
作者介绍
杜亦舒,创业中,技术合伙人,喜欢研究分享技术。个人订阅号:性能与架构。
本文介绍了 Apache Storm 的基本原理和开发方法,包括一个 PDF 和 2 个示例的源码。
内容大纲:
Storm是什么
应用场景
Storm与Hadoop的关系
Storm怎么用
示例1:统计单词出现的次数
核心概念
集群架构
示例2:统计通话记录
1
Storm是什么
Storm 是一个分布式实时大数据处理系统,可以帮助我们方便地处理海量数据,具有高可靠、高容错、高扩展的特点。
Storm 是流式框架,有很高的数据吞吐能力,Strom 本身是无状态的,通过 ZooKeeper 管理分布式集群环境和集群状态。
Strom 的安装和使用都很简单,但功能强大,可以并行地对实时数据流进行各种处理。
2
应用场景
应用 Storm 的场景例如:
日志处理
监控系统中的事件日志,使用 Storm 检查每条日志信息,把符合匹配规则的消息保存到数据库。
电商商品推荐
后台需要维护每个用户的兴趣点,主要基于用户的历史行为、查询、点击、地理信息等信息获得,其中有很多实时数据,可以使用 Storm 进行处理,在此基础上进行精准的商品推荐和放置广告。
3
Storm与Hadoop的关系
Storm 与 Hadoop 都用来处理大数据,那么它们的关系是怎样的呢?
Hadoop 是强大的大数据处理系统,但是在实时计算方面不够擅长;Storm的核心功能就是提供强大的实时处理能力,但没有涉及存储;所以 Storm 与 Hadoop 即不同也互补。
它们的最主要的区别例如:
Storm 是实时流处理模式,Hadoop 是批处理模式;
Storm 就像一条川流不息的河流,只要不是意外或者人为停止,它就会一直运行,Hadoop 是在需要时执行 MapReduce 任务,执行完成后停止;
在处理时间上,Storm 每秒可以处理数万条消息,HDFS+MapReduce 处理大量数据时通常需要几分钟到几小时。
4
Storm 怎么用
Storm 非常简洁,为了便于理解,先看 2 个最核心的概念:
数据源头 Spout
数据处理单元 Bolt
先把 Spout 与外部数据进行对接,这样就可以把外面的数据量引到 Storm 中了。Spout 接收到数据后就会发给 Bolt,这就需要告诉 Bolt 如何处理,处理完成后把数据放到哪儿,例如数据库。
这就是一个最简单的模型:
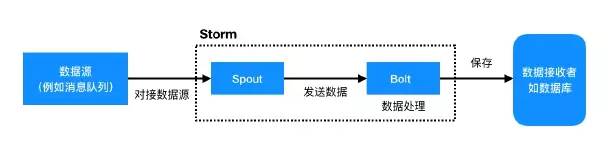
而其中 Bolt 可以有多个,这就使得 Storm 强大而灵活。
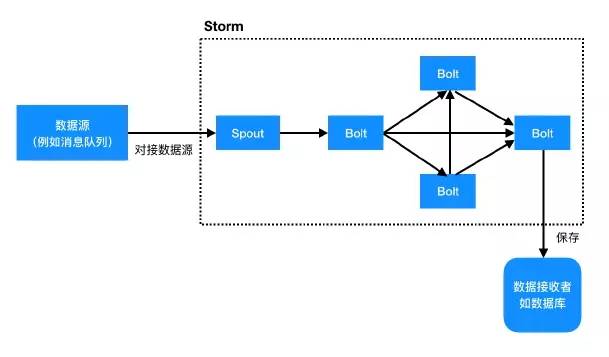
可以看出 Storm 就是一个有拓扑图,点是 Spout 或者 Bolt,边是数据流向。

所以,使用 Storm 时需要做的就是把整个拓扑图构造出来:
定义数据从哪儿来
定义数据流向和处理单元的逻辑
定义数据到哪儿去
5
示例1 统计单词出现的次数
以大数据中的helloworld “词频统计” 为例来学习 Storm 的开发方法。
1、实现思路
构造拓扑结构:
Spout 读取一行文本,向下游发送;
把句子分割为单词的 Bolt,从 Spout 发出的数据中取得一行文本,然后分割为一个个的单词,把每个单词向下游发送;
单词计数的 Bolt,接收分词 Bolt 发出的单词,对每个单词出现的次数进行统计,然后把单词及其次数作为一个数据单元向下游发送;
结果输出的 Bolt,接收计数 Bolt 发出的数据单元,取出单词及其次数进行汇总,最后输出统计结果;
创建拓扑对象,把 Spout 和各个 Bolt 连接起来,然后提交到 Storm 中执行。
2、代码实现
创建项目目录 storm-wordcount
项目目录下新建 maven 工程文件 pom.xml

项目根目录下执行 maven 命令,安装依赖
mvn package
mvn dependency:tree
项目根目录下创建源码目录 src/main/java
然后在 java 目录下创建包目录 com/storm/test
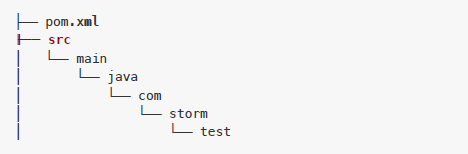
现在项目的目录结构如下:
具体代码如下:
SpoutWords.java

BoltSplit.java

BoltCount.java

BoltReport.java

WordCountTopology.java

编译运行

执行后会输出大量日志信息,之后会循环输出单词统计信息,例如:

6
核心概念

Storm 从外部接收数据,例如 Twitter Streaming API、Kafka ……,通过 Spouts 从这些数据源读取数据。
Spouts 向 Bolts 传递数据,Bolts 接收数据进行处理操作,然后把结果再发射出去。
Bolts 的常见操作例如:过滤、聚合、连接、与数据源数据库交互。
Storm 数据流中的数据单元,例如水流中是一滴滴的水滴,Storm 数据流中流淌的就是一个个的 tuple,里面包含着数据。
是一个无序的 Tuple 序列。
Spouts 和 Bolts 连接起来之后形成了 Topology,其中定义了整个应用的实时处理逻辑。
Topology 是一个有向图,定点是计算单元,边是数据流。
Topology 始于 Spout,Spout 向一个或者多个 Bolt 发射数据,Bolt 拥有处理逻辑,Bolt 的输出可以发射给其它 Bolt 作为它们的输入。Storm 会保持 Topology 一直运行,除非杀掉他。
一个 Task 就是一个 Spout 的执行,或者一个 Bolt 的执行。
Worker 负责实际运行 Task,Topology 运行在一个分布式环境中的多个工作节点上,Storm 会把 Tasks 均匀的分布在所有 Worker 上。
每个 Worker 都是一个物理 JVM,执行着 Topology 中所有 Task 的一个子集。
简单理解就是控制 Tuple 的路由,定义 Tuple 在 Topology 中如何流动。每个 Spout 或 Bolt 都会在集群中执行多个任务,每个任务都对应为一个线程的执行,Stream Grouping 定义的就是如何从一个 Task 集合 向其他 Task 集合 发送 tuple。
现在 Storm 中已经有 8 种分组策略,下面看下其中 4 种常用的:
(1)Shuffle Grouping
随机分配,可以让每个 Bolt 获得数量均衡的 tuple。

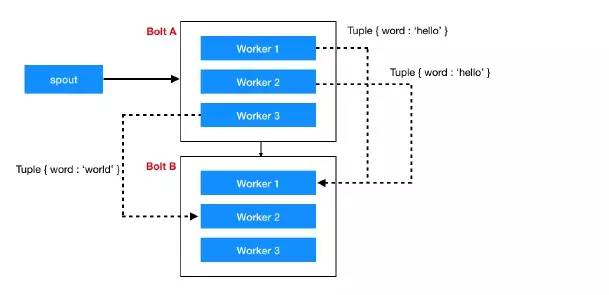
(2)Field Grouping
field 名字相同的 tuples 会被组织在一起,例如,如果根据 "user-id" 这个 field 分组,相同 "user-id" 的 tuples 将总是去向同一个 Task,其他的 tuples 则去向不同的 Task。
(3)Global Grouping
全局统一分组,所有数据流都流向同一个 Bolt。
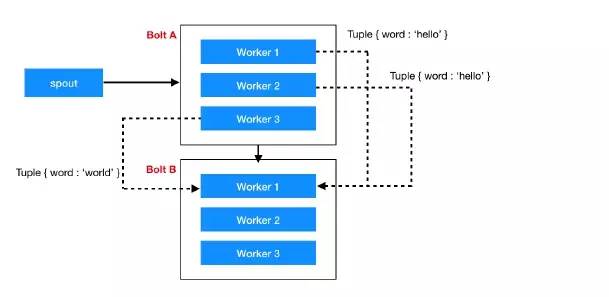
(4)All Grouping
向每个实例都发送一次,主要用于发送信号。

回顾一下 wordcount 示例中使用的 grouping 方法

设置第一个 Bolt bolt-split 时使用的是 shuffleGrouping,因为 Spout 发送一行文字,给谁都行,不关心分组,所以使用 shuffleGrouping 随机即可。
设置第二个 Bolt bolt-count 时使用的是 fieldsGrouping,因为 bolt-split 是按单词发射的,所以需要让同一个单词被同一个Task处理,就要使用按字段分组方式。
设置第三个 Bolt bolt-report 时使用的是 globalGrouping 统一分组,因为到这儿就要汇总了,需要接收所有的统计结果。
7
集群架构
Storm cluster 中有2种类型节点:master node、worker nodes。
master node 中运行着一个守护进程,名为 Nimbus,负责向集群中分布代码、分配任务、监控失败状况。每个 worker node 中运行着一个守护进程,名为 Supervisor,负责接收工作任务,根据 Nimbus 的指令来启动或者停止工作进程。
每个工作进程执行一个拓扑的子集,一个拓扑包含多个工作进程,这些工作进程散布在集群里的多台机器中。
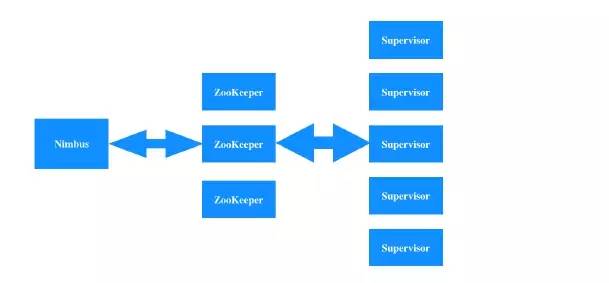
Nimbus 与 Supervisors 的协作是通过 ZooKeeper 集群 完成的,Nimbus 与 Supervisors 都是无状态的,状态信息保存在 ZooKeeper 或者本地磁盘中。
Nimbus 与 Supervisors 具有高可靠性,即使通过 kill -9 杀掉他们,也会快速重新启动起来,这使得 Storm Cluster 极其稳定。
上图是 Storm Cluster 的全景图,下面我们看一下细节:
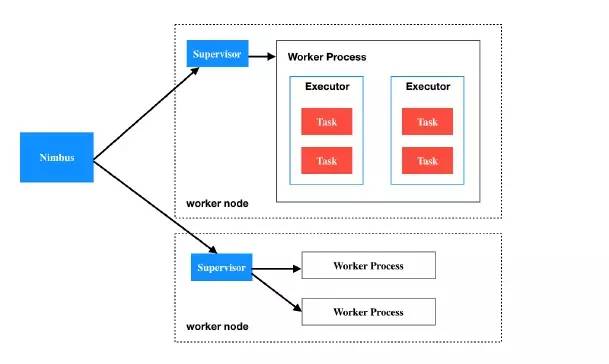
概念总结:
Nimbus - Storm Cluster 的主节点,其他节点都是工作节点 worker node,主节点负责任务分配、监控失败等管理工作。
Supervisor - 负责接受 Nimbus 分配的任务,一个 Supervisor 会有多个工作进程 worker process,并管理这些工作进程来完成接收到的任务。
Worker process - 工作进程,一个工作进程会执行某个特定 Topology 的相关任务,它并不直接自己执行任务,而是创建executors 来执行,一个工作进程可以有多个 executor。
Executor - 执行器,就是工作进程创建的一个线程,一个执行器会执行一个或多个任务。
Task - 执行实际的数据处理,也就是一个 Spout 或 Bolt。
简单总结一下:
一个 Storm cluster 中有一个Nimbus 和多个Supervisor;
一个 Supervisor 下有多个 Worker process;
一个 Worker process 有多个 Executor;
一个 Executor 下有多个 Task。
8
示例2: 统计通话记录
1、需求描述
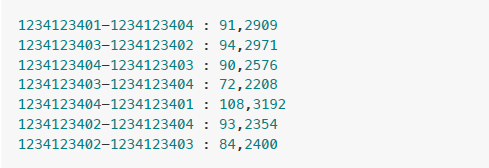
处理通话记录,统计相同呼叫人和被呼叫人的通话次数、通话总时长。
例如通话记录:
# 呼叫者号码,接收者号码,持续时长
1234123402, 1234123401,20
...
统计结果例如:
1234123402-1234123401 : 87,2523
1234123402-1234123404 : 95,2919
...
2、实现思路
构造拓扑图:
Spout 读取通话日志,发送给 Bolt,数据包括 from, to, duration
Bolt1 接收 Spout 的数据,重新组织数据格式为 from-to, duration
Bolt2 接收 Bolt1 的数据,对 from-to 相同的数据进行汇总,累计次数、总时长,在最后输出统计结果
Topology 中连接 Spout 与 Bolt1、Bolt2,并提交 Storm 执行
3、具体实现
(1)创建项目目录
在合适的位置创建项目目录 storm-mobile
(2)新建 pom.xml
项目根目录下新建maven工程文件 pom.xml,内容:

项目根目录下创建源码目录 src/main/java
然后在 java 目录下创建包目录 com/storm/test
现在项目的目录结构如下:

(3)安装依赖
项目根目录下执行maven命令
mvn package
mvn dependency:tree
(4)代码
下面是具体代码:
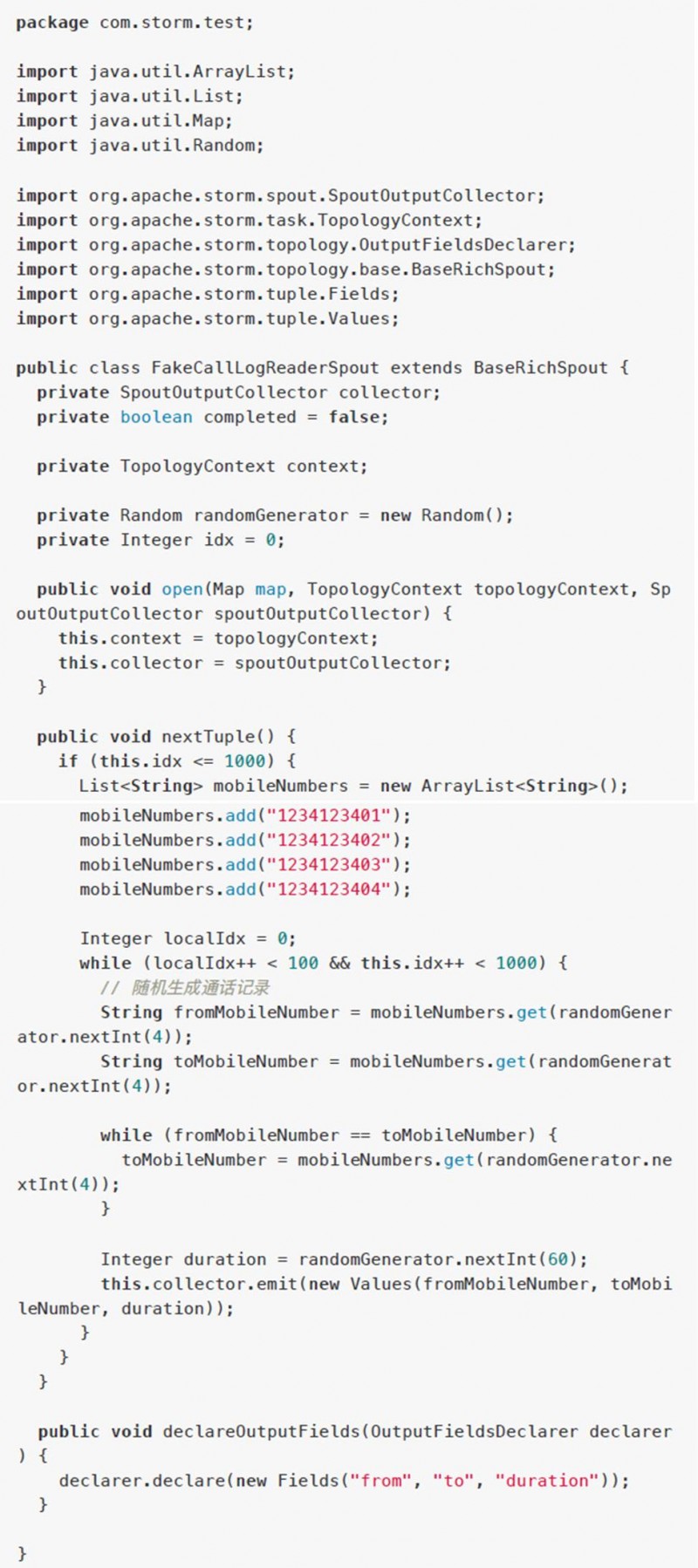
FakeCallLogReaderSpout.java
CallLogCreatorBolt.java
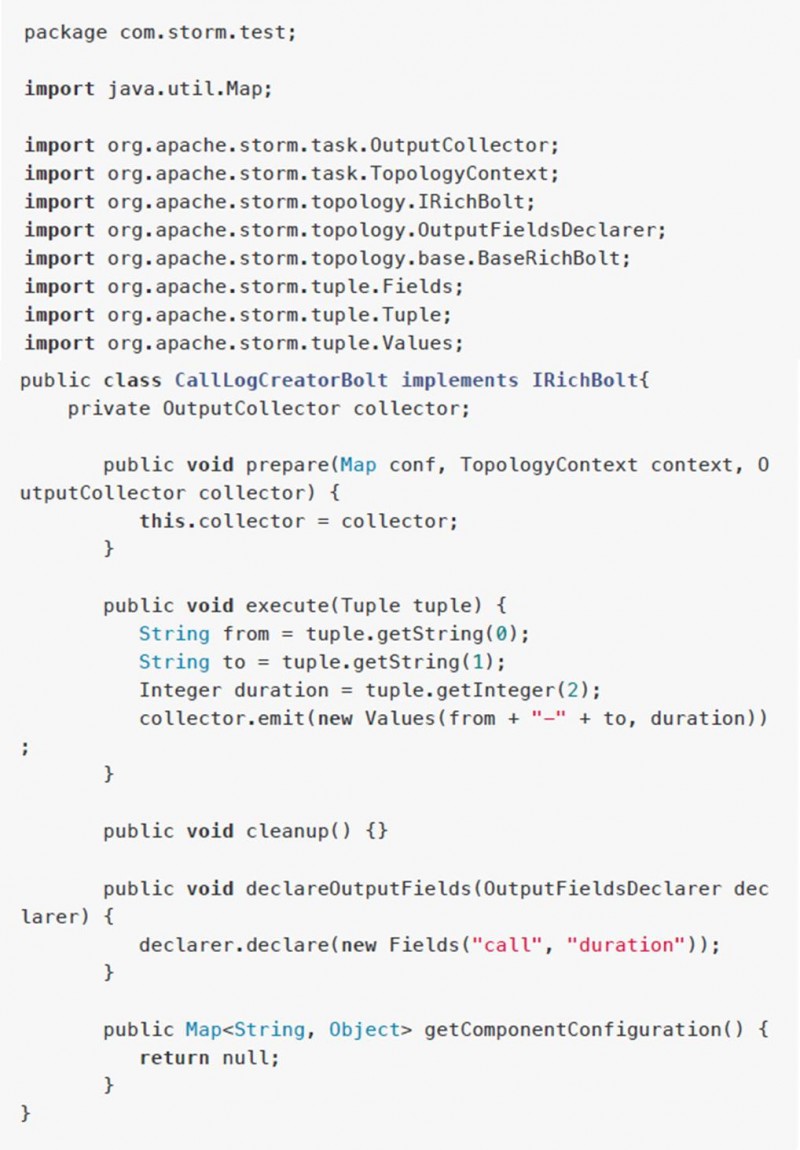
CallLogCounterBolt.java
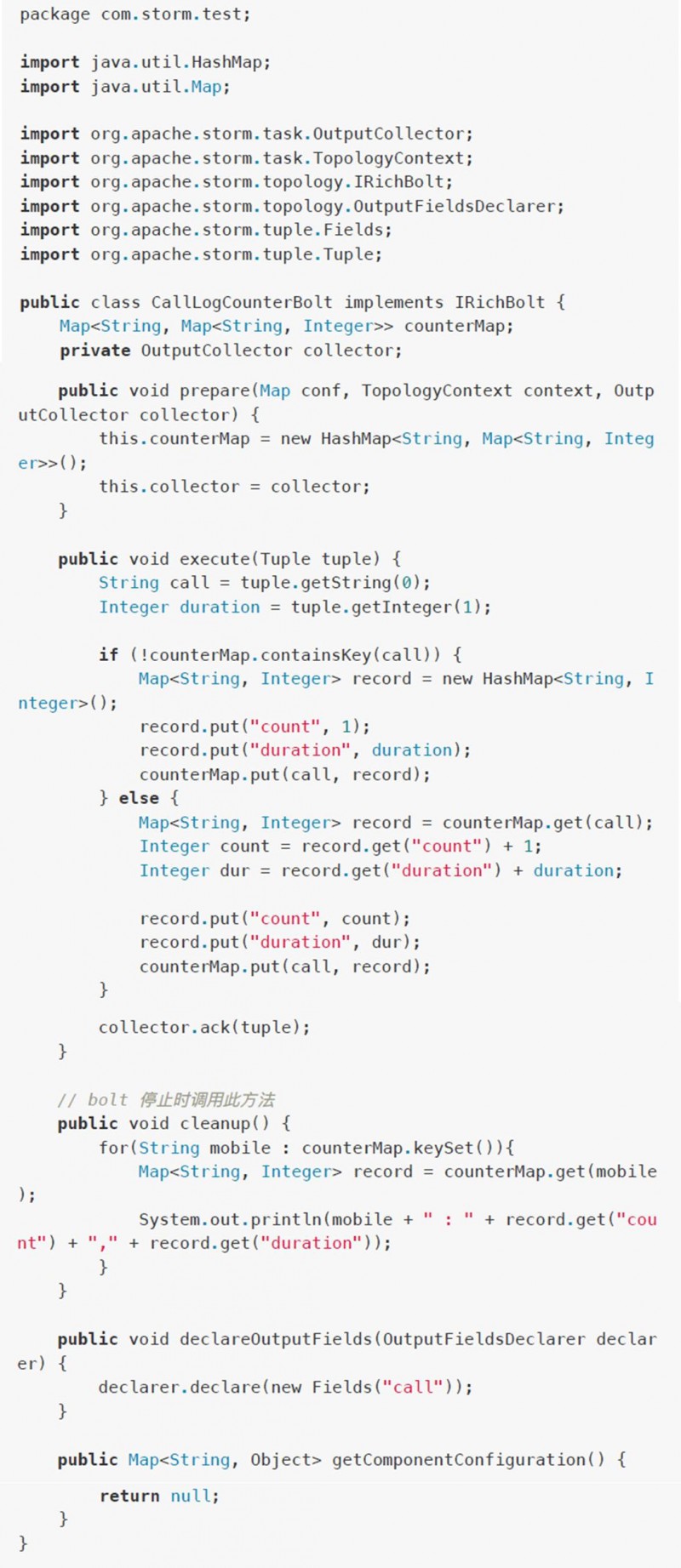
LogAnalyserStorm.java

(5)编译运行

会输出大量的 log 信息,执行完成后,会在底部附近输出程序的执行结果,类似如下信息:
9
小结
Storm 开发的基本思路:
Spout 中与外部数据源对接,然后发送给内部的 Bolt
Spout 中的主要方法 nextTuple() 被循环调用,在这里面处理数据的接收、发射
Bolt 中定义数据处理逻辑,对接收到的数据进行处理
其主要方法 execute() 每次收到数据时被调用,在这里定义处理逻辑
Topology 中把 Spout 和 Bolt 串起来,定义好上下游关系,然后提交到 storm 执行
先把这个最简单的思路理解好,然后在此基础上进行扩充,学习更多的用法就简单了,希望本文可以帮助您快速认识 Storm。
教程下载:如需下载本文,登录云盘 http://pan.baidu.com/s/1geHiLY7进行下载。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721