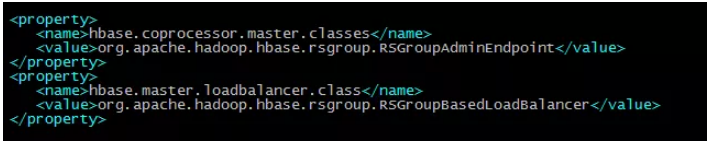
要开启HBase的ACL,只需要在配置文件hbase-site.xml中关于Master、RegionServer和Region的协处理器都加上org.apache.hadoop.hbase.security.access.AccessController类就可以了。具体HBase ACL的配置项如下图所示:
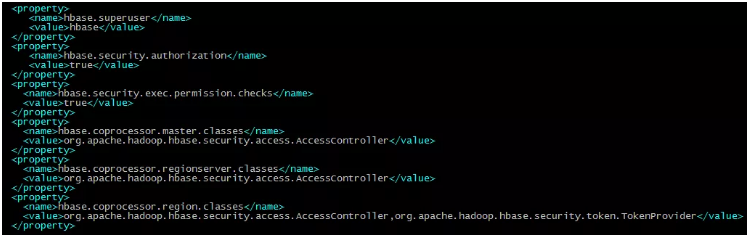
HBase的访问级别有读取(R)、写入(W)、执行(X)、创建(C)、管理员(A),而权限作用域包括超级用户、全局、命名空间、表、列族、列。访问级别和作用域的组合创建了可授予用户的可能访问级别的矩阵。在生产环境中,根据执行特定工作所需的内容来考虑访问级别和作用域。
在58的实际应用中,我们将用户和HBase的命名空间一一对应,创建新用户时,创建同名的命名空间,并赋予该用户对同名命名空间的所有权限(RWCA)。以下以新用户zhangsan为例,创建同名命名空间并授权:
create_namespace 'zhangsan'
grant 'zhangsan','RWCA','@zhangsan'
3)RSGroup物理隔离
虽然SCF Quota和HBase Quota功能可以做到对用户的读写进行限制,一定程度上能降低各业务读写数据的相互干扰,但是在我们的实际业务场景中,存在两类特殊业务,一类是消耗资源非常大,但是不希望被限流,另外一类是非常重要,需要高优先级保证服务的稳定。
对于这两种情况下,我们只能对该业务进行物理隔离,物理隔离既能保证重要业务的稳定性,也避免了对其他业务的干扰。我们使用的物理隔离方案是RSGroup,也即RegionServer Group。
RSGroup整体架构:
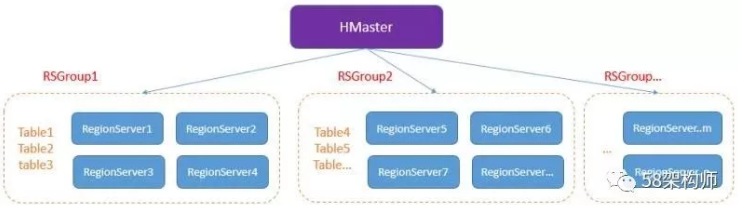
RSGroup有以下几个特点:
不同RS和表划分到不同的RSGroup;
同一个RS只能属于一个RSGroup;
同一个表也只能属于一个RSGroup;
默认所有RS和表都属于“default”这个RSGroup。
RSGroup实现细节:

从以上RSGroup实现细节中看出,RSGroup的功能主要包含两部分,RSGroup元数据管理以及Balance。
RSGroup开启的配置项:
二、数据读写接口
目前我们提供了三种HBase的数据读写接口以便于用户使用,包括SCF代理、Java原生API和Thrift Server。以下分别进行说明:
SCF是58架构部自研的RPC框架,我们基于SCF封装了原生的Java API,以SCF RPC接口的方式暴露给用户使用,其中以这种方式提供给用户的接口多达30个。由于SCF支持跨语言访问,很好的解决了使用非Java语言用户想要访问HBase数据的问题,目前用户使用最多的是通过Java、Python和PHP这三种语言来访问这些封装的接口。
SCF proxy接口整体架构:
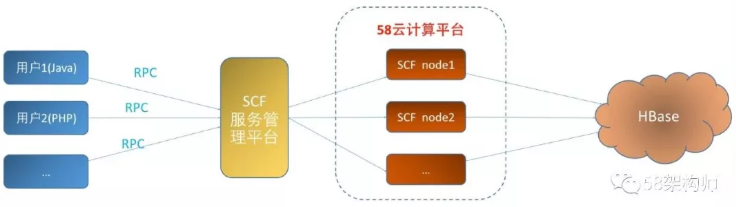
数据读写流程:用户通过RPC连接到SCF服务管理平台,通过SCF服务管理平台做服务发现,找到58云计算平台上部署的服务节点,服务节点最终通过访问HBase实现用户数据的读写操作。
使用SCF Proxy接口的优势:
避免用户直连HBase集群,降低zk的压力。之前经常遇到因为用户代码存在bug,导致zk连接数暴涨的情况;
针对大量一次性扫描数据的场景,提供单独访问接口,并在接口中设置scan的blockcache熟悉为false,避免了对后端读缓存的干扰;
通过服务管理平台的服务发现和服务治理能力,结合业务的增长情况以及基于58云计算平台弹性特点,我们很容易对服务节点做自动扩容,而这一切对用户是透明的;
通过服务管理平台可以实现对用户的访问做应用级限流,规范用户的读写操作;
服务管理平台提供了调用量、查询耗时以及异常情况等丰富的图表,用户可以很方便查看。
以下是我们的SCF服务在服务管理平台展示的调用量和查询耗时图表:

由于SCF Proxy接口的诸多优势,我们对于新接的业务都要求通过申请这种方式来访问HBase。
由于历史原因和个别特殊的新业务还采用Java原生的API外,其他新业务都通SCF Proxy接口来访问。
也是由于历史原因,个别用户想使用非Java语言来访问HBase,才启用了Thrift Server,由于SCF proxy接口支持多语言,目前这种跨语言访问的问题都通过SCF Proxy来解决了。
三、数据导入导出
HBase相对于其他KV存储系统来说比较大的一个优势是提供了强大的批量导入工具BulkLoad,通过BulkLoad,我们很容易将生成好的几百G,甚至上T的HFile文件以毫秒级的速度导入Hbase,并能马上进行查询。
所以对于历史数据和非实时写入的数据,我们会建议用户通过BulkLoad的方式导入数据。
针对全表扫描的应用场景,HBase提供了两种解决方案,一种是TableScanMR,另一种就是SnapshotScanMR。这两种方案都是采用MR来并行化对数据进行扫描,但是底层实现原理确是有很大差别,以下会进行对比分析。
TableScanMR的实现原理图:
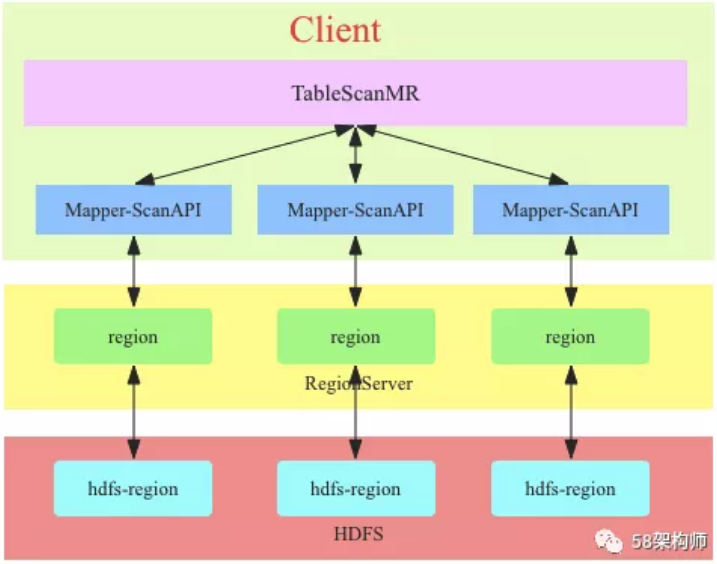
TableScanMR会将scan请求根据HBase表的region分界进行分解,分解成多个sub-scan(一个sub-scan对应一个map任务),每个sub-scan内部本质上就是一个ScanAPI。假如scan是全表扫描,那这张表有多少region,就会将这个scan分解成多个sub-scan,每个sub-scan的startkey和stopkey就是region的startkey和stopkey。
这种方式只是简单的将scan操作并行化了,数据读取链路和直接scan没有本质区别,都需要通过RS来读取数据。
SnapshotScanMR的实现原理图:

SnapshotScanMR总体来看和TableScanMR工作流程基本一致,不过SnapshotScanMR的实现依赖于HBase的snapshot,通过shapshot的元数据信息,SnapshotScanMR可以很容易知道当前全表扫描要访问那些HFile,以及这些HFile的HDFS路径,所以SnapshotScanMR构造的sub-scan可以绕过RS,直接借用Region中的扫描机制直接扫描HDFS中数据。
SnapshotScanMR优势:
避免对其他业务的干扰:SnapshotScanMR绕过了RS,避免了全表扫描对其他业务的干扰。
极大的提升了扫描效率:SnapshotScanMR绕过了RS,减少了一次网络传输,对应少了一次数据的序列化和反序列化操作。TableScanMR扫描中RS很可能会成为瓶颈,而SnapshotScanMR不需要担心这一点。
基于以上的原因,在全部扫描,以及全部数据导出的应用场景中,我们选择了SnapshotScanMR,并对原生的SnapshotScanMR进行了进一步的封装,作为一个通用工具提供给用户。
四、平台优化
在使用HBase的过程中,我们遇到了很多问题和挑战,但最终都一一克服了,以下是我们遇到一部分典型问题及优化:
在一次排查HBase问题的时候发现RS进程存在大量的CLOSE_WAIT,最多的达到了6000+,这个问题虽然还没有直接导致RS挂掉,但是也确实是个不小的隐患。
从socket的角度分析产生CLOSE_WAIT的原因:对方主动关闭连接或者网络异常导致连接中断,这时我方的状态会变成CLOSE_WAIT, 此时我方要调用close()来使得连接正确关闭,否则CLOSE_WAIT会一直存在。
对应到咱们这个问题,其实就是用户通过RS访问DataNode(端口50010)的数据,DataNode端已经主动关闭Socket了,但是RS端没有关闭,所以要解决的问题就是RS关闭Socket连接的问题。
解决办法:社区对该问题的讨论见HBASE-9393。该问题的修复依赖HDFS-7694,我们的Hadoop版本是hadoop2.6.0-cdh5.4.4,已经集成了HDFS-7694的内容。
HBASE-9393的核心思想是通过HDFS API关闭HBase两个地方打开的Socket:
RS打开HFile读取元数据信息(flush、bulkload、move、balance时)后关闭Socket;
每次执行完成用户scan操作后关闭Socket。
优化效果:CLOSE_WAIT数量降为10左右。
由于集群某个磁盘出现坏道(没有完全坏,表现为读写慢,disk.io.util为100%),导致RS所有handler线程因为写WAL失败而被阻塞,无法对外提供服务,严重影响了用户读写数据体验。
最后分析发现,RS写WAL时由于DN节点出现磁盘坏道(表现为disk.io.util为长时间处于100%),导致写WAL的pipeline抛出异常并误将正常DN节点标记为bad节点,而恢复pipeline时使用bad节点进行数据块transfer,导致pipeline恢复失败,最终RS的所有写请求都阻塞到WAL的sync线程上,RS由于没有可用的handler线程,也就无法对外提供服务了。
解决办法:
RS配置RPC读写分离:避免由于写阻塞所有handler线程,影响到读请求;
pipeline恢复失败解决:社区已有该问题的讨论,见并HDFS-9178,不过因为HDFS的pipeline过程非常复杂,HDFS-9178能否解决该问题需要进一步验证。
某次有一个业务执行BulkLoad操作批量导入上T的数据到HBase表时,RS端报BulkLoad操作获取Region级写锁出现超时异常:failed to get a lock in 60000 ms,当时该表并没有进行读写操作,最终定位到是该时间段内这个业务的表正在进行compact操作,在我们的HBase版本中,执行compact时会获取Region级的读锁,而且会长时间占用,所有导致BulkLoad获取写锁超时了。
解决办法:Compact时不持有Region读锁,社区对该问题的讨论见HBASE-14575。
我们的SCF服务最初是基于HTablePool API开发的,SCF服务在运行一段时间后经常会出现JVM堆内存暴增而触发FGC的情况,分析发现HTablePool已经是标记为已废弃,原因是通过HTablePool的获取Table对象,会创建单独的线程池,而且线程个数没有限制,导致请求量大时,线程数会暴增。
解决办法:最后我们换成了官方推荐的API,通过Connection获取Table,这种方式Connection内部的线程池可以在在所有表中共享,而且线程数是可配置的。
BlockCache启用BuckCache;
Compact限流优化等。
五、总结
本文从多租户支持、数据读写接口、数据导入导出和平台优化四个方面讲解了HBase相关的平台建设工作。
HBase作为一个开源的平台,有着非常丰富的生态系统。在HBase平台基础之上,我们持续不断地引入了各种新的能力,包括OLAP、图数据库、时序数据库和SQL on HBase等,这些我们将在58 HBase平台实践和应用的后续文章中进一步介绍。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721