
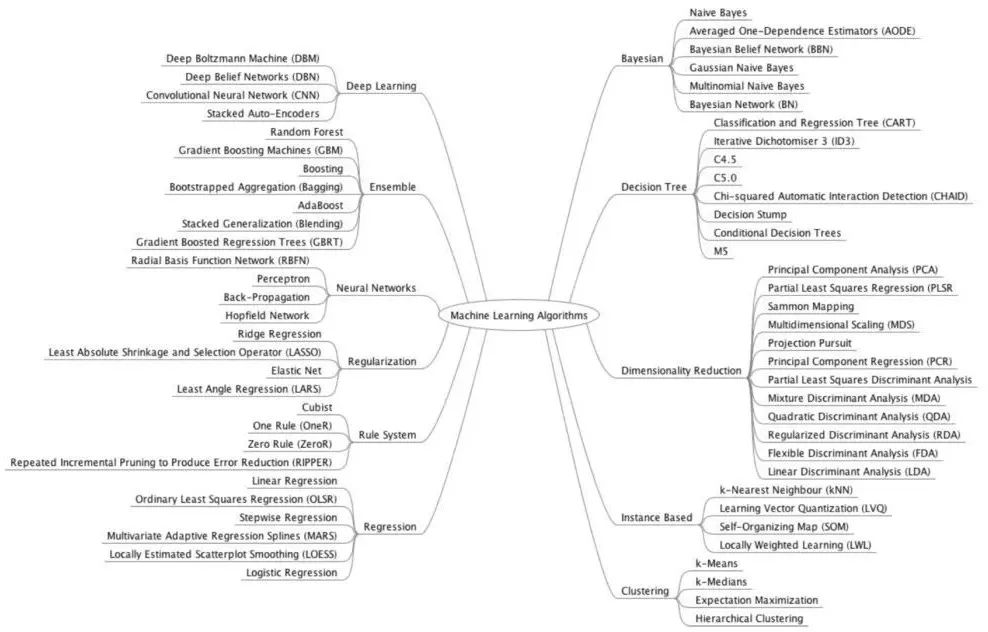
▲ 机器学习模型概要
我最开始使用机器学习来解决问题时,会尝试许多机器学习模型,并从中选择最有效的一个。而我现在依然这么做,不过会遵循一些关于如何选择机器学习模型的最佳实践经验。这些经验是从经历、直觉和同事中学到的,它们会让事情变得更容易。以下是我收集的内容。
我会根据你问题的本质来告诉你要使用哪种机器学习模型,还会尽量解释一些概念。
一、分类问题
首先,假设你有一个“预测给定输入类别”的分类问题。
请记清楚你将对输入进行分类的类别数目,由于有些分类器不支持多类预测,它们仅能支持2类预测。
非线性支持向量机(SVM) 有关使用SVM的更多信息,请查看分类问题结尾部分的注意事项;
随机森林(Random Forest);
神经网络(需要大量数据点);
梯度提升决策树(Gradient Boosting Tree,类似于随机森林,但容易过度拟合)。
可解释的模型:决策树和逻辑回归;
不可解释的模型:线性支持向量机(SVM)和朴素贝叶斯(Naive Bayes)。
注意:对支持向量机(SVM)内核的选择(来自吴恩达的课程)
当特征数量大于观测数量时,使用线性内核;
当观测数量大于特征数量时,使用高斯核心;
如果观测数量大于50k,使用高斯内核时速度可能会成为问题;因此这时可以考虑使用线性内核。
二、回归问题
如果你的问题是“给定房子的大小、房间的数量等特征,让你预测房子的价格”,那么这是一个预测连续取值的回归问题。
随机森林(Random Forest);
神经网络(需要大量数据点);
梯度提升决策树(类似于随机森林,但容易过度拟合)。
决策树;
线性回归。
三、聚类分析问题
如果你的问题是“根据数据的特征将它们分成k组,使得同一组里的对象具有某种程度的相似性”,那么这是一种聚类分析问题。
层次聚类分析(Hierarchy Clustering Analysis,HCA)是一种旨在构建聚类层次结构的聚类分析方法。层次聚类分析通常分为两种策略:
凝聚:这是一种“自下而上”的方法。每个观测点从自己的集群开始凝聚,当一个集群向上移动时,成对的集群将进行合并。;
分裂:这是一种“自上而下”的方法。所有观测点都在一个群集中开始分裂,当一个集群向下移动时,递归地执行分割。
DBSCAN(不需要指定k的值,即集群的数量);
k-means;
混合高斯模型。
如果你对分类数据进行聚类分析,请使用k-modes。
四、维度降低方法
使用主成分分析(PCA)方法
PCA可以理解为将n维椭球拟合到数据中,其中椭球的每个轴代表一个主要成分。如果椭圆体的某个轴很小,那么沿该轴的方差也很小。从数据集的表示中省略该轴及其相应的主成分,我们只会丢失相当少量的信息。
如果你想进行主题建模(后面将解释),你可以使用奇异值分解(SVD)或隐含狄利克雷分析(Latent Dirichlet Analysis,LDA)方法,并在进行概率主题建模时使用LDA。
主题建模是一种统计模型,用于发现文档集合中出现的抽象“主题”。主题建模是一种常用的文本挖掘工具,用于发现文本体隐藏的语义结构。
希望对你来说现在事情变得容易些了,我会根据你从反馈和实验中得到的信息更新这篇文章。
最后,这是两个非常好的概要,供你参考。
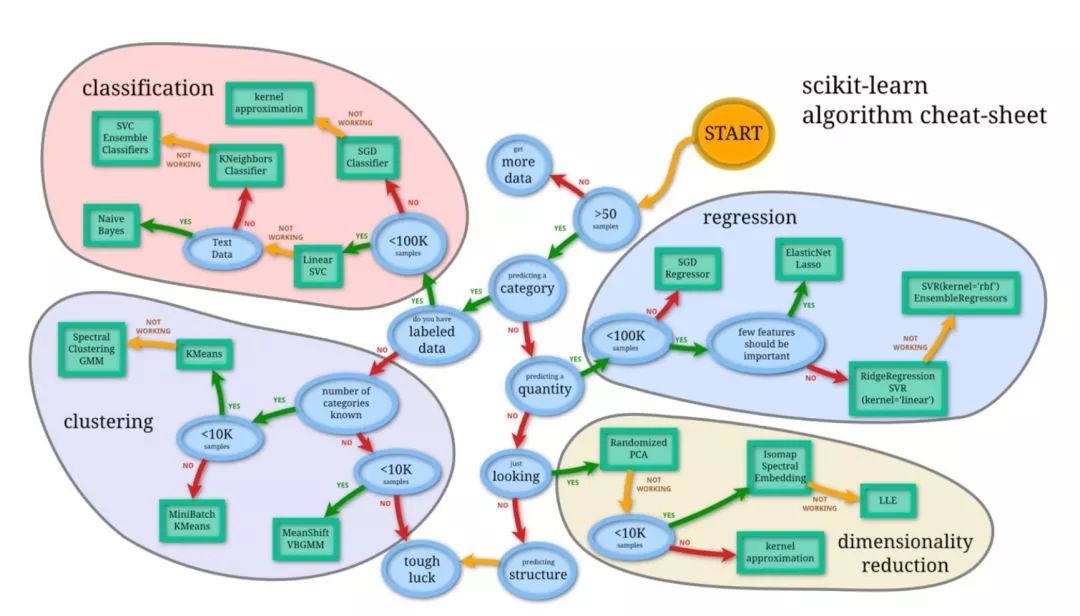
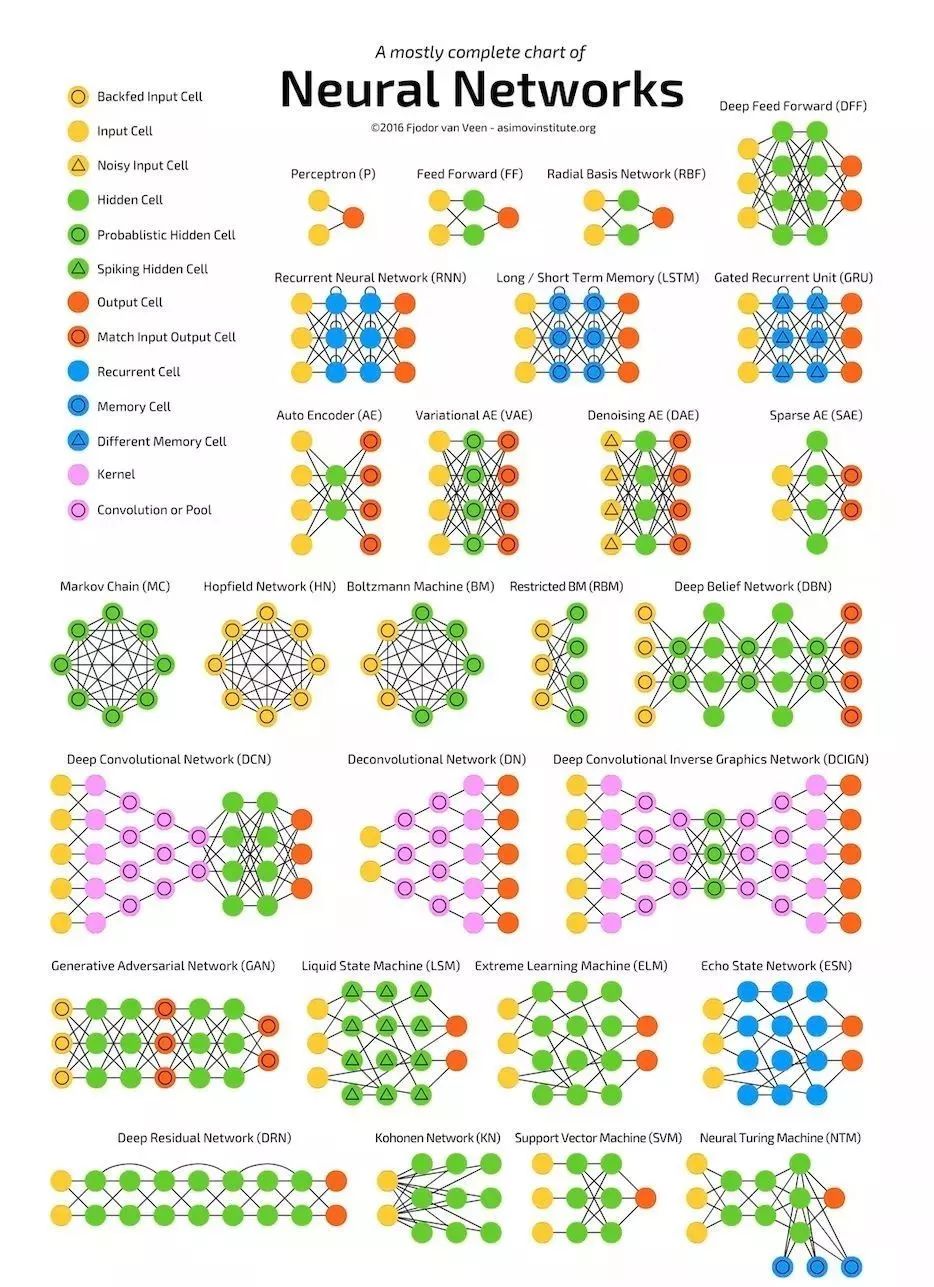
参考资料
作者:Maher 译者:吴鑫全 校对:杨鹏岳
来源:图灵TOPIA(ID:turingtopia)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721