
本文根据彭冬老师在〖2019 DAMS中国数据智能管理峰会〗现场演讲内容整理而成。

讲师介绍
彭冬,微博广告大数据团队负责人、技术专家。目前负责微博广告智能运维系统、大数据平台、数据挖掘及用户画像等工作,著有《智能运维:从0搭建大规模分布式AIOps系统》。
分享概要
1、微博及商业化特色
2、微博社交化数据
3、微博商业化增长
一、前言
从技术层面,大数据包括底层数据存储、实时计算、计算分析、数据挖掘等等,这些都是我们经常听到的内容,但提到大数据往往很重要的一点是要结合场景来讲。
比如我们经常会收到垃圾短信或诈骗短信,他们就是用到了大数据的技术中的用户画像技术,先分析和勾勒出目标用户的特点再给目标用户发送垃圾短信或者诈骗短信。又比如我们经常听到的算命先生,他们也用的是大数据的技术里的统计学原理和相关技术。
数据,尤其是大数据,需要结合场景,本次分享结合了微博的场景,来看看微博怎么用数据驱动带来商业收入的增长。
本次分享的主题是数据和增长,主要从数据的思想和方法层面进行分享。
二、微博及商业化特色
很多朋友经常会问我,微博现在还在吗?还有人用吗?我告诉他们微博过得非常好,微博有非常健康的生态体系:
在用户方面,微博的用户规模从最开始的几千万到现在的2个亿,MAU有4个多亿,微博上有很多用户,包括大量KOL,以及超过5万的明星账号。
在关系方面,微博场景里面包含了大家经常会看的关注流,我们关注了大V或者垂直行业的意见领袖,如李开复,发表了微博,那我们就可以在关注流中看到。
在场景方面,微博里面有大量的场景,比如大家经常看到的热搜、热门事件就在热门场景流里,而我们看到的各种话题就在话题流里,我们看到的视频在视频流等等。
在内容方面,微博有很多KOL,超过2100家MCN的机构跟微博合作,他们有相当大规模的内容输出,包括短视频、长文、短文等等,所以微博有相当丰富的内容做支撑。

总结下来,与其他产品或者平台相比,微博有两大最主要的特点:
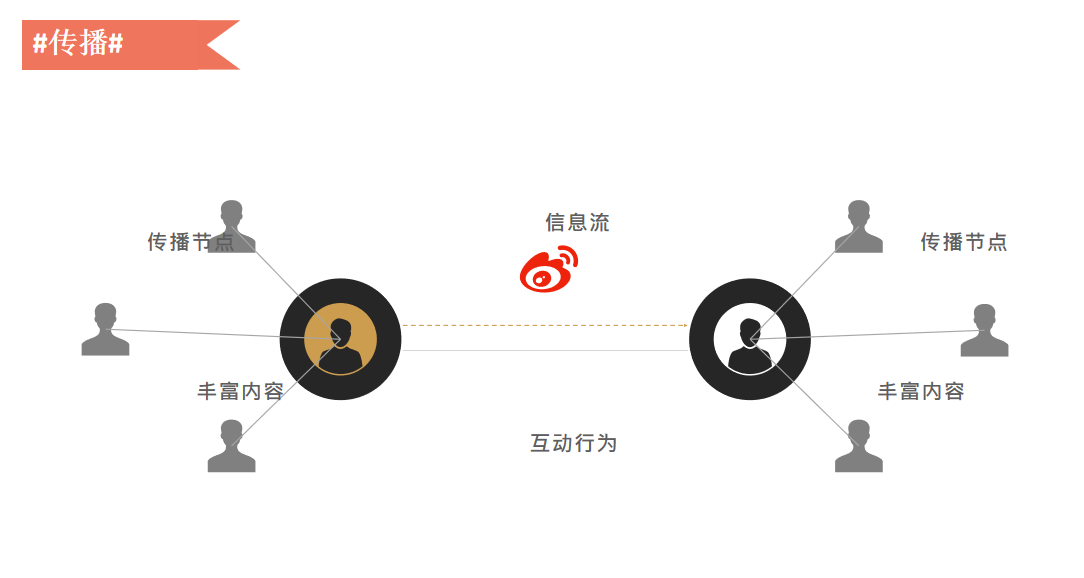
1)传播
前文提到,热门事件经常会在微博上进行传播,在别的平台可能传播速度没有这么快,微信的DAU也有9个亿,但实际上从传播的角度看, 会发现娱乐明星的八卦\热门事件都是从微博传过来的,所以说微博的传播是病毒式的。
举一个例子:#瓶盖挑战#。前段时间微博有这样一个话题,非常有意思,我们可以看到甄志丹蒙面用脚踢开瓶盖,这个话题瞬间拉升了起来,他发布的这条微博有接近900万的播放量。
其他吃瓜群众也开始躁动起来,我们看到这个视频是一位父亲让小孩儿头上顶着瓶子,也模仿甄子丹蒙面把瓶盖踢开,最后把小孩儿踢飞了(苦笑)。
类似的话题,在微博里面是非常多的,我们看了一下这个话题(#瓶盖挑战#)的讨论量接近4.5亿,很多明星,包括李冰冰、赵文卓、周杰伦、以及好莱坞明星杰森·斯坦森等等也都参与了进来。

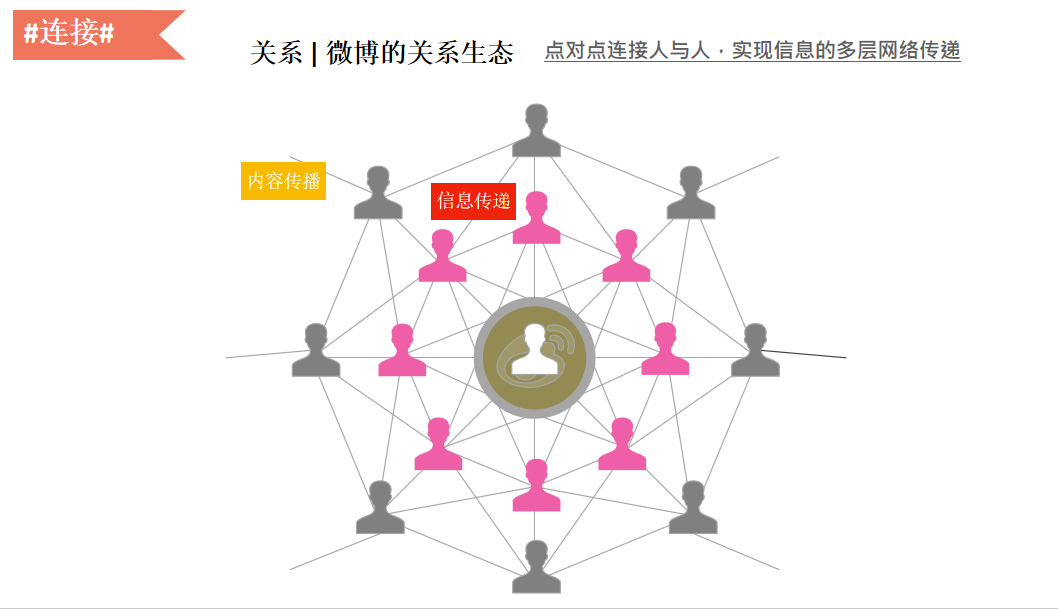
2)连接
微博有“关注”的关系,我们希望看到谁的消息,就可以通过关注的方式去建立连接。这种连接会形成场的效应,通过内容、关系进行大量的社交化连接,也促进了传播,爆炸式或者病毒式的传播都是基于复杂的社交连接的。
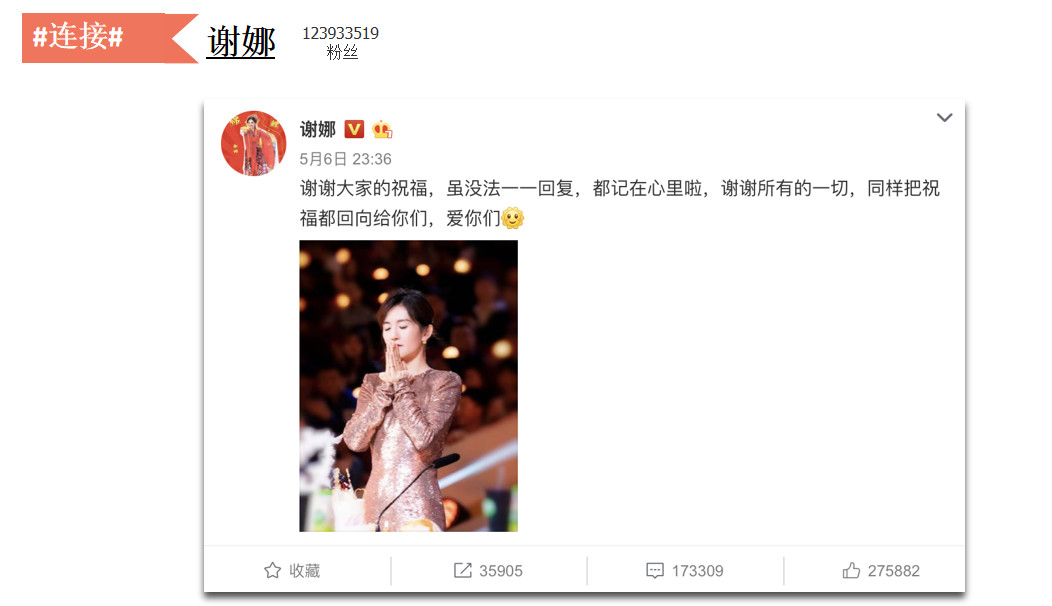
谢娜的粉丝数字已经超过1个亿了,她的任何一条新闻或者微博都会带来大规模的用户互动,如图所示,互动量超过了几十万,这个特点给微博带来了很重要的价值,微博也成为了正能量的传播,包括对负能量的举报、遏制都是非常有帮助的。
比如,去年很多明星自动发起了“中国一点都不能少”的爱国活动,这些微博得到了大规模的传播,也在社会上取得了很大的正能量传播和宣扬爱国情怀的效应。
接下来分享微博怎么将以上特点应用在商业化中。
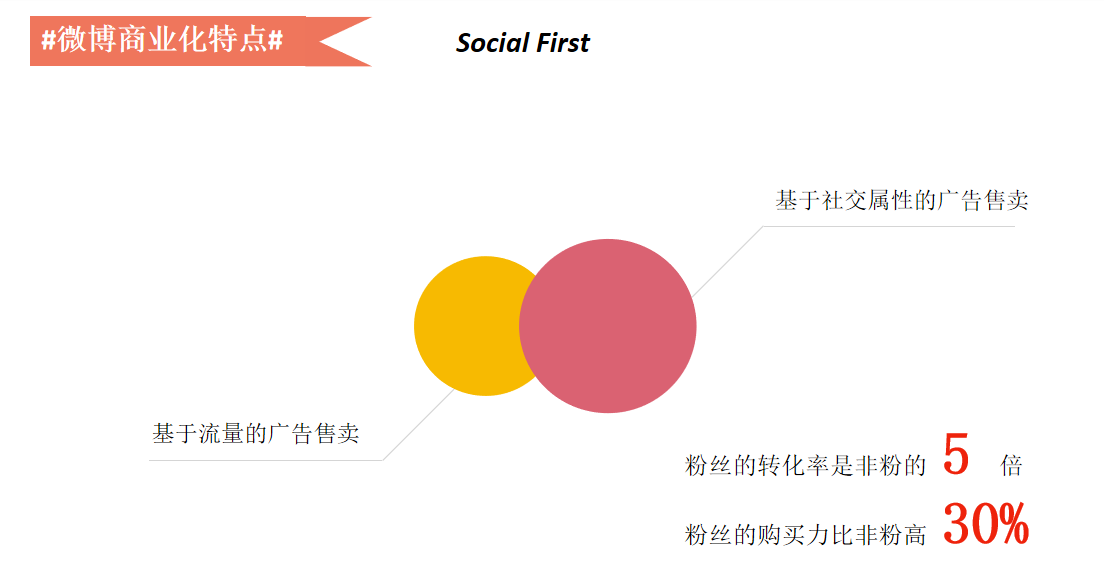
做过商业或者广告的同学都了解过,最开始,做商业化的方式基于流量的售卖,典型代表就是百度,百度广告是基于流量的售卖方式,广告主购买一个流量,按转化(比如点击)效果来付费,还有Google这样的企业都采取按流量售卖的方式。
微博除了按流量以外,还有一个基于社交的售卖方式。上文提到这些明星、大V、KOL都有很多的关注量,通过这种关注关系可以带来瞬间的或者长效的传播。
之前的流量经济中,我们只能去覆盖特定的那批用户,但是通过社交的关系转发、评论、点赞,就可以带来爆炸式的传播,这就是基于社交属性的售卖。
有一个比较有意思的数据,粉丝的转化率是非粉丝的5倍,如果你关注了一个大V,他发微博说某个产品非常好,你被转化成购买者的可能性会高出5倍,粉丝的购买能力也要比非粉高30%。现在明星带货、网红带货的情况越来越普遍,就是这个原理。
再细化一下模型,对于流量经济而言,商业化模型从曝光到吸引再到转化,呈现为如图的漏斗关系,也就是说曝光了1000万个曝光量,最终有1000个转化,这个转化率为万分之一。
这样的漏斗模型中,不关注用户,只关注流量,1000万的曝光量不会带来额外的流量和持续的转化效果。
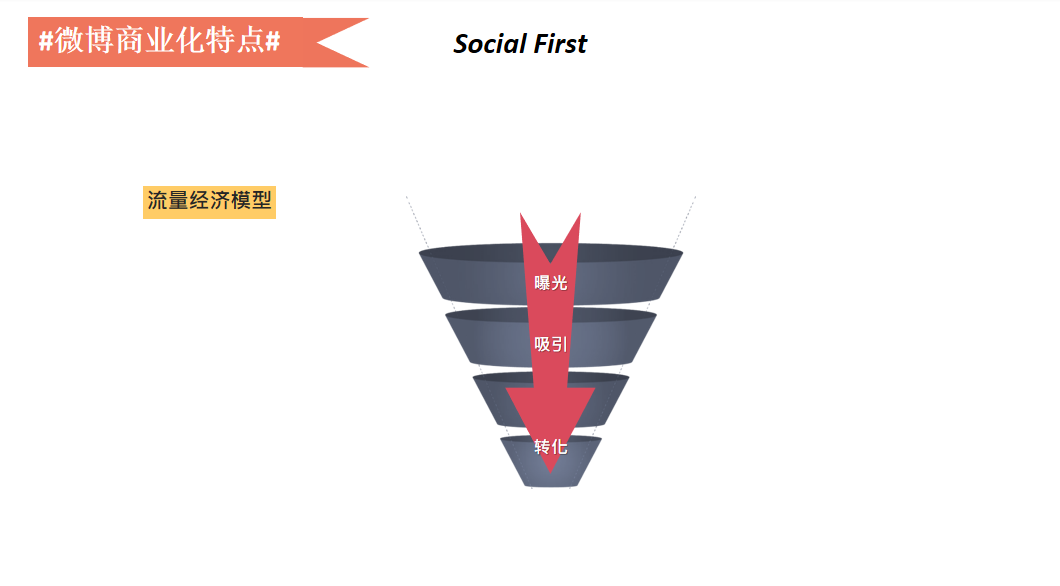
基于社交或者粉丝经济的模型而言,最终目标也是购买,可能会存在两个循环,第一个是上文提到的流量循环,用户对商品从认知到考虑再到评估,如果觉得对自己很有价值,最终会转化成购买,这是一个普通的流量循环。
另一个是忠诚循环,你喜欢这个产品,关注了这个账号或者关注这个产品,如果觉得这个产品非常好,就会推荐给别人,同时会让推荐的朋友又跟这个产品建立一个纽带,这就是持续的忠诚循环,跟产品实现了长期忠诚的连接,也就是Social First,这是微博基于自己独特的社交特点演变出来的粉丝经济的商业化模式,这也是微博有别于其他平台很重要的价值点。
正因为有关注关系这样的社交特点,拿上面基于流量售卖的例子来讲,假设这1000万曝光量最终可以覆盖100万用户,通过流量售卖转化了1000个用户,这1000个用户中有一部分会成为这个商品的关注者和推荐者,进而带动更多的持续购买,这就是忠诚循环。

举一个案例,海尔的手持洗衣机的应用场景如下:吃饭的时候恰好有一滴油滴在衣服上,可是衣服又刚穿上,此时拿去洗比较麻烦,有了手持洗衣机,喷一点就可以立马洗掉。
这个产品是怎么通过微博社交化的模式推广的呢?
在最开始的研发阶段,海尔让粉丝做了一个问卷调查,首先调查粉丝有没有这样的需求。
当很多粉丝反馈说确实有这样的诉求,希望有这样产品的时候,海尔又发动所有的粉丝参与产品的外观设计和功能设计,最后产品出来之后,他们直接在微博上发布,让粉丝购买、传播,带来了巨大的产品营销传播,最后这个产品卖得非常好。

这种模式有别于流量经济,比如,在百度卖一个产品,你需要先生产出一个产品,不管用户喜不喜欢直接卖成品,恰好碰到有些用户喜欢就购买了,不喜欢就不购买。
粉丝经济的玩法是从研发阶段开始就让所有的用户,包括潜在购买者参与进来,辅助设计研发和最后的销售和市场的阶段,这就是微博的Social First。
从另外一个角度来讲,我们如何利用明星和KOL进行商业化?
举一个例子,我们2017年和三只松鼠合作,我们先进行了一轮深度的数据分析,发现三只松鼠的消费者画像跟TF-boys的用户画像契合度非常高,他们大多分布在90和00后群体,女性居多,兴趣爱好是上网、购物和零食。
所以我们让三只松鼠通过TF-boys做营销,最终的结果非常棒,带来了17.7亿的话题阅读量和1400多万的话题讨论量。这对于三只松鼠品牌营销来说起到了巨大作用。

三、微博社交化数据
接下来分享微博如何利用数据,如何把数据的价值发挥到商业化中。
大数据是金矿,但里面掺杂着很多沙子,要把沙子剥掉,就需要用到相关大数据的技术。
我们来更细致地聊数据,作为开场,我们一起看一下上海的用户特点和用户画像是什么样子的。
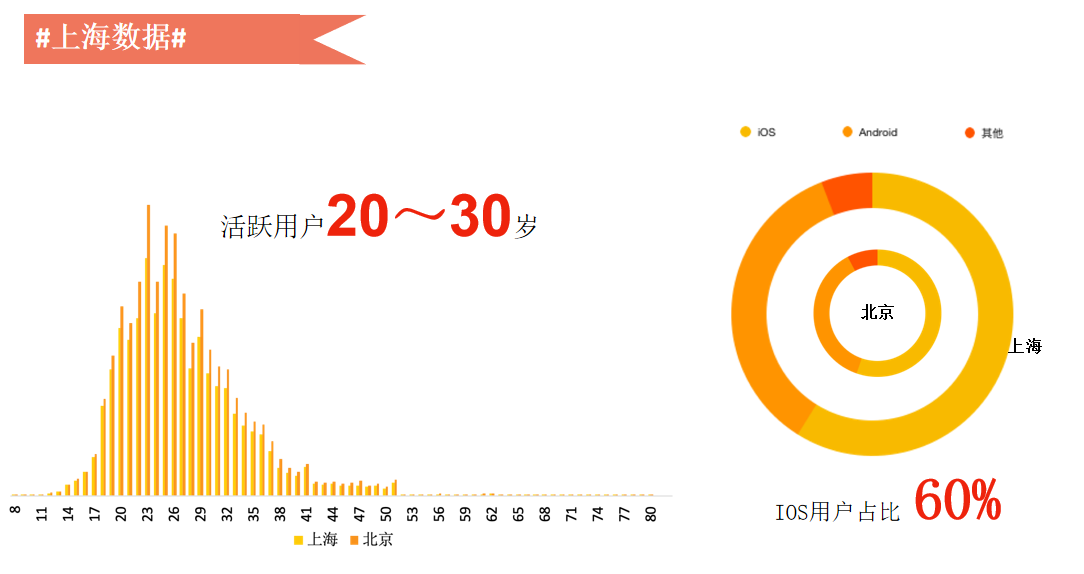
我们拿上海和北京做对比,可以看到,上海和北京的用户年龄其实是差不多的,都是在20-30岁,这个数据回答了一个问题,很多人说自己不用微博,为什么微博的DAU还有2个亿?可能是因为我们老了,年轻人还是继续在用微博,尤其是学生。
上海和北京的用户使用的手机品牌也是IOS最多,我们发现一线城市IOS用户规模比较大,可能上海比北京的IOS占比还会更高一点,上海用户使用的手机品牌也会更丰富一点。
关于上海话题,我们发现垃圾分类最近一两个月活跃度非常高,其中“上海垃圾分类个人扔错罚款”的话题已经覆盖了43万。所以上海讨论的话题主要集中在垃圾分类这一部分上。

在用户兴趣关键词这一方面,我们可以看出上海和北京的差异。北京比较多的是口腔医学、生活、整牙、空气干燥、教育。上海就比较时尚一点,其兴趣关键词有二次元、日韩文化、美妆、婚纱、美容还有垃圾分类。

另外,北京比较关注房地产,前段时间雷布斯也发了一条微博,称经过了九年的奋斗终于买房了,房子比较贵,52亿。

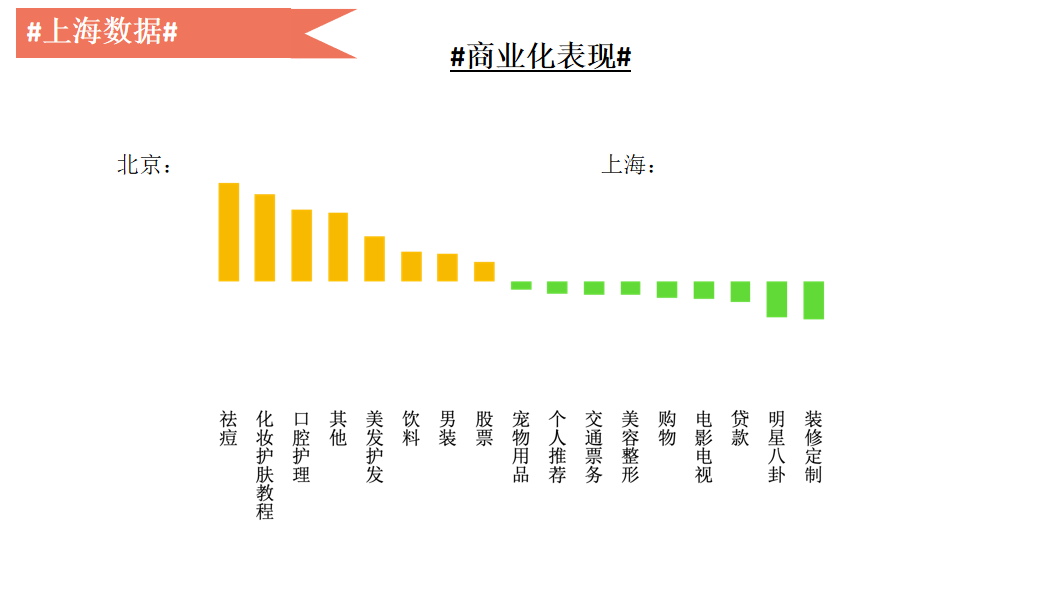
从商业的角度来讲我们投的广告中上海和北京关键词的差别。如图,北京祛痘是第一个,上海较多的是明星八卦。两个地方在数据层面存在较大的差异。
我们怎么利用好数据为未来收入增长助力呢?要做好四个点。
1)用户画像
数据挖掘,从用户画像开始。
上文可以看到上海和北京的用户画像的差别,用户画像不仅服务于商业产品,对用户产品也很重要,如果我们不能了解用户是什么样子的、有什么喜好,就没有办法更好地为他服务。
因此,我们调查微博上大量用户的行为,包括各种互动行为,通过这些互动行为挖掘到用户真实的画像。
我们对用户画像建立了非常详细的标签体系,这里列了一个提纲。
标签体系可以包含人口统计类型指标,比如年龄、性别、地域,这是一个最基本的人口统计学指标,除此之外,还有兴趣类别类型指标、兴趣关键词类型指标、关注关系类型指标、预测类类型指标、互动行为类型指标等等,建立一套非常复杂的用户标签体系是用户画像的基础。
接下来做商业化的应用,用户画像可以从两个维度来辅助于商业化:
① 广告定向
商业化应用里跟用户侧的推荐系统不一样,我们需要建立商业广告、广告主跟用户之间的连接,也就是下图右边这条线。
这条线是通过用户画像来做的,广告主会选择定向条件(用于圈定人群),比如投放上海20-30岁的男性用户,这就是定向。
广告系统的作用是根据广告主的定向寻找与之匹配的人群(即用户画像与广告定向的匹配),这里面会包含精准的定向,也包含泛化的定向匹配。这个过程在广告系统里通常叫targeting或者叫召回。
② 算法特征
在CTR预估上会引入画像,以此来提高CTR预估算法的能力。
广告系统通过targeting得到了与用户相关的一系列广告候选集,为了让流量价值最大化,保证广告主的广告投放效果最优,通常需要进行广告候选集合的排序,这个排序叫ranking。
ranking的基本思路就是按照广告主出价和CTR的高低来进行(具体模型可以参考相关资料),因此CTR的预估就至关重要,用户画像能一定程度表征了某类用户对广告的喜好程度,在CTR预估尤其是基于深度学习(DNN、RNN等)的预估模型中,通常会加入用户画像作为特征。

2)捕获即时兴趣
除了要建立更加完善、丰富的用户体系之外,我们要让数据动起来。数据放在那儿不动的话没有任何价值,我们需要让它动起来。
举两个在微博商业化中所使用的例子,第一个让数据动起来是仓库,很多同学做过离线仓库相关工作,为了减少不必要的计算和存储,数据仓库一般是分层设计的,底层ODS到中间DWD再到最上面的DWS层。
但是离线的仓库有一个很大的问题,数据基本上是按天算的。当然,现在也有小时表,但基本上很多数据是按天计算出报表的。
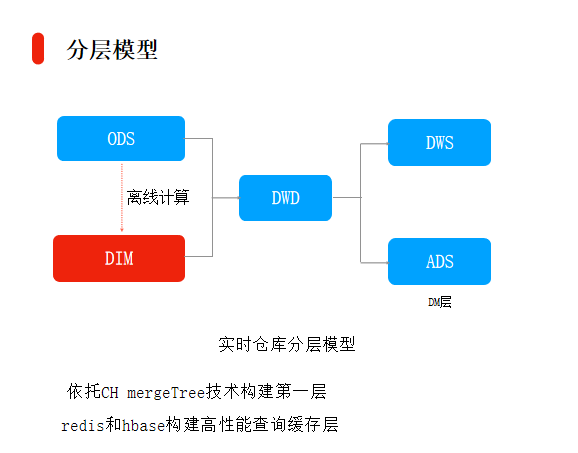
对于我们这种社交化的产品来讲,使用离线方法会难以捕获用户的行为,进行数据分析时也不可能等到第二天再去看数据。
因此,我们需要建立一套实时仓库的模型,结合离线仓库的经验,我们使用了一些存储构建这样的体系,主要是为了上层的数据分析,包括CTR的实施特征的捕捉。同时,在一定程度上也可以减少数据的重复计算。
下图是我们的效果数据,可以看到计算规模从248亿条降到137亿条,减少了很多重复的计算,对内存资源到CPU资源都有极大的降低。

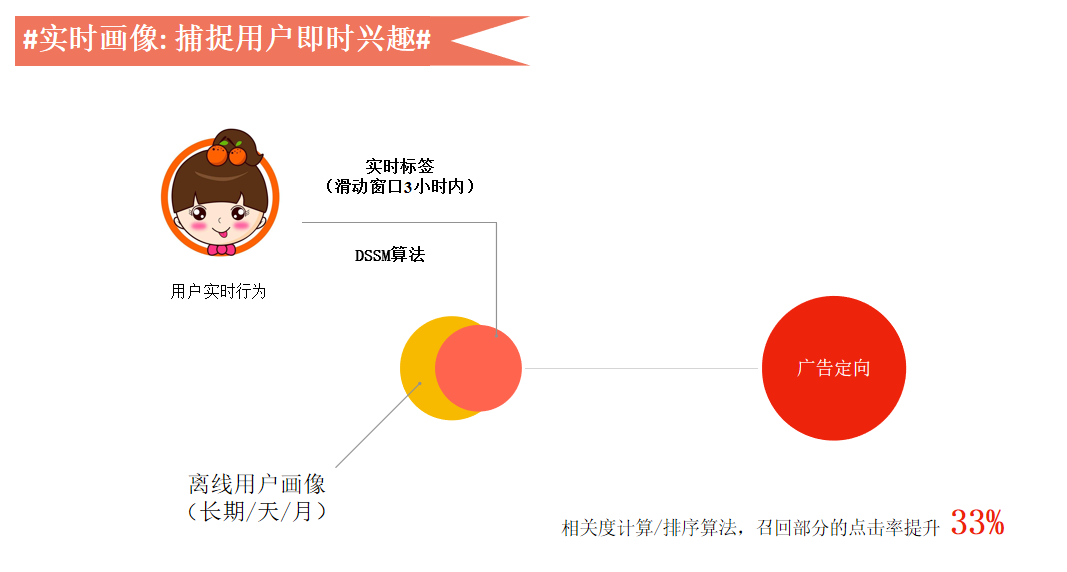
第二是要捕获用户的即时兴趣,这也非常关键,刚才提到的用户画像大部分基于长期的兴趣。
但实际上用户的短期兴趣更有用,比如用户刚刚阅读了关于汽车文章,可能反映出用户对汽车比较感兴趣,这个数据要反馈到广告系统里面,需要有一套实时标签计算架构,捕获到用户的实时行为。
引入实时行为对于点击率有33%的提升,所以让数据动起来是非常有必要的。
3)数据挖掘
数据挖掘的范畴非常大,包括语音、图像的识别,文本、视频的挖掘等等,在此举一个在商业化里面经常用到的例子。
它的基本原理如下,从下图左边的用户里面寻找相似用户,再扩展这些用户,扩展到一定的体量。
应用场景如下,广告主积累了购买过商品的10万转化用户,接下来看看这10万用户有没有什么特点,能不能扩展到100万客户,根据一个种子人群的特点来扩展一波用户,这波用户就是高转化的用户。

举一个案例,“曹操出行”是我们的客户,我们就是通过lookalike这样的技术将它的转化成本从100降到40,效果非常明显。
4)科学实验
最后讲一下数据驱动中最重要、最核心的一部分——科学实验。
我们在产品设计和功能设计上经常会遇到一些不确定性的问题,比如说要增加一个功能,这个按钮到底对我们产品有没有用处呢?效果是什么样子呢?应对这样的不确定性问题,就需要有一套科学实验的体系来辅助决策,这时候就需要科学实验平台。
举两个案例,第一个案例是电商网站Yuppiechef,下图左边是原来的网站首页,右边是测试的首页,差别就是红框那部分,黑色是导航菜单栏,右边把导航菜单栏去掉了。
我们发现去掉导航栏以后商品购买和转化率提高了一倍,最后分析出有了导航,用户的注意力会被分散掉,很多用户点菜单去了,没有点商品。
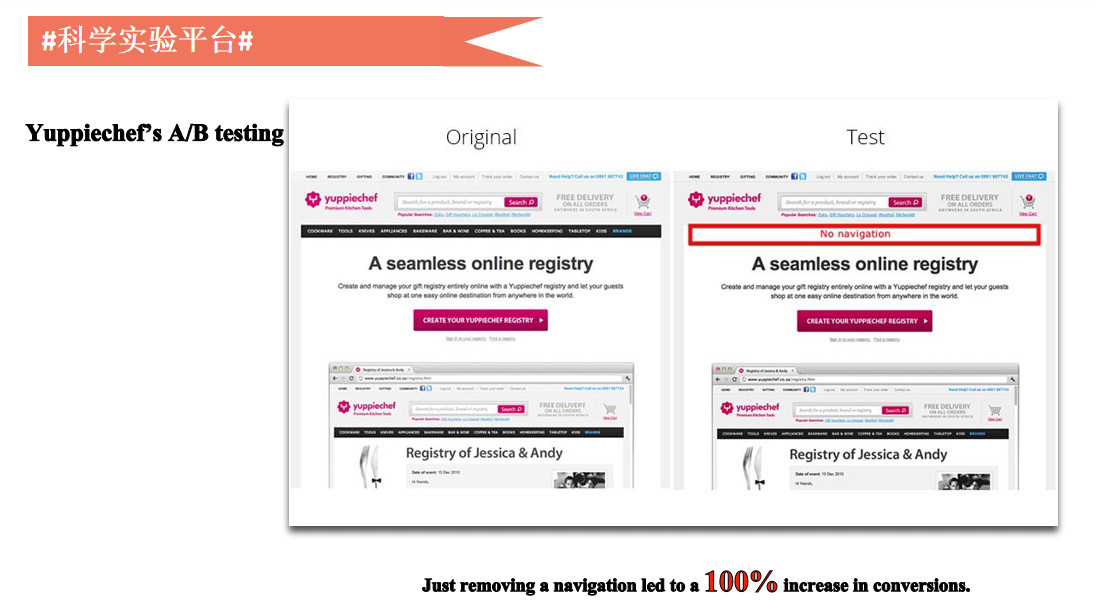
那么是不是注意力就应该集中,不该被分散掉呢?这个结论也是不一定正确。
第二个案例是一个医疗网站加了一个使用说明的链接,有链接的按钮转化率居然提高了244%,同样的原理,这个案例会引起注意力被分散的情况,效果反而比上面的案例效果好了。

因此,很多情况直观来讲很难判断最终的结果,因为我们很难去判断用户的喜好到底是怎么样的,需要通过非常科学的实验平台帮忙做判断,有这个平台以后,我们就能更加科学地判断、做决策。
分享一张系统架构图,本次分享技术方面的内容偏少一点,更多是讲想法和总结出来的经验。
这里不再详细讲,大家的做法都是一样的,这是基于Google分层实验框架模型来做的,里面的技术也都用了大数据处理、实时流计算,包括存储引擎等技术。

四、微博商业化增长
2014年微博上市,营收几千万,当时有人调侃说你们赚的钱只够在北京买一套房的。
但是经过2014-2019年大概五年时间的发展,去年的营收已经到100多亿了,增长非常快,这里面离不开我们使用到的数据驱动的方法,包括上文提到的科学实验方法。
接下来聊一下增长的情况,增长包含用户的增长和客户的增长。
在商业方面,我们可能需要增加广告主,增加客户数,在用户侧方面,我们需要提高DAU、MAU,把用户的规模做大,这是头条系不断拓展海外市场的重要原因。
最终要实现用户跟商业侧的健康生态,我们不希望广告放到内容里面让用户反感,而是期望广告对用户有帮助。
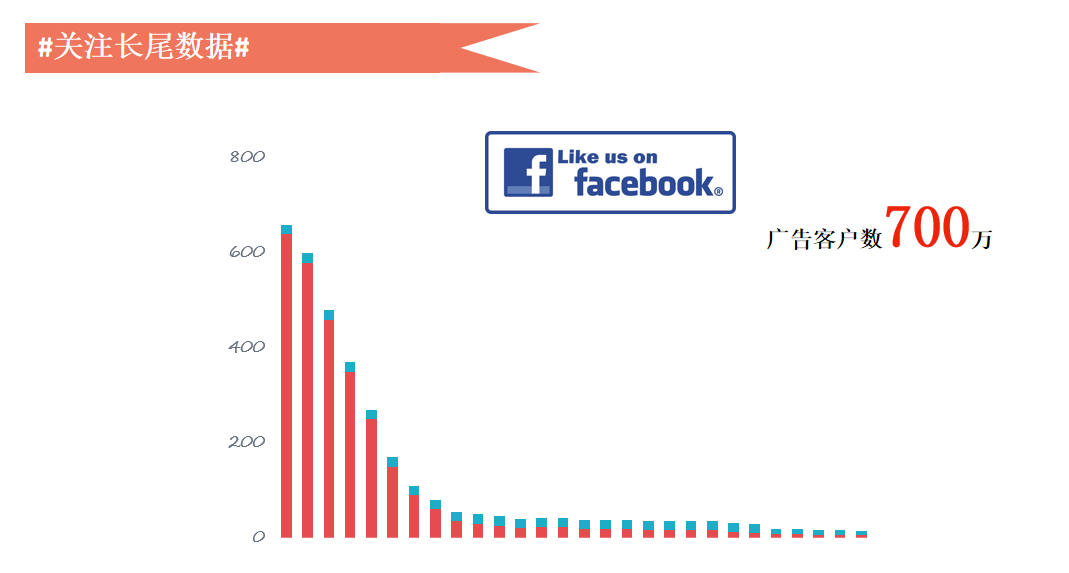
举一个Facebook的例子,Facebook是最早的社交媒体,广告客户数超过700万,客户规模非常庞大,国内的百度的规模接近100万,跟他们的差距还是非常大的。
对于这么大的体量客户来讲,它的品牌或者头部客户占比也不会太多,可能就是百分之十几,剩下的全部是长尾。中小企业的规模是非常大的,我们利用好中长尾帮他们解决效果问题,就能最终实现收入的增长。
商业增长更要关注客户增长、效果增长,流量利用率和变现效率增长。
我们要关注效果,提升流量的利用率,最终做到变现效率的提升。
我们团队根据不同的忠诚度等级,对客户的级别会分成头部、中部、尾部三个等级。
对于不同的等级,我们会有不同的数据进行分析和处理,会监测健康度。
比如说头部客户发生变化了,我们要及时调整策略。
尾部客户发生变化可能情况还好,影响会小一点。
新客发生变化了,需要通过一些策略把新客保育起来,比如给新客增加一些优惠的措施等等,让这些客户留存下来。
做过数据分析或者数据处理的同学可能知道,我们每天看到指标是非常多的,看到成百上千的指标,都不知道最后哪些指标对我们是有用的。
因此我们需要把所有的指标抽象出来,提炼成一些比较简单的指标,类似于芝麻信用的信用得分。
我们将代理商的情况,平台的指标,分成不同的维度,会通过数据模型算出来最终计算成一个值,每天看这个指标即可。
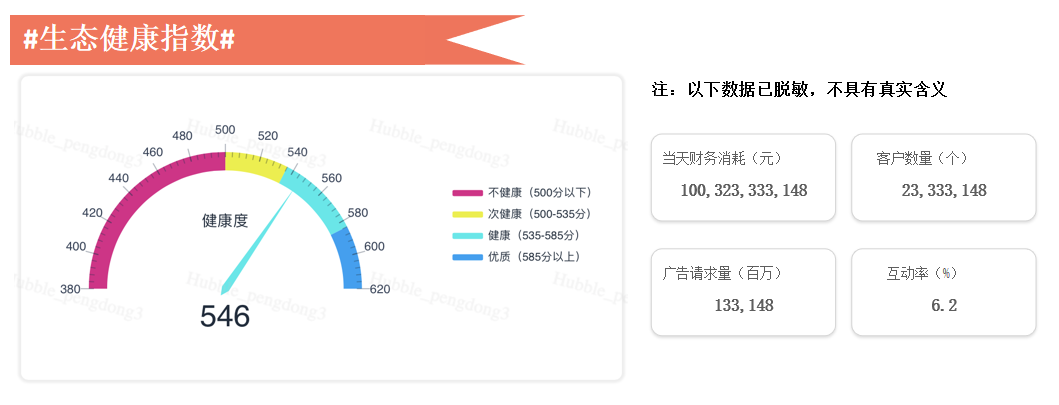
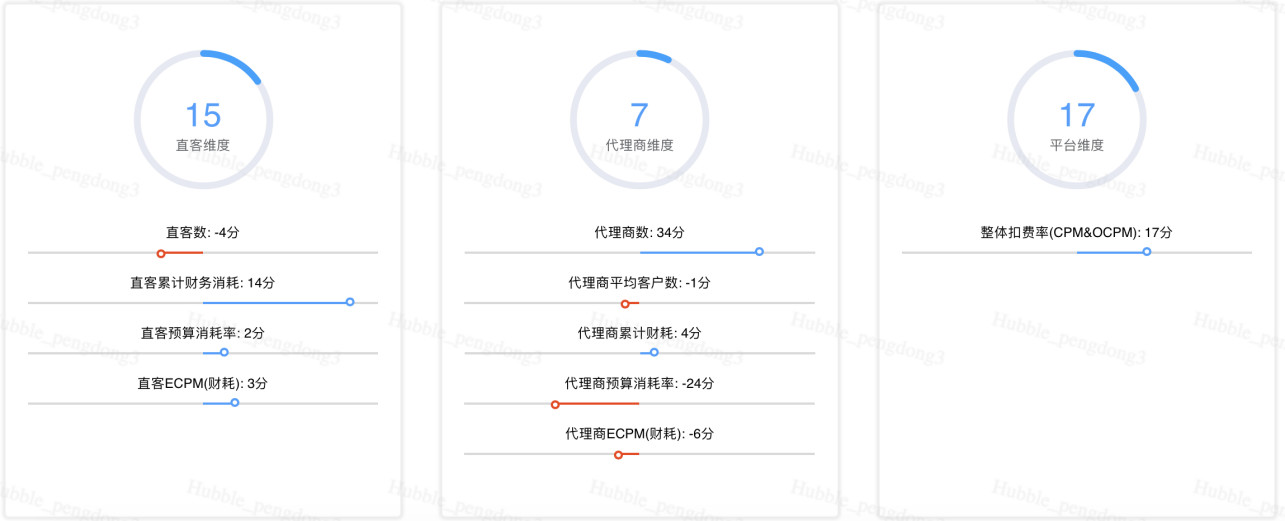
商业的增长,本质上是解决客户ROI,让客户赚钱。如果不能让客户赚钱,我们这个平台存在的价值就非常小了。
上文提到中长尾的客户,你只要让他赚1块钱,他就愿意付费,持续投入预算。所以解决客户的ROI非常关键,举一个O2O行业(我们最近在O2O这个方向,腾讯也在这个方向加大了力度)的例子:2017年中国餐饮行业数据情况。
餐饮行业其实非常惨,月倒闭率是10%,年复合倒闭率是100%,一线城市半年时间就倒闭的餐厅数是16万,经常看到楼下的餐厅过段时间就换一个。
他们会受到线上电商平台的冲击,也会受到竞争对手的竞争压力,还会受到房租、人员工资、设备等等各种因素的影响。

我们需要帮这些客户建立ROI,让他们赚到钱,让他们找到自己的客户或者消费者,这是我们平台的使命。
80%的消费者关注口碑,我们经常会看一下点评再决定去哪儿吃。微博也有类似功能,微博里面有评论,评论对于客户或者商家来讲是非常重要的。
数据分析是商业增长的基石,我们团队里有数据分析师,有的团队把数据分析师称为数据科学家,因为既要懂数据,又要懂数据模型,又要懂一些算法,还要懂一些统计学的原理。他们的主要职责是通过数据找到问题,再快速解决问题,提高增长。
举一个通过数据分析解决实际问题的案例,百威啤酒在微博的粉丝数大概有400万,名称也比较有意思:“一个不满18岁就不能关注的账号”。
下图是百威啤酒发的广告,内容选取了上海,发的微博非常有意思,把上海体现得非常魔幻。
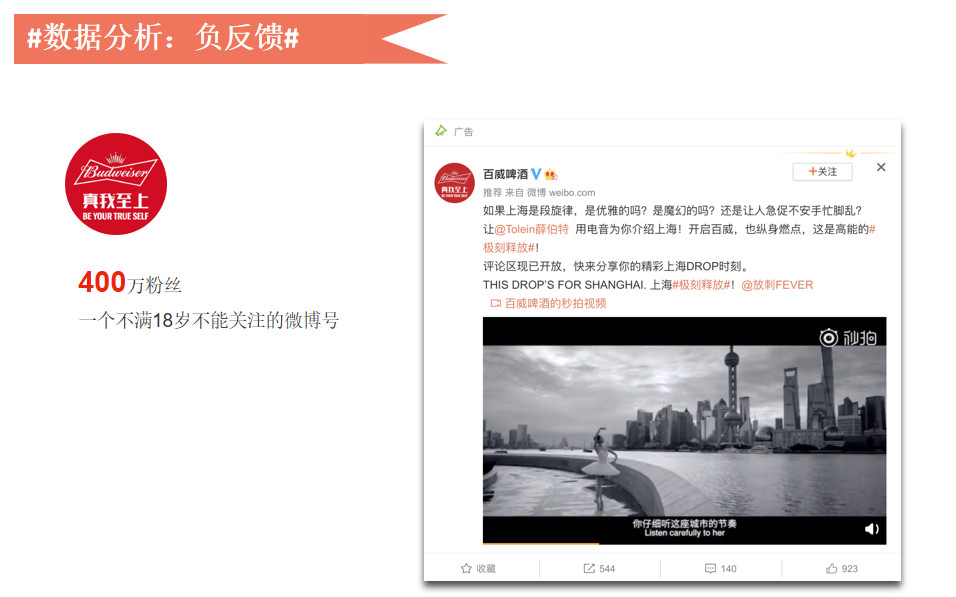
但你会发现,即使是这么有意境的博文,还是会有人不喜欢(微博右上角点叉,可以表达不感兴趣)。
我们后来通过数据分析发现,一周有五次以上点不感兴趣的用户数占总用户大概千分之四,曝光量是千分之九,曝光量会影响到我们收入,曝光量越大收入就会越多。
但是负反馈量却占了46%,这是什么概念呢?就是有一群用户什么广告都不愿意看。
有了数据分析和结论之后,我们进行了对比实验,建立一个Filter机制,去掉这群用户,不让他们看广告,他们本身很反感广告,让他们看也没有用,对广告主来讲又是白投了。所以用简单的过滤机制把这部分用户过滤掉就好了,我们发现这样做的效果非常好。

这个例子让我们发现,很多业务的增长没有想象中那么复杂,只需要进行数据分析,挖掘出数据里面有价值的东西,再做相应的策略和机制就好了。
就像Youtube是允许跳过广告的。在国内视频广告里面,基本上一个广告2分钟,但Youtube就敢让用户跳过。
为什么会有这样的信心呢?它涉及的理论依据就是上文所提到的,有一群用户就是不喜欢广告,即使给他推非常有意思的广告他也不看,对于这些用户,直接过滤掉就好了,原理就是这么简单。
有的时候数据是很有意思的,关键在于怎么发掘它的意义,把它转化成业务,推动我们业务的增长。
以上就是我的全部内容,谢谢大家。
Q1:我们在收集的时候发现标签越来越多,还有些是冷的,像噪音类的标签,这类怎么处理呢?
A:首先标签体系按一类、二类划分,我不知道你们是如何建立用户画像的,至少我们需要进行分层,一般分到三个级别就可以了,这时标签就已经建立起来了。
同时,标签需要有更新机制,有些标签要不停地去迭代,而且还要建立标签监控的机制。比如说标签覆盖了多少用户?使用率怎么样?你得有这个数据,有这个数据之后才知道怎么去淘汰和新增。
比如说我们在广告定向里有一个用户登录频次的标签,分为:偶尔、经常。
你会发现广告主投偶尔这个标签效果非常好,但是我们观察到偶尔用户覆盖率不多,我们就得想办法通过数据挖掘方式挖这部分标签,让这部分标签覆盖数更大,通过这种方式逐渐迭代,让标签更加完善。
Q2:实时数仓建设那部分你们第一步直接放在ClickHouse,标准做法轻度聚合,能详细介绍一下吗?
A:我们使用ClickHouse,是会分多个层次的,也是为了上层接近业务,下层接近数据,中间做一些处理的工作,这些都会生成中间的表,这些数据会放到ClickHouse里,可以参考离线仓库的分层模型,我们只是用ClickHouse作为存储和查询引擎。
Q3:每一层怎么调度?
A3:我们用Flink去算(包括一部分的聚合、关联、过滤等操作),算完更新数据到ClickHouse就好了,因此每一层不会有调度关系,实时仓库里的这个层是一个逻辑概念。
Q4:你们这个广告覆盖了合约广告?
A:在我们这儿叫品牌广告或者KA广告,通过合同的方式,比如大家经常看到的微博开机广告就是合约广告,另外在信息流里也有,不过比较原生,从创意样式上不太容易区分。
Q5:有些用户不喜欢看广告却不关掉,这些用户数据量有多大?有没有想办法转化这些用户?
A:我们不想转化这部分用户了,而且这部分用户规模非常小,因为负反馈率是千分之一,这个量是非常小的。
刚才分析也看到,很多用户要点五次,你给他看广告也没用,我们是按CPM计费方式算广告主的钱,把这部分去掉就好了。
对于其他用户来讲,因为广告系统要做的事情是让用户看到他真正想要的广告,这也是我们平台的使命。
提到这点我想补充一下,我们经常会反感广告,其实有点先入为主,广告其实也是我们日常的一种需求。
比如说买车的诉求,购房的诉求,有可能长痘痘了,有去痘的诉求。
这些诉求是真实存在的,因此广告也是有存在的价值,只是说是否能够让用户真正看到他想要的产品,让广告客户触达到自己真正的目标受众,这是我们广告平台方要完成的使命。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721