

11月26日,IBM资深软件工程师朱志辉老师,在DBA+社群DB2用户群进行了一次主题为“初窥Spark”的线上分享。小编特别整理出其中精华内容,供大家学习交流。同时,也非常感谢朱志辉老师对DBA+社群给予的大力支持。
IBM中国开发中心高级软件工程师
具有多年的数据库软件开发设计经验,擅长解决复杂的数据库应用系统问题及性能优化,拥有DB2多项认证和Oracle OCP证书
合作出版了《DB2设计,管理与性能优化艺术》《DB2性能管理与实战》
自从2007年加入IBM以来,一直从事DB2相关工具的开发与研究,现在专注Spark工具的初创研究
一、前言
Spark作为现在大数据领域最火热的技术,被称为将会是下个十所最重要的开源技术,其基于内存的计算速度100倍速于Hadoop MapReduce,基于磁盘的运算速度也比Hadoop MapReduce要快10倍,它易于使用,Spark提供了80个以上的高阶操作使你很容易的使用Java,Scala,Python,R等语言快速地构建分布式应用,你也可以Scala,Python和R shells进行交互式分析。作为一种通用数据处理引擎,你可以组合使用SQL,流处理等技术来进行复杂的分析,它能够运行在Hadoop,Mesos,standalone或者云环境下,也能够访问HDFS,Cassandra,HBase和S3等多种存储,下面我们从Spark的诞生背景开始讨论它是如何实现这些优势的。
二、Spark诞生的背景
MapReduce计算模型的诞生,极大的加速了大数据时代的到来(如果不熟悉MapReduce概念可以参考“我是如何向老婆解释MapReduce的?”这篇Blog),在许多情况下,可以将MapReduce视为关系型数据库管理系统的补充。两个系统的差异如下表。
|
传统关系型数据库 |
MapReduce |
|
|
数据大小 |
GB |
PB |
|
数据存取 |
多次读写 |
一次写入,多次读取 |
|
结构 |
静态模式 |
动态模式 |
|
完整性 |
高 |
低 |
|
横向扩展 |
非线性 |
线性的 |
MapReduce比较适合以批处理方式处理需要分析整个数据集的问题,随着MapReduce技术的发展,除了批处理类型的工作负载外,越来越多独立系统被开发出处理不同的工作负载。

Google就开发了Pregel来处理图形计算,Dremel来处理交互式SQL,也有自己流处理引擎。而开源的Hadoop体系也自己对应的处理引擎,每一种工作负责的处理都是由不同的引擎来负责,这样很难去部署,优化和管理众多的系统,而且这些工作流之种也很组合在一起形成流水线(Pipeline)。
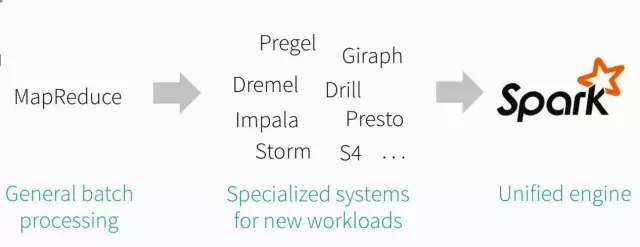
为了消除这种复杂性,Spark被设计为统一的大数据处理引擎,将批处理,交互式,迭代和流处理等有机的组合在Spark中。
Spark创始人认为,大多数的数据分析活动是探索性交互式的,Spark为这种探索性交互方式设计了Resilient Distributed Datasets(RDDs),对具有简单函数式编程接口的分布式数据集合的抽象。可以理解RDD就是分页在不同机器上的List,当遇到错误的时候,这些List能够被恢复。
lines=sc.textFile(“hdfs://....”)
points = lines.map(line => parsePoint(line))
points.filter(p => p.x>100).count()
如上面的Scala代码,RDD通常开始从HDFS文件系统读取文本文件开始,lines这个RDD由字符串组成,每个元素都对应着文本文件中的一行。调用map函数,可以将RDD转换成包含点元素的ponits集合。可以过滤这个集合并计算符合要求的点的数量。
总而言之:Spark是一个统一的大数据处理引擎,它有机的组合了批处理,交互式,流处理和图计算处理能力,并以RDD抽象为基础,提供了简洁的函数式编程API来支持交互式的探索性数据分析处理手段。
三、Spark的核心概念
1)Resilient Distributed Dataset (RDD)弹性分布数据集
RDD弹性分布式数据集是分布式的只读的且已分区的集合对象,是对分布式内存的抽象使用,实现了以操作本地集合的方式来操作分布式数据集的抽象实现。这些集合是弹性的,如果数据集的一部分丢失,则可以对它们进行重建。具有自动容错,位置感知调试和可伸缩性,而容错性最难实现的。大多数分布式数据集的容错性有两种方式:数据检查点和记录数据的更新,对于大规模数据分析系统,数据检查点操作成本很高,主要原因是大规模数据在服务器之间的传输会带来各方面的问题,相比记录数据的更新,RDD只支持粗粒度的轮换,也就是记录如何从其他RDD转换而来,以便恢复丢失的分区。RDD必须是可序列化的。RDD可以cache到内存 中,每次对RDD数据集的操作之后的结果,都可以存放到内存中,下一个操作可以直接从内存中输入,省去了MapReduce大量的磁盘IO操作。这对于迭代运算比较常见的机器学习算法, 交互式数据挖掘来说,效率提升比较大。
2)RDD编程接口
作为Spark的目标之一,Spark提供了丰富的API来操作这些数据集,RDD包含2类API。
Transformations——转换操作,这类操作的返回值还是一个RDD,常用的有map、filter、sort等,变形操作采用的是懒策略,如果只是将转换操作提交是不会提交任务来执行的。
Spark支持的转换操作可参考以下链接:Transformations
|
map(func) |
返回一个新的分布式数据集,由每个原元素经过func函数转换后组成 |
|
filter(func) |
返回一个新的数据集,由经过func函数后返回值为true的原元素组成 |
|
flatMap(func) |
类似于map,但是每一个输入元素,会被映射为0到多个输出元素(因此,func函数的返回值是一个Seq,而不是单一元素) |
|
sample(withReplacement, frac, seed) |
根据给定的随机种子seed,随机抽样出数量为frac的数据 |
|
union(otherDataset) |
返回一个新的数据集,由原数据集和参数联合而成 |
|
groupByKey([numTasks]) |
在一个由(K,V)对组成的数据集上调用,返回一个(K,Seq[V])对的数据集。注意:默认情况下,使用8个并行任务进行分组,你可以传入numTask可选参数,根据数据量设置不同数目的Task (groupByKey和filter结合,可以实现类似Hadoop中的Reduce功能) |
|
reduceByKey(func, [numTasks]) |
在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起。和groupbykey类似,任务的个数是可以通过第二个可选参数来配置的 |
|
join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)类型的数据集上调用,返回一个(K,(V,W))对,每个key中的所有元素都在一起的数据集 |
|
groupWith(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)类型的数据集上调用,返回一个数据集,组成元素为(K, Seq[V], Seq[W]) Tuples。这个操作在其它框架,称为CoGroup |
|
cartesian(otherDataset) |
笛卡尔积。但在数据集T和U上调用时,返回一个(T,U)对的数据集,所有元素交互进行笛卡尔积 |
|
sortByKey([ascendingOrder]) |
在类型为( K, V )的数据集上调用,返回以K为键进行排序的(K,V)对数据集。升序或者降序由boolean型的ascendingOrder参数决定 (类似于Hadoop的Map-Reduce中间阶段的Sort,按Key进行排序) |
Actions——动作操作,这类操作或者返回结果,或者将RDD存储起来,如count,save等等,当动作操作提交时,任务执行立即被触发。
Spark支持的动作操作可参考以下链接:Actions
|
reduce(func) |
通过函数func聚集数据集中的所有元素。Func函数接受2个参数,返回一个值。这个函数必须是关联性的,确保可以被正确的并发执行 |
|
collect() |
在Driver的程序中,以数组的形式,返回数据集的所有元素。这通常会在使用filter或者其它操作后,返回一个足够小的数据子集再使用,直接将整个RDD集Collect返回,很可能会让Driver程序OOM |
|
count() |
返回数据集的元素个数 |
|
take(n) |
返回一个数组,由数据集的前n个元素组成。注意,这个操作目前并非在多个节点上,并行执行,而是Driver程序所在机器,单机计算所有的元素 (Gateway的内存压力会增大,需要谨慎使用) |
|
first() |
返回数据集的第一个元素(类似于take(1)) |
|
saveAsTextFile(path) |
将数据集的元素,以textfile的形式,保存到本地文件系统,hdfs或者任何其它hadoop支持的文件系统。Spark将会调用每个元素的toString方法,并将它转换为文件中的一行文本 |
|
saveAsSequenceFile(path) |
将数据集的元素,以sequencefile的格式,保存到指定的目录下,本地系统,hdfs或者任何其它hadoop支持的文件系统。RDD的元素必须 由key-value对组成,并都实现了Hadoop的Writable接口,或隐式可以转换为Writable(Spark包括了基本类型的转换,例如 Int,Double,String等等) |
|
foreach(func) |
在数据集的每一个元素上,运行函数func。这通常用于更新一个累加器变量,或者和外部存储系统做交互 |
3)RDD依赖关系
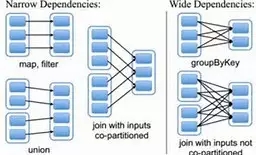
如上图,RDD之间有两种依赖:
窄依赖(Narrow Dependency)——一个父RDD最多被一个子RDD引用,如map,filter,union等等。
宽依赖(Wide Dependencies)——一个父RDD被多个子RDD引用,如groupByKey。
4)Stage DAG
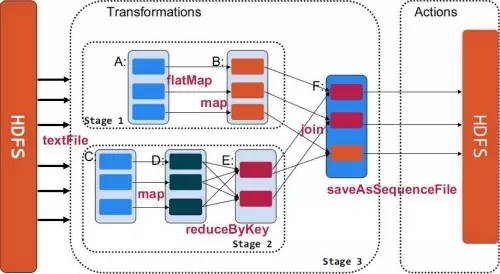
如图Spark提交Job之后会把Job生成多个Stage,多个Stage之间是有依赖的,如上面Stage3就依赖于Stage1和Stage2,Stage之间的依赖关系就构成了DAG(有向无环图)。Spark通常会将窄依赖的RDD转换放在同一个Stage中,而对于宽依赖,通常会发生Shuffle操作,Spark通常将Shuffle操作定义为stage的边界。
5)Spark运行模式
在了解RDD和DAG的基础下,我们来看看,Spark是如果对资源管理与作业调度来完成实际的分析任务。
Spark支持如下运行模式:
Local模式:单机运行环境,通常用于测试开发
伪分布模式:在单机环境下,模仿分布集群运行模式,也用于测试开发
集群模式:Spark支持多种集群管理器
1.Standalone模式,对于资源管理与作业调度由Spark集群来完成。
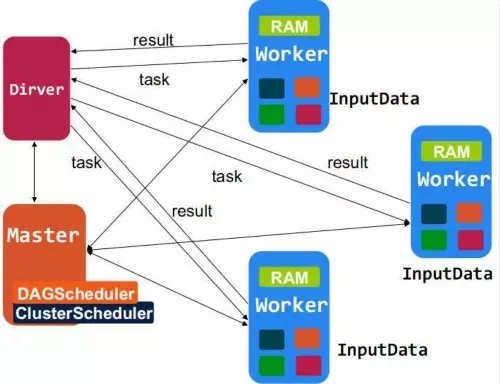
在这种模式下,Driver负责创建SparkContext来为应用的运行准备运行环境,SparkContext负责与集群管理器通信,进行资源的申请,任务的分配和监控等,在Worker节点上运行的Executor工作进程在完成分配的任务后,Driver同时负责将SparkContext关闭。通常用SparkContext代表Driver。
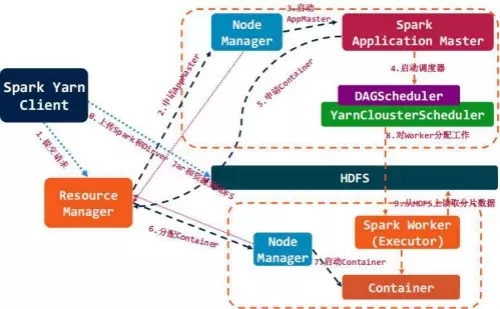
2. Spark on Yarn模式
Spark应用的资源与调度由Yarn来管理 ,Spark on Yarn遵循YARN的官方规范实现,得益于Spark天生支持多种Scheduler和Executor的良好设计,对YARN的支持也就非常容 易,Spark on Yarn的大致框架图。
3.Spark也可运行在Mesos集群管理器上
四、Spark的组件
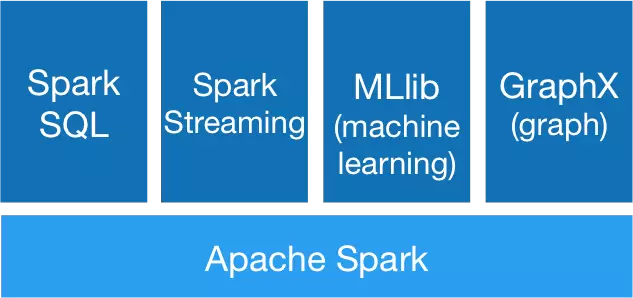
1)Spark SQL
Spark SQL是Spark用来处理结构化数据的模块,它提供了叫做DataFrames的编程抽象,也叫做分布式SQL查询引擎,这个概念在Spark1.5中引入。一个DataFrame就是一个由命名列组织的分布式数据集。它在概念上等同关系型数据库中表或者R/Python中的数据框。DataFrames能够由多种方式构建,例如:结构化数据文件,Hive中的表,外部数据库或者已有RDD。
DataFrame API支持Scala,Java,Python和R语言,下面是使用语言Scala操作DataFrame的简单实例。

2)Spark Streaming
Spark流程处理模块扩展了Spark的核心API来支持,可伸缩,高吞吐量,可容错的实时的流数据处理,数据可以从不同的来源注入,例如Kafka,Flume,Twitter,ZeroMQ,Kinesis或者TCP sockets. 可以对这些实时数据运用高级函数例如map,reduce,join结合窗口机制作一些复杂的数理运算,最终的处理结果可以推送到文件系统,数据库,实时仪表盘显示,也可使用Spark机器学习算法或者图计算处理引擎来处理这些实时数据。
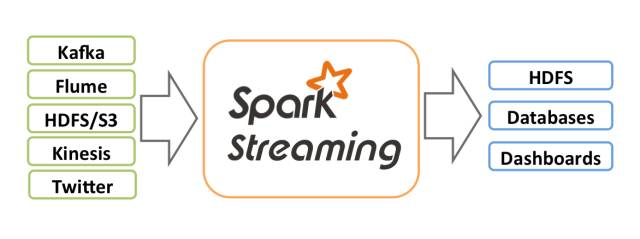
Spark的内部工作机制如下,Spark Stream接收到实时数据流,按照一定时间将数据流分隔成批,然后由Spark引擎依次处理这些批量数据来获取最终的结果。

Spark Streaming提供的高阶抽象叫做“离散流”或者DStream,它代表一个持续的数据流。Dstreams能够从Kafka,Flumea和Kinesis数据源创建或者从其它DStreams转换而来。在内部,DStream代表序列化RDDs。
流计算技术通常用来处理实时业务分析,例如实时日志收集和预警系统等等。
3)Machine Learning Library
MLlib是Spark的机器学习库,其目标使实际的机器学习运算简单和可伸缩。它由一些通用的学习算法和辅助类组成,包括分类、回归、聚类、协同过滤、降维等和一些底层的优化手段和API。
4)GraphX
GraphX是 Spark中用于图(e.g., Web-Graphs and Social Networks)和图并行计算(e.g., PageRank and Collaborative Filtering)的API,可以认为是GraphLab(C++)和Pregel(C++)在Spark(Scala)上的重写及优化,跟其他分布式 图计算框架相比,GraphX最大的贡献是,在Spark之上提供一栈式数据解决方案,可以方便且高效地完成图计算的一整套流水作业。
GraphX能过引入Graph抽象来扩展Spark RDD:由附有属性的点和边组成的有向多边形。GraphX提供了一些基本的图计算操作集(如:subgraph,joinVertices和aggregateMessages)和一个经过优化的Pregel API变体。GraphX所包含的图形算法还在持续的增加和构建以使对于图分析任务更简单。
图算法通常用来处理最短路径,社交网络分析等等,比较有名的图算法就是Google计算网页链接权重的PageRank。
五、结束语
Spark基于RDD的抽象,结合DAG,延迟计算等技术,尽可能充分利用内存迭代避免低效的磁盘读写,来提高运算速度,并以这个抽象为基础,将批处理,机器学习,流处理和图计算能多种工作负载有机的统一到其运算平台中,并且能够组合这些技术来进行复杂的分析任务,例如将流处理获得数据实时的分发的机器学习模块进行实时预测。其提供的高阶操作接口和各种便利的计算库,使得开发能够专注于自己的业务,使用它们快速的开发自己的应用。
通过上面的介绍,相信读者已经了解Spark的基本的了解,如果想进一步的学习Spark的知识,可以访问Big Data University,其中包含许多免费的MOOC、IBM也提供了Spark服务平台来免费试用。
再次感谢IBM资深软件工程师朱志辉老师,对DBA+社群活动给予的大力支持!
“DBA+社群”将陆续在各大城市群进行线上专题分享活动,以后每周一、周三晚上为【DBA+专业群】的固定时间,每周二、周四晚上为【DBA+各城市群】的固定时间,每周五晚上为【DAMS架构师精英群】的固定时间,欢迎大家积极加入我们。无论是内容还是形式,有好的建议我们都会积极采纳。
想入群的小伙伴们请关注DBA+社群微信公众号:dbaplus,回复“加群”即可。
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复002,看《灾备故障上了红头文件,容灾技术到底哪家强?》;
回复003,看吕海波的《去不去O,谁说了算?》;
回复004,看胡怡文《PG,一道横跨oltp到olap的梦想之桥》;
回复005,看付新《达梦专家解读:国产数据库也疯狂》;
回复006,看郭耀龙《假事务之名,深入研究UNDO与REDO》;
回复007,看宋日杰《Oracle后台专家解决library cache锁争用的终极武器》;
回复008,看周俊《被埋没的SQL优化利器——Oracle SQL monitor》。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721