
作者介绍
冯武,目前在瓜子从事大数据集群运维管理,主要负责Hadoop、Ansible、Ambari、Cloudera Manager等技术栈的维护调优工作。
公司从建设Hadoop起,采用了Apache社区版本的Hadoop,随着业务的发展,集群规模越来越来大,现已突破百余节点。
在频繁的更改配置、增删节点、监控告警等操作中,传统手工运维的弊端被放得越来越大,日常维护消耗了工程师大量的时间和精力。
现状的产生是可以理解的,公司基础架构的发展往往始于快速搭建,然后在崩溃中挣扎,最后瓶颈痛苦后经历重构。本文将介绍,我们团队如何一步一步优化Hadoop运维部署架构。
一、梳理痛点,调研并制定最优方案
多个组件,HA配置,部署方案存在风险:
HDFS HA配置不够完善;
Yarn没有HA;
HiveServer2 / Hive MetaStore没有HA;
NameNode与JournalNode混合部署;
Zookeeper与DataNode混合部署。
哪台机器安装哪些进程,不可知:
历史遗留问题,首先各机器服务安装清单不齐全,需手工维护;
安装各类小工具,已不可考证。
没有机架感知(rack level)相关配置:
HDFS的持久性会经受考验,没有跨机架的3副本。
各组件的conf管理方式原始,各节点配置没有统一管理:
调参,目前依赖逐台机器的con_bak方式;
conf没有版本控制,各worker节点可能各不相同,导致资源错配、浪费;
conf没法按机器分组,也没有记录维护分组的地方。
无客户端管理:
客户端如果管理不到位,影响admin做大部分的参数调优,部署调整,严重影响Hadoop的可维护性。
HDFS依赖的JournalNode仍然和NameNode混合部署:
NameNode主盘的IOPS已经很高了。
日常运维麻烦:
重启一个进程,至少需要4步:ssh到跳板机→ssh到目标机→切换Hadoop用户→重启服务命令;
滚动重启没有正规化的trigger,很难做集群级别的调参。
监控报警不全:
没有Hadoop工具集的统一探针服务;
人工给各组件添加prometheus collector工作压力巨大。
机器操作系统不统一:
40% ubuntu;
60% centos。
没有用DNS解析,需要维护/etc/hosts。
为了一次性解决以上尽可能多的痛点,不得不思考跳出手工运维的大坑。我们整理出了三种方案:
方案一,采用Ansible工具进行半自动管理,经过一段时间使用,批量部署修改效率明显提升,但是配置管理等依然不方便,容易失误;
方案二,先采用Ansible过渡,采用Cloudera Manager托管现Apache集群,在托管测试中发现CDH 5.x的Hadoop版本为2.6.0,而公司用的Hadoop版本为2.7.2,有大版本的跨跃,且被托管需要Hadoop降版本,这个无法实现,所以失败;
方案三,先采用Ansible过渡,采用Ambari托管现Apache集群,采用HDP 2.6.5版本与现集群几乎匹配,可升级。
平台升级一般有2种大的选择:
第一种是原地升级即直接在原有平台上操作,该办法操作效率较高,马上看到效果,但往往风险较高,比如升级失败回滚方案不完善,可能HDFS还有丢数据的风险;
第二种是拷贝数据的方式升级,需要额外的服务器资源,需要新搭平台,然后把旧平台的数据拷贝过去,数据拷贝完毕后,再把旧集群的机器下线了慢慢加入到新集群,该方法一般实施周期较长,但风险较小。
根据实际情况(成本/可行性分析)考虑,最后选择方案三:Apache集群原地升级Ambari-HDP。
原地升级该怎么做?主要有以下思考:
第一,升级的重中之重是HDFS,只要HDFS完成托管且数据不丢失,其他组件Yarn、HBase就能水到渠成,这样我们主要精力放到HDFS的升级上面;
第二,Apache集群的HDFS版本为2.7.2,HDP的为2.7.3,NameNode元数据的结构是一致的;
第三,HDP版本和Apache的解析数据的方式、原理是一样的,只有进程启动的方式、配置文件的目录不一样。
所以只要把Apache HDFS的元数据拷贝到HDP的元数据目录,然后用HDP命令启动Name Node就可以升级NameNode;DataNode同理,HDP启动DataNode只要配置中指向老集群的数据目录即可。如此,Apache的HDFS就可升级成HDP版本。
下图是整个集群升级前后的部署全景对比:
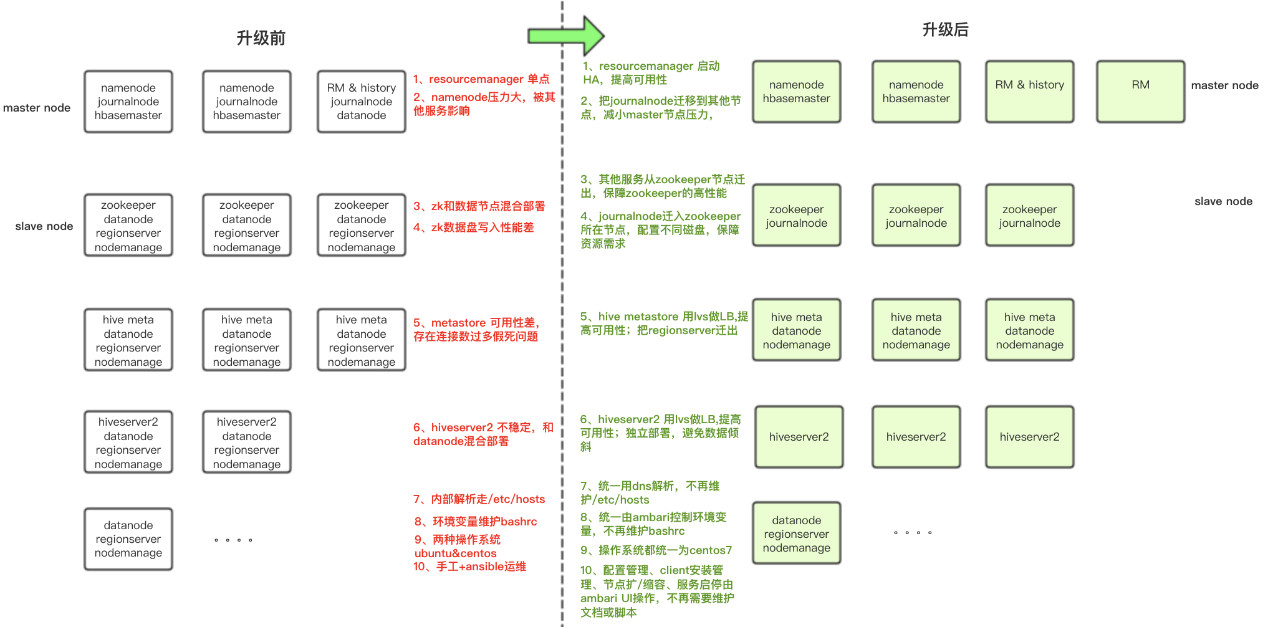
(点击图片可查看清晰大图)
下图是整个集群的操作流程:
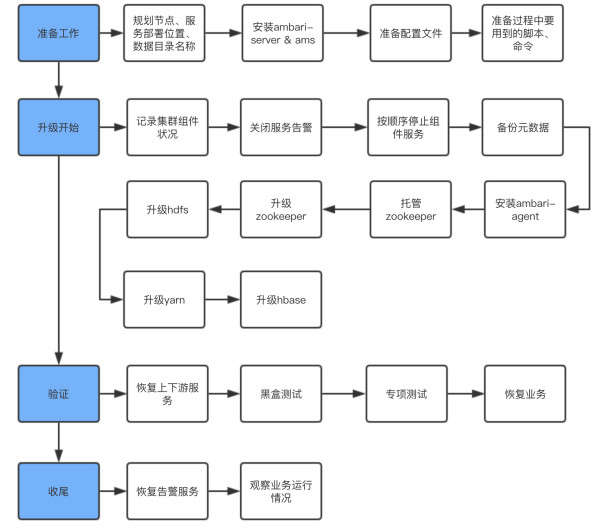
(点击图片可查看清晰大图)
二、各组件升级的技术本质和挑战
升级顺序是:
Zookeeper → HDFS → Yarn → HBase
升级的通用思想是:备份老集群的元数据目录,用HDP版本的进程,使用新备份出来的元数据目录启动。如果遇到任何错误,可以迅速回滚(使用Apache版本的进程,使用老的元数据目录重启)。
备份元数据的好处是,新HDP进程启动过程中发生任何问题,不会污染老的元数据。
每个组件在升级过程中,都有一些特殊的难点,分别阐述:
1)停止Apache的zk & 安装HDP的zk(data_dir不同):

2)Copy zk data到HDP data_dir覆盖&同步配置文件:
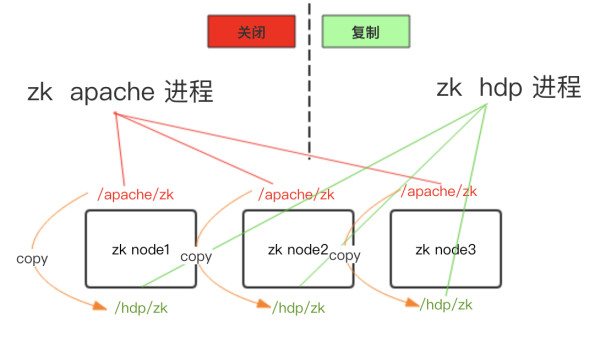
3)启动HDP zk&下线Apache zk:
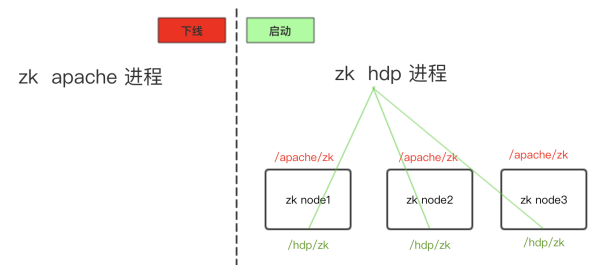
4)验证:如此,Zookeeper就升级完成了,同理可快速回滚。
HDFS的三台管理节点操作系统是ubuntu,不能直接升级,这里预备了用于替换的centos机器,在安装HDP HDFS时,需要先切换hostname+IP到新centos系统的机器进行安装。
1)记录HDFS老状态,3台master节点为ubuntu系统:

2)停止Apache HDFS & 备份元数据。
3)准备centos新机器&切换hostname+IP:
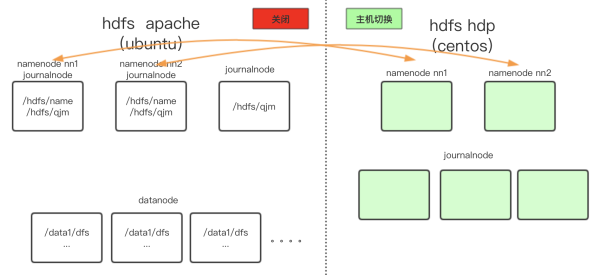
4)新centos机器上安装HDP HDFS&同步配置文件:

5)拷贝Apache HDFS NameNode & JournalNode的元数据到HDP HDFS目录并覆盖:

6)同步配置并启动HDP JournalNode & NameNode:

7)安装DataNode &启动:

8)启动DataNode数据汇报完成,完成升级:
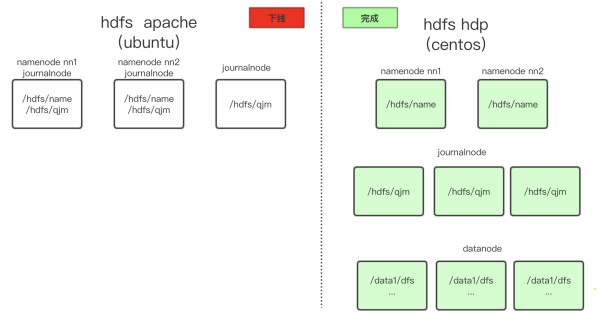
9)验证:HDFS数据上传下载测试&数据完整行校验。
1)停止Apache Yarn &安装HDP Yarn:
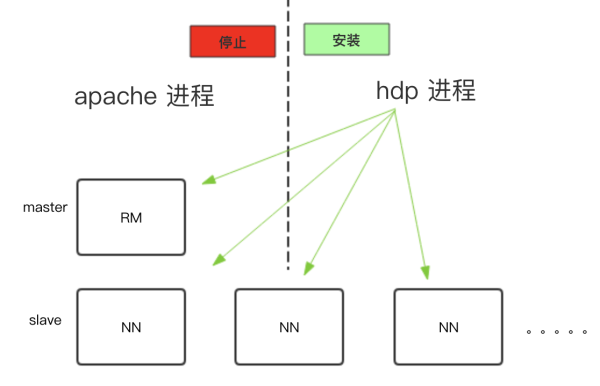
2)同步配置&启动HDP Yarn &下线Apache Yarn:
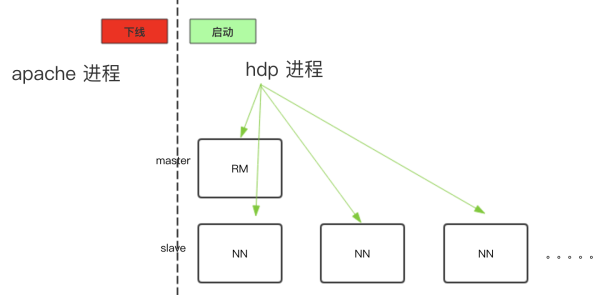
3)Enalbe Yarn HA:
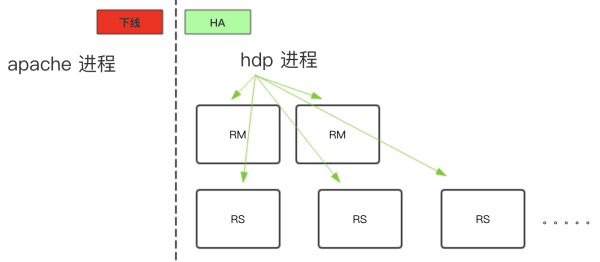
4)验证:进行简单MR / Hive / tez / Spark测试。
5)问题:怎么去兼容new / old client?
A:在升级Yarn的过程中,发现old client提交job时找不到org.Apache.Hadoop.mapreduce.v2.app.M RAppMaster,经过分析与以下两个参数有关:
mapreduce.framework.name
在HDP中是支持多版本mapreduce的,所以开启了这个参数用于存放多版本任务所需lib。而old client没开启这个参数导致问题,所以在server的关闭该参数。
yarn.application.classpath
该classpath在new / old classpath中不一致,(如old client由于历史原因指定了$YARN_ HOME,但是在HDP中是没有$YARN_HOME的)所以考虑怎么能在启动Yarn启动container时找到$YARN_HOME呢?
在yarn-env中export $YARN_HOME;
并将该变量$YARN_HOME指向container内部yarn.nodemanager.admin-env;
将old client的lib软链接(或者copy)到new nodemanager节点相应$YARN_HOME下。
1)停止Apache HBase &安装HDP HBase:
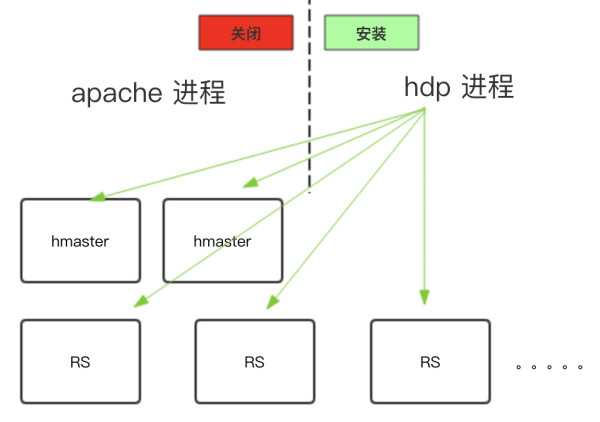
2)同步配置启动HDP HBase &下线Apache HBase:
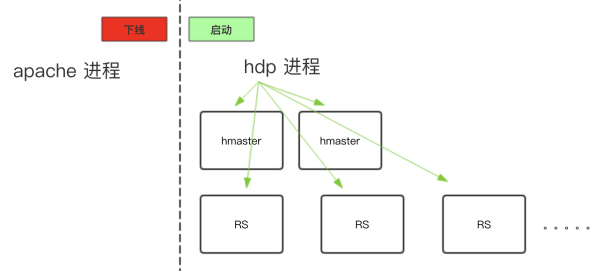
3)验证:进行get / put测试基本测试。
4)问题:怎样能既快速又最小影响地停止HBase呢?直接stopregionserver会产生大量的WALlog,升级启动时恢复数据容易出错,且耗时较长,grancfulstop最后region相互迁移不仅耗时长,最后也需要大量的WALlog恢复。
A:停机时,保证不产生额外的WAL,且保证速度。
disable table来停止继续写入数据,等升级完成后enble table恢复写入。由于disable_all执行效率低,建议采取了多进程的方式并行disable table;
flush table刷写memstore,减少WALlog恢复。
三、收获经验
本次Hadoop升级,涉及到shutdown整个集群。意味着全公司的所有大数据pipelien都会经历一次停止/启动。要规划好全公司所有大数据工程师的一致行动,是很有挑战的一件事情。有一些经验总结:
提前与各使用方沟通运维窗口期,找到各业务线能达成一致的业务低峰期作为运维窗口期,把对业务的影响降到最低。我们在沟通过程中,就发生了首次协商的时间,因为部分团队没发达成一致,最后在第二次充分沟通后才找到合适的运维窗口期,使全公司数据团队达成一致;
建一个“专项作战群”,不定期同步项目进度,让所有参与方感受到项目的热度;
协调各Hadoop组件管理员,在升级前后,参与server端的确认和恢复工作;
协调各业务方接口人,在升级前后,参与应用/服务的确认和恢复工作,保障业务快速恢复。
梳理整个上线运维窗口期所有操作的checklist,团队实施人员按照分工操作配合;
一定要明确分工。有人负责主流程操作,有人在“专项作战群”对接业务方接口人;
checklist一定要多人相互review,在事前确保万无一失,避免当场遇到问题手忙脚乱。
本次Hadoop升级,预支了6个小时的停服窗口期。但运维中的每一项工作,仍然要不断地压缩操作时长。
1)能前置的工作尽量前置:
新机器准备,新机器操作系统统一;
ambari-server安装& ams安装;
ambari集群配置文件准备。
这里着重说下Ambari集群的配置脚本化。在改为Ambari集群后,首先要把所有slave节点加入Ambari托管,再梳理老集群所有组件的所有配置,然后apply到Ambari集群上。
而在Ambari添加节点&更改每一个组件的配置,如果通过webUI逐项更改,都耗时太长。经过调研,我们将以上所有工作自动化:
使用API安装组件,提升效率;
使用configs.py设置配置参数,节约手动配置时间,例如在ambari-server节点上:
2)充分压缩单项操作的操作时长:
操作自动化。
此次升级工作中,我们采用的是Ansible自动化工具来批量执行大量操作,包括停止集群脚本、etc_hosts 配置脚本、bashrc 配置脚本、agent 刷配置脚本、测试脚本。根据需要,预先编写好playbook并在ansible-AWX中配置妥当,就可以在升级过程中一键执行。不仅省去了手工执行的时间消耗,并行执行也大大提高操作效率,压缩操作时长。
下面是playbook样例:
ambari_install/
├── group_vars
├── inventory
│ ├── ambari_agent
│ ├── ambari_bashrc
│ ├── ambari_hosts
│ ├── ambari_ln
│ └── ambari_slave
├── README.md
├── roles
│ ├── ambari_agent
│ │ └── tasks
│ │ └── main.yml
│ ├── ambari_bashrc
│ │ ├── files
│ │ │ └── bashrc_default
│ │ └── tasks
│ │ └── main.yml
│ ├── ambari_hosts
│ │ ├── files
│ │ │ ├── hosts_default
│ │ │ └── hosts_old
│ │ └── tasks
│ │ └── main.yml
│ └── ambari_ln
│ └── tasks
│ └── main.yml
└── roles.yml
配置到ansible-AWX的project/inventory/templates
这样就可以一键运行了。
3)尽可能并行化某些操作步骤:
不同的人负责执行不同的脚本。
从运维窗口期的前1个月开始,每周进行全流程演练;
每次演练,不定时地强制要求回滚;
最后一次,在公司的全局测试环境,做最后一次“演练”。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721