
360运维开发团队,作为一支技术导向型团队,为HULK云平台在容器化、微服务、AIOPS、自动化运维等领域积累了丰富经验。更多技术好文欢迎访问团队技术博客:www.opsdev.cn。
背景
在私有云环境下,对于业务线所使用的计算和存储资源介质可能会出现老化、迁移等问题需要进行退还处理。但随着业务数和机器数的增多,退还机器的数量也随之增大。然而并不可能将业务中的所有机器全部退还,有效的机器退还不仅能够节约成本,也能提高业务的稳定性与效率。因此需要设计一个算法,用于判断机器是否需要退还。
这个问题很容易把它想象成一个机器的分类问题,即设计一个分类器用于判断机器是否需要退还。实际上,该问题不仅仅可以用分类的方法进行解决,也可以设计一个推荐系统,为用户(即业务)推荐最应该退还的机器。
面临挑战
为退还机器设计推荐系统时,将业务作为用户,机器作为物品。但是分析数据时发现,一台机器一般只属于一个业务,不会属于另一个业务,即一件物品只属于一个用户,它只能被一个用户所得,其他用户无法得到;此外,一个业务所有的机器是特定的,推荐时只能推荐业务现有的机器作为退还机器。
上述两个问题使得退还机器推荐与传统的音乐、电影,或者物品推荐有很大的区别,不能直接运用现有算法解决,需要自行构造共享物品,进行推荐。
考虑到上述问题,本文提出基于K-Means聚类和ItemCF算法的推荐方法,从而解决了退还机器的推荐问题。
方法研究
本章节一共分为两个部分:K-Means聚类和ItemCF算法,下面将详细介绍:
由于一台机器一般只属于一个业务,不会属于另一个业务,所以机器是业务独有的,而不是共享物品。因此可以利用聚类分析的方法,将现有的机器分为几类,则这几类机器就是所有用户共享的了。
进行推荐时,首先进行机器类别的推荐,每个类别都有一个推荐分数,分数越高,则退还机器越容易出现在该类别中。其次,针对目标业务所拥有的机器进行推荐,此时计算每个现有机器与该业务已经退还的机器的平均形似度,平均相似度越高,则代表该机器越容易退还。综合上述两步,可以得到每个机器的最终的推荐分数,再按照该分数进行排序,从而得到目标业务具体的推荐机器。
本文中对于机器的聚类,选择的是:CPU空闲率等5个特征。K-Means聚类在Python中有现有的算法包,只需要调用即可,具体如下:
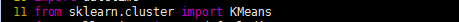
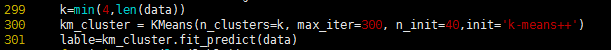
本文经过实验发现聚类时K值的选择对最终的结果影响不大,但是经过分析可知,K取值应当适中,过大或者过小都不好。过小则无法分类,推荐误差比较大;过大则会出现某些业务中有很多机器类别都没有机器的现象。综合考虑上述情况,最终K值取为4。
ItemCF算法是协同过滤算法中比较经典的一种算法,该方法基于物品的相似度对用户进行物品推荐。在推荐时主要考虑了一下两个假设:
兴趣相近的用户可能会对同样的东西感兴趣;
用户可能较偏爱与其已购买的东西相类似的商品。
也就是说考虑进了用户的历史习惯,对象客观上不一定相似,但由于人的行为可以认为其主观上是相似的,就可以产生推荐了。
ItemCF算法的关键步骤:
计算物品之间的相似度
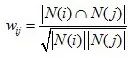
其中N(i)是喜欢物品i的用户的集合。
根据物品的相似度和用户的历史行为给用户生成推荐列表
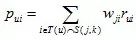
其中p_ui是用户u对物品i的喜好程度,T(u)是用户u曾经偏好的物品的集合, S(j,k)是和物品j最相似的k个物品的集合,r_ui用户u对物品i的兴趣。
对于隐反馈数据集,如果用户u对物品i有过行为则r_ui=1,本推荐中是业务u对机器类别i曾经退还过的机器个数。ItemCF算法在Python中没有算法包,需要自行实现。
总结
本文利用K-Means聚类和ItemCF算法进行了退还机器的推荐,现在推荐精度为79%左右,但是需要主业务中至少有2个子业务,但是实际操作中有很多业务不满足条件,所以不能进行推荐。而且推荐精度也不够高,也能使算法比较粗糙,也可能是机器的特征选择不够好,还需进一步优化。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721