
美图公司有美拍、美图秀秀、美颜相机等十几个app,每个app都会基于数据做个性化推荐、搜索、报表分析、反作弊、广告等,整体对数据的业务需求比较多、应用也比较广泛。
因此美图数据技术团队的业务背景主要体现在:业务线多以及应用比较广泛。这也是促使我们搭建数据平台的一个最主要的原因——由业务驱动。
一、美图的数据应用案例
举几个美图的数据应用案例:

图1
如图1所示,左起第一张是美图自研的数据可视化平台DataFace,支持业务方自由拖拽生成可视化报表,便于高效地做数据报表以及后续的分析;中间是美拍APP的首页“热门个性化推荐”:基于用户的行为数据,为用户推荐可能喜欢、感兴趣的视频列表;右起第一张是基于用户作弊的数据,根据一定的模型与策略进行反作弊,有效判断、过滤用户的作弊行为。除此之外,搜索、a/b实验、渠道跟踪、广告等方面都有广泛应用。
我们当前的数据量大致每月有5亿活跃用户,这些用户每天产生接近200亿条的行为数据,整体的量级相对来说比较大,集群机器达到千量级,还有PB级的历史总数据量。
我们的业务线也比较多,而且各业务线都比较广泛地运用了数据,加上整体的用户规模也比较大,以上因素促使我们必须构建对应的数据平台,来驱动这些业务增长,更高效地使用数据。
二、美图数据平台整体架构
如下图2所示是我们数据平台的整体架构:

图2
在数据收集这部分,我们构建了一套采集服务端日志系统Arachnia,支持各app集成的客户端SDK,负责收集app客户端数据;同时也基于DataX实现数据集成(导入、导出);Mor爬虫平台支持可配置的爬取公网数据的任务开发。
数据存储层主要是根据业务特点来选择不同的存储方案,目前主要有用到HDFS、MongoDB、Hbase、ES等。在数据计算部分,当前离线计算主要基于Hive&MR、实时流计算基于Storm、Flink以及一个自研的bitmap系统Naix。
数据开发这块我们构建了一套数据工坊、数据总线分发、任务调度等平台。
数据可视化与应用部分主要是基于用户需求构建一系列数据应用平台,包括:A/B实验平台、渠道推广跟踪平台、数据可视化平台、用户画像等等。
图2右侧是各组件都可能依赖的一些基础服务,包括地理位置、元数据管理、唯一设备标识等。
如图3所示是基本的数据架构流图,使用典型的lamda架构。从左端数据源收集开始,Arachnia、AppSDK分别将服务端、客户端数据上报到代理服务collector,通过解析数据协议,把数据写到Kafka;然后实时流经过一层数据分发,最终业务消费Kafka数据进行实时计算。
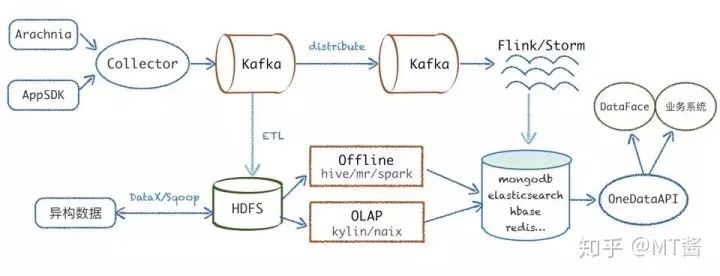
图3
离线会由ETL服务负责从Kafka dump数据到HDFS,然后异构数据源(比如MySQL、Hbase等)主要基于DataX以及Sqoop进行数据的导入导出,接着通过Hive、Kylin、Spark等计算把数据写入到各类的存储层,最后通过统一的对外API对接业务系统和我们自己的可视化平台等。
三、数据平台的阶段性发展
企业级数据平台建设主要分三个阶段:
第一阶段:
刚开始是基本使用免费的第三方平台,这个阶段的特点是能快速集成并看到app的一些统计指标,但是缺点也很明显,没有原始数据、除了第三方提供的基本指标之外,其他分析、推荐等都无法实现。所以有从0到1的过程,让我们自己有数据可以用。
第二阶段:
在有数据可用后,业务线、需求量爆发,就需要提高开发效率,让更多的人参与数据开发、使用到数据,不是仅局限于数据研发人员使用,所以下一步就是把数据、计算存储能力开放给各个业务线,而非握在自己手上。
第三阶段:
在数据开放了以后,业务方会关注数据任务能否跑得更快,能否秒出,能否更实时;另外一方面,为了满足业务需求,集群的规模越来越大,那么在满足业务的同时,也开始考虑如何实现资源更节省。
美图现在处于第二与第三阶段的过渡期,在不断完善数据开放的同时,也在逐步提升查询分析效率,并开始考虑如何优化成本。接下来我们重点介绍从0到1和数据开放这两个阶段我们平台的实践以及优化思路。
从0到1是要解决从数据采集到数据最终可以使用。
如图4所示是数据收集的演进过程,从刚开始使用类似umeng、flurry的免费第三方平台,到后面快速使用rsync同步日志到一台服务器上存储、计算,再到后面快速开发了一个简单的Python脚本支持业务服务器上报日志,最终我们开发了服务端日志采集系统Arachnia以及客户端AppSDK。
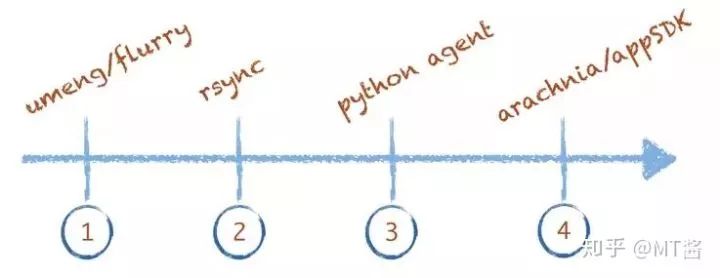
图4
数据采集是数据的源头,在整个数据链路中是相对重要的环节,需要更多关注:数据是否完整、数据是否支持实时上报、数据埋点是否规范准确、以及维护管理成本。因此我们的日志采集系统需要满足以下需求:
能集成管理维护,包括Agent能自动化部署安装升级卸载、配置热更、延迟方面的监控;
在可靠性方面至少需要保证at least once;
美图现在有多IDC的情况,需要能支持多个IDC数据采集汇总到数据中心;
在资源消耗方面尽量小,尽量做到不影响业务。
基于以上需求我们没有使用flume、scribe、fluentd,而是选择自己开发一套采集系统Arachnia。
如图5是Arachnia的简易架构图,它通过系统大脑进行集中式管理。puppet模块主要作为单个IDC内统一汇总Agent的metrics,中转转发的metrics或者配置热更命令。采集器Agent主要是运维平台负责安装、启动后从brain拉取到配置,并开始采集上报数据到collector。
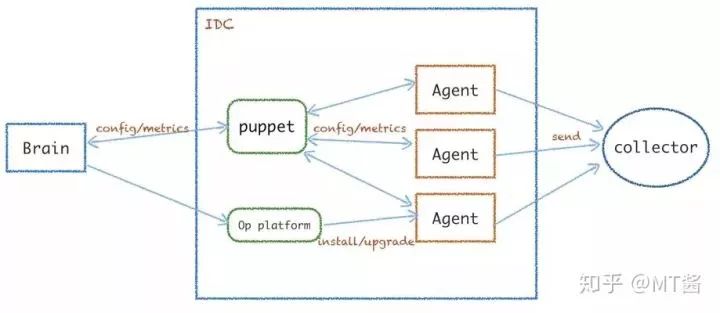
图5
接着看Arachnia的实践优化:首先是at least once的可靠性保证。不少的系统都是采用把上报失败的数据通过WAL的方式记录下来,重试再上报,以免上报失败丢失。我们的实践是去掉WAL,增加了coordinator来统一的分发管理tx状态,如图6:
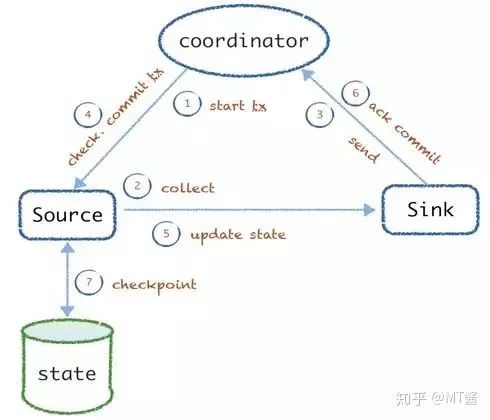
图6
开始采集前会从coordinator发出txid,source接收到信号后开始采集,并交由sink发送数据,发送后ack tx,告诉coordinator已经commit。coordinator会进行校验确认,然后再发送commit的信号给source、sink更新状态,最终tx完source会更新采集进度到持久层(默认是本地file)。
该方式如果在前面3步有问题,则数据没有发送成功,不会重复执行;如果后面4个步骤失败,则数据会重复,该tx会被重放。
基于上文的at least once可靠性保证,有些业务方是需要唯一性的,我们这边支持为每条日志生成唯一ID标识。另外一个数据采集系统的主要实践是:唯一定位一个文件以及给每条日志做唯一的MsgID,方便业务方可以基于MsgID在发生日志重复时能在后面做清洗。
我们一开始是使用filename,后面发现filename很多业务方都会变更,所以改为inode,但inode linux会回收重复利用,最后是以inode&文件头部内容做hash来作为fileID。而MsgID是通过agentID & fileID & offset来唯一确认。
数据上报之后由collector负责解析协议推送数据到Kafka,那么Kafka如何落地到HDFS呢? 首先看美图的诉求:
支持分布式处理;
涉及到较多业务线因此有多种数据格式,所以需要支持多种数据格式的序列化,包括json、avro、特殊分隔符等;
支持因为机器故障、服务问题等导致的数据落地失败重跑,而且需要有比较快速的重跑能力,因为一旦这块故障,会影响到后续各个业务线的数据使用;
支持可配置的HDFS分区策略,能支持各个业务线相对灵活的、不一样的分区配置;
支持一些特殊的业务逻辑处理,包括:数据校验、过期过滤、测试数据过滤、注入等;
基于上述诉求痛点,美图从Kafka落地到HDFS的数据服务实现方式如图7所示:
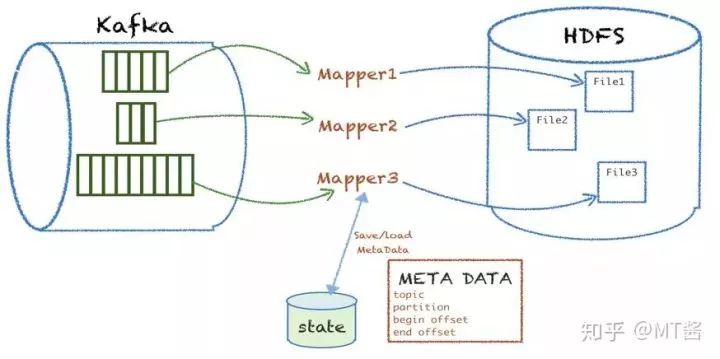
图7
基于Kafka和MR的特点,针对每个kafka topic的partition,组装mapper的inputsplit,然后起一个mapper进程处理消费这个批次的kafka数据,经过数据解析、业务逻辑处理、校验过滤、最终根据分区规则落地写到目标HDFS文件。落地成功后会把这次处理的meta信息(包括topic、partition、开始的offset、结束的offset)存储到MySQL。下次再处理的时候,会从上次处理的结束的offset开始读取消息,开始新一批的数据消费落地。
实现了基本功能后难免会遇到一些问题,比如不同的业务topic的数据量级是不一样的,这样会导致一次任务需要等待partition数据量最多以及处理时间最长的mapper结束,才能结束整个任务。
那我们怎么解决这个问题呢?系统设计中有个不成文原则是:分久必合、合久必分,针对数据倾斜的问题我们采用了类似的思路。
首先对数据量级较小partition合并到一个inputsplit,达到一个mapper可以处理多个业务的partition数据,最终落地写多份文件,如图8所示:
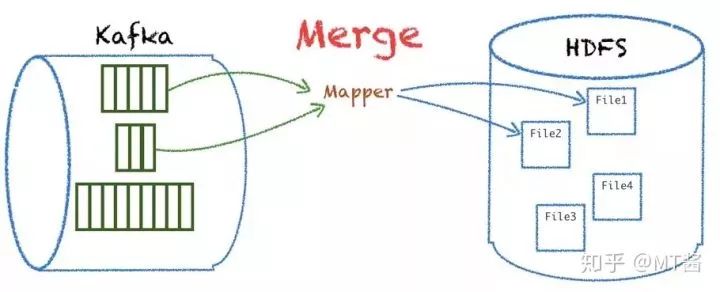
图8
另外对数据量级较大的partition支持分段拆分,平分到多个mapper处理同一个partition,这样就实现了更均衡的mapper处理,能更好地应对业务量级的突增,如图9所示:
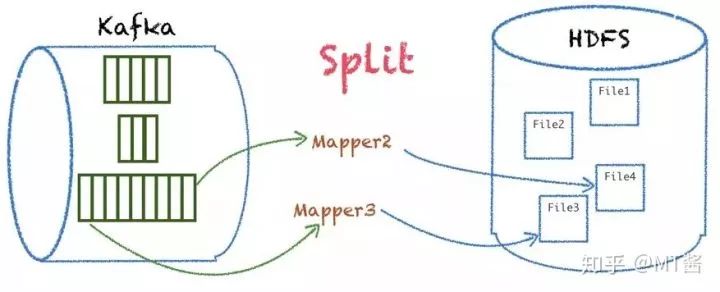
图9
除了数据倾斜的问题,还出现各种原因导致数据dump到HDFS失败的情况,比如因为Kafka磁盘问题、Hadoop集群节点宕机、网络故障、外部访问权限等导致该ETL程序出现异常,最终可能导致因为未close HDFS文件导致文件损坏等,需要重跑数据。那我们的数据时间分区基本都是以天为单位,用原来的方式可能会导致一个天粒度的文件损坏,解析无法读取。
我们采用了分两阶段处理的方式:mapper1先把数据写到一个临时目录,mapper2把HDFS的临时目录的数据append到目标文件。这样当mapper1失败的时候可以直接重跑这个批次,而不用重跑整天的数据;当mapper2失败的时候能直接从临时目录merge数据替换最终文件,减少了重新ETL天粒度的过程,如图10所示:
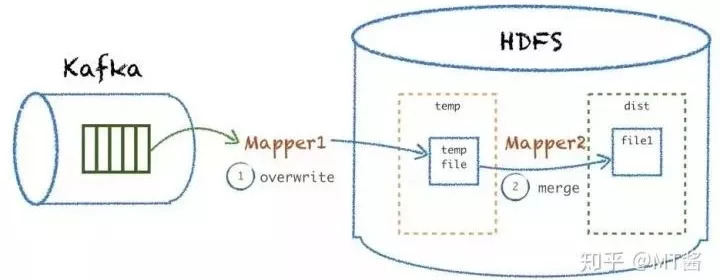
图10
经由数据的实时分发订阅写入到Kafka1的数据基本是每个业务的全量数据,但是针对需求方大部分业务都只关注某个事件、某小类别的数据,而不是任何业务都消费全量数据做处理,所以我们增加了一个实时分发Databus来解决这个问题,如图11所示:

图11
Databus支持业务方自定义分发rules往下游的Kafka集群写数据,方便业务方订阅处理自己想要的数据,并且支持更小粒度的数据重复利用。
图12可以看出Databus的实现方式,它的主体基于Storm实现了databus topology:

图12
Databus有两个spout,一个支持拉取全量以及新增的rules,然后更新到下游的分发bolt更新缓存规则,另外一个是从Kafka消费的spout。而distributionbolt主要是负责解析数据、规则match,以及把数据往下游的Kafka集群发送。
有了原始数据并且能做离线、实时的数据开发以后,随之而来的是数据开发需求的井喷,数据研发团队应接不暇。所以我们通过数据平台的方式开放数据计算、存储能力,赋予业务方数据开发的能力。
实现元数据管理、任务调度、数据集成、DAG任务编排、可视化等不一一赘述,接下来我们主要介绍数据开放后,美图对稳定性方面的实践心得。
数据开放和系统稳定性是相爱相杀的关系:一方面,开放了之后不再是由有数据基础的研发人员来做,经常会遇到提交非法、高资源消耗等问题的数据任务,给底层的计算、存储集群的稳定性造成了比较大的困扰;另外一方面,其实也是因为数据开放,才不断推进我们必须提高系统稳定性。
针对不少的高资源、非法的任务,我们首先考虑能否在HiveSQL层面做一些校验、限制。如图13所示是HiveSQL的整个解析编译为可执行的MR的过程:
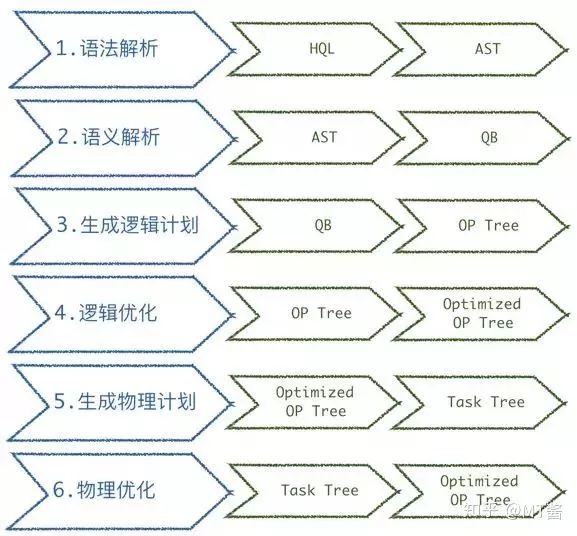
图13
首先基于Antlr做语法的解析,生成AST,接着做语义解析,基于AST会生成JAVA对象QueryBlock。基于QueryBlock生成逻辑计划后做逻辑优化,最后生成物理计划,进行物理优化后,最终转换为一个可执行的MR任务。
我们主要在语义解析阶段生成QueryBlock后,拿到它做了不少的语句校验,包括:非法操作、查询条件限制、高资源消耗校验判断等。
第二个在稳定性方面的实践,主要是对集群的优化,包括:
我们完整地对Hive、Hadoop集群做了一次升级。主要是因为之前在低版本有fix一些问题以及合并一些社区的patch,在后面新版本都有修复;另外一个原因是新版本的特性以及性能方面的优化。我们把Hive从0.13版本升级到2.1版本,Hadoop从2.4升级到2.7;
对Hive做了HA的部署优化。我们把HiveServer和MetaStoreServer拆分开来分别部署了多个节点,避免合并在一个服务部署运行相互影响;
之前执行引擎基本都是On MapReduce的,我们也在做Hive On Spark的迁移,逐步把线上任务从Hive On MR切换到Hive On Spark;
拉一个内部分支对平时遇到的一些问题做bugfix或合并社区patch的特性;
在平台稳定性方面的实践最后一部分是提高权限、安全性,防止对集群、数据的非法访问、攻击等,如图14所示:

图 14
提高权限主要分两块:API访问与集群。
API Server:正如上文提到的,我们有OneDataAPI,提供给各个业务系统访问数据的统一API。这方面主要是额外实现了一个统一认证CA服务,业务系统必须接入CA拿到token后来访问OneDataAPI,OneDataAPI在CA验证过后,合法的才允许真正访问数据,从而防止业务系统可以任意访问所有数据指标。
集群:目前主要是基于Apache Ranger来统一各类集群,包括Kafka、Hbase、Hadoop等做集群的授权管理和维护。
以上就是美图在搭建完数据平台并开放给各个业务线使用后,对平台稳定性做的一些实践和优化。
三、总结
接下来我们对数据平台建设过程做一个简单的总结:
首先在搭建数据平台之前,一定要先了解业务,看业务的整体体量是否较大、业务线是否较广、需求量是否多到严重影响我们的生产力。如果都是肯定答案,那可以考虑尽快搭建数据平台,以便更高效、快速提高数据的开发应用效率。如果本身的业务量级、需求不多,不一定非得套大数据或者搭建多么完善的数据平台,以快速满足支撑业务优先。
在平台建设过程中,需要重点关注数据质量、平台的稳定性,比如关注数据源采集的完整性、时效性、设备的唯一标识,多在平台的稳定性方面做优化和实践,为业务方提供一个稳定可靠的平台。
在提高分析决策效率以及规模逐渐扩大后需要对成本、资源做一些优化和思考。
作者:卢荣斌
来源:美图数据技术团队订阅号
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721