
转载声明:本文为DBA+社群原创文章,转载必须连同本订阅号二维码全文转载,并注明作者名字及来源:DBA+社群(dbaplus)。
在数据库日常优化中,索引是经常使用的手段之一。本文由DB2数据库专家刘自传就围绕索引从DB2索引的扫描方式、DB2在索引列上应用谓词、在DB2中如何设计索引、在DB2中如何做索引的深度清理展开一些讨论、学习,更进一步探索索引的奥妙。
专家简介

刘自传
拥有10年IT从业经验,DB2数据库专家;具有多年的SQL开发、C语言开发、DB2运维及诊断优化经验;获IBMDB2 V10.1 for LUW的初、中、高级的DBA认证;擅长DB2的SQL优化、故障诊断及性能调优;db2china.net社区专家,并组织在线DB2数据库性能优化技术交流活动;具有多年医疗、金融行业、移动运营商(广东、西藏)运维经验。
1
DB2索引的扫描方式
在DB2,索引的扫描方式有多种形式,从DB2执行计划中可以看到有以下的形式:
1、IXSCAN–FETCH (先索引扫描,再根据RID读数据行)
2、INDEX–ONLY(索引扫描,只索引读即可满足整个SQL)
3、LIST PREFETCH(先索引扫描,再把RID排序,最后根据排序后RID读数据行)
4、IndexANDing(也叫IXAND,对两或多个索引分别进行扫描,这些索引一般是单列索引,再把符合条件RID进行AND运算,最后根据AND运算后的RID读取数据行)
5、IndexORing(也叫IXOR,对两或多个索引分别进行扫描,这些索引一般是单列索引,再把符合条件RID进行OR运算,最后根据OR运算后的RID读取数据行)
如下图的执行计划树中,分别有LIST PREFETCH、IXAND、IXOR扫描方式:

2
DB2索引管理器在对索引进行扫描时,在索引列上应用谓词时涉及到索引列的start key/stop key,有以下3种情况:

(以上效率比较,是在这3种方式之间的比较,并不是与表扫描方式比较)
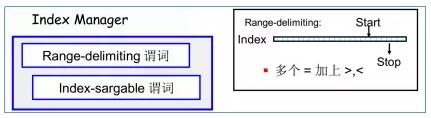
结合上图,其中A类型是属于Range-delimiting谓词;B、C类型是属于Index-SARgable谓词。
在分析执行计划时,可以识别出索引扫描时使用的是哪种谓词扫描方式,如下图可以看出是使用A类型:Range-delimiting谓词方式:

3
(一)、索引设计大原则:
1.为最重要、最频繁的查询/业务优先建索引;
2.为表的主、外键建立索引(注意主、外键的数据类型及长度最好一致,避免数据类型的转换);
3.索引的总数量、每个索引的字段数量要适中,一定不能太多,否则会增加IO、内存、CPU的额外开销,增加UDI、编译及准备、实用工具、备份及恢复的工作负载。(如:OLTP建议在5个以内,OLAP在10个以内);
4.可结合SQL执行计划、经验、db2advis等来分析:SQL是否使用了已有索引、是否需要创建新索引、是否基于现有索引重设计索引;
5.根据不同的情况选择不同的索引类型:普通索引、唯一索引、集聚索引、包含索引;单键索引、组合索引;MDC索引等;
6.若业务有特殊性,可考虑让索引支持双向扫描;
7.根据表的UID工作负载,选择适当pctfree/minpctused,避免索引页的浪费、不合理的索引页合并;
8.必要时可考虑创建完全索引扫描、包含索引来避免数据页读;
9.若评估启用索引压缩能有效节省索引大小,则启用索引压缩(注意不建议在CPU密集型环境中启用);
10.把索引表空间与数据表空间、大对象表空间分开放置在不同的物理磁盘,避免IO争用;
11.对于分区表,可根据实际情况,选择建立全局索引、分区索引,建议使用分区索引;
12.若时间、工作负载允许,可考虑在建索引时收集统计信息、采样收集统计信息,加快收集统计信息速度;
13.避免在小表上建议索引;
14.避免在大对象、长列(LB/LF)列上建立索引;
15.避免创建不使用的索引(建议考虑定期的索引清理,后面会提到索引的深度清理);
16.特殊情况下,考虑建多个相关单列索引,让DB2优化器使用index-Anding/index-Oring索引操作。
(二)、避免创建冗余索引
冗余索引是指一个索引字段是另一个索引字段的前导部分,如存在两个索引,分别是:(+A+B+C)、(+A+B),则索引(+A+B)是索引(+A+B+C)的冗余索引。相比之下,DB2优化器一般不会优先考虑冗余索引。
知道了什么是冗余索引,那么我们就可以有效地避免冗余索引、识别冗余索引。
要识别冗余索引,通过查询系统视图:syscat.indexes.COLNAMES/SYSCAT.INDEXCOLUSE,检查系统中是否已经存在了冗余索引,根据索引的使用情况考虑做索引的清理,以节省额外的磁盘、IO、内存、CPU的开销及相关UDI的维护成本。
(三)、复合索引的设计细节建议:
在对复合索引设计有一个three-star原则,就是选择哪些字段、安排字段的顺序:
1-start: where谓词列表放最前面,当然where谓词列表中有多个字段时,索引字段也有先后原则:等于谓词及范围定界谓词的放在前面、过滤因子较小(能过滤较多的记录)的放在较前;注意部分操作谓词(如<>)是不能使用索引或索引对此操作谓词不起优化作用。避免在索引列上使用函数。
2-start: order/group等字段置中间;
3-start: select列字段列表最后页(这个可以做为可选项,若想建立完全索引扫描索引进选用)。
当然这此原则也要视业务及数据情况而定,可能平衡索引扫描与排序操作之间的成本。所以有时部分order/group等列表中的字段可能会优先于where谓词部分字段放在中间,where的部分字段放在order/group字段的后面。
虽然启用双向扫描可以提高非按建索引时的顺序来扫描,但最好是索引字段升序、降序尽量与业务SQL要求的排序一致。
4
随着业务的发展,在生产库上会创建越来越多的索引,如何识别从未使用、不经常使用的索引呢,给我们的数据库减减负?
1、DB2 V9.5及以下版本:
使用db2pd -d DBName -tcb index[all],在“TCB Index Stats”信息块中,请关注以下两列:Scans、IxOnlyScns。
如果索引没有出现在“TCB Index Stats”信息块中、或其中的Scans值及IxOnlyScns值相对同一表的其他索引的这两个值来说,要小很多数量级,则一般可以认为很少使用的,可以考虑删除。
(注意:由于db2pd是直接读取内存的,其数据是数据库Activate以来的积累,如果数据库启动的时间范围覆盖了所有或大多业务周期是最好的,即该跑的SQL基本跑过了,才更有多参考价值;数据Activate了多久,可以从刚才的输出的前面部分可以看到类似:Database Partition 0 -- Database SAMPLE -- Active -- Up 0 days 00:14:20 -- Date 2015-07-09-19.21.27.429000的情况,可以从“UP”看看数据库启动了多久。)
2、DB2 V9.7及以上版本:
查看系统索引视图:syscat.indexes.LASTUSED,表示索引最后一次使用的日期;如果其值在对应表的业务周期(如月类型、年类型、周类型)还要前的,则证明索引在最近的业务周期内使用不上了。
对于syscat.indexes.LASTUSED,还应考虑以下3点:
syscat.indexes.LASTUSED='0001-01-01',表示索引在创建以后重来没有使用过;结合索引创建时间(syscat.indexes.CREATE_TIME),如果索引创建时间比较久了,则很有可能是无用索引,否则就要结合业务周期来考虑了。
syscat.indexes.LASTUSED<>'0001-01-01',则还要结合上述db2pd,因为最近使用过并不代表是经常使用的。
考虑索引与表的聚集度,查询系统视图:SYSCAT.INDEXES.CLUSTERRATIO或对比SYSCAT.INDEXES.FULLKEYCARD与syscat.tables.card的值,如果比值很小,说明索引行与表数据行的聚集度比较差,差则表明在对表进行批量操作时很有可能对此索引发生较高的维护成本,特别是IO维护成本上,所以请考虑清理此索引。
根据版本不同的,结合以上两点来识别无用索引、不经常用的索引,但还有一个很重要的前提,索引的统计信息是经常及时更新,否则可能会引起误判进而误杀索引。
另外,在清理无用、不经常用的索引时,请注意索引类型为P(主健)、U(唯一)一定要小心,当初建这些类型索引时可能是基于业务约束。
通过以上的讨论、学习,让我们对索引有了更进一步的认识,为我们用好索引这把双刃剑打下良好的基础。
即日起,凡是推送在【DBAplus社群】平台的文章,阅读量超过1000,该文章作者可获得赠书一本。大家如有好的干货文章也可以向我们的订阅号投稿,投稿邮箱:1017465571@qq.com。近期赠书有:白鳝《思想的天空》、杨志洪《Oracle核心技术》……
小编精心为大家挑选了近日最受欢迎的几篇热文:
回复001,看杨志洪《【职场心路】一个老DBA的自白》;
回复002,看丁俊的《【重磅干货】看了此文,Oracle SQL优化文章不必再看!》;
回复003,看胡怡文《PG,一道横跨oltp到olap的梦想之桥》;
回复004,看陈科《memcached&redis等分布式缓存的实现原理》;
回复005,看宋日杰《Oracle后台专家解决library cache锁争用的终极武器》;
回复006,看郑晓辉《存储和数据库不得不说的故事》;
回复007,看袁伟翔《揭秘Oracle数据库truncate原理》;
回复008,看李海翔《MySQL优化案例:半连接(semi join)优化方式导致的查询性能低下》;
回复009,看丁启良《LINUX类主机JAVA应用程序占用CPU、内存过高分析手段》;
回复010,看徐桂林《以应用为中心的企业混合云管理》。
DBA+社群是全中国最大的涵盖各种数据库、中间件及架构师线条的微信社群!有100+专家发起人,建有15大城市微信群,6大专业产品群,多达10000+跨界DBA加入队伍。每天1个热议话题,每周2次线上技术分享,不定期线下聚会与原创专家团干货分享,更多精彩,欢迎关注dbaplus微信订阅号!

扫码关注
DBAplus社群
超越DBA圈子,连接的不仅仅是DBA








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721