
一、背景
随着饿了么在大数据应用的不断深入,需要解决任务数量增长快、任务多样化、任务关系复杂、任务执行效率低及任务失败不可控等问题。
目前现状:
每天完成大数据任务计算54000+;
节点集群85台。
二、开源解决方案
1、Ooize
Ooize是基于工作流调度引擎,是雅虎的开源项目,属于Java Web应用程序。由Oozie client和Oozie Server两个组件构成。

Oozie Server运行于Java Servlet容器(Tomcat)中的Web程序。工作流必须是一个有向无环图,实际上Oozie就相当于Hadoop的一个客户端,当用户需要执行多个关联的MR任务时,只需要将MR执行顺序写入workflow.xml,然后使用Oozie提交本次任务,Oozie会托管此任务流。
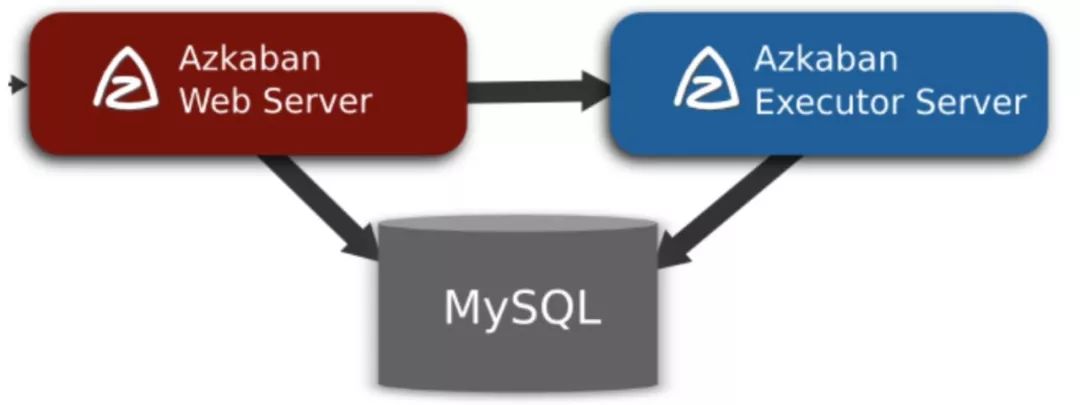
2、AzKaban
AzKaban是一套简单的任务调度服务,是Linkedin的开源项目,开发语言为Java,包括Web Server、DBServer、ExecutorServer,用于在一个工作流内以一个特定的顺序运行一组工作和流程,定义了一种KV文件格式来建立任务之间的依赖关系,并提供一个易于使用的Web用户界面维护和跟踪你的工作流:
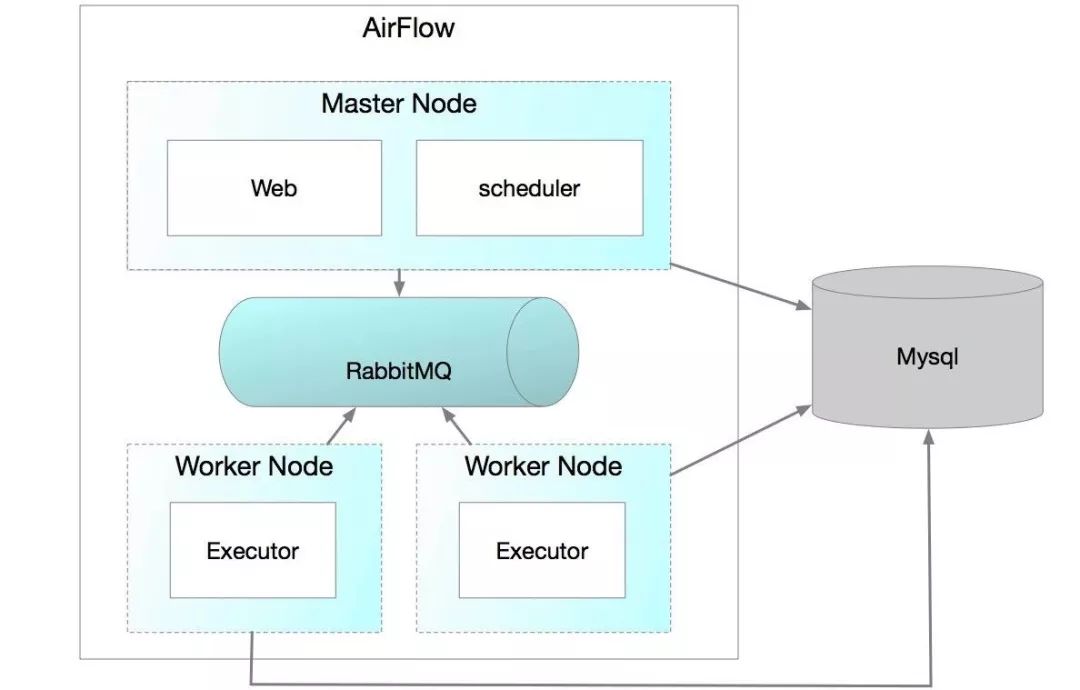
3、AirFlow
AirFlow是一个编排、调度和监控workflow的平台,由Airbnb开源,现在在Apache Software Foundation 孵化。AirFlow将workflow编排为tasks组成的DAGs,调度器在一组workers上按照指定的依赖关系执行tasks。同时,AirFlow提供了丰富的命令行工具和简单易用的用户界面以便用户查看和操作,并且AirFlow提供了监控和报警系统。
三、饿了么调度系统特性
任务创建简单,执行频率支持cron表达式;
任务拆分为多种任务类型,支持19种任务类型(计算、推送、抽取、检测);
任务依赖配置简单,支持不同周期匹配,提供推荐依赖,DAG VIEW功能;
调度与执行支持HA,平滑发布,宕机恢复,负载均衡,监控告警,故障排查,快速扩容,资源隔离。
支持任务类型:
计算:Hive、Spark、PySpark、MR、Kylin;
推送:MySQL推送、HBase推送、Redis推送、Cassandra推送、HiveToX推送、MySQL多推;
抽取:数据抽取;
检测:Dal-slave检测、数据质量检测、Edsink检测、抽取数据检测、数据有效期、导入导出校验;
其他:邮件定时任务。
四、饿了么调度系统整体架构
饿了么调度系统整体架构包括5个部分——Web服务、调度执行、基础服务、底层服务,公共设施:
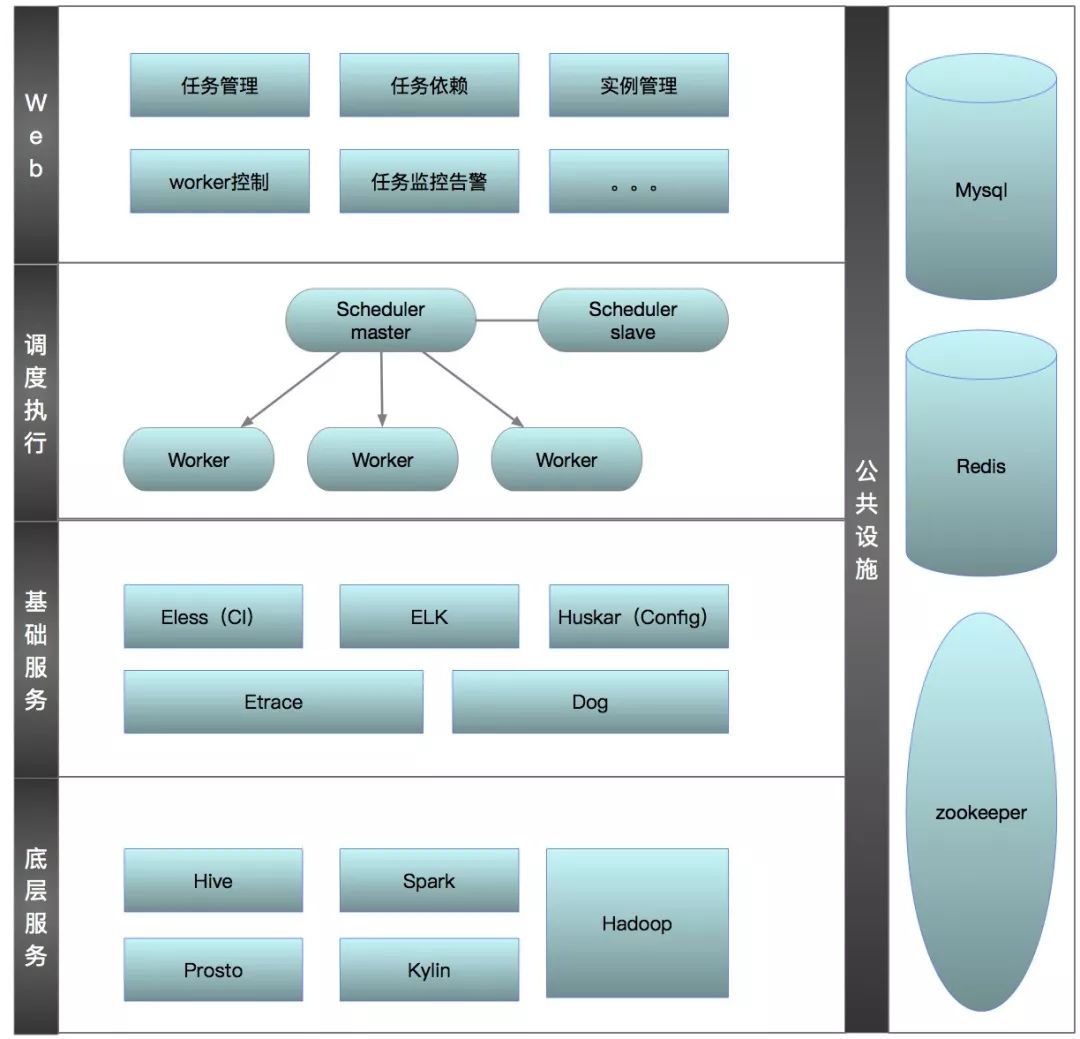
Web服务主要提供任务创建、实例管理、任务依赖管理、worker控制、任务监控告警等;
调度执行主要由主备Scheduler和多个worker节点组成,负责任务的调度与执行;
基础服务提供了Eless自助发布,ELK故障排查,Huskar配置中心,Etrace埋点监控,DOG告警等功能;
底层服务提供Hive、Spark、Presto、Kylin、Hadoop支持;
公共设施包括MySQL、Redis、Zookeeper。
任务运行过程
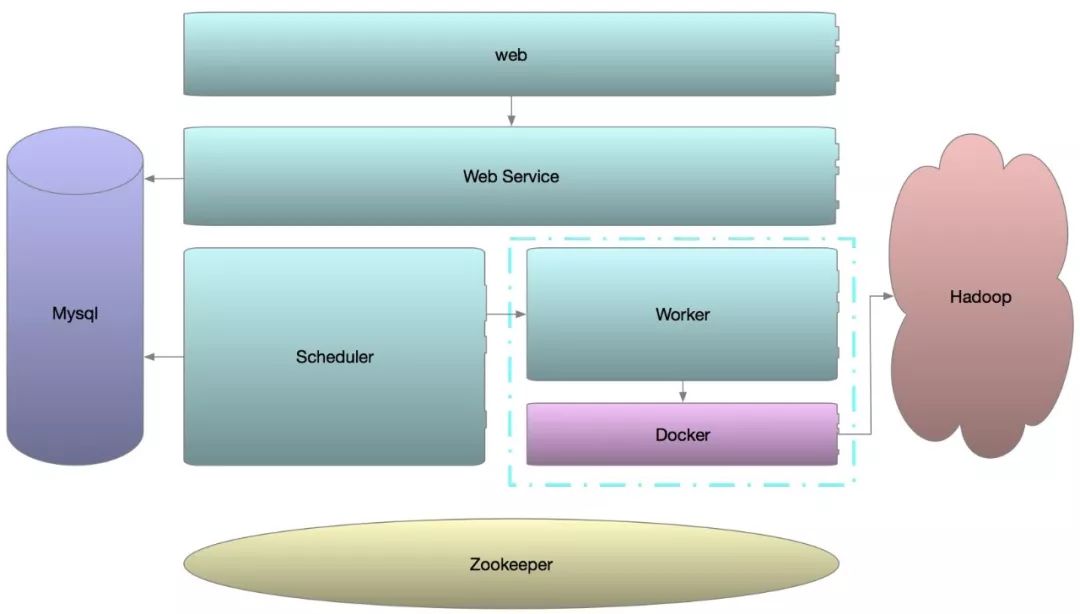
WebService提供的Api创建任务和依赖关系,将任务信息存入MySQL;
Scheduler定时生成第二天所有任务实例,并定时轮询检查并改变任务状态为ready(是否到了执行时间,是否依赖已完成);
Worker 启动时注册信息至Zookeeper,并定时上报机器状态给Scheduler;
Scheduler的ZkWorkerManager监听Zookeeper,获取Worker的注册信息;
获取ready的任务,TaskPacketFactory将任务构造成TaskPacket,使用对应的SubmitPolicy投递任务给Worker;
Worker通过Thrift接收任务,将任务解析成InterpreterContext,交给对应的Interpreter执行,最终由Dorker运行任务;
Docker执行情况返回给Worker,Worker回调给Scheduler将状态写入MySQL。
五、饿了么调度系统功能
1、任务依赖
任务依赖通过两种方式配置,推荐依赖和手动依赖:
推荐依赖是通过任务执行完将表和列的信息存入MySQL,由饿了么血缘系统根据表的关联进行推荐;
手动依赖则是人为通过界面设置表的依赖关系。依赖关系支持不同周期的任务依赖,偏移量支持表达式【,】【~】。
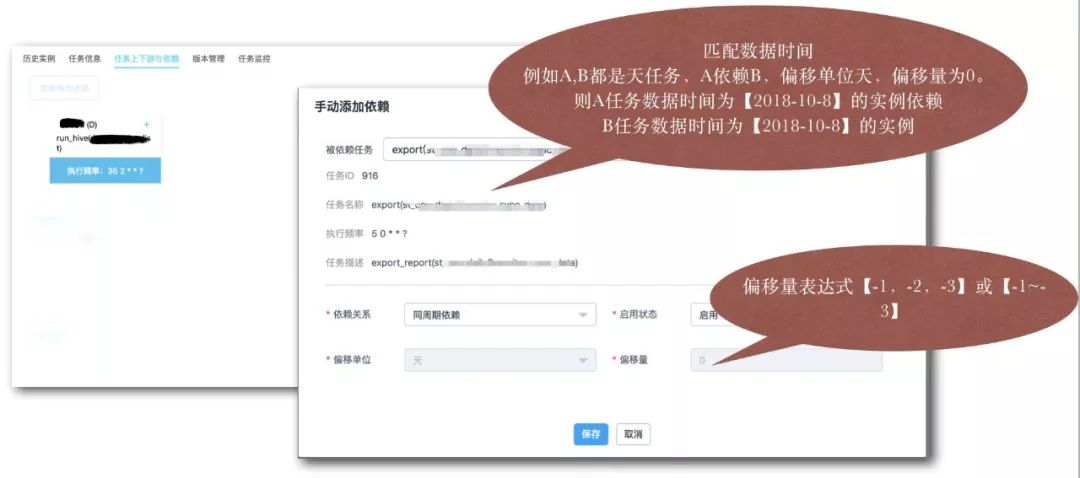
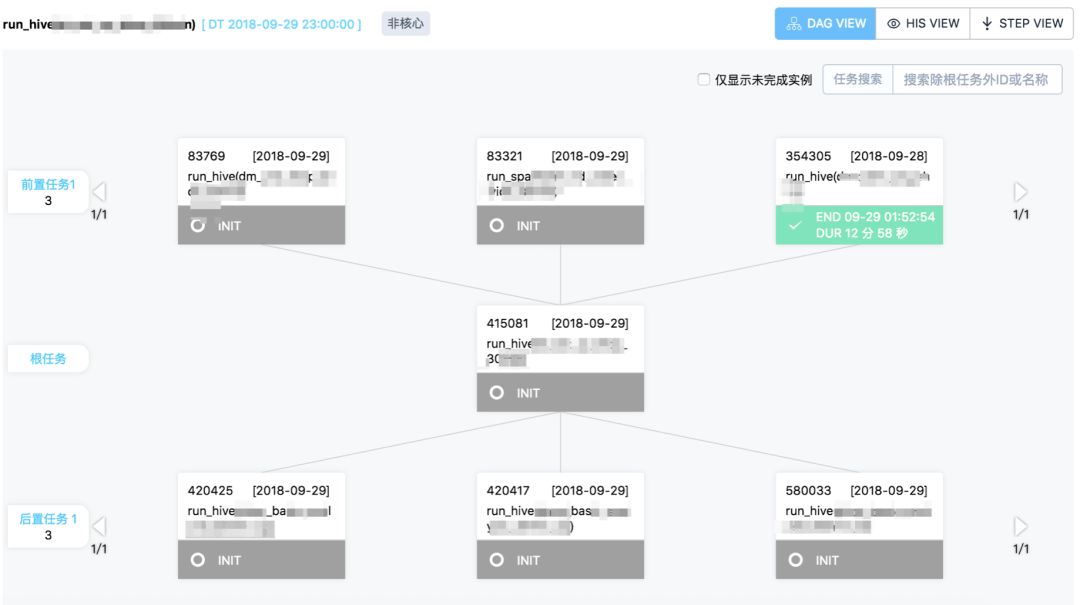
2、失败快速自动重试
当任务执行失败时,系统自动重新调起,默认重试3次;
当任务投递过程中,节点因资源紧张拒绝投递,调度会根据负载均衡策略尝试投递另一台机器。
3、自助故障排查
任务执行错误故障排查:节点提供Http服务,将任务执行的日志通过http返回给WebService并展示到界面上,提供用户自助排查。或者通过页面上的连接访问饿了么错误分析平台(Grace)自动分析;
任务非执行错误排查:任务调度和执行通过Flume将任务日志进行收集,通过在Elk上搜索全局ID即可查看调度和执行情况。
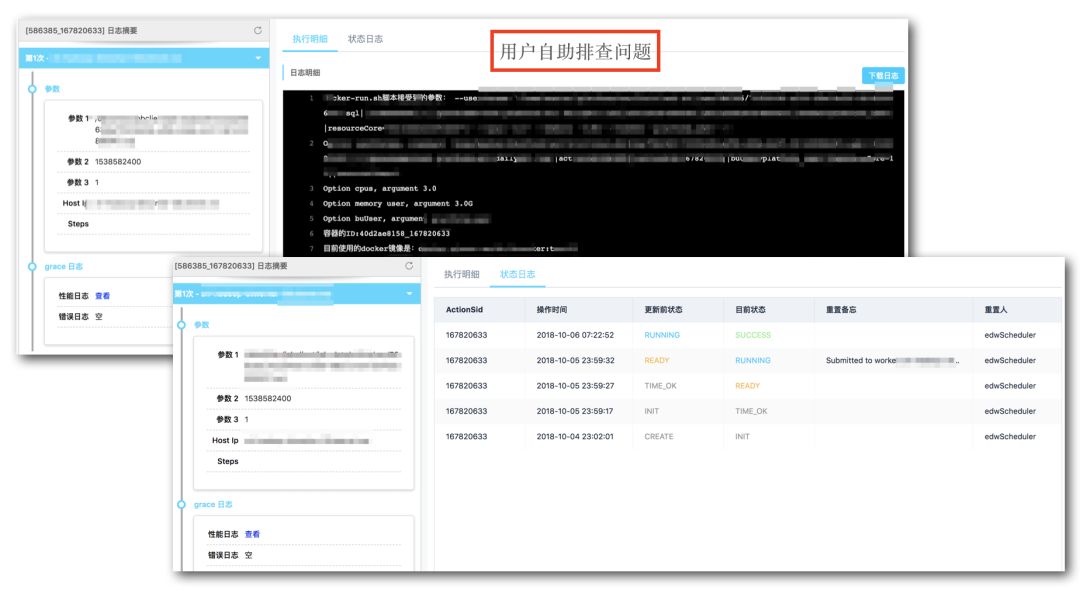
4、监控告警
任务监控告警:根据用户设置的告警规则和告警频率,对任务执行超过完成时间和失败的进行手机、邮件、钉钉告警;
故障监控和告警:调度和执行节点进行etrace埋点,通过对接收、执行、回调等关键点的进行监测,当指标低于其他节点时间窗口平均值时,进行告警。
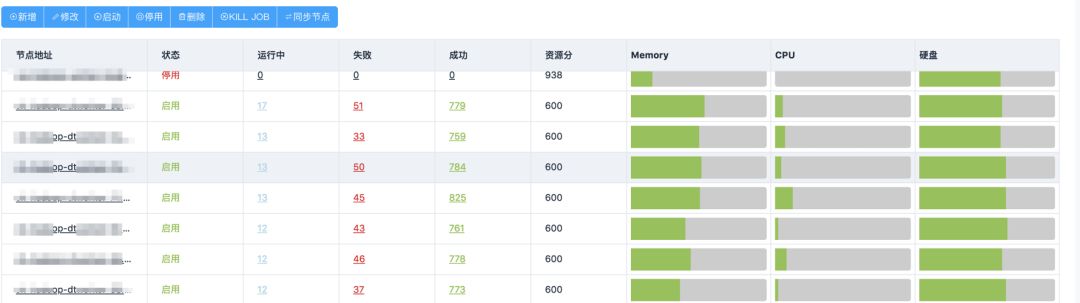
5、调度&执行
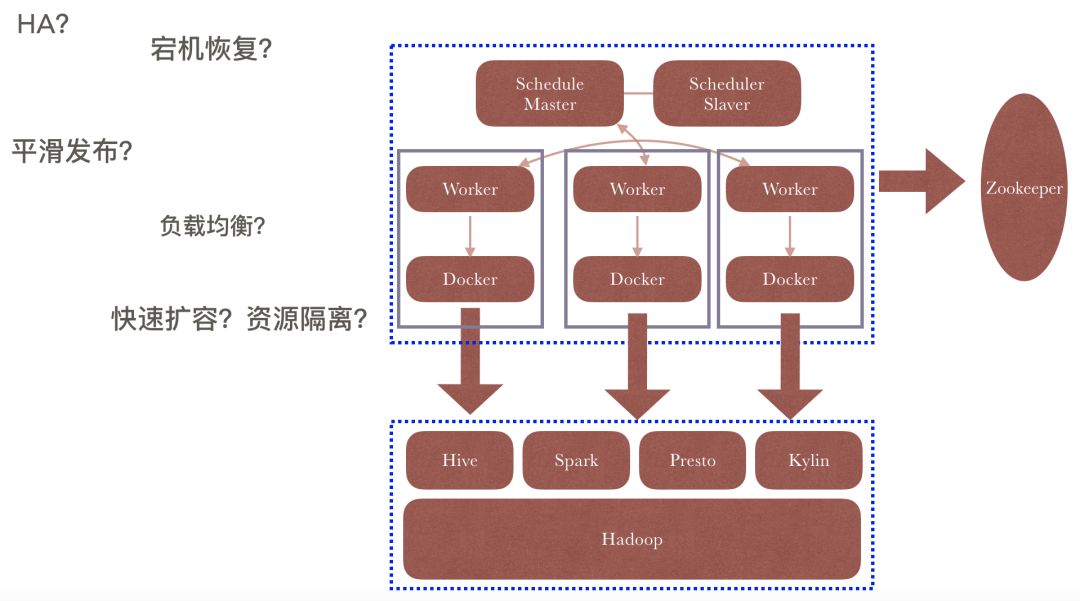
6、调度主备自动切换
调度器通过向Zookeeper注册,并随机选举出leader提供调度服务。非leader服务监听leader状态并wait,当leader出现故障,立即切换为leader角色提供服务。
7、宕机恢复、自我修复
当所有调度都宕机时,调度服务未恢复期间,Worker执行节点回调会出现异常。此时任务状态会存入本地文件数据库,并定时重试回调。当调度服务恢复时,任务状态恢复正常;
当Worker执行节点宕机时,节点上的任务会处于运行中。当节点重启时,Worker会自我修复运行中的任务,将节点上未调起的任务重新调起,已经运行中的任务通过读取Docker执行完写入本地的状态文件进行恢复。
8、平滑发布
当Worker节点进行版本升级时,运行中的任务进行自我修复,同上。
9、资源隔离和快速扩容
通过Docker限制每个任务的Memory和CPU资源使用;
将依赖的底层服务打包成镜像,扩容时便可以很方便的构建需要的环境。
10、节点故障维护
当节点发生故障或则需要维护时,Worker执行节点通过Web界面即可进行在线上下线服务,下线后认为不再接收任务,但不影响节点上运行中的任务运行。
Q1:Worker和Scheduler是通过ZK通讯的吗?
A1:是通过Thrift进行通讯的。
Q2:一般只是将具体的任务脚本部署到Docker上?Scheduler和Worker是怎么部署的?
A2:是的,Scheduler和Worker都是单独的机器分开部署的,Worker需要部署在宿主机上,Dorker运行在Worker机器上。
Q3:Scheduler如何选取住节点?
A3:Scheduler通过注册Zookeeper,随机选出一个节点做为leader,非leader节点做为从节点wait,直到leader释放锁,见curator实现。
Q4:请问是Docker任务是跑在Yarn上吗?
A4:Docker是在宿主机器上跑,主要是做了资源隔离和环境隔离。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721