
怎样实现一次近乎完美的数据库版本大升级?本文详细介绍了 GitLab 将 PostgreSQL 从 9.6 升级到 11 版本的工作。
2020 年 5 月,我们与 OnGres 合作,对 GitLab 上的 Postgres 集群进行版本大更新,从 9.6 版本升级到 11 版本。升级全部在维护窗口内运行,没有丝毫差错;更新中所有涉及的内容、计划、测试,以及全流程自动化,全部进行拆包,只为实现一次近乎完美的 PostgreSQL 升级。
本次版本更新,我们面临的最大难题在于如何利用一个规划完善的 pg_upgrade,方便且高效地对整体项目进行重要版本升级。为此,我们需要制定一个回滚计划,以保证 12 节点集群的 6 TB 数据一致的同时,优化恢复目标时间(RTO)后的容量,为 600 万用户提供每秒 300000 次的聚合交易服务。
解决工程难题的最佳方案是按照蓝图和设计文档行事。在创建蓝图的过程中,我们需要定义目标问题,评估最合适的解决方案,并考虑每个解决方案的优缺点。
在此,我们附上为这个项目准备的蓝图链接。
https://gitlab.com/gitlab-com/gl-infra/readiness/-/tree/master/library/database/postgres/Postgresql-upgrade/blueprint/
一、我们为什么要升级PostgreSQL
我们决定在 GitLab 13.0 中停止对 PostgreSQL 10.0 的支持,而 PostgreSQL 9.6 版本将在 2021 年 11 月 EOL(项目终止),因此,我们需要采取相应的行动。
下面是 PostgreSQL 9.6 和 11 版本之间的主要区别:
表分区支持 LIST、RANGE,以及 HASH;
存储过程支持事务;
即时编译(JIT)加快查询表达式的运行速度;
并行查询,增加并行化数据定义功能;
新版本的 PostgreSQL 继承了版本 10 中的“逻辑复制——分发数据的发布 / 订阅框架”,该功能可以使日后的升级更加顺滑,简化了其他相关流程;
基于 Quorum 的提交(commit),确保事务能在集群中指定节点进行提交;
提升了通过分区表进行查询的性能。
二、环境与架构
PostgreSQL 集群,其基础架构容量由 12 个服务于 OLTP 以及异步管道的 n1-highmem-96 GCP 示例组成。同时,它还有两个不同规格的 BI 节点,每个节点都有 96 个 CPU 内核以及 614GB 的 RAM。HA 集群通过 Patroni 进行管理和配置,以保证 Consul 集群及其所有复制体在异步流复制中,使用复制槽和 WAL 对 GCS 存储桶进行复制工作时的 leader 选举一致性。
https://github.com/zalando/patroni
我们的配置目前使用的是 Patroni HA 解决方案,它会不断收集集群、leader 检测,以及节点可用性的关键信息。该解决方案采用 Consul 的 DNS 服务等关键功能来实现,进而更新 PgBouncer 端点,确保读写和只读流量使用不同架构。
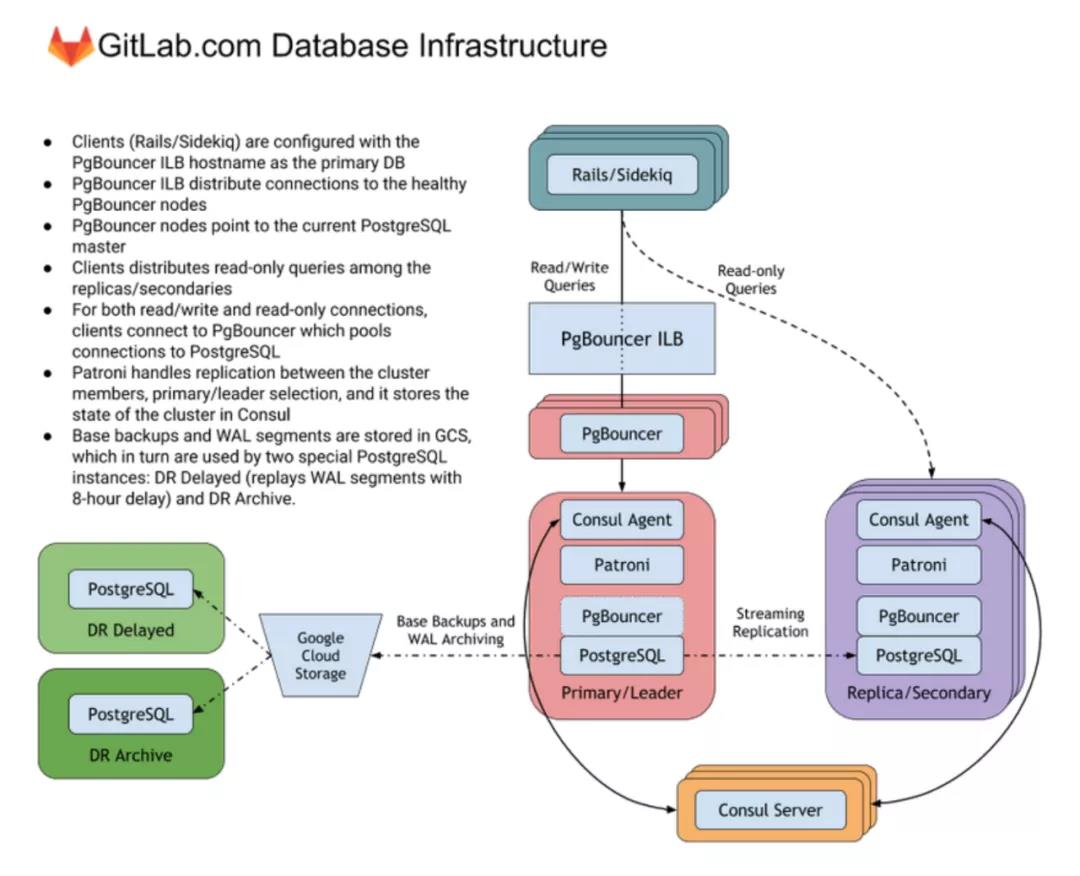
GitLab.com 架构
因为 HA 的缘故,其中两个复制体不在只读服务器列表池中,而是由 Consul DNS 支持,服务于 API。对 GitLab 架构几次改进后,我们得以将项目整体降到 7 个节点。
此外,我们的整个集群平均每周要处理大约 181000 个交易每秒,如下图所示,流量会在周一有明显增加,并在周一至周五 / 六内保持该吞吐量。我们需要让维护影响到尽量少的用户,因此流量数据的统计对于设置合适的维护窗口至关重要。

GitLab.com 上连接数量统计
项目整体在全天中最忙碌的时刻可以到达 25000 交易每秒。

GitLab.com 上 commit 数量统计
与此同时,项目处理的交易峰值可以到达每秒 30 万次交易,GitLab.com 能到达每秒 6 万次连接。
三、我们的升级需求
在生产环境进行升级前,我们首先确定了一些需求:
PostgreSQL 11 上不能有回归。我们开发了一个自定义基准测试来运行更广泛的回归测试,目标是识别 PostgreSQL 11 中潜在的查询性能下降;
升级应当针对整体项目,并在维护窗口内完成;
使用 pg_upgrade 升级,其依赖于物理层面,而非逻辑或者复制。
保留一个 9.6 版本的集群样本。并非所有节点都需要升级,我们应保留一些 9.6 版本的节点以备回滚;
升级应全自动化,以降低人类失误的可能性;
全部数据库升级的维护窗口只有 30 分钟;
升级应留有记录并将其发布。
四、项目
为使生产升级能顺利运行,我们将项目划分为以下四个阶段:
1)开发 ansible-playbook,并在 staging 上备份的 PostgreSQL 环境中进行测试
https://gitlab.com/gitlab-com/gl-infra/db-migration/-/tree/master/pg-upgrade
2)独立环境的使用让我们可以随时停止、启动,或者恢复备份,也让我们专注开发,并得以将环境随时回滚到升级前。
3)我们使用 staging 上的备份在环境中进行项目升级。在这个过程中,我们也遇到一些诸如在迁移数据库的过程中如何监视不同程序之类的挑战。
第二阶段:在staging中将升级开发与配置管理进行分段式融合
1)在 Chef 中集成配置管理,并运行数据库磁盘中的一个快照(可用于还原更新前状态)。
2)通知用户,本次维护窗口将力争对他们工作的影响降到最低,并在没有数据损失风险的情况下进行安全升级。
3)在对配置管理进行迭代和集成测试后,我们开始在 staging 上运行端到端测试。这些测试内容是在内部公开的,所以其他共享这个环境的团队会知道 staging 在这段时间暂时不可用。
第三阶段:在staging上测试端到端升级
正式运行前对环境的检查。我们有时候会在这一步发现认证的问题,有时候也会做一些能提升测试效率的小调整;
停止 GitLab 上所有应用和流量,在 CloudFlare 和 HA-proxy 上添加维护模式,停止包括数据库、sidekiq、workhorse、WEB-API 等一切能访问数据库的应用;
升级集群中六个节点中的三个。与生产中部分场景的策略类似,我们同样准备了回滚方案;
为 PostgreSQL 的更新运行 ansible-playbook。首先是数据库 leader 节点,之后是一些二级节点;
升级之后:我们在 ansible-playbook 中运行了一些自动化测试,用以检测复制数据与原数据是否相符;
接下来,启动应用程序,让我们的 QA 团队能运行一些测试。他们在升级后的数据库上运行了本地单元测试,我们对负面结果进行了调查。
测试结束后,我们再次停止程序运行,并将 staging 集群还原到 9.6 版本,将升级过后的节点关闭到版本 11,最后启动旧版集群。Patroni 会 promote 其中一个节点,启动应用后集群就可以收到流量反馈。我们将 Chef 的配置恢复到集群 9.6 版本后重建数据库,留出六个节点为下次测试做准备。
我们总共在 staging 中运行过 7 次测试,并通过反馈不断完善程序。
第四阶段:升级进入生产环境
生产环境的步骤与 staging 中类似,我们计划迁移八个节点,留下四个作为备份。
执行项目前期检查;
宣布维护开始;
运行 ansible-playbook 以停止流量和应用;
运行 ansible-playbook 以进行 PostgreSQL 升级;
开始验证测试并恢复流量。我们只运行了必需的测试,才能在短暂的维护窗口内完成所有内容。
回滚计划只会在数据库不一致或者 QA 测试出错时才调用,以下是具体步骤:
停止 PostgreSQL 11 集群;
还原 Chef 中配置到 PostgreSQL 9.6;
用 9.6 版本中的四个节点初始化集群。通过这四个节点,我们可以在流量较低的时候恢复 GitLab 上的活动;
开始接收流量,借此可以尽量减少停机时间;
使用在维护期间和升级前的磁盘快照恢复其他节点;
升级中的所有步骤都在用于运行项目的模板中有详细说明。
五、pg_upgrade运行原理
pg_upgrade 让我们可以在不用 dump/reload 策略,不用更多停机时间的情况下,将 PostgreSQL 数据文件升级到日后的主要版本。
https://www.postgresql.org/docs/11/pgupgrade.html
正如在 PostgreSQL 官方文档中所写,pg_upgrade 工具通过避免执行 dump/restore 的方法来升级 PostgreSQL 版本。这里有几点细节需要注意:PostgreSQL 的主要版本会添加新功能,这些新功能经常会改变系统表的布局,但内部数据存储格式基本会保持不变。如果某次主要版本升级改变了数据格式,那么就不能继续用 pg_upgrade 了。因此,我们必须要先验证这些版本之间都有什么变化。
还有一点很重要,任何外部模块都必须兼容二进制,虽然你并不能通过 pg_upgrade 来检查这点。对 GitLab 的更新来说,我们在升级前先卸载了 postgres_exporter 等视图及拓展,以便在升级后重新创建,出于兼容性考虑,还要稍作修改。
https://github.com/wrouesnel/postgres_exporter
在更新前,必须先安装新版本的二进制文件。新的 PostgreSQL 二进制文件及拓展文件都装在需要升级的主机中。
pg_upgrade 在使用时有很多选项。我们选择在 Leader 节点上使用 pg_upgrade 的链接模式,因为维护窗口很短暂,只有两个小时。这种模式可以通过 inode 硬链接文件,避免了复制 6TB 文件的麻烦。缺点则是旧数据集群无法回滚到 9.6 版本。我们保存了 9.6 版本的副本和 GCP 快照作为后备计划的回滚路径。因为从头开始重建副本是不可能的,所以我们选择使用 rsync 增量功能来进行升级。pg_upgrade 的官方文档也有写:“从主服务器上位于旧数据库集群目录和新数据库集群目录上方的目录中,在每个备用服务器的 primary 上运行此命令。”
ansible-playbook 对于这一步的实现,是通过从 leader 节点到每一个副本都有一个任务,在新旧数据目录中的父目录中触发 rsync 命令。
六、回归测试的基准
任何的迁移或数据库升级都需要在最终的生产升级前进行回归测试。
对团队来说,数据库测试在升级过程中是至关重要的一步,根据生产过程中的查询数额来进行性能测试,将结果存到 pg_stat_statement 表中。这些都是在同一个数据集中运行的,一次是在 9.6 版本,一次是在 11 版本的迭代。
这一步过程可以在下面这个公共的 issue 中找到:
https://gitlab.com/gitlab-com/gl-infra/infrastructure/-/issues/
工具的准备;
创建测试环境;
计算容量;
使用 JMeter 工具运行基准测试。
最后,根据 OnGres 在这一基准测试上的工作,GitLab 将在未来跟进新的基准测试。
主要生产数据库集群的能力评估;
数据库容量及饱和度分析。
七、升级过程:全自动就完事了
在升级项目中,升级团队坚持使用自动化和基础架构及代码工具(IaC)。所有流程必须全部自动化,以减少在维护窗口的人为失误。pg_upgrade 所有的运行步骤都可以在这个 GitLab 的 pg_upgrade 的模板 issue 上找到详细说明。
https://gitlab.com/gitlab-com/gl-infra/db-migration/-/blob/master/.gitlab/issue_templates/pg_upgrade.md
GitLab.com 的环境由 Terraform 和 Chef 共同管理,所有的升级自动化都是用 Ansible 2.9 的 playbook 和 roles 编写的,我们用了两个 ansible-playbook 来完成升级自动化:
一个 ansible-playbook 控制流量和应用:
将 Cloudflare 设置为维护状态,不接受流量;
停止 HA-proxy;
停止访问数据库的中间件:Sidekiq、Workhorse、WEB-API。
另一个 ansible-playbook 运行升级过程:
协调所有数据库和连接池的流量;
控制 Patroni 集群和 Consul 实例;
在主节点和次级节点上执行升级;
收集升级后的统计数据;
使用 Chef 同步更改,以保持配置管理的完整性;
验证集群的完整性和状态;
执行 GCP 快照;
(可能的)回滚过程。
playbook 以交互方式逐个运行所有任务,让程序员得以在任意给定执行点跳过或暂停程序。参与 staging 测试和迭代的所有团队成员都要过目升级过程中的所有步骤,staging 环境让我们通过演习提前找到升级过程中潜在的漏洞。而执行和迭代 staging 中自动化过程则让我们实现了 PostgreSQL 9.6 版本至 11 版本的基本无缺陷升级。
为完成本次的版本升级,GitLab 的 QA 团队将部分测试中发现的问题反馈给我们,这一部分的工作可以在这条 issue 中找到。
https://gitlab.com/groups/gitlab-com/gl-infra/-/epics/106#note_332170837
八、PostgreSQL预升级的步骤
升级工作的第一步是“预升级”,这里涉及到预留给回滚的示例。我们做了相应分析,以确保新的集群可以不丢失吞吐量的情况下,以 8 个示例为起点,保留 4 个通过标准 Patroni 集群同步的 9.6 版本示例,为后续可能需要的回滚情况准备(共计 12 个实例)。
在这个阶段,我们还需要停止依赖 PostgreSQL 的服务,诸如 PgBouncer、Chef 客户端,以及 Patroni 服务。
在正式开始更新前,必须要告知 Patroni,避免任何虚假 leader 选举,通过 GCP 快照(通过对应低级备份 API 获得)进行一致的备份,并通过运行 Chef 应用新的设置。
https://www.cybertec-postgresql.com/en/exclusive-backup-deprecated-what-now/?gclid=CjwKCAjwltH3BRB6EiwAhj0IUBjiSxBdmS11SUpITLCmk-oPkBa7udOWyA6bK6hig8neaiJc8n1WexoCq8UQAvD_BwE
九、PostgreSQL升级阶段
首先,停止所有节点。
然后,运行以下检查:
pg_upgrade 版本检查;
验证所有节点都已同步,并且不再接受任何流量。
一旦主节点数据升级完毕,就会触发 rsync 进程以同步所有副本数据。在升级完成后,启动 Patroni 服务,这样所有副本都能轻松更新至新集群的配置。
通过 Chef 安装二进制文件,新集群在版本方面的设置是在同一个 MR 中定义的,MR 源自 GitLab.com,可以安装用于数据库中的拓展项。
最后一个阶段则包括恢复流量、运行初始的真空期,以及最后的启动 PgBouncer 和 Chef 客户端服务。
十、迁移日
到了最后,我们为运行生产线上升级做好了万全准备,团队在周日一早 8:45 UTC 开始会议(对有的人来说是晚上)。服务将最多下线两小时,当最终的通知下达后,工程团队终于可以开始进行。
升级过程由停止所有流量及相关服务开始,这是为了避免用户在更新中途访问网站。
下面图表显示在服务更新之前,维护期间(图标中的空白部分)、以及维护结束、流量恢复后的流量和 HTTP 数据统计。

GitLab.com 上的数据统计图,从维护开始到结束
整个流程共花费四个小时,其中仅包括两小时断线时间。
此外,我们录下了 PostgreSQL 更新的全过程并发布在 GitLab Unfiltered 上。
https://youtu.be/TKODwTtKWew








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721