
蔡永承,现任唯品会大数据平台高级架构师、技术负责人。加入唯品会之前在eBay工作了12年,曾任大数据平台研发经理、MTS2等职位。主要关注大数据平台监控、数据治理以及性能优化。
声明:本文转自唯技术公众号,已经同意授权转载。
大数据平台在唯品会近几年有了飞速发展,已经完成了从0到1的过程,各个部门逐渐将其引入到实际业务中。在业务压力和集群负载同步增加的情况下,如何实现平台优化是2017年的主旋律。本文不可能面面俱到讲所有新东西,主要从集群健康和资源有效利用角度进行探讨,围绕集群监控、HDFS、Yarn和Capping调度来展开。
集群监控
Hive在多HDFS集群的实践
Yarn分配性能优化
基于Hook的Capping资源管控
一、集群监控
1、技术架构

这个技术架构主要关注于离线数据平台。原始数据通过Flume和Sqoop接入不同的数据源,离线的ETL主要通过Hive 和Spark SQL进行数据处理。Presto主要用于Ad hoc的查询任务。这些工作都在数据开发平台自研的数坊中进行。ETL开发自助的数据查询、定时任务ETL开发以及自助报表订阅,这些作业通过调度程序和作业前置依赖进行调度。在前端我们开发了自助分析平台和各种数据产品,比如比价选品、魔方等数据应用于生产。
2、大数据平台
Hadoop=HDFS+Yarn版本CDH5.3.2->CDH5.13.x
2个集群:主集群(900)+SSD集群(50)
Hive版本0.13.1->2.1.1
Spark版本2.1.1,2.2
Hadoop集群开始于2013年,已经有4年时间了。我们从0开始建设,到现在有一个将近1000个节点主的集群以及一个用于实时离线融合的SSD集群。我们正在升级Hadoop以及Hive到最新版本。目前每天运行作业10万,yarn app达到50万以上。
3、大数据周边系统
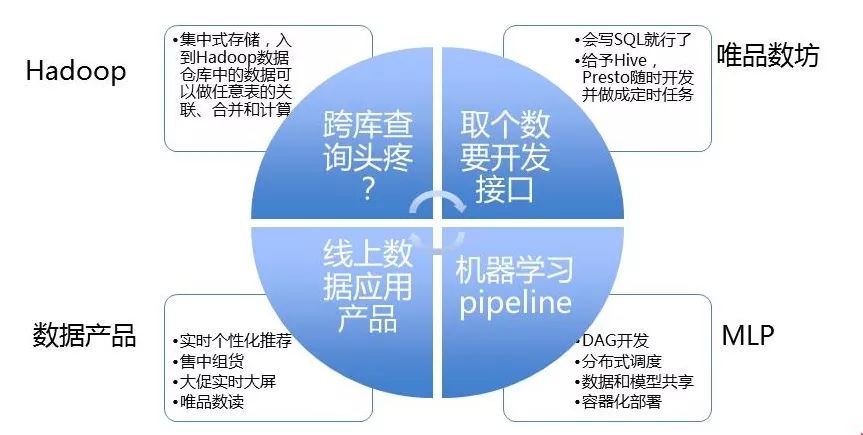
首先,通过专为海量数据批量处理设计的Hadoop集中式存储数据的平台,数据进入Hive数据仓库后,任意表就能关联、合并和计算,同时还保存了全量数据。SQL基本是一个人人都会的开发语言,在唯品数坊中通过SQL查询和处理数据,结合调度系统,就可以自动处理,合理分配资源执行大数据量的数据批量任务。对于个性化推荐需求,机器学习pipeline建立了DAG,开发者通过DAG Editor就可以通过拖拉的方式建立机器学习实例,并且分布式进行调度。大数据除了应用于内部数据分析工具外,还出品线上业务的数据产品比如消费者在前端看到的实时个性化推荐,内部比价系统和供应商用于生产的售中组货,魔方等。
4、技术挑战:数据平台监控、集群压力、性能优化
大数据平台主要职责是维护集群的稳定性,提供充足的资源以及多样化场景的需求。这个和我们面对的挑战是一致的。集群稳定性很重要的一点是可以通过平台监控来感知平台的隐患和压力。在监控中发现集群压力,我们下一步就要进行性能优化。优化后我们通过监控系统查看效果。这在整体上是一个闭环的过程。
监控架构图

系统告警在框架上必须满足三大要求:第一是必须全部覆盖机器层面、日志层面和服务层面,不可偏颇;第二必须是实时监控,遇到故障需要从邮件、短信和电话不同级别地升级和降级;第三也是非常重要的,就是告警规则必须是容易配置的。
用ES来监控日志文件和Zabbix来做机器层面的监控是我们做了比较久的,今年我们新的尝试是引入Prometheus和Grafna来重构服务层的监控。Prometheus相当于就是开源版本的Borgmon,而Borgmon是Google内部做大规模集群的监控系统。唯品会使用Prometheus主动Pull各种指标数据通过Grafana完美展现部门大屏dashboard。目前Grafana已经对接原有的Zabbix数据源和ES数据源,同时开通了基于jmx的各种开源组件监控,包括Kafka、Hadoop、Cassandra等,对接邮件、短信和电话告警用于生产。
HTTP Sever实现

这里简单介绍一下如何通过Prometheus做服务层面的监控原理。Preometheus 是采用pull的模式而不是通过玩agent的方式拿数据,这样的好处就是不用客户端的强依赖。但prometheus对于数据格式是有要求的,所以在这里首先需要建立一个Http Server来将metrics转换成prometheus认识的文本格式。这里的例子是获取kafka lagoffset,然后这个服务开放以后,prometheus就可以主动pull这个网址来实时抓到数据了。
Grafana配置
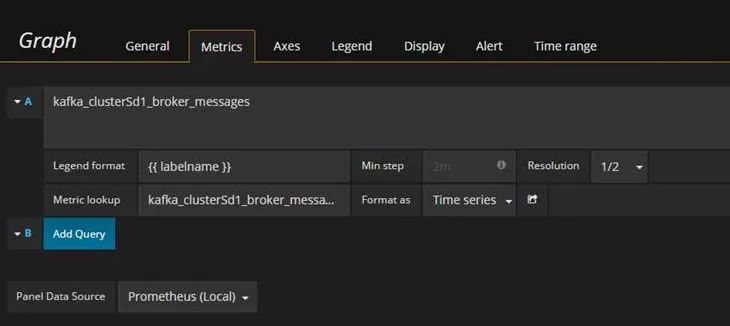
Prometheus拿到数据后就会存储到本地或者remote的存储,前端Grafana的配置也是非常简单的,定义好数据源和metrics,加到Graph就可以了。在这个配置中,可以通过嵌入的web hook来定义告警规则。规则定义也是所见即所得,运维人员非常容易上手。
Grafana展示
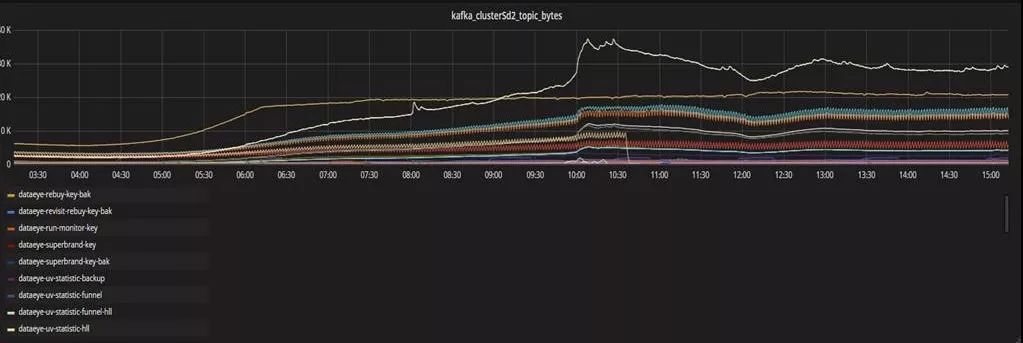
通过Grafana展示可以校验监控数据的链路。Grafana提供了托拉拽的功能,我们把各种不同的metrics监控图组合成立了一个部门大屏。通过统一制定大屏,我们可以对系统情况一目了然。我现在每天上班的第一件事情,就是打开这个部门大屏查看系统情况。
二、Hive在多HDFS集群上的实践
说完了监控部分,我们开始今年的一个落地尝试——实现多HDFS集群。在调研落地时我们发现目前比较流行的社区Federation方案与业务不是非常兼容。在这个基础上,我们研究了多HDFS集群的应用,保持一个YARN、支持多个HDFS集群方式。该实践的特点是通过Hive层来使HDFS透明化,最大限度兼容原来的应用。
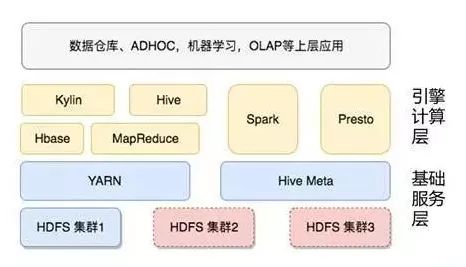
多HDFS架构图
从多HDFS架构上来看,我们可以支持更多的HDFS集群,在上面暴露给业务方的是一个统一的yarn和Hive metastore。通过底层的改变,我们希望用户如果通过metastore的访问可以做到透明。但是如果用户直接访问HDFS层,就需要通过设置一个缺省的hdfs集群保持不变。
1、问题背景
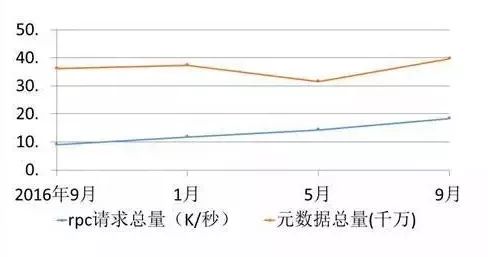
需要多HDFS集群是由于单节点的NameNode压力导致。在去年9月份时一亿的元数据增长一年就到了两亿元数据,数据增长非常快。对于平台方来讲,我们需要未雨绸缪。这样如何横向扩展NameNode能力就被提上了日程。
社区Federation虽好,但……
ViewFS与原来的scheme不兼容,要全面替换业务方代码中不兼容的路径,容易导致数据生产的不稳定。
用mounttable的挂载方式过于负责,对客户端的依赖性很强,难以维护,不利于后期数据的迁移。
Hive、Spark等上层应用对Federation的支持存在问题。
目前业界比较普遍的做法是采用Federation,我们在调研后发现federation需要业务分割的比较清楚,这和我们目前的业务模式不是非常吻合,而且它需要通过比较重的客户端ViewFS来实现,需要使用mounttable的挂载方式,这就好比为行驶中的汽车换轮胎一样。有没有一种更加轻量级的方法来实现类似的横向扩展呢?
2、Hive表的数据存在跨多个集群

多HDFS扩展首先需要解决的问题是如何透明地支持上层应用。我们用的方法是使用Hive的location特性使得表的location是可以区分集群的。这个可以支持一个表的不同分区在不同HDFS集群上面。
XML配置方式
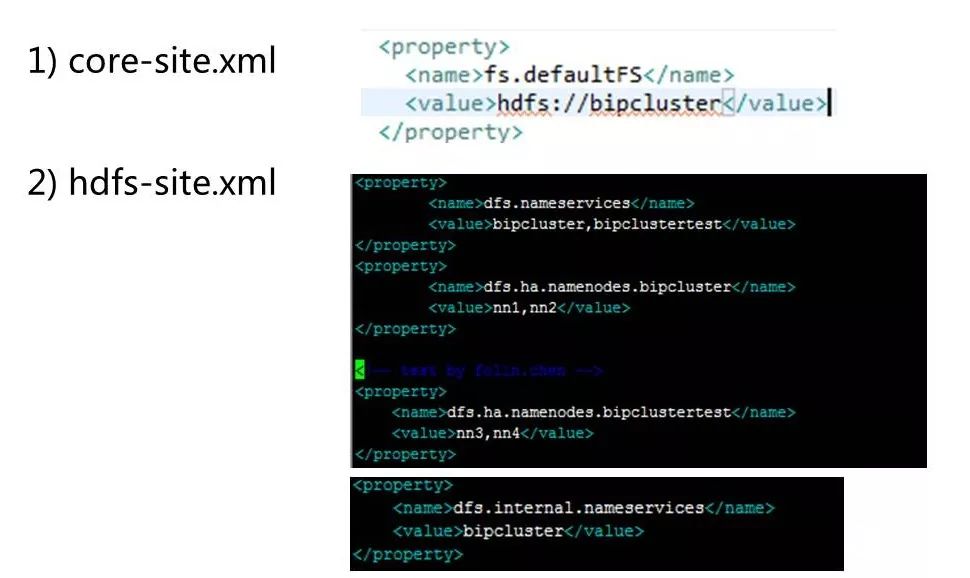
在XML配置上,和federation 非常类似,但是去除了部分关于mount table的配置和减少重客户端viewFS的方式。我们增加了internal.dataservices的属性,来指定缺省的集群。
3、多HDFS集群的应用
保持一个Yarn集群、两个或多个HDFS集群
保持HDFS的Scheme,最大限度兼容原来的应用
通过Hive层来使用新HDFS集群,以Hive的DB为粒度将Hive数仓的部分库与表迁到新集群
查询中心、Presto、Kylin等使用Hive元数据可以读写新集群的库和表
轻量级地实现Federation功能,去除强客户端依赖
我们已经部署了半年时间,对用户唯一不方便的地方则是直接写HDFS的程序使用具体的集群,由于我们在配置里加了internal.nameservices,如果用户不写,缺省就会到缺省的集群。各方面反映还是不错的。
三、Yarn分配Container性能优化
1、问题背景

问题的提出是这样的,在优化以前每一个containser分配资源需要0.8ms,那么总共7万个container,如果顺序分配完的话就需要大约1分钟。这个需要进行优化。
2、分析原理
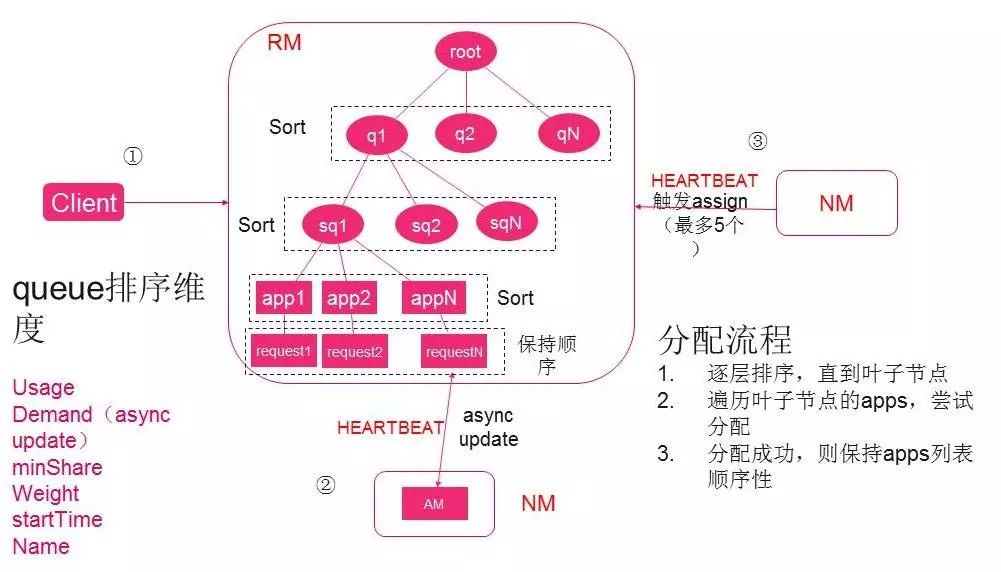
优化首先要了解分配原理是怎样的。唯品会使用的yarn的分配策略是fair scheduler,它的特点是倾向于公平分配。调度器每次选择作业资源缺额最大的。那么每一次分配逐层遍历并根据缺额进行倒排序,然后尝试分配。
分析原理——metrics耗时
排序childQueues耗时和childQueues尝试分配资源失败耗时有一半左右时间
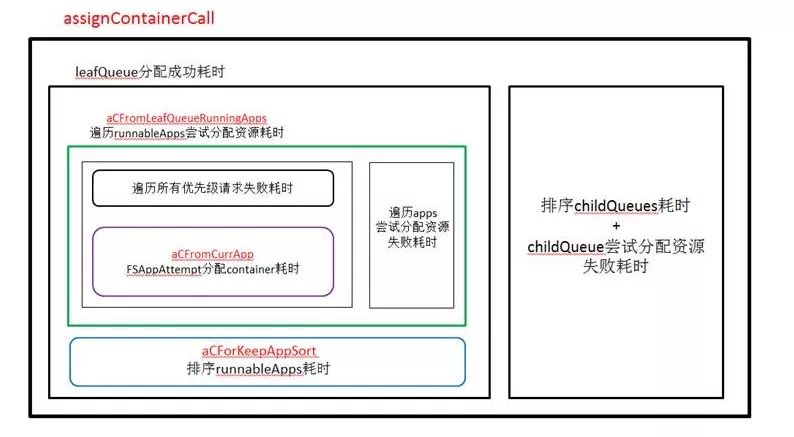
我们通过打metrics将耗时进行了分析,发现分配资源占了一半时间。当然分配失败是有很多种原因的,这里不一一列举了。我们的关注点在于如何提高资源分配的成功率,这将会缩短分配时间,提高分配效率。
3、优化方案——每次心跳分配新逻辑
连续分配contianer不排序同时启发策略使得第二次分配从上一次index开始减少了分配失败几率
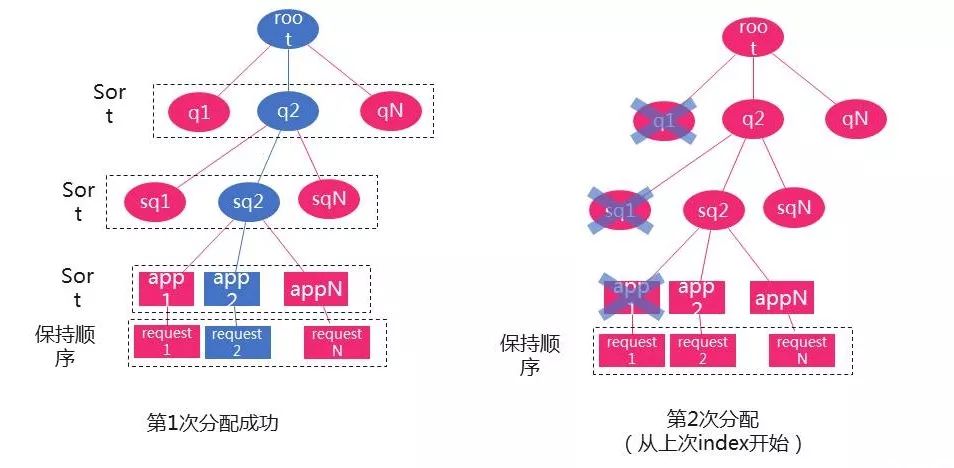
有了前面的分析以后,新的分配算法就呼之欲出了。我们通过分配container不排序同时启发策略,从上一次index开始继续分配。这个方法提高了分配的时间效率,当然这是一种trade-off。
4、优化结果
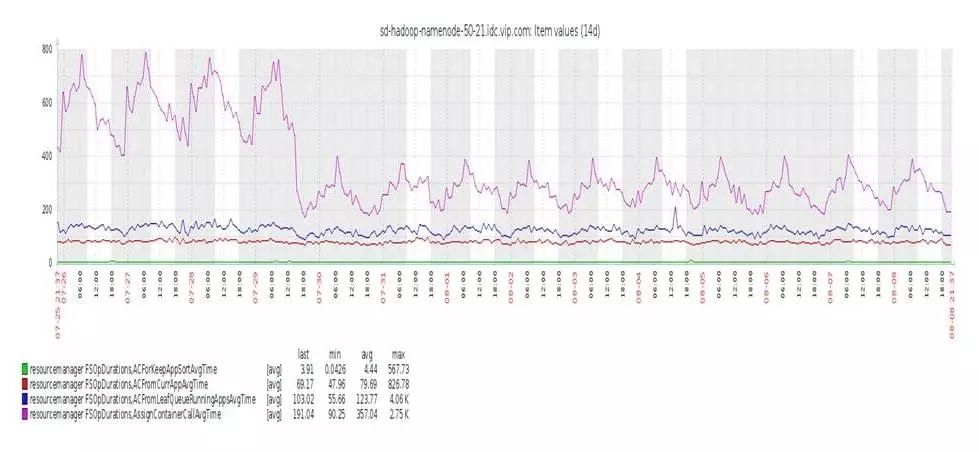
从优化结果看,提高了近一倍的分配效率。
四、基于Hook的Capping资源管控
最后再讲一下以capping的流量控制为基础的资源管控。
1、问题背景
(1)问题-系统繁忙时候,不断有作业提交上来,两种后果:
部分拒绝服务请求,只挑选高优先级作业
全部接收服务请求,把自己搞死
(2)对策-就像交通指挥,我们在Hive/Spark Hook中增加管控,通过比较监控系统繁忙和队列Capping阈值,如果超限拒绝请求。
这个资源管控问题源自于交通控制问题。那么在交通繁忙的时候,马路上公交车的优先级比私家车高,救火车的优先级又比公交车高。这个原理同样可以应用于Hadoop的资源管控。
2、调度系统队列自动匹配
基于项目维度进行作业管理
基于项目进行队列分配
基于作业特征进行子队列匹配
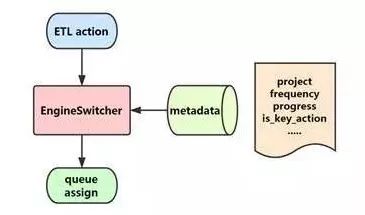
实现作业资源管制的方法是首先我们能够认识来的作业是什么项目的,作业的优先级设置是怎样的。在平台这一层还需要配置不同优先级的队列,就像马路上不同的车道一样的道理。这里核心功能就是engineswitch可以通过读取metadata,给作业填上不同的队列信息进行作业提交。
3、基于hook的capping控制模块
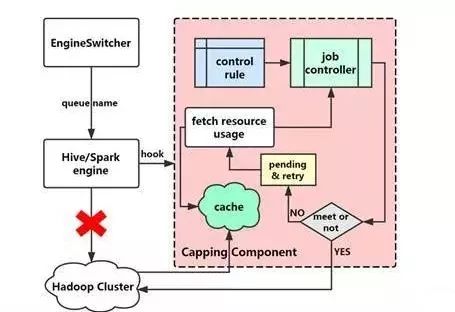
有了capping控制模块以后,作业将不会直接提交到集群,而是调用hook首先感知系统资源使用繁忙程度,然后比较队列capping阈值,再决定是否直接提交还是继续等待。我们设置了等待重试6次将会直接设置作业失败。
4、基于Quota的Capping资源管控
基于三级队列定制差异化Capping值
团队的日Quota超出后,自动降级当日Capping值
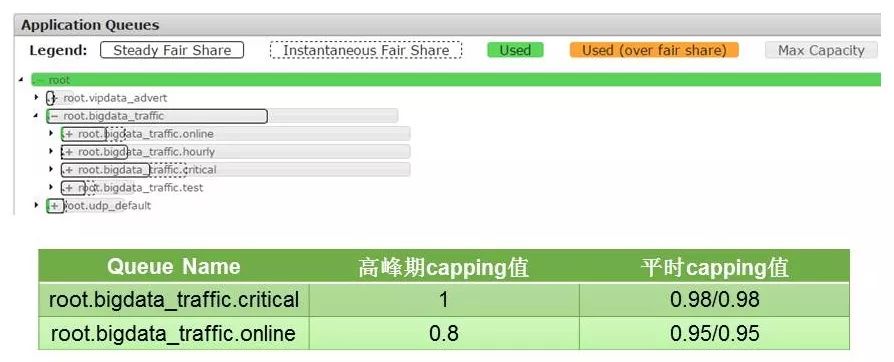
通过一个实际例子,我们可以更加清楚地了解这个原理。Root.bigdata_traffic.critical 和root.bigdata_traffic.online是两个三级队列,他们的capping阈值是不同的。在高峰期,他们的capping值分别是1和0.9。当系统繁忙root.usage在0.95时,critical这个关键队列里的作业就可以提交作业,而online队列就被堵塞了。直到root.usage下降了或者到了非高峰期的阈值变成了0.95。
另外一点是我们已经实现了为各业务团队配置资源的限额(Quota),一旦该团队当日使用量超过日Quota值,系统将会自动降级该团队下面队列的Capping阈值。
感谢各位,以上是我们在2017年做的一部分工作,欢迎指正。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721