
本文根据DBAplus社群第111期线上分享整理而成。
朱祥磊
山东移动BOSS系统架构师
负责业务支撑系统架构规划和建设
获国家级创新奖1项,通信行业级科技进步奖2项,移动集团级业务服务创新奖3项
申请发明专利13项
近几年,各类大数据技术迅猛发展,企业中数据处理量呈现几十到几百倍增长,数据类型也从传统结构化数据,延伸到实时流数据,以及各类非结构化数据。传统数据库单一技术包打天下的局面无法适应复杂多变的海量数据处理,从而出现了各类NewSQL技术和NoSQL技术,出现不同技术解决不同场景应用的局面。
以某运营商大数据平台为例,建立了基于“MPP平台+Hadoop平台+Kafak+Spark+Oracle”混搭架构的企业大数据中心。但随着数据量和业务量的倍增,平台间数据交互运算频繁,常规跨平台数据迁移和跨平台数据交叉运算的工作复杂度越来越高,急需高效方案实现对各大数据平台的统一管理。
本文通过研究SQL和NoSQL融合技术,并进行了测试,通过融合MPP之GBase数据库,以及传统Oracle数据库和Hadoop、Kafaka等平台能力,可以便捷地以统一的SQL接口打通跨平台的数据迁移和运算功能,解决了实际应用难点和痛点,并可以进一步推广到数据集市、历史数据统计分析等场景,实现在不改变当前应用架构的前提下,充分利用大数据能力的目的。
首先简单介绍各类SQL技术,具体如下:
基于强事务一致性的数据库,如Oracle、TimesTen、Sybase等,支持SQL标准,擅长于在线交易类型应用。特点是数据存储在列与表里、关系通过数据表来表示、DML\DDL\DCL语言、事务、物理层的抽象。
适合处理热数据,适用于小数据量、业务逻辑复杂、并发度高的事务型业务场景,如BOSS系统各个数据库。
本质上仍然属于关系型数据库,但是引入了分布式并行处理架构,支持SQL标准,如MPP(大规模并行处理)数据库,常见的如GBase、Greenplum等。
适合处理温数据,新型MPP数据库适合处理大规模的复杂分析,例如我们的经分核心数据仓库系统。
基于键值对的,而不是基于关系,适合查询需要快速返回答案场景,适合场景的特点是大量查询、极少修改、异步插入数据与更新数据、无模式、不需要强一致性事务,一般为开源,不支持SQL。
NoSQL细分为4类:列存储数据库(如Cassandra)、文档存储数据库(如MongoDB)、键值存储数据库(如Redis)、图形数据库(如GraphSQL)。
Hadoop适合任意结构化数据处理以及大规模批量复杂作业,键值存储数据库则适合缓存场景。

OldSQL和NewSQL都是基于SQL标准的,传统的SQL语法已经很强大,很多人已经习惯通过SQL获取自己需要的数据。但是NoSQL产品一般不支持SQL,这就造成了一定的知识碎片,传统技术人员需要再去掌握另一种NoSQL技术,带来很多的不便,同时NoSQL解决的问题是传统OldSQL和NewSQL无法解决的,如下:
非结构化数据处理(传统数据库仅支持结构化和半结构化数据)
海量历史数据的处理和查询(传统数据库难以进行海量数据存储)
流数据处理
深度迭代,机器学习
图算法引擎
R语言非结构数据算法分析
这就带来一个问题,是否可以实现采用传统的SQL和NoSQL结合,进行融合,即利用SQL的强大语法,同时利用NoSQL上述优点呢?
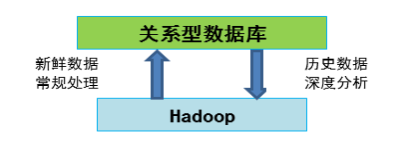
一个场景例子,在现有的Oracle数据库上保存最近期的数据,需要深度挖掘和历史查询,则自动转到Hadoop进行处理,这样充分利用了SQL和NoSQL的优点,避免了数据同步,大幅降低学习掌握NoSQL的难度。
SQL和NoSQL融合主要由如下几种演进路径:
一类是开源产品,如Apache Impala、Phoenix、Spark-SQL等。
一类是商业产品,如IBM的Big SQL、Pivotal的HAWQ等。
上述属于SQL on Hadoop,即在Hadoop上研发实现支持SQL机制,实现融合。
为了实现传统数据库和NoSQL的深度融合,一些数据库公司正在开发或已退出SQL and Hadoop产品,如Oracle公司的Big Data SQL等,可在Oracle中实现对Hadoop数据的直接查询。国产南大通用数据库GBase则推出了GBase UP产品,使后端SQL 和NoSQL上层封装为一个整体呈献给用户使用。
不同的产品以成熟的数据库为基础,扩展出针对Hive&Spark、HBase等组件的计算和存储引擎,建立引擎之间高效数据交换通道,构建了对外统一,对内可扩展的集群数据库产品。

对比上述SQL on Hadoop和SQL and Hadoop产品,后者在利旧现网数据库,以及在处理复杂多变的业务场景下优势明显,实现几乎不改变现有技术架构的前提下实现对大数据技术的充分利用。
为充分验证SQL and Hadoop技术,我们近期进行了测试,一是现有交易数据库Oracle和Hadoop的融合,一是数据仓库类型GBase和Hadoop的融合,取得较好的效果:
1Oracle和Hadoop的融合
Oracle公司推出Oracle Big Data SQL来实现本功能,主要思路是Oracle标准SQL通过实现跨Oracle数据库、Hadoop和NoSQL数据存储提供统一查询。
该产品需要Oracle数据库12c作为支持,数据库版本要求12.1.0.2以上;支持的Hadoop版本包括CDH 5.5以上或HDP 2.3以上。
Big Data SQL的主要理念是“SQL应该直接在数据所存储的地方”进行操作,即最大限度利用各类数据存放的位置平台的优势,同时利用统一的元数据用来实现如何执行统一跨平台查询,充分利用原有存储数据的技术平台的特性来优化查询执行效率,对于关系型数据库的技术平台,其优点包括:能立即查询处理,变化数据日志记录,细粒度的安全访问控制等等。对于Hadoop的技术平台,其优势在于可扩展性和schema-on-read。

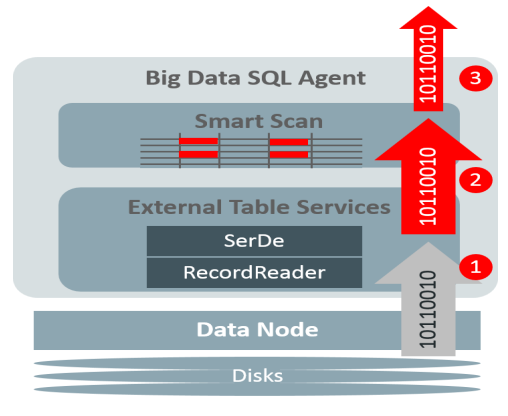
1)从HDFS DataNone上读取数据
直接路径读
基于C开发的读取引擎(目前支持分割文本和JSON)
其它使用Hadoop原生类来访问
2)转换成Oracle数据格式
3)基于Oracle格式数据做Smart Scan
WHERE子句条件过滤
列投影
应用布隆筛选器以提高联接性能
JSON/XML解析,数据挖掘模型评分
Oracle Big Data SQL通过Oracle数据库的数据字典技术,通过Oracle外部表技术的扩展,将在Hadoop或者NoSQL数据库中的表定义成Oracle的外部表。在通过外部表技术进行设计的同时,还充分保存和利用了Hadoop的特性。

CREATE TABLE movieapp_log_json
(click VARCHAR2(4000))
ORGANIZATION EXTERNAL
(TYPE ORACLE_HIVE
DEFAULT DIRECTORY DEFAULT_DIR )
ACCESS PARAMETERS
(
com.oracle.bigdata.tablename logs
com.oracle.bigdata.cluster mycluster))
PARALLEL 20
REJECT LIMIT UNLIMITED;
Oracle数据库12.1.0.2支持两个新类型的外部表,也就是两种新的访问驱动:ORACLE_HIVE和ORACLE_HDFS。ORACLE_HIVE是在Apache Hive数据源上创建Oracle外部表。ORACLE_HIVE也可以访问存储在其他位置如HBase的数据。ORACLE_HDFS是在HDFS文件上直接创建Oracle外部表。ORACLE_HIVE访问驱动从Hive中继承元数据, ORACLE_HDFS访问驱动需要手工指定数据访问方式。
Oracle Big Data SQL性能优化的核心是充分利用并行,让尽可能多的数据处理工作在Hadoop端完成,从而减少数据的流动。
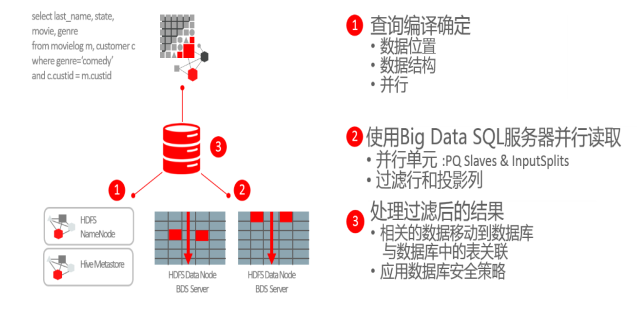
上面是Big Data SQL针对Hadoop智能扫描的技术,通过这个技术让数据能在其存放的Hadoop层就完成尽可能多的数据处理。Oracle Big Data SQL给Hadoop生态系统引入了一个新的服务,这个服务和HDFS的DataNodes,YARN NodeManagers协同工作。外部表的查询的请求能直接发送到这些服务,进行直接路径的数据本地读取。通过智能扫描加速I/O最大限度地减少数据移动。
存储索引
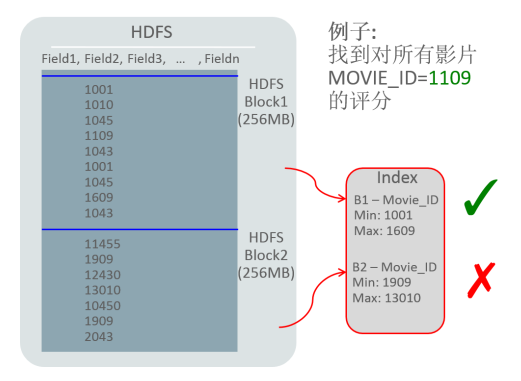
Big Data SQl还通过减少HDFS IO的扫描提升查询性能。通过外部表Mapping HDFS上的数据,存储索引记录每个HDFS block的最大、最小值。
数据安全
Big Data SQL支持跨Oracle,Hadoop和NoSQL数据源的一个统一的数据字典,将Hive和NoSQL数据呈现为Oracle的常规表,允许DBA来创建关系型数据的安全性,制定行级过滤策略等。
下面是测试的几个场景例子:
场景1:联合查询:A表(10亿行,在Hive中)和B表(7.6千万,在Hive中),指定某一个手机号。
场景2:联合查询:A表(10亿行,在Hive中)和B表 (7.6千万,在Hive中)指定b_avg_arpu字段排序,并取Top10。
场景3:联合查询:A表(10亿行,在Hive中)和B表(17行,在Oracle中)根据应用类型和城市分组,取记录数Top20。
场景4:联合查询:A表(7.6千万行,在Hive中)和B表(18行,在Oracle中),C表(315行,在Oracle中),根据城市分组,取4G流量最高的Top20。
场景5:联合查询:A表(10亿行,在Hive中)和B表(7.6千万,在Oracle中),指定vie_game_flow字段排序,并取Top10。
测试结果如下:

2MPP之GBase和Hadoop的融合
GBase UP,它是融合了GBase 8a MPP、GBase 8t、开源Hadoop生态系统等大数据平台产品,兼顾了大规模分布式并行数据库集群系统、稳定高效的事务数据库,以及Hadoop生态系统的多种大规模结构化与非结构化数据处理技术,能够适应OLAP、OLTP和NoSQL三种计算模型的业务场景。
通过构建完整的Schema定义和数据库访问控制,能够对用户数据库访问进行解析、优化、数据缓冲等操作,完成透明高效的中间数据存储、关联、聚合等操作,对内构建GBase 8a MPP、Hadoop或者其它数据库之间的内部数据传输协议,实现高效的数据交换,构建统一的监视和控制系统,进行资源调度。提供了经典的数据库接入方式和结构化查询语言,从而大大降低维护和开发成本。
其核心技术架构如下图:

其实质是在各个数据引擎(Oracle、GBase、Hadoop等)之上建立Mega SQL Engine (数据联邦),实现统一接口、统一查询语言、统一元数据以及统一的用户管理和权限控制,并构建了跨引擎的优化器和关联查询。整个架构中,GBase UP负责连接接入、元数据管理、跨集群查询调度、安全认证、日志记录等一系列分布式数据库的功能;GBase 8a集群(集合)负责高质量高密度高性能的数据存储和计算;GBase 8t(Oracle)负责支撑高端事务处理;Hive集群负责驱动Hadoop或Spark集群实现对低密度、低质量、结构化/非结构化的大数据进行分析;Hadoop集群的HDFS负责高效高可用的存储海量数据,HBase负责存储海量中小文件,以及作为分布式可扩展的KV型数据仓库。目前已经支持SQL92标准、HiveQL、GBase 8t 、HBase等,目前已融合Oracle部分功能。
测试环境:
测试功能点包括:统一接口数据加载,跨引擎数据交换(简单),跨引擎关联查询,跨引擎数据交换(复杂),水平分区表,数据备份恢复,Kafka对接UP测试,Hive on Spark模式用例测试。
测试软件版本:

场景1:统一数据接口数据加载
场景一是从ftp方式远程加载到UP数据库,二是从Hadoop HDFS加载到UP。
数据量:1157542760行
文件大小:593G
表名称:
cdr_gbase_t01_fromftp
cdr_gbase_t01_fromhdfs
语句:

执行结果:
|
SQL执行 |
耗时 |
|
FTP加载到8a(UP) |
Elapsed: 00:10:54.20 |
|
HDFS加载到8a(UP) |
Elapsed: 00:06:55.24 |
场景2:跨引擎关联(MPP和Hive)
测试MPP与Hive 在不同计算机制(MR/Spark)下join关联查询并分别插入MPP和Hive的功能。
表名:cdr_hive_t01 数据量:1157542760行
表名:dw_brand_status 数据量:98291109行
语句:

执行结果:

场景3:Kafka对接UP测试
验证Kafka消息加载到UP功能支持情况。
表名:cdr_gprs_dm_kafka 数据量:10000000行
消息大小:5.3GB 单行消息长度:560B
语句:

执行结果:
|
SQL执行 |
耗时 |
|
FTP加载到8a(UP) |
Elapsed: 00:10:54.20 |
|
HDFS加载到8a(UP) |
Elapsed: 00:06:55.24 |
场景4:水平分区表
验证UP产品对数据生命周期管理机制。
测试过程:
创建水平分区表,8a为热分区,Hive为冷分区;
创建自动数据迁移任务,每天将前一天的数据自动迁移至Hive分区;
将数据导入至热分区,验证热分区和整个水平分区表的数据正确性;
等待一天,观察数据是否已经自动迁移至冷分区,并验证冷分区和整个水平分区表的数据正确性;
尝试向冷分区插入数据,应报错(只有热分区可以更新数据,冷分区只供读取)。
语句:

执行结果:GBase UP按照设定的数据迁移策略后台自动透明的完成高效迁移。
以上为本阶段针对UP产品的测试说明,后续将逐步测试融合HBase、Oracle产品的能力,本文就不做过多赘述。
经过上述测试,初步验证了SQL和NoSQL融合技术的可行性,后续将推广使用,尤其历史数据存放和查询等场景,可实现Hadoop的历史数据直接查询,大大方便了数据生命周期管理。
密码:123









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721