
不同于传统物理主机,每个容器相当于一个主机,导致一台物理主机上的系统指标数量成本增长,总的监控指标规模相当庞大(经线上统计,每node指标达到10000+)。
此外,为了避免重复造轮,需要最大限度的利用公司的监控报警系统,需要把k8s的监控和报警融入其中。在小米现有的基础设施之上,落地该监控,是一个不小的挑战。
一、当监控遇上K8S
为了更方便的管理容器,k8s对Container进行了封装,拥有了Pod、Deployment、Namespace、Service等众多概念。与传统集群相比,k8s集群监控更加复杂:
监控维度更多,除了传统物理集群的监控,还包括核心服务监控(API server,Etcd等)、容器监控、Pod监控、Namespace监控等;
监控对象动态可变,在集群中容器的销毁创建十分频繁,无法提前预置;
监控指标随着容器规模爆炸式增长,如何处理及展示大量监控数据;
随着集群动态增长,监控系统必须具备动态扩缩的能力。
除了k8s集群监控本身的特性外,具体监控方案的实现要考虑公司内部的实际情况。
目前弹性调度计算平台提供的k8s集群包括:
融合云容器集群;
部分Ocean集群以及CloudML集群;
拥有十余个集群;
1000+机器。
不同k8s集群的部署方式,网络模式,存储方式等不尽相同,监控方案需要兼顾各种差异。
Open-Falcon是公司内通用的监控报警系统,有完善的数据收集,展示和报警机制,但是Open-Falcon并不支持k8s这种采集方案。
此外,k8s里的各种资源,有天然的层次关系,这就决定了监控数据的整合需要强大而灵活的聚合能力,Falcon在这些方面不太能满足需求。
但我们并不想重复造轮子,需要最大限度利用公司既有基础设施,从而节约开发和运维成本。
对于监控的持久化存储,如何结合公司内的数据库,实现监控数据的长期存储,都是需要考虑的问题。
现有业界针对k8s监控也有一些成熟的方案:
1)Heapster/Metrics-Server+ InfluxDB + Grafana
Heapster是k8s原生的集群监控方案(现已废弃,转向Metrics-Server),从节点上的cAdvisor获取计算、存储、网络等监控数据,然后将这些数据输出到外部存储(Backend),如InfluxDB,最后再通过相应的UI界面进行可视化展示,如Grafana。
此方案部署简单,但采集数据单一,不合适k8s集群整体监控,只适用于监控集群中各容器的资源信息,如作为k8s dashboard的数据展示源。
2)Exporter+Prometheus+Adapter
Prometheus是一套开源的系统监控报警框架,具有多维数据模型、灵活强大的查询语句、性能良好等特点。
Prometheus可以通过各种exporter,如node-exporter、kube-state-metrics、cadivsor等采集监控Metrics监控数据,此外Prometheus可以动态发现k8s集群中的pod,node等对象。
通过Prometheus采集各个维度的数据,进行聚合并提供报警,然后利用Adapter可以将数据写到远程储存中(如OpenTSDB,InfluxDB)等实现持久化存储。
但由于数据采集可能会有丢失,所以Prometheus不适用于对采集数据要 100% 准确的情形,例如实时监控等。
二、监控方案及演进
前期,为了尽快实现k8s的落地,监控系统借助Falcon还有内部开发的Exporter,仅实现了对于核心监控数据的采集,如Pod的CPU,内存,网络等资源使用情况,具体架构如下图所示:
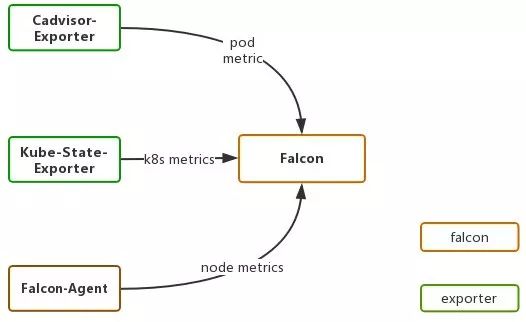
通过实现cAdvisor-exporter采集cAdvisor的容器监控数据;kube-state-exporter采集k8s关键Pod指标;Falcon-agent采集物理节点数据。
初始方案仅采集了核心监控数据,初步实现对核心资源使用情况的监控,缺乏更全面的数据监控,例如API Server,Etcd等。
由于Falcon目前不支持对于容器的监控,所以需要手动实现各种exporter来满足k8s的监控需求。而且监控数据没有实现持久化存储,不支持长期查询。
由于初始监控系统的不足,经过调研对比最终选用Prometheus作为k8s的监控方案,主要考虑一下几点原因:
原生支持k8s监控,具有k8s对象服务发现能力,而且k8s的核心组件提供了Prometheus的采集接口;
强大的性能,单个Prometheus可以每秒抓取10万的Metrics,可以满足一定规模下k8s集群的监控需求;
良好的查询能力:Prometheus 提供有数据查询语言 PromQL。PromQL 提供了大量的数据计算函数,大部分情况下用户都可以直接通过 PromQL 从 Prometheus 里查询到需要的聚合数据。
基于Prometheus的k8s监控系统的架构如下图所示:
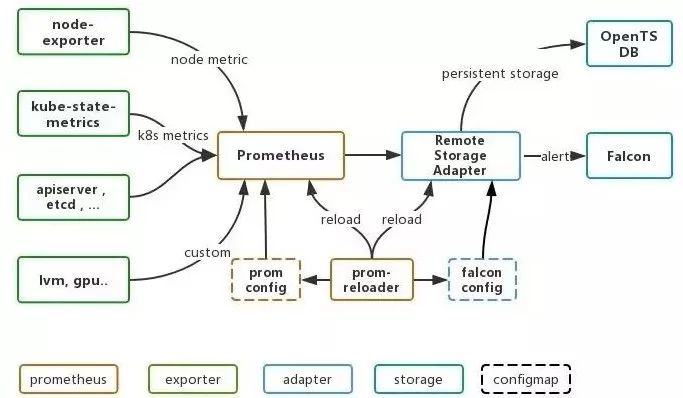
1)数据源
node-exporter采集物理节点指标;
kube-state-metrics采集k8s相关指标,包括资源使用情况,以及各种对象的状态信息;
cAdvisor采集容器相关指标;
API Server, Etcd, Scheduler, k8s-lvm,GPU等核心组件的监控数据;
其他自定义Metrics,通过在Pod YAML文件Annotations添加 prometheus.io/scrape: "true" 可实现自动抓取提供的Metrics。
2)Prometheus数据处理模块
Prometheus以Pod方式部署在k8s上,Pod中含有Prometheus、Prom-Reloader。
Prometheus负责采集聚合数据;
prom-config为监控的聚合规则与抓取配置,以ConfigMap存储;
Prom-Reloader实现监控配置的热更新,实时监控配置文件,无需重启应用即可动态加载最新配置。
3)存储后端
Falcon与OpenTSDB。
Open-Falcon是公司统一的监控报警系统,提供了完善的数据采集、报警、展示、历史数据存储功能以及权限功能。
由于Falcon设计较早,没有对于容器相关指标提供监控,而Prometheus原生支持了k8s,但是其报警功能只能静态配置且需要实现与公司相关账号打通以方便用户配置监控,且有些k8s的指标,需要暴露给容器用户。
基于此考虑,我们使用Falcon作为k8s监控的报警和对外展示平台。通过实现Falcon-Adapter,将监控数据转发到Falcon以实现报警与展示。
根据k8s服务对象将监控目标分为多个层次:Cluster,node,namespace,Deployment,Pod,将关键报警指标通过Falcon-Agent打到Falcon,用户可自行在配置报警查看指标。
原生Prometheus的监控数据放在本地(使用TSDB时区数据库),默认保存15天数据。监控数据不止用于监控与报警,后续的运营分析和精细化运维都需要以这些运营数据作为基础,因此需要数据的持久化。
在Prometheus社区中也提供了部分读写方案,如Influxdb、Graphite、OpenTSDB等。而小米正好有OpenTSDB团队,OpenTSDB将时序数据存储在HBase中,我们公司的HBase也有稳定的团队支持。
基于此通过OpenTSDB为监控数据提供远程存储。实现了OpenTSDB-Adapter,将监控数据转发到时序数据库OpenTSDB以实现数据的持久存储,满足长期查询以及后期数据分析的需要。
4)部署方式
系统监控的核心系统全部通过Deployment/Daemonset形式部署在k8s集群中,以保证监控服务的可靠性。全部配置文件使用ConfigMap存储并实现了自动更新。
5)存储方式
Prometheus的存储包括本地存储与远程存储,本地存储只保存短期内的监控数据,按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中,每一个块中包含该时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。
由于各集群提供存储类型的不行,目前已经实现多种存储方式的部署包括pvc、lvm、本地磁盘等。
远程存储通过实现prometheus的远程读写接口实现对OpenTSDB的操作,方便对于长期数据的查询。
为了保持Prometheus的简单性,Prometheus并没有尝试在自身中解决以上问题,而是通过定义两个标准接口(remote_write/remote_read),让用户可以基于这两个接口对接将数据保存到任意第三方的存储服务中,这种方式在Promthues中称为Remote Storage。

如上图所示,可以在Prometheus配置文件中指定Remote Write(远程写)的URL地址,一旦设置了该配置项,Prometheus将采集到的样本数据通过HTTP的形式发送给适配器(Adapter)。
而用户则可以在适配器中对接外部任意的服务。外部服务可以是真正的存储系统,公有云的存储服务,也可以是消息队列等任意形式。
同样地,Promthues的Remote Read(远程读)也通过了一个适配器实现。在远程读的流程当中,当用户发起查询请求后,Promthues将向remote_read中配置的URL发起查询请求(matchers,time ranges),Adapter根据请求条件从第三方存储服务中获取响应的数据。同时将数据转换为Promthues的原始样本数据返回给Prometheus Server。
当获取到样本数据后,Promthues在本地使用PromQL对样本数据进行二次处理。启用远程读设置后,只在数据查询时有效,对于规则文件的处理,以及Metadata API的处理都只基于Prometheus本地存储完成。
远程存储现已支持公司内部的Falcon与OpenTSDB,通过Falcon方便用户查看监控数据以及配置报警。写到OpenTSDB已实现持久化存储,并且支持通过Prometheus对其进行远程读写。
目前基于Prometheus的监控方案已在各集群部署,但随着集群规模的增长逐渐暴露出一些问题。
其一,是随着容器增长监控指标激增,对Falcon-agent与transfer造成一定压力,致使经常造成Falcon-agent拥堵以及部分监控数据延迟、丢失等问题。
在线上测试当通过单个Falcon-agent发送超过150000/m时,经常性出现数据丢失,现已关闭部分监控数据的发送。根本原因是prometheuse集中的数据聚合和推送,把分散在各集群的指标汇聚到了一台主机,从而带来了超常的压力。
其二,是在规模较大的集群,Prometheus占用CPU与内存资源都较多(下表中为线上集群Prometheus的运行情况),偶尔会出现某些metrics抓取不到的情况,随着集群规模的扩大单个Prometheus将会遇到性能瓶颈。

针对单个Prometheus监控方案的不足,需要对其进行扩展已满足大规模k8s集群监控,并适配Falcon系统agent的性能。
通过调研,发现Prometheus支持集群联邦。这种分区的方式增加了Prometheus自身的可扩展性,同时,也可以分散对单个Falcon agent的压力。
联邦功能是一个特殊的查询接口,允许一个Prometheus抓取另一个Prometheus的Metrics,已实现分区的目的。如下所示:

常见分区两种方式:
其一是功能分区,联邦集群的特性可以帮助用户根据不同的监控规模对Promthues部署架构进行调整,可以在各个数据中心中部署多个Prometheus Server实例。
每一个Prometheus Server实例只负责采集当前数据中心中的一部分任务(Job),例如可以将不同的监控任务分配到不同的Prometheus实例当中,再由中心Prometheus实例进行聚合。
其二是水平扩展,极端情况下,单个采集任务的Target数也变得非常巨大。这时简单通过联邦集群进行功能分区,Prometheus Server也无法有效处理时。
这种情况只能考虑继续在实例级别进行功能划分。将同一任务的不同实例的监控数据采集任务划分到不同的Prometheus实例。通过relabel设置,我们可以确保当前Prometheus Server只收集当前采集任务的一部分实例的监控指标。
针对k8s的实际情况,分区方案架构如下:
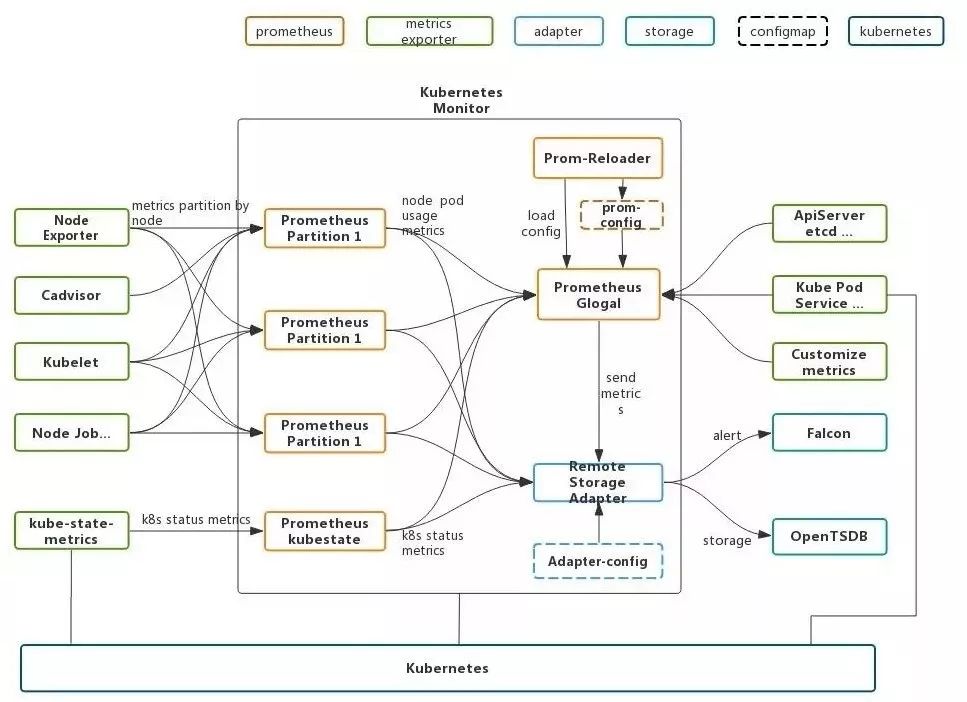
Prometheus分区包括master Prometheus 与 slave Prometheus以及 kube state Prometheus。
由于大量指标的采集来源于node上的服务,如kubelet, node-exporter, cadvisor等是以node为单位采集的,所以按照node节点来划分不同job,slave Prometheus 按照node切片采集node,pod级别数据。
kube-state-metrics暂时无法切片,单独作为一个kube-state Prometheus,供master Prometheus采集。其他Etcd,API Server,自定义指标等可通过master Prometheus直接采集。
Prometheus master对于其他Prometheus slave的抓取可通过如下配置:
- job_name: federate-slave
honor_labels: truemetrics_path: '/federate'params:'match[]':- '{__name__=~"pod:.*|node:.*"}'kubernetes_sd_configs:- role: podnamespaces:names:- kube-systemrelabel_configs:- source_labels:- __meta_kubernetes_pod_label_appaction: keepregex: prometheus-slave.*
Prometheus slave的对于抓取任务的分区通过Prometheus提供的hashmod方法来实现:
- job_name: kubeletscheme: httpskubernetes_sd_configs:- role: nodenamespaces:names: []tls_config:insecure_skip_verify: truerelabel_configs:- source_labels: []regex: __meta_kubernetes_node_label_(.+)replacement: "$1"action: labelmap- source_labels: [__meta_kubernetes_node_label_kubernetes_io_hostname]modulus: ${modulus}target_label: __tmp_hashaction: hashmod- source_labels: [__tmp_hash]regex: ${slaveId}action: keep
master Prometheus 与 kube-state Prometheus通过deployment部署。
slave Prometheus可有多个pod,但由于每个pod的配置不同(配置中的${slaveId}不同),每个slave prometheus需要在配置中体现分区编号,而原生的deployment/statefulset/daemonset都不支持同一Pod模板挂载不同的ConfigMap配置。
为了方便管理Slave Prometheus通过statefulset来部署slave,由于statefulset会将每个pod按顺利编号如slave-0,slave-1等。通过Prom-Reloader获得到Pod名称,持续监听Prometheus配置变化,然后生成带有编号的配置以区分不同的分区模块。
测试包括两方面,一是针对分区后的监控方案进行功能测试是否符合预期,二是对于其性能进行测试。
在功能测试中,验证分区方案的聚合规则正常,特别对于分区前后的数据进行校验,通过对一周内的数据进行对比,取一小时内平均的差值比率,如下图:
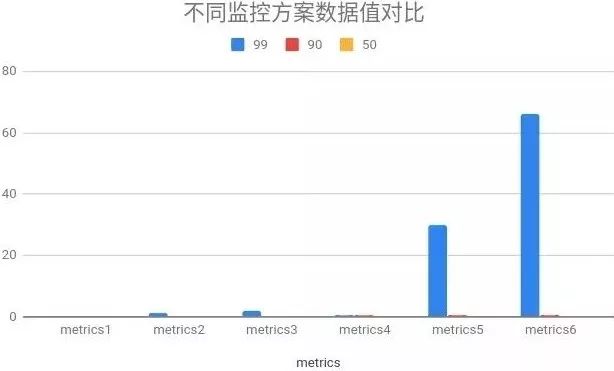
经统计,超过95%的时间序列对比误差在1%以内,个别指标瞬时波动较大(如网络使用率),但随着时间增加会抵消差异。
在性能测试中,针对不同分区监控不同负载下进行测试,验证其性能状况。在测试集群上创建1000个虚拟node,创建不同数量Pod测试Prometheus分区性能:

对于Prometheus master与Prometheus kube-state在1分钟抓取时间内最多可支持8w pod,主要瓶颈在于kube-state-metrics随着pod增加,数据量激增,一次抓取耗时不断增长。
对于Prometheus slave由于采集部分数据,压力较小,单个Prometheus可抓取超过400个节点(60 pod/node)。如下图所示在开启remote write后抓取时间不断增加,后续将不断增加Remote-Storage-Adapter的性能。
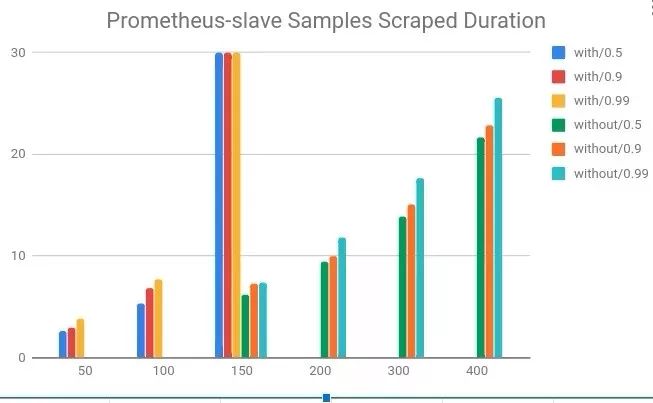
经过在k8s测试集群验证,Prometheus分区监控架构最多支持8w的pod,可以满足预期集群增长需求。
三、展望
目前分区监控方案已在部分集群部署,具有高可用、持久存储、可动态调整等特点。
另外,我们未来将持续改进:
实现监控的自动扩容,针对kube-state-metrics的性能优化(目前不支持分区);
在部署方式上,借助prometheus-operator与helm等实现更简洁的配置管理与部署;
在监控数据的利用上,可以应用特定算法对数据进行深度挖掘以提供有价值的信息,如利用监控数据提供扩容预测,寻找合适的扩容时机。
通过不断优化,以确保更好地为k8s提供稳定可靠智能的监控服务。
作者:郭如意
来源:小米云技术(ID:mi-cloud-tech)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721