VM - Single server - All in One 单点方式,提供 Docker image ,单点 VM 可以支撑 100 万 Data Points/s。
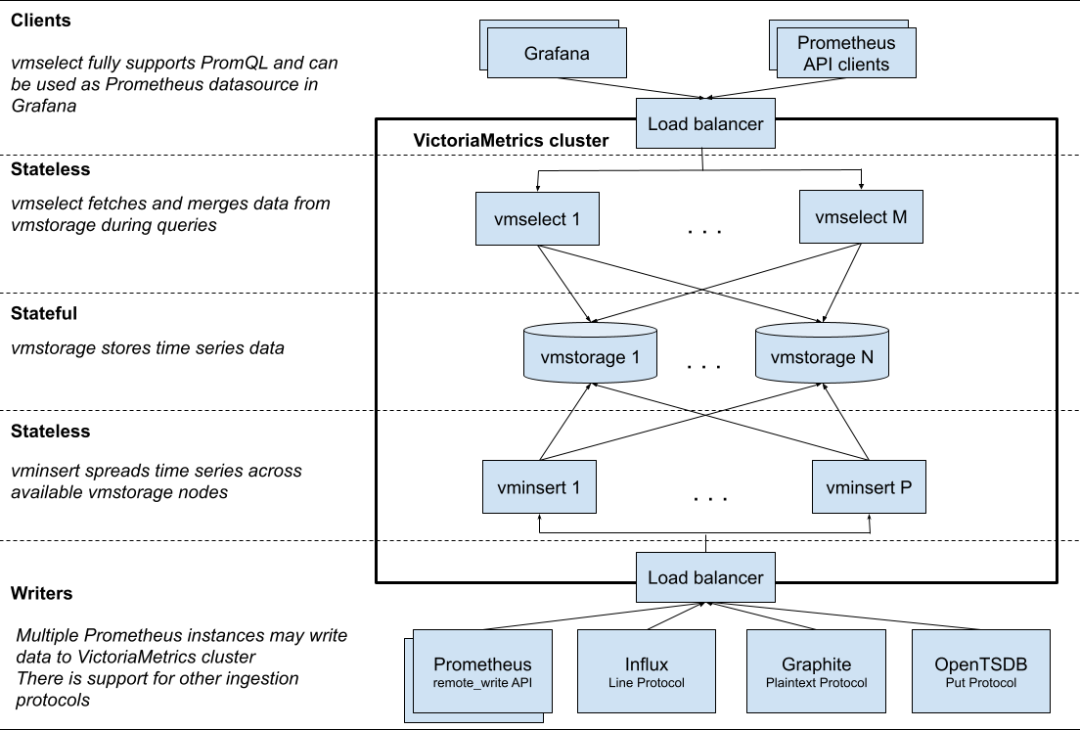
VM - Cluster - 集群版,拆分为了 vmselect、vminsert、vmstorage 3个服务,提供 Operate ,支持水平扩展;低于百万指标/s建议用单点方式,更易于安装使用和维护。
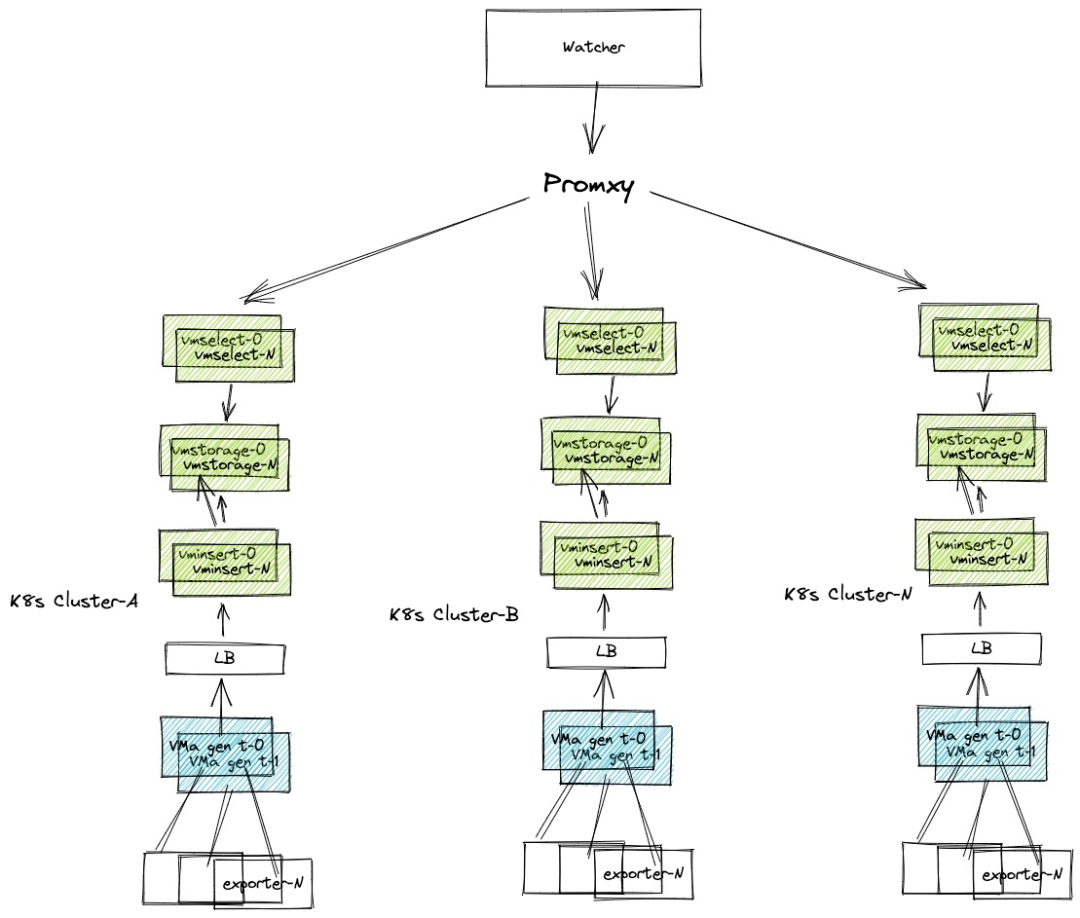
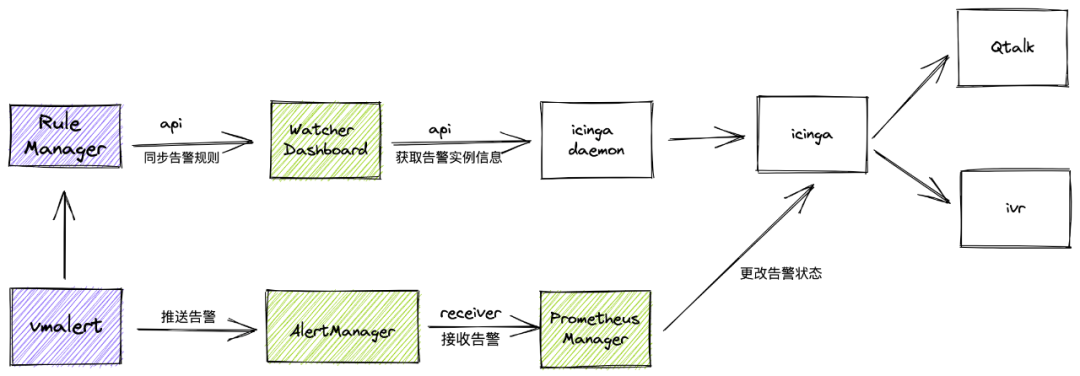
Qunar 单集群 Total Data points 17万亿,采用的是 VMCluster 方案。另外对于指标采集和告警,需要单独以下组件:可选,可按自身需求选择是否使用如下组件替代现有方案。如果只是将 VM 作为 Prometheus 的远程存储来使用的话,这两个组件可忽略,仅部署 VM - Single 或 VM - Cluster ,并在 Prometheus 配置 remoteWrite 指向 VM 地址即可。
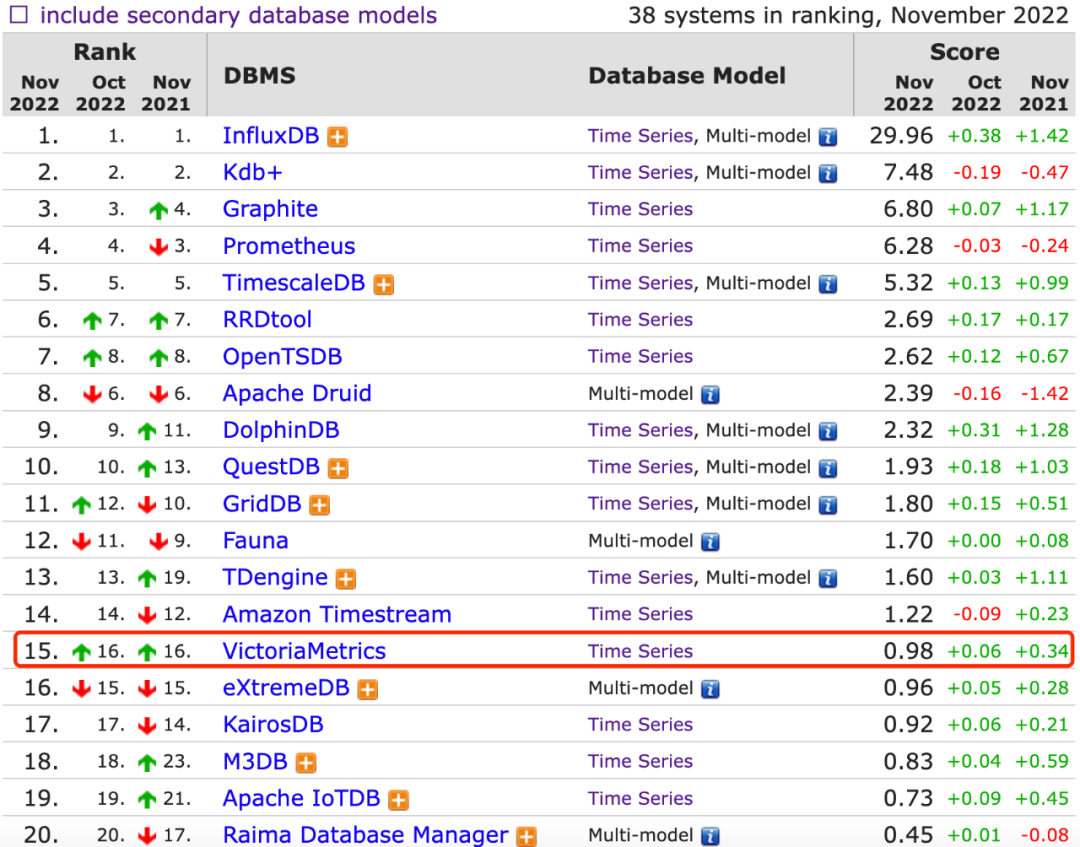
本文介绍了 Victoriametrics 的优势以及 Prometheus 不足之处,在 Qunar 替换掉的原因以及替换后的效果展示。也分享了 Qunar 对 VM 的使用方式和架构。使用 VM 替代 Prometheus 是个很好的选择,其它有类似需求的场景或组织也可以尝试 VM 。如果要用最直接的话来形容 VM ,可以称其为 Prometheus 企业版,Prometheus Plus 。最后,任何系统、架构都并非一劳永逸,都要随着场景、需求变化而变化;也并没有哪种系统、架构可以完全契合所有场景需求,都需要根据自身场景实际情况,本着实用至上的原则进行设计规划。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721