
作者介绍
汪涉洋,来自美国视频网站hulu的工程师,毕业于北京理工大学计算机专业,目前从事大数据基础架构方面的工作。
今天我们来聊聊 Hadoop 集群的CPU&内存管理,更多学习资料可点击文末“阅读原文”,进入笔者的个人专栏。
本文目录:
1、Yarn 的历史和由来
2、Yarn 相同的领域,还有哪些产品
3、设计、多租户APP& 队列/标签
4、Real World 中 Yarn 的问题
5、数据驱动的 Yarn 管理,资源治理
6、分析规律,反哺线上
当下Hadoop稳定在了2.x.x版本,3.x版本也基本production stable了,虽然敢用的公司很少。在Hadoop 2.x后,都是用 Yarn (Apache Hadoop Yarn )来管理集群的计算资源。
随着互联网的发展,互联网公司的业务越来越复杂。早在10年前,一个普通的小网站有个50台机器,能有20个Web服务器20个数据库,公司内有10来个应用系统,也就差不多了。但像Google、BAT这种巨无霸,很早就面临了大规模集群的管理问题,且问题越来越大。随着网络的爆炸发展,网络巨头公司的业务线越来越多,越来越复杂。看看现在的BAT,有多少业务线,内部有多少IT系统在不停歇的运转。倘若应用的维护者,都自己维护自己的物理机,那这些机器出问题后,维护成本简直无法估量。
于是,分布式操作系统就产生了。因此,现在单台操作系统管理本机的CPU、内存,分布式操作系统就管理整个集群成千上外台机器的CPU、内存、甚至网络。
资源管理领域:
Google先有了Borg,后又开源了 Kubernetes
Hadoop系有了Yarn
Twitter开源了Mesos
因为Hadoop的特点和历史原因,Hadoop集群的资源管控发展到了Yarn这套系统后,基本就是由Yarn来专门跑Hadoop应用,即 Mapreduce/Spark等等计算作业。
那么Yarn上面能否跑一些别的项目呢? 当然可以,需要自己编写一个on Yarn的程序,写自己的Application-Master (Hadoop: Writing Yarn Applications )和资源申请模块等。
on-Yarn 应用
笔者这里找了一些开源者尝试的on-Yarn应用:
Docker on YARN
https://conferences.oreilly.com/strata/strata-ca-2017/public/schedule/detail/55936
Presto YARN Integratio
https://prestodb.io/presto-yarn/
prestoDB/presto-yarn
https://github.com/prestodb/presto-yarn
Introducing Hoya - HBase on YARN - Hortonworks
https://hortonworks.com/blog/introducing-hoya-hbase-on-yarn/
但在实际的应用场景中,大多数规模以上公司光跑Mapreduce/Spark的Job,集群资源就都挤破头了,所以other on-Yarn Application,不在本文的讨论范畴内。本文将讨论竞争激烈且真正跑满了Hadoop Application 的 Yarn Cluster。
Yarn设计的最大初衷,是多租户,并行APP。
在早版本的 Jobtracker/Tasktracker时期,整个集群是first-in-first-out的调度策略。每个APP都在排队跑,一个APP占不满集群的资源,整个集群的计算资源就浪费了。
到了Yarn时期,可以允许多个APP同时跑,按自己的需求共享集群资源。

队列/标签
队列
在当下稳定的Hadoop版本里,资源的调度都是基于队列的。

队列——标签的映射关系
在一个公司里,不同的Team可以按需求把作业提交到不同的队列里。这就好比银行的门店,不同的窗口(Queue)可以办理不同的业务。
根据业务强度,银行会给不同的窗口分配不同的人(机器),有的窗口分配能力强的人(多CPU),甚至开多个窗口(子队列),有的子队列只服务“军人”/“老人” (Sub-queue)。有的窗口分配普通员工。
Yarn的主流调度器 Hadoop: Fair Scheduler & Hadoop: Capacity Scheduler 都是基于队列设计的。对这一块还不了解的朋友,可以点击下方Scheduler链接,读读官网的原版wiki:
http://hadoop.apache.org/docs/r2.7.1/hadoop-yarn/hadoop-yarn-site/CapacityScheduler.html
CapacityScheduler

FairScheduler

本文的第5部分,将会重点谈谈基于Queue History Data 的分析,笔者这里提供两篇关于调度器的文章:
1.Cloudera Community : Cloudera’s Fair Scheduler vs. Capacity Scheduler, which one is the best option to choose?
https://community.cloudera.com/t5/Hadoop-101-Training-Quickstart/Cloudera-s-Fair-Scheduler-vs-Capacity-Scheduler-which-one-is-the/m-p/37645#M2251
2.[StackOverflow]: What is the difference between the fair and capacity schedulers?
https://stackoverflow.com/questions/26546613/what-is-the-difference-between-the-fair-and-capacity-schedulers
标签
Node label (Yarn Node Labels )是一个为了给相同特点的集群机器分组的解决方案。直白地说就是异构机器分组。这一波机器A,用来跑 map-reduce;另一波机器B,用来跑spark;还有一部分机器C,用来跑AI/Machine-Learning Job。
为什么会产生这种需求呢?
因为Hadoop这个技术栈已经产生了很多年了。在公司集群中,有的机器是3年前、5年前买的,有的是近1年买的。那么随着时间的推移,集群中的机器配置必然会是异构性。
一般来讲,都会用老的机器跑一些“实时性不是很重要”的Batch Job,而让一些新一些的机器,跑一些需要快速处理的"Spark/Streaming" 甚至OLAP的计算任务。
这里有几篇讲NodeLabel的很好的文章,大家也可以参考看看:
slideshare.net/Hadoop_Summit/node-labels-in-yarn-49792443
http://link.zhihu.com/?target=https%3A//www.slideshare.net/Hadoop_Summit/node-labels-in-yarn-49792443
YARN Node Labels: Label-based scheduling and resource isolation - Hadoop Dev
https://developer.ibm.com/hadoop/2017/03/10/yarn-node-labels/
Node labels configuration on Yarn
https://community.hortonworks.com/articles/72450/node-labels-configuration-on-yarn.html
总之,Hadoop的Admin可以把一个或多个Label关联到Queue上,一个Hadoop Application只能使用一个Queue下面的一种Label。例子:
提交MR作业到Label X:
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 3g --executor-memory 2g --conf spark.yarn.am.nodeLabelExpression=Y --conf spark.yarn.executor.nodeLabelExpression=Y jars/spark-examples.jar 10
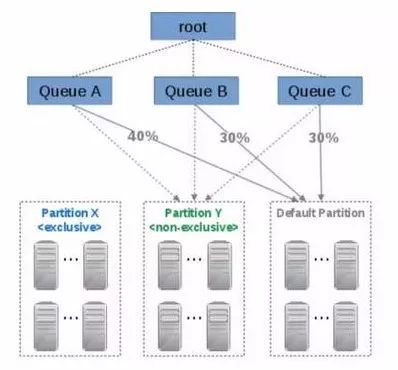
Yarn Queue Label
Tip: YARN Node-labels 功能在Apache Hadoop 2.6被开发出来,但并没有被merge到官方版本中,只能通过打Patch的方式使用,因此是有很多Bug的。官方推荐 Hadoop 2.8.x 之后再使用,Fix了很多Bug,而事实上在Apache Hadoop 2.7.3 版本的官方主业里,NnodeLabel功能被正式介绍出来。
Cloudera 把Node-label的Feature打入了,但很多Bug并没有Fix。笔者会在下一小节着重讲这部分内容。
目前,Yarn已经到了一个相对完备的功能阶段,发展到了多Queue 多租户以及成熟的Label管理。下面来讲讲我个人在运维Yarn的工作时碰到的各种问题。
用户问题
YARN resources are always complained insufficiently by big-data users.
big data infrastructure team里有一个内网的聊天Channel。我总是能听到一些Hadoop User抱怨,说他们的job今天跑慢了,Pending太久了,为什么还拿不到资源等。
如果仔细分析产生问题的原因,总结下来大致有以下2种:
资源分配问题
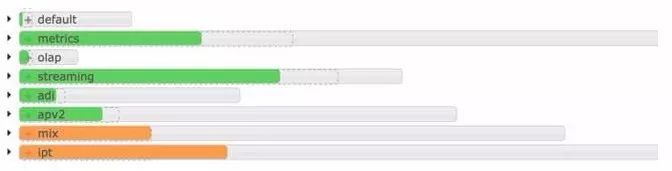
资源分配不均就可能会导致上述问题的产生。如果给某些队列划分了过多的资源,就会导致某些队列的Job卡住很久。当队列资源使用率达到100%时,另一个队列的资源使用还不到50%。 比如下图,Streaming队列明显快满了,而OLAP队列还使用了不到1/4。
应用程序滥用问题
先给大家show几个图。第一个图是一个APP,经过分析,它申请了32GB的内存,但统计后平均使用的内存是514MB 。 what?作为管理员,看到这种用户,是不是很生气呢…

第二个是APP申请的资源,这一个APP申请了740个CPU,3000GB的总内存,这类APP很多。这种APP我认为调优的空间都很大。一个Mapper/Reducer能优化30%的内存占用量,总体看就是一个很客观的数字。

Yarn的管理员问题
我们怎么才能知道队列的资源使用长期情况呢? 拿什么数据来作为调整Yarn队列Queue级别资源的依据呢?
每次新加入了一批机器后,我们当然要给机器打Label,Yarn的Shell Cmd中,打Label:
Yarnrmadmin—replaceLabelsOnNode“node1[:port]=label1node2=label2
如果一次加入100台机器,打Label去输入这么多命令,很容易出问题。怎么能又快速又安全地搞定这个工作呢?
用户在Channel不停地问Application的问题,有什么办法能减少Admin人工回复用户的工作,让用户自助解决问题?
Node-Label问题
Bug1
缺乏 Node-Label 资源显示如下图。
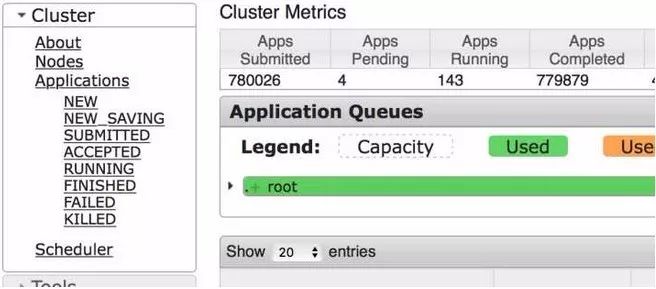
cdh-5.7.3-Hadoop-2.6.0的Yarn UI
在稳定版本中,是可以显示出哪种Label、有多少机器、有多少Memory和CPU资源的。
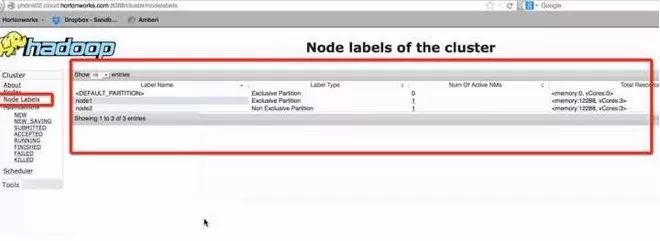 Node-Label稳定版本Hadoop2.8.x
Node-Label稳定版本Hadoop2.8.x
Bug2
Yarn Shell 功能不全,甚至不能使用list all labels功能。

Bug3
Yarn UI没有分Label去显示Queue的资源使用率。
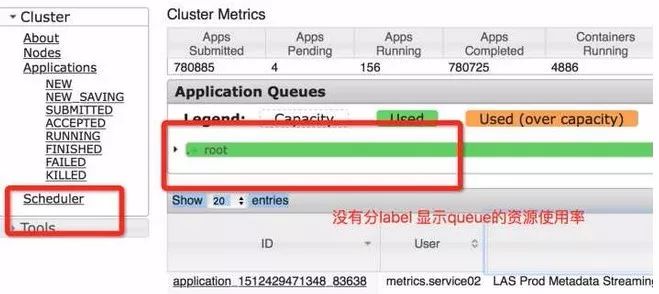
非稳定版
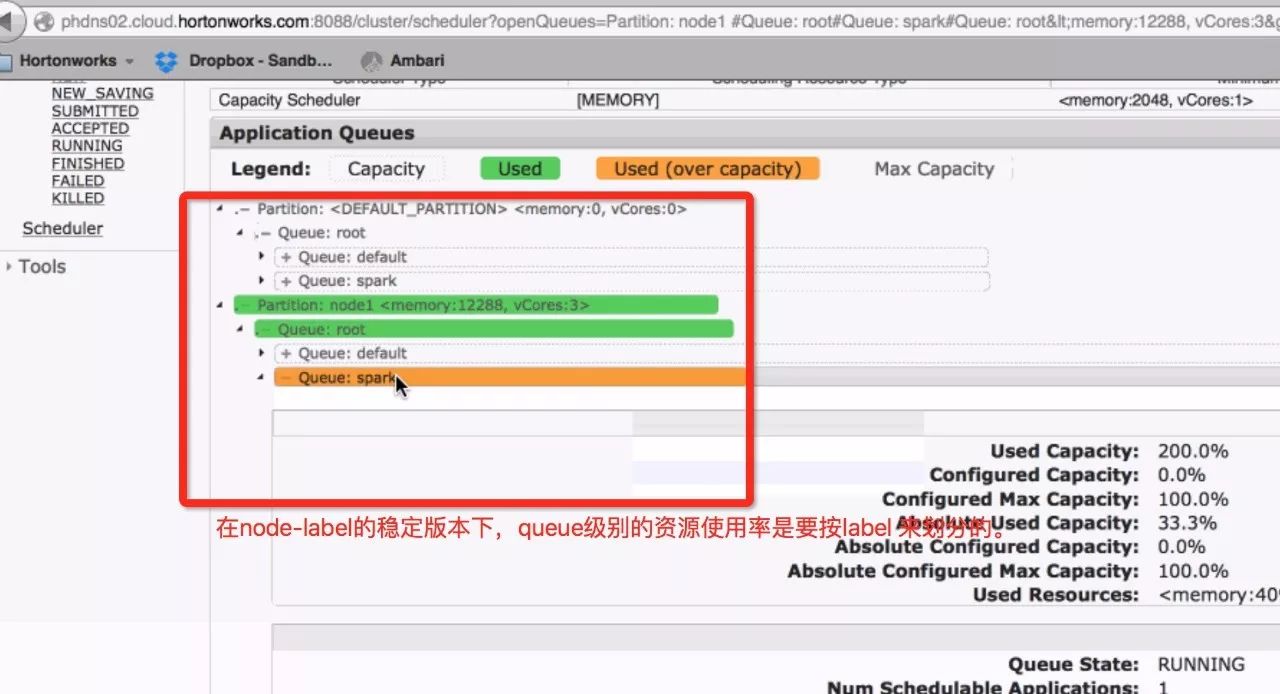
稳定版
为了解决上一节提出来的种种问题,我们做了很多自动化的工具。
我们用搜集“时间序列”的数据,来评估队列的使用情况
用UI Tool 来加快运维操作的批量性/安全性
用更简洁明了的图表,来给用户展示他能得到的资源等。
Yarn资源调配
趋势图
为了解决Yarn Queue资源调配的公平,我们制作了Yarn Qqueue Level 的 Capacity 占比History 趋势图。
总揽图:所有子队列的历史资源使用都在这里:大家可以看出哪个队列长期超负荷运转,哪些Queue长期用不满资源。
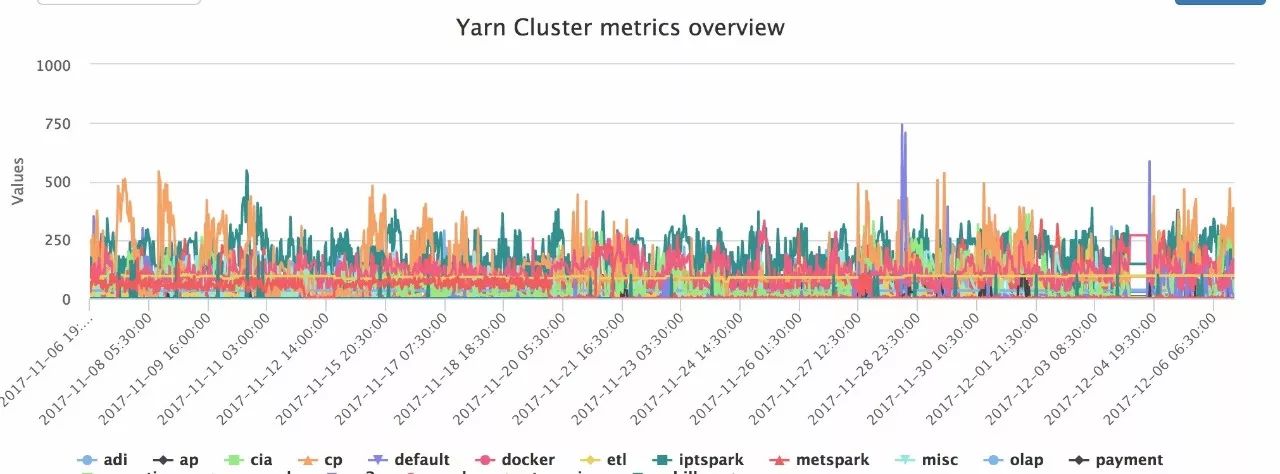
总揽图主要用来做对比,发现有问题的Queue。
队列图:队列图是针对一个Queue进行详细的分析用的:包括队列里使用哪种Label的机器,队列有多少资源,队列资源的历史使用占比、超负荷占比、Running/Pending APP历史,以及Reserve 的Container历史等。
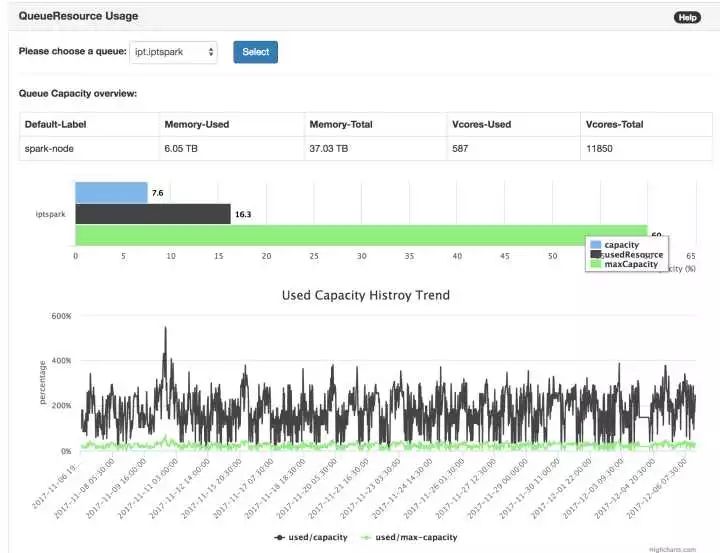
这样,在user提出质疑时,先让user自己来看是否队列的使用量已经满了、是否队列在Reserve Container,从而满足user的Job等。
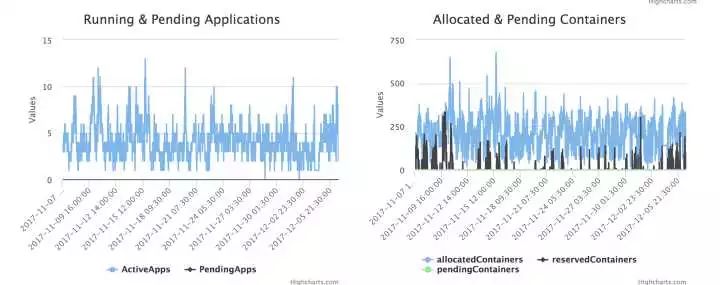
级别资源调配
那么,一次Yarn的Queue 级别资源调配应该是这样的:
从“总揽图”找到长期相对空闲的队列。
把相对“空闲”队列的资源,划归给“超负荷”的队列
等一段时间,再观察“总揽图”,是否“超负荷”队列的资源真的变好了。(不是重复1)
Yarn运维
在上一节,我们提到了给新加入集群的机器打Label是个漫长的过程。没关系,本着 “让一切人对机器的操作尽可能的自动化”的原则,我们设计给Node批量打Label的UI界面如下。
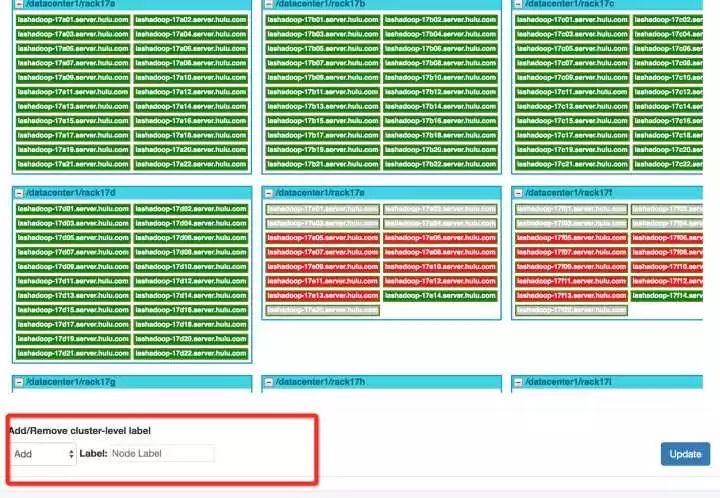
Yarn Queue 级别资源分配展示的不友好
开源版本的Yarn UI 样式其实很土,很多信息都展示得不够透彻,比如:
Yarn 的Queue资源分配到底占了资源的多少。
缺失不同Queue之间的资源对比
像这种文字类的UI,作为使用Hadoop的其它数据团队user,是不够直观的。
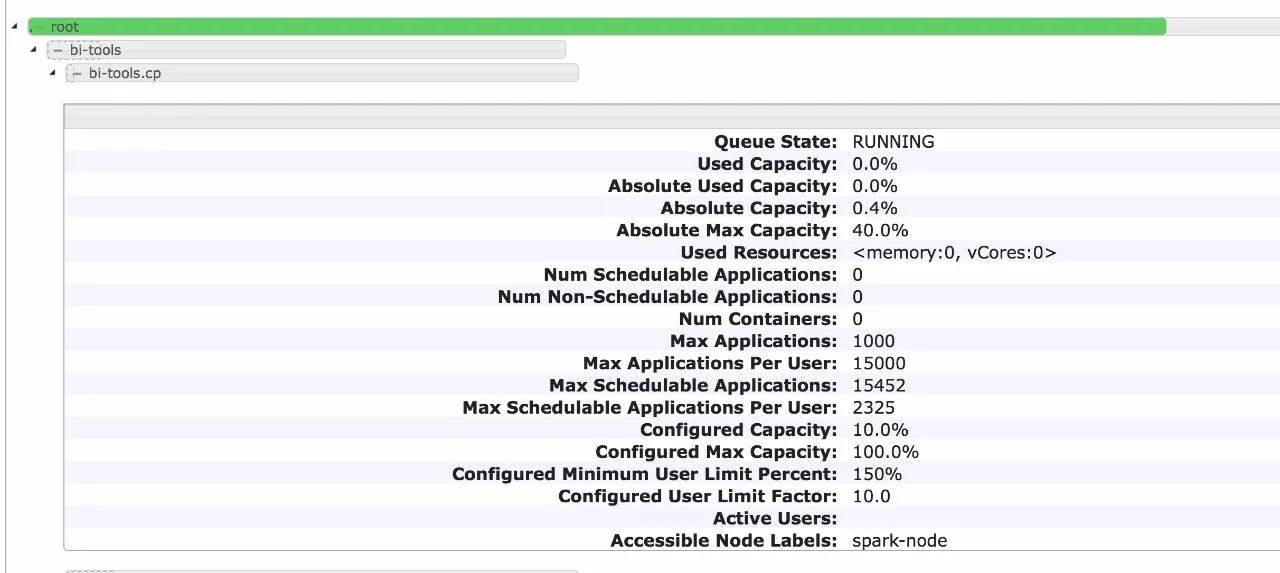
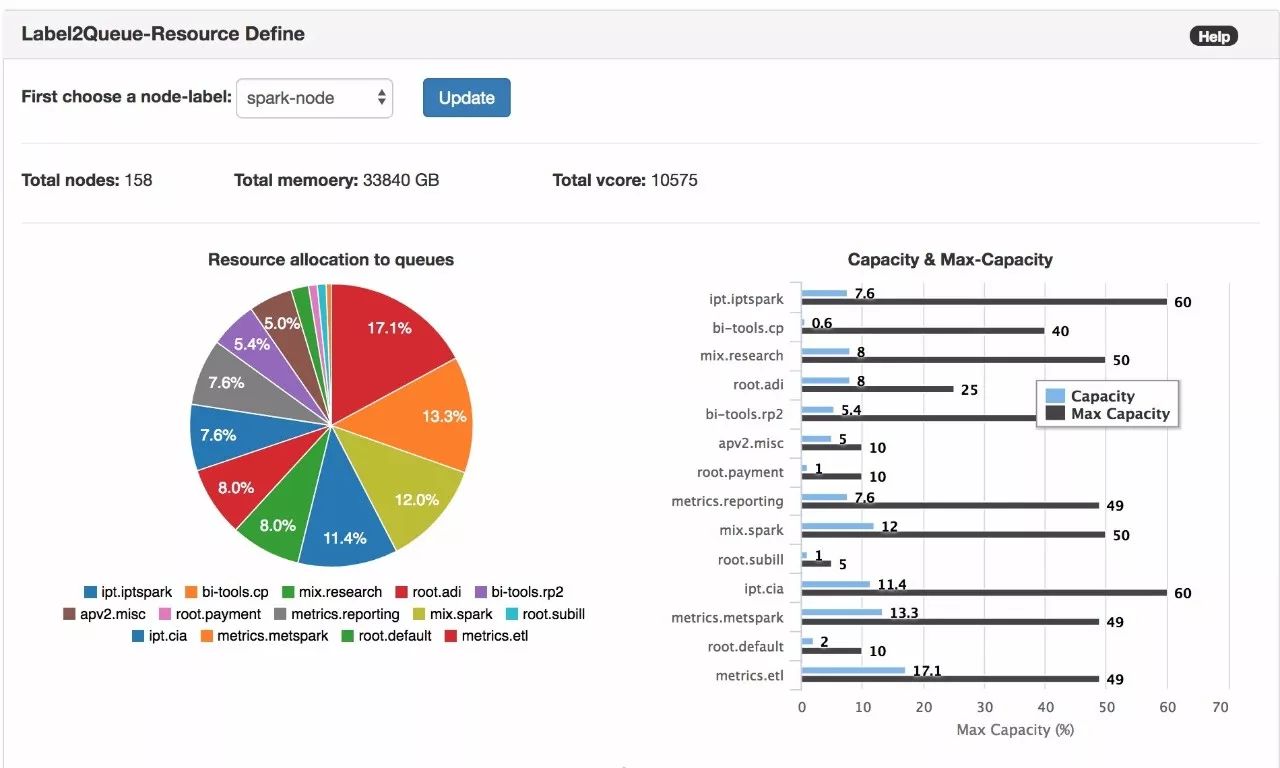
我们重绘了Yarn 的Queue Level 资源分配(哪个Queue分多少资源,一目了然),并着重强调了Node-label在划分资源里的重要性。
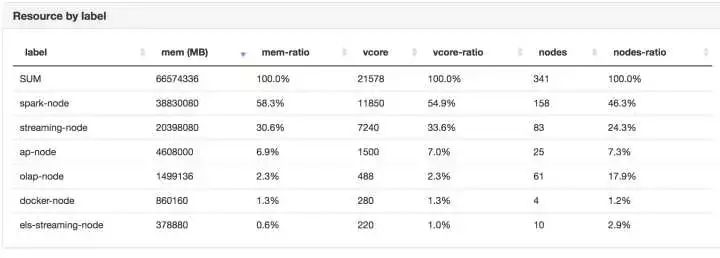
解决用户自助排查问题
这一块我们就使用了Linkedin开源的dr.elephant linkedin/dr-elephant.(https://github.com/linkedin/dr-elephant)。
这个工具提供了很多针对Hadoop Job的诊断/调休信息,可以帮助用户调优自己的Hadoop Job。我们也基于此做了很多二次开发,比如我们需要这样的功能:
在某个“Queue”下面,按“浪费”的内存数量倒排,分别罗列出所有浪费内存绝对数量/相对数量最多的 Application。
这个工具就好比很多公司的“客服系统”。当遇到简单的问题时,它先让用户自行解决包括查阅文档、语音机器人等;若是遇到用户很难解决的问题时,它会进行人工介入。毕竟公司内是很少Hadoop Admin 的,而每个人的时间资源更是宝贵,不能陷入“运维陷进”。
如何调整Yarn Queue级别的资源分配,上一章已做了简单的介绍。
至于实操,每个公司都不一样,但有一个通用的原则,即Hadoop 运维团队可以按月/季度,设定运维日。所有需要调整Yarn资源的需求,都发给管理员,待管理员在运维日统一调整。
另外一个比较有意思的地方是,Yarn 集群资源使用率往往是有高峰期和低谷期。
在高峰期时,可能会让集群的使用率持续打满。 而低谷期,使用率往往又可能下降到50%甚至更低。通过之前绘制的集群使用率“总揽图”,以及队列的“队列图”,大家可以分别观察集群总体的规律和每个队列的规律。
比如Yarn的总体使用量走势,如下图所示:
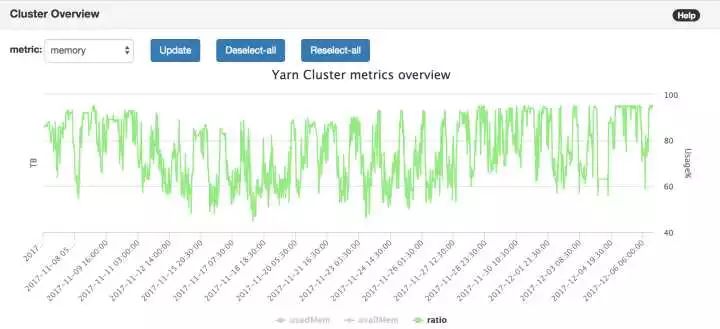
分析后得出,Yarn Job最大的来源是来自于作业的调度,即调度系统!
我们可以看到,每一天的凌晨零点左右,资源使用率都会爬上去直到100%,而每一天的早上6点到下午3点,集群资源使用率都会下降,甚至降到50%以下。
很多调度系统都是按天级别来调度作业的,允许用户配置类似Cron语法的Job。很多调度体系还提供简单的 Daily选项(Airflow Daily:
https://airflow.apache.org/scheduler.html#dag-runs),而这个选项就默认把作业的调度时间设置为了0点。这样在0点时,大规模的作业被同时调度出去,互相挤占资源,所以大家都跑得慢。
我们会建议数据团队们,更改不那么重要的Job的Daily运行的小时点,“错峰”运行。
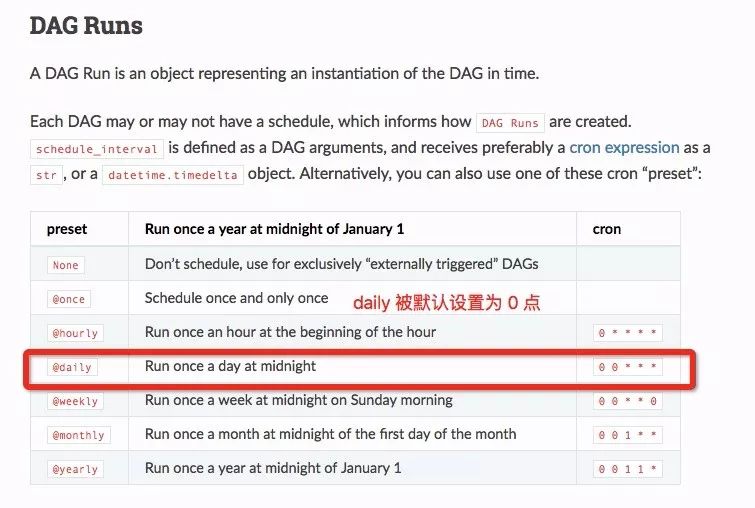
Airflow的Daily调度默认为0点
1.用数据说话,让一切人的决策基于数据;
2.开发灵活方便的Tool ,让一切人对机器的操作尽可能的自动化;
3.谨慎使用开源版本,尤其是非稳定的需要打Patch的功能,做好踩坑填坑的准备。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721