
作者介绍
黄浩,现任职于中国惠普,从业十年,始终专注于SQL。十年一剑,十年磨砺。3年通信行业,写就近3万条SQL;5年制造行业,遨游在ETL的浪潮;2年性能优化,厚积薄发自成一家。
在生活中,很多时候我们会有这样的体悟:问题要么不出,一旦出现,会像多诺米骨牌一样,会连锁引发诸多相关问题,让我们疲于应付。SQL优化也是如此,那厢,因一个视图代码变更引发的性能事件(参见案例:《SQL Hint都无法解救DB性能时,如何通过视图曲线救国?》)还恍若昨日,余尘未落;这厢,与该视图相关的首页加载的性能问题又甚嚣尘上杀伐四起。
就在距离上次视图优化一个星期的时间,一封“红色”的邮件中的“SQL优化”项格外醒目:
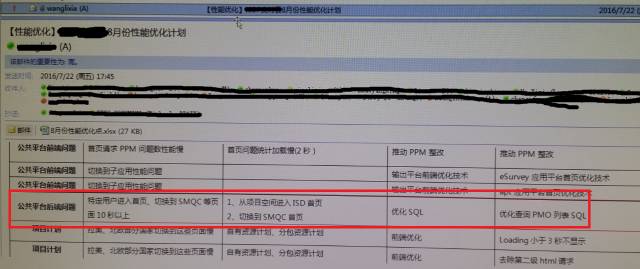
唯一值得庆幸的是,该性能问题被放在8月版本计划里面:时间还是蛮充裕的。于是我按照自己的节奏展开分析。
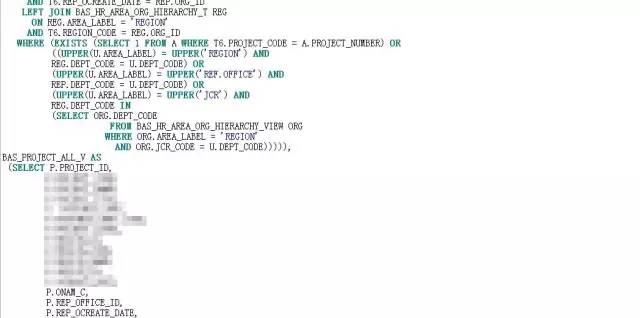
我找到开发责任人,拿到了SQL:

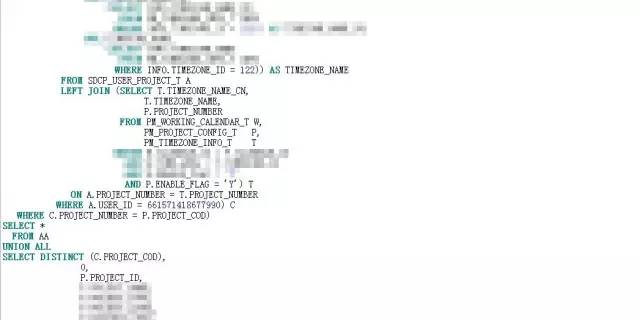

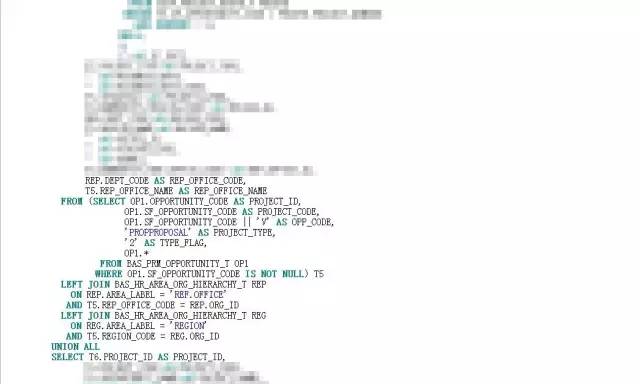
初一看,122行,不算长,也不短。但是我对SQL中出现的视图对象BAS_PROJECT_ALL_V产生了很大的兴趣。这个视图刚刚完成优化,怎么就又出现了性能问题了呢?看了下执行计划:
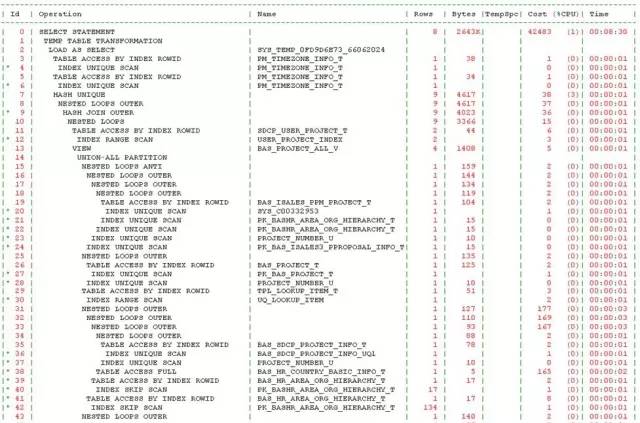
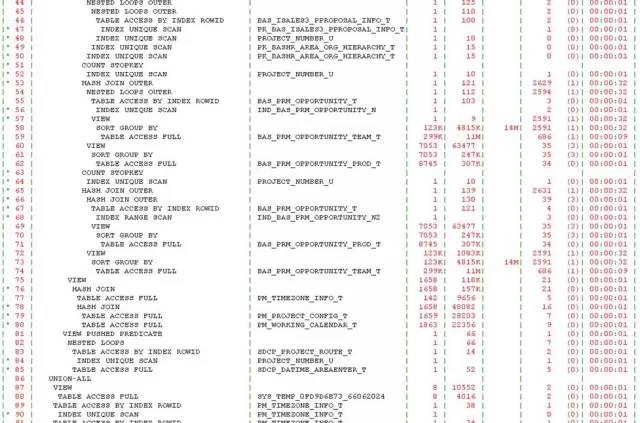
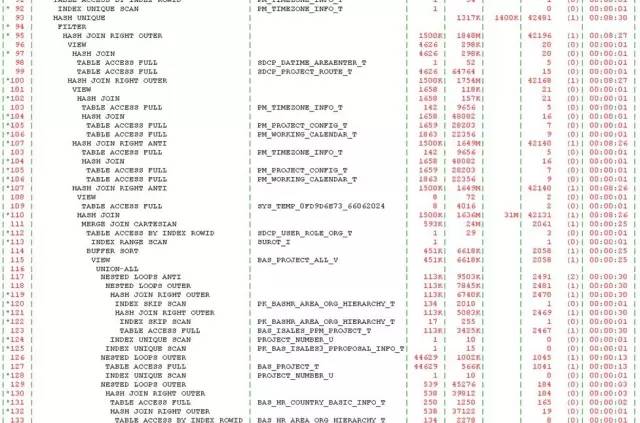
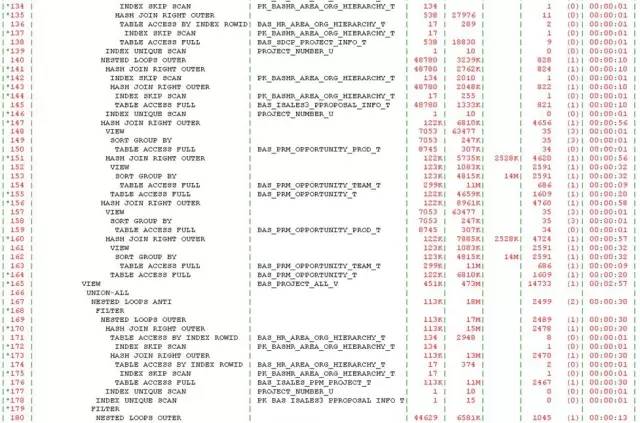


自上而下,体型虽然婀娜妙曼,但是“妙曼”得有些让人眩晕。这都要归功于视图对象BAS_PROJECT_ALL_V,该视图有5个union all,而在该SQL中,又被访问了3次。记得上次案例是由于谓词没有被推入引发的,而看执行计划,视图被访问三次,都没有做谓词推入,我就试着强制谓词推入看看效果,但是即便是谓词推入,问题依旧。因临近下班,也就没有深入分析,计划第二天再看看,反正离8月版本还有3周的时间。
第二天一过来,因为有来自其他同事的性能问题,我暂时将昨天的性能问题搁在一旁。大概在11点钟的时候,托盘上的espace弹出了消息,发消息的是昨天提供SQL的同事,内容是:昨天的那个性能问题必须要在今天内完成优化。这个消息着实把我“震”住了,不是说好的是8月版本吗?友谊的小船咋说翻就翻呢?
原来,同样的性能问题在生产环境也出现了,而且生产用户直接提了一个BUG单,用户很生气,后果很严重。从测试人员到生产用户,从UAT到生产,从邮件到BUG单,事态的严重程度已完全超出了当下深圳高温天气的黄色预警级别,以至于我立马放下手头的工作,顶着烈烈炎日,大汗淋淋的赶往“事发现场”—开发责任人所在ODC。
因为越是时间紧迫,沟通就越显得紧要,何况昨天初步“目测”,一方面执行计划过于复杂,而代码逻辑似乎又并不简单,因此更需要当面沟通。
根据开发人员的描述,这个功能的业务需求很简单,如下:
根据登录用户ID,获取该用户对应的所有项目列表,用户的项目列表包含两部分:其一是分配至该用户下的项目列表,其二是该用户所在区域的所有初始化过的项目,如下图所示:
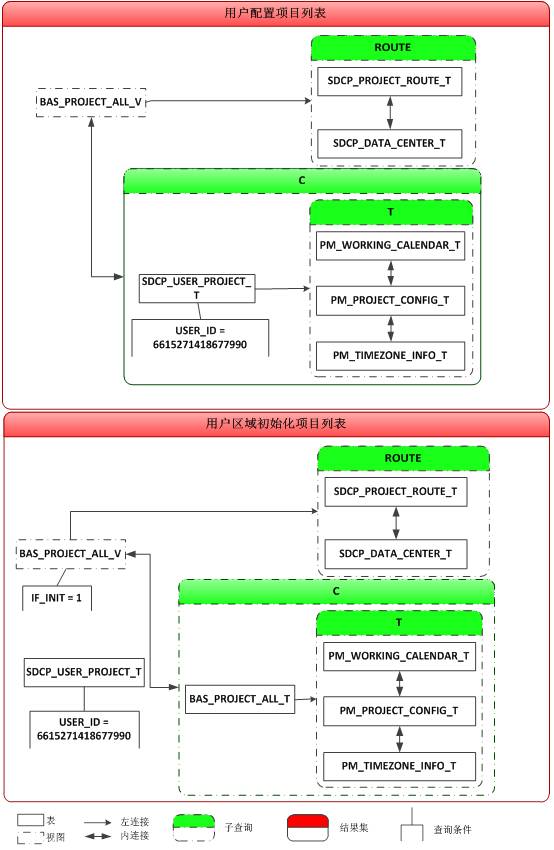
在了解到业务需求后,我开始解读SQL,在解读的过程中不时的向开发人员请教、交流。约莫半小时后,SQL的逻辑框架也逐渐明朗起来,如下:
从逻辑示意图中,我们至少有如下两个疑问:
子查询route及T在配置项目列表和区域项目列表中都出现了,是否可以进行合并?
在“用户区域初始化项目列表”中,表SUROT_T与其他结果集没有任何关联条件,只有UID_C的过滤条件,这意味着会发生笛卡尔积。
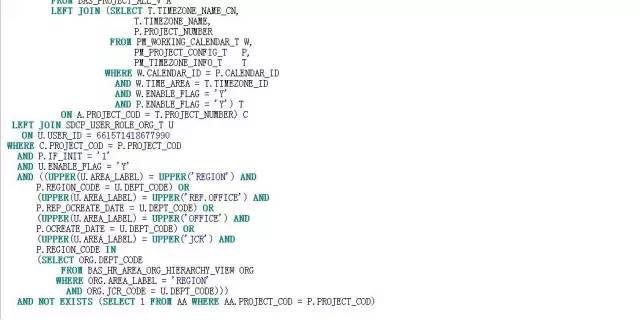
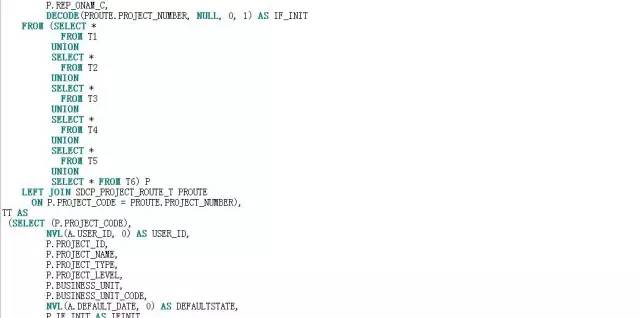
了解完业务逻辑及SQL代码逻辑结构后,我们不能绕过视图BAS_PROJECT_ALL_V,且看该视图的代码逻辑:
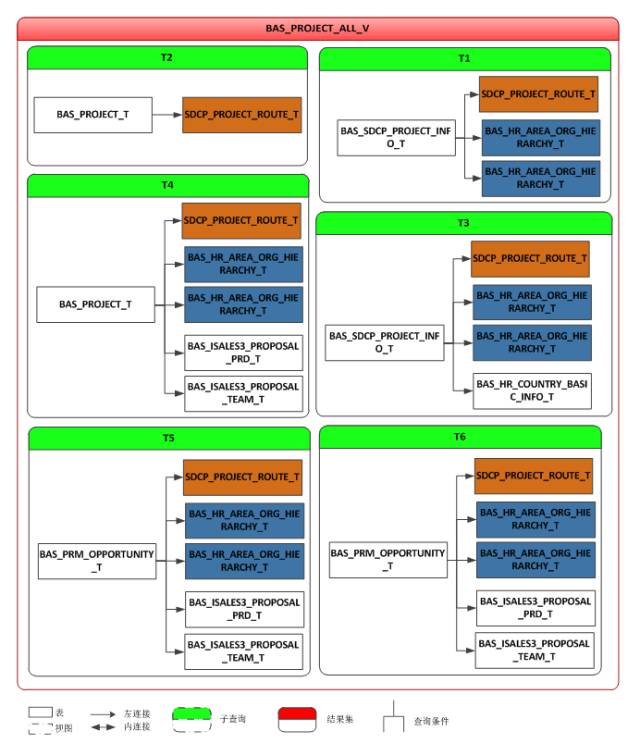
单从视图的数据逻辑看,存在以下问题:
表重复访问,图中黄色底纹和蓝色底纹的表对象都是重复访问;
除了T2结果集外,其他结果集都都访问了三个以上的表对象,模式都是一样的:以主表LEFT JOIN从表。众所周知,LEFT JOIN在SQL中的功能是获取字段,并没有过滤数据的作用。从LEFT JOIN的这些表获取的字段是否被外层的SQL访问了呢?如果没有被访问,那就意味着,就本案例的SQL而言,这些LEFT JOIN是多余的。
带着上述分析后的问题,我深入分析了代码,确认了如下信息:
SQL中的部分代码是可以精简的,比如子查询ROUTE及T只是为了获取属性字段,完全可以在得到了所需的PN_C清单后,再与子查询ROUTE及T关联获取。
视图的代码也可以精简,比如在视图T5结果集中访问BPOPT_T表对象获取的字段,在SQL中根本没有访问,也就是说在T5结果集中完全可以不访问该表对象。
那么还有个问题,那就是笛卡尔积。而通过分析代码,发现并非没有关联条件,而是将关联条件写到了where过滤位置了,如下:
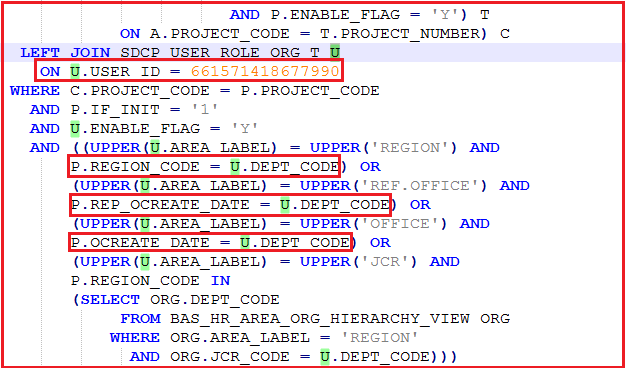
基于该逻辑的复杂性,我决定将该过滤条件改写成EXISTS子查询。
业务需求了解了,大致的逻辑框架也清楚了,病症病因也定位了,接下来就是该大刀阔斧的进行SQL改写了,改写的过程就很简单了,改写后的SQL:
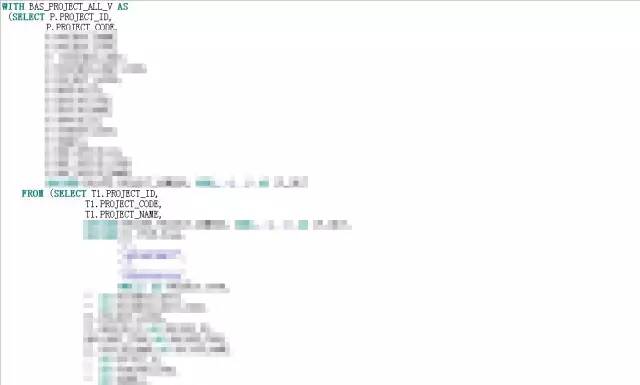

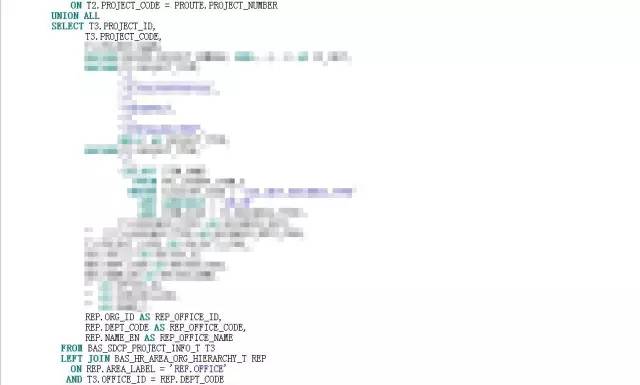


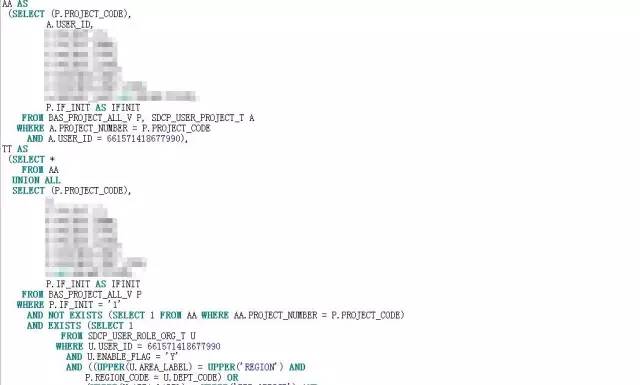
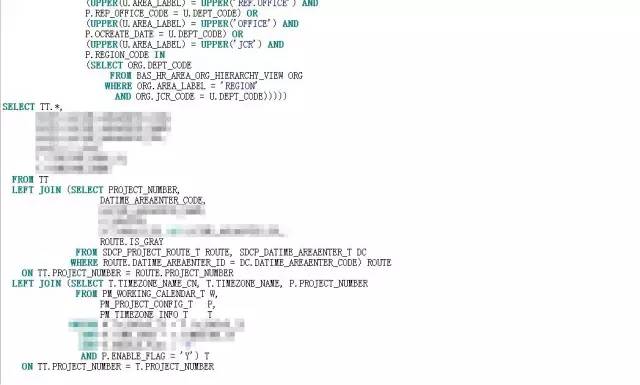
改动点如下:
取消视图BAS_PROJECT_ALL_V,用WITH 子查询替代视图。在with子查询中,根据需求关联表对象,砍掉了无关的表对象;
在获取区域项目列表的代码里,将LEFT JOIN WHERE改成EXISTS;
在获取了所有的项目列表后,再关联子查询ROUTE和T,获取项目相关属性信息。
修改后的执行计划如下:



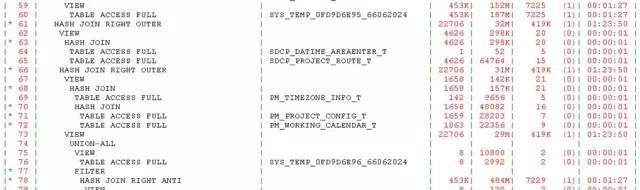


在PL SQL DEV中执行,2.5S左右,看来SQL改写还是收到了成效,我也长长的舒了口气,看窗外,已是夕阳西下,一抹余晖透过玻璃窗投射进来,此刻在呼呼空调室内,丝丝暖意,却全然忘记早上发布的高温黄色预警,虽然已近黄昏,窗外依旧炙热。
第二天,正当我准备整理本次优化案例时,ESPACE弹出了消息,是开发人员发过来的。消息的内容让我立马停止了整理。因为开发人员告诉我,2.5S仍然不能满足需求,需要控制在2S内。此时此刻我的心情有些忐忑:根据经验,这0.5S的性能提升,其难度远比从10S优化到3S要大。
为了这0.5S,我又重新审视了昨天的优化方案。可以说昨天的优化方案已经对之前的代码结构做了很大程度的解构,但是更多的是“精简”SQL。在数据处理流程上还没有变化,优化前后的数据流程都是先集合再过滤,逻辑图如下:
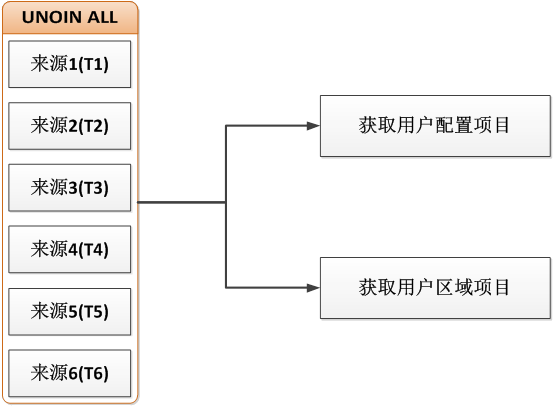
再看下执行计划:

发现在UNION ALL六个来源的WITH子查询时,产生了31M的IO写操作,数据量达到了163K,而SQL最终返回的结果集不到1000条。此时,我看到了希望的曙光。我将数据处理流程方案做了优化,如下图所示:
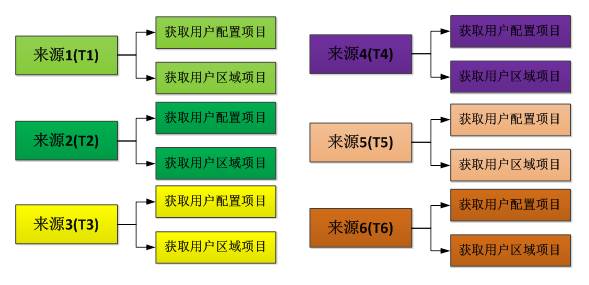
也就是说,将之前合而治之变更成了分而治之,在原理上显然是等价的。
根据分而治之的方案,改写后的SQL见附件:
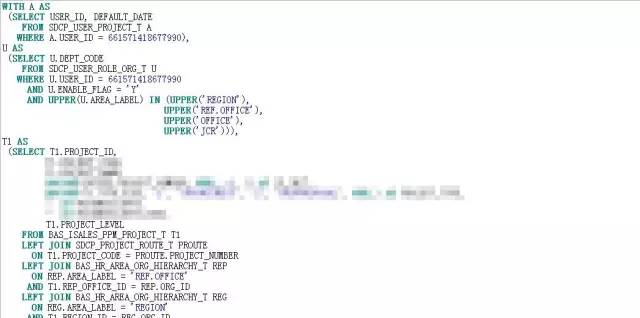
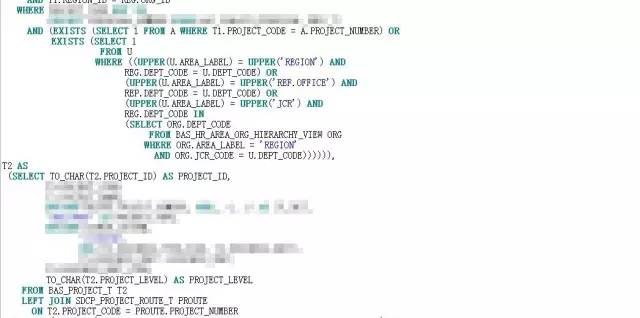
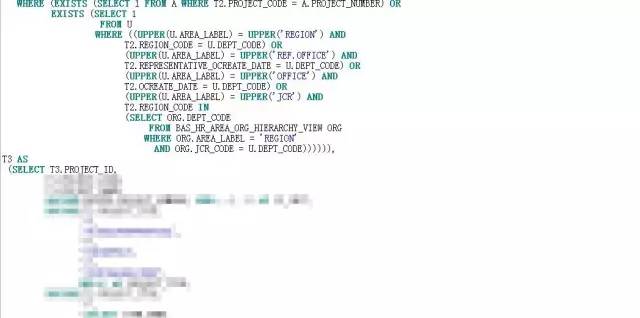
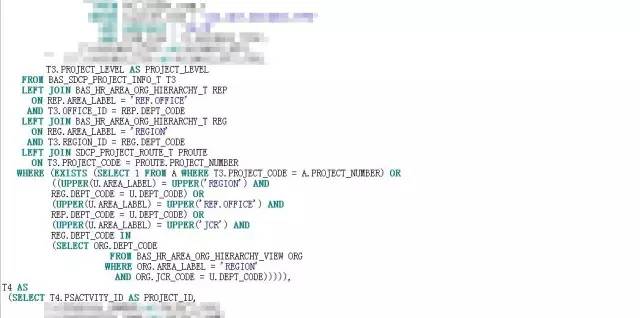
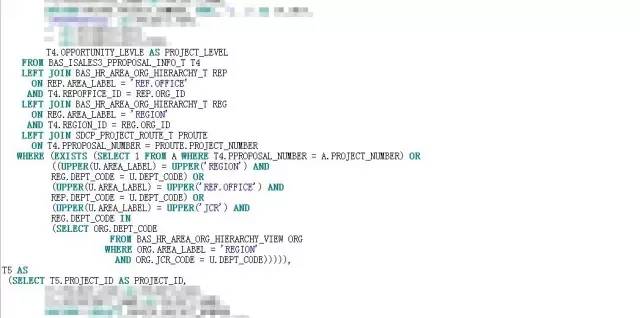

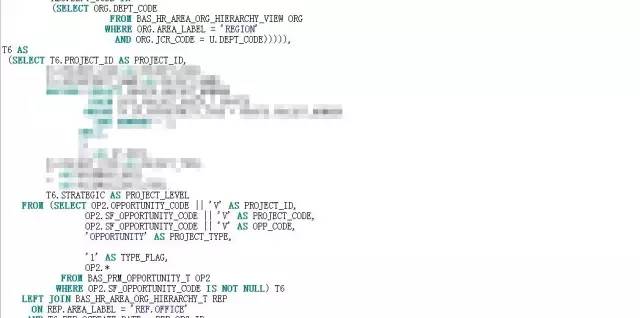

SQL改写后,怀着虔诚又激动的心情按下了F8,焦急得恍若停滞。1.8S,不容易呀。这0.7S的提升在动辄几秒钟、几分钟的优化空间中,如沧海一粟,但此刻却显得弥足珍贵。
该案例的优化过程其实就是一个SQL改写的过程,而最终演变成了SQL重写。这回到了一个最古老的问题:什么样的SQL才是好SQL?这个问题很难回答,因为这个问题跟哲学问题“什么样的人才是好人”是一样的。然而,我在长期与SQL为伴的过程中,从开发到优化,发现一个准则:简单即高效。这也合乎现在流行的返璞归真、大道至简的追求。
简单,并不是表现在代码量,而更在于SQL代码结构的简明、逻辑处理的简练。所在,在优化过程中,我首先考虑的是SQL自身的优化,也就是通常说的等价改写。我坚信,索引、Hint等技术的应用,应该是基于SQL已经极致化的假设。因为无论是索引,还是hint,在纷繁芜杂、不确定性的环境中,其负面影响也是巨大的。在风起云涌大浪淘沙时还能浪遏飞舟的,唯有“简单”的SQL。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721