
投稿:新炬网络浙江大数据团队
这是一个大数据爆发的时代。面对信息的激流、多元化数据的涌现,我们在获取、存储、传输、理解、分析、应用、维护大数据时,无疑需要一种便捷的信息交流通道,以便快速、有效、准确地理解和驾驭这个过程。本文将通过时序数据库(InfluxDB)+Grafana的实践,来介绍如何将数据便捷地展现出来。
开源的分布式时序、时间和指标数据库,使用Go语言编写,无需外部依赖。其中,时间序列数据库是数据格式里包含Timestamp字段的数据,比如某一时间用户上网流量、通话详单等。但是,有什么数据不包含Timestamp呢?几乎所有的数据都可以打上一个Timestamp字段。时间序列数据更重要的一个属性是如何去查询它,包括数据的过滤、计算等。
它有三大特性:
时序性(Time Series):与时间相关的函数的灵活使用(例如最大、最小、求和等);
度量(Metrics):对实时大量数据进行计算;
事件(Event):支持任意的事件数据,换句话说,任意事件的数据我们都可以做操作。
个人认为InfluxDB的几个优点:
无特殊依赖,几乎开箱即用(如ElasticSearch需要Java)
自带数据过期功能;
自带权限管理,精细到“表”级别;
原生的HTTP支持,内置HTTP API
强大的类SQL语法,支持min, max, sum, count, mean, median 等一系列函数,方便统计。
自带管理界面(如下图),免插件配置。
1、与传统数据库中的名词做比较
|
InfluxDB中的名词 |
传统数据库中的概念 |
|
database |
数据库 |
|
measurement |
数据库中的表 |
|
points |
表里面的一行数据 |
2、InfluxDB中特有的概念
1)Point
Point由时间戳(time)、数据(field)、标签(tags)组成。
Point相当于传统数据库里的一行数据,如下表所示:
|
Point属性 |
传统数据库中的概念 |
|
time |
每个数据记录时间,是数据库中的主索引(会自动生成) |
|
fields |
各种记录值(没有索引的属性)也就是记录的值:温度, 湿度 |
|
tags |
各种有索引的属性:地区,海拔 |
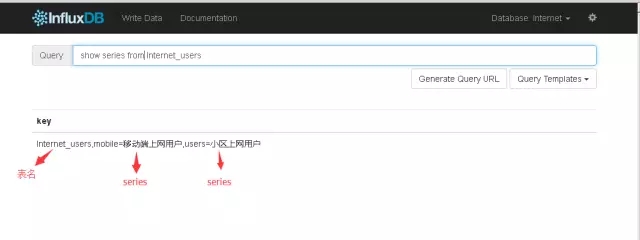
2)series
所有在数据库中的数据,都需要通过图表来展示,而这个series表示这个表里面的数据,可以在图表上画成几条线:通过tags排列组合算出来。
如下所示:
3、InfluxDB相关API
InfluxDB 支持http api 方式写入数据。使用curl这个工具来模拟HTTP 请求,在实际使用中,可以将请求写入代码中,通过其他编程语言来模拟HTTP请求。
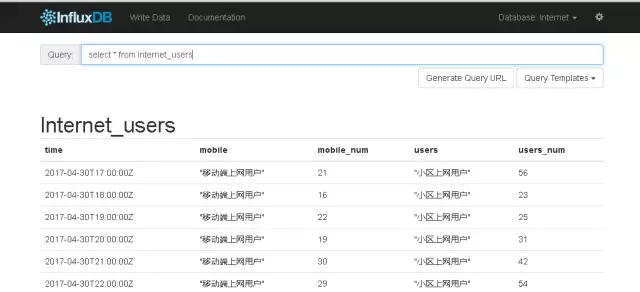
例如:通过HTTP API向Internet_users这张表添加数据
curl -v –XPOST "http:// localhost:8086/write?db=Internet&u=user&p=password" --data-binary "Internet_users,users=小区上网用户,mobile=移动端上网用户,users_num=56,
mobile_num=21 1493571600000000000"

说明:
db=Interne是指使用Interne数据库;
--data-binary后面是需插入数据,其中:
Internet_users:表名(measurement)
tag字段:users和mobile,值分别为:小区上网用和移动端上网用户
field key字段:users_num和mobile_num,值分别为56和21
时间戳(timestamp):1493571600000000000
这样,就向Interne数据库的Internet_users表中插入了一条数据。
需要注意,DB参数必须指定一个数据库中已经存在的数据库名,数据体的格式遵从InfluxDB规定格式,首先是表名,后面是tags,然后是field,最后是时间戳。tags、field和时间戳三者之间以空格相分隔。
InfluxDB 用于存储基于时间的数据,比如监控数据,因为InfluxDB本身提供了Http API,所以可以使用InfluxDB很方便的搭建了个监控数据存储中心。对于InfluxDB中的数据展示,这里不得不提数据展示利器-Grafana。
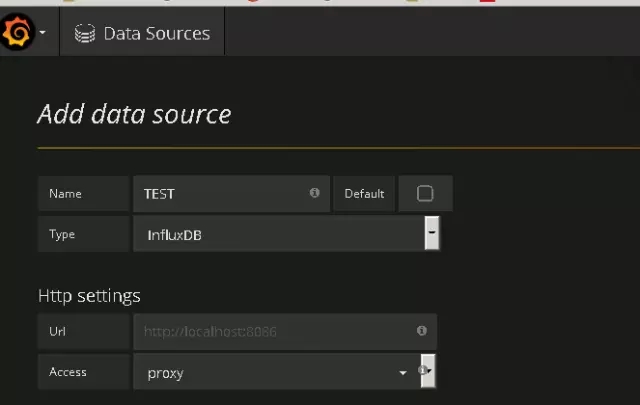
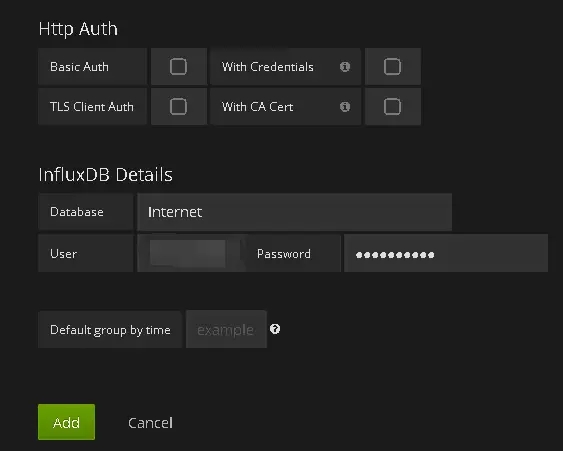
一个纯粹的HTML/JS应用,其功能非常强大,访问InfluxDB时不会有跨域访问的限制。只要配置好数据源为InfluxDB之后就可以,剩下的工作就是配置图表。
配置数据源:
设置查询条件:
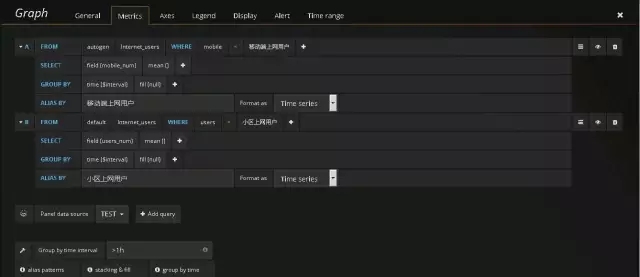
展示数据:
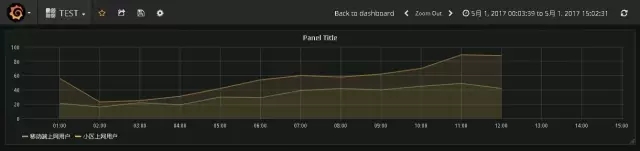
Grafana告警功能
没有比”可视化“更好的一个词能来概括运维的本质,我想Grafana也是深知广大运维人员的痛处:如何用可视化数据说话? 所以Grafana在 4.0以后版本:新增报警功能(Alerting),根据官网介绍,Grafana报警方式也有很多种,常见的Email、Slack即时通讯、webhook等。
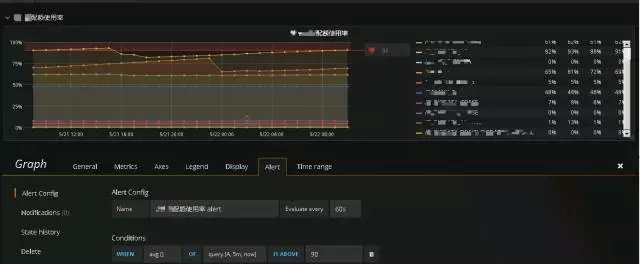
下图为目前集群Grafana监控界面,主要包含对集群主机CPU、内存配合Grafana的阈值预警功能:
主机内存和CPU使用率监控:
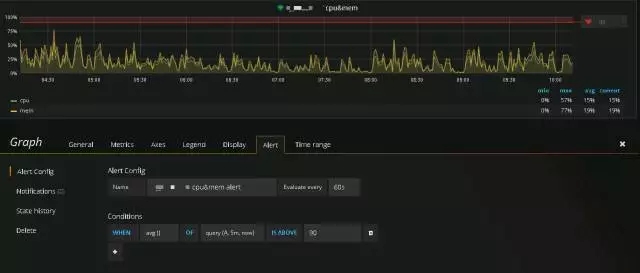
通过规则配置,可配置相关监控规则,包含相关逻辑与时间跨度以及监控告警条件。目前,仅支持一种条件类型—— Query 。可以指定Query字母,时间跨度和聚合函数。字母指定你在Metrics tab里设置的聚合函数。Query的结果和聚合函数将会是一个单一的值,用于后面判断是否超过了阈值。
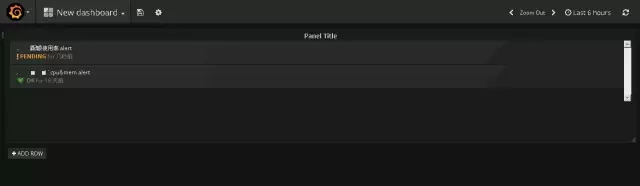
规则配置完成后可在报警列表里统一查看报表状态:
1、数据采集规划
目前采集数据主要来源于Hadoop的jmx监控,获取相关Cluster、Queue等Metrics信息以及部分Oracle日志信息,通过相关接口写入InfluxDB数据库,根据来源及日志信息从数据库层进行独立管理设计,以便后续维护。
2、InfluxDB数据库权限配置
InfluxDB自带权限控制,权限分别为:
ADMIN:所有者
READ :只读 (精确到库与表)
WRITE:只写 (精确到库与表)
ALL (READ 和 WRITE ) :读和写
鉴于源数据流,目前只会用到三个角色,对于这三个角色分工如下:
ADMIN:维护人员
READ:数据展示与后台查询(Grafana上设置的Influnxdb为只读)
WRITE:外部程序(插入数据至Influnxdb)
配置数据库权限需开启相关认证,操作如下:
把 [http] 标签下的 auth-enabled 选项值改为 true
[http]
enabled = true
bind-address = ":8086"
auth-enabled = true
log-enabled = true
write-tracing = false
pprof-enabled = false
https-enabled = false
https-certificate = "/etc/ssl/InfluxDB.pem"
3、Influnxdb和Grafana高可用配置
本次实践为了避免因主机通断而导致Influnxdb和Grafana服务无法使用的情况,所以在部署应用时用了2台虚拟机,2台虚拟机安装的服务如下:
|
主机 |
服务 |
|
Localhost-01 |
InfluxDB+Grafana |
|
Localhost-02 |
InfluxDB+Grafana |
在系统层方面又做了如下设置:
主机域名设置
将两台主机设置为主备模式,共用同一个域名http://xxx.xxx.com
|
域名 |
主机 |
主备模式 |
|
http://xxx.xxx.com |
Localhost-01 |
主 |
|
http://xxx.xxx.com |
Localhost-02 |
备 |
负载均衡设置
负载均衡设置即VIP主用与容灾端域名+端口与的Localhost-01~02主备节点域名+端口映射。大家都知道InfluxDB和Grafana端口如下图展示:
|
服务 |
端口 |
|
InfluxDB |
8083 |
|
InfluxDB |
8086 |
|
InfluxDB |
8088 |
|
Grafana |
3000 |
所以映射关系可设计成这样:
VIP:主用ip、容灾ip
VPORT:8083
均衡算法:pi 32 rr
健康检查:tcp
实例IP及端口:
Localhost-01的ip 8083
Localhost-02的ip 8083
其它端口均按此设置,负载均衡设置完成后,这里不得不提Grafana配置,如果要做到可视化展示的高可用,那么Grafana配置数据源就必须采用域名+端口的方式:
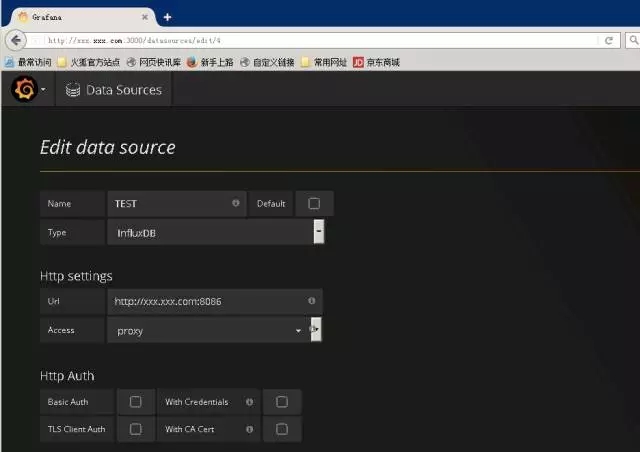
至此数据安全设置完毕。
4、Grafana界面配置
完成以上环境配置,根据相关需求进行Grafana界面配置以及监控配置,具体操作可以参照官网操作教程,这里不再赘述。
HDFS目录配额监控:
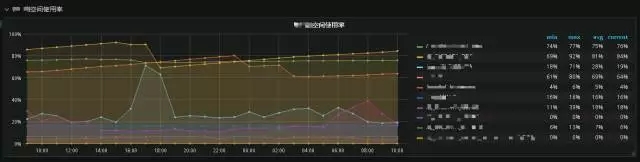
HDFS空间使用率监控:








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721