
刘航,国信司南地理信息技术有限公司GIS研发工程师、技术经理。
之前介绍了如何使用PG与PostGIS搭建实时矢量瓦片服务,但未介绍如何做优化,对于日常项目使用基本可以满足。这篇文章主要试介绍如何浏览百万级要素,示例为300万点要素。
《基于PG与PostGIS搭建实时矢量瓦片服务》:https://blog.csdn.net/qq_35241223/article/details/106439268
对于某些应用场景,数据量很容易达到百万级要素,数据每天都在改变。而且还要考虑在1-6级这种小级别时候的数据展示,那么这个时候仅仅是PG与PostGIS简单的矢量瓦片服务比较困难达到客户想要的效果,这个时候就要考虑做一些优化了。
百万级要素优化对于不同的业务来说,有相应不同的解决办法,没有最好,只有更好,这个时候要做考量,下面介绍几个常用的会考虑使用的方法:
1、依据业务,对要素进行抽稀过滤
根据业务层面,在不同场景浏览不同的要素,虽然总的要素在几百万,但是这个时候过滤一部分后剩余要素可以进行实时矢量瓦片展示。
2、几种抽稀过滤的算法
除第一种方法外,其余几种方法包含一些个人的想法与思路,其它小伙伴有其他好的思路,或者对我的想法思路有疑问的话,欢迎在评论区留言。
1)道格拉斯-普客算法(DP)
该算法个人理解为是简化的算法,对于线或者面的边界,可以使用该算法对节点进行抽稀,达到对线或者面的简化。但是为什么在点要素抽稀过滤中也介绍该算法呢?
答案:在轨迹数据中,每一次存储的都是点位信息(点),所以对于该种数据可以使用该算法进行过滤,但是对于一个点即代表一种信息的数据来说,该算法不太适用。
2)基于网格的抽稀过滤算法
该算法结果为均匀分布。
根据数据范围以及阈值将范围划分网格。
遍历网格,利用网格与数据求交(使用PostgreSQL的gist索引,加快速度),计算交到的要素。
将交到要素随机选取一个,其余要素舍弃。
遍历完网格后,即可完成要素过滤。
本人写了一个简单的实现,供各位参考。
github链接:https://github.com/MrSmallLiu/point_dilution
3)基于距离的抽稀过滤算法
该算法结果为均匀分布。
设置距离阈值。
选取初始点,计算其它点到该点的距离,阈值范围内的点,舍弃。
从上次结果中,选取另一个点作为基准点,再次执行(2)的步骤,只需计算保留下来的点。
全部点计算完成后,即可完成要素抽稀过滤。
4)基于随机数的抽稀过滤算法
该算法结果可以保持数据疏密。
对于大数据量时的随机数,可以达到伪随机性,所以可以利用该算法进行随机性的抽稀。
设置经验阈值,例如r=0.5,同时因为该算法效率可以实时进行,可以考虑基于每一次查询矢量切片时,根据级别设置阈值。
查询的sql语句中或者其它方式后面添加where条件,where random()>0.5时保留要素。
基于以上就可以完成50%的抽稀率。
使用的局限:
对于小数据量可能效果达不到。
优势:
效率很高,可以不用提前处理数据。
可以将random()做到数据字段中,使用btree加速。
设置字段中后,可以保证例如小级后的结果例如3级,在后续级别中保留例如4-18级。
5)基于网格与随机数抽稀过滤算法
该算法结果可以保持数据疏密。
根据范围与网格大小阈值,划分数据网格。
遍历网格,利用网格与数据求交(使用PostgreSQL的gist索引,加快速度),计算交到的要素。
在网格内根据随机数,将网格内数据随机丢弃一些。
网格遍历完成后,即完成数据抽稀过滤。
该算法弥补了单纯基于数据数的一些局限性,不会导致数据存在缺块(对于大数据量,可能性微乎其微)。
6)基于距离并保持疏密程度的抽稀过滤算法
该算法结果可以保持数据疏密。
设置距离阈值,设置丢弃比例。
选取初始点,遍历其它要素,计算其它要素到该要素的距离,小于距离阈值的归为一片。
将该片数据,基于丢弃比例,舍弃一部分要素。
继续下一个点为基准点,循环(2)(3)的步骤。
全部要素完成后,即可完成数据抽稀过滤。
以上即为介绍的几种抽稀过滤算法,可以在合适的场景使用合适的方式。其中虽然有些算法存在局限性(基于随机数的算法),但是对于大数据量来说,可能性很低,并且效率极高,可以做到实时,以下效果也是采用该方法。
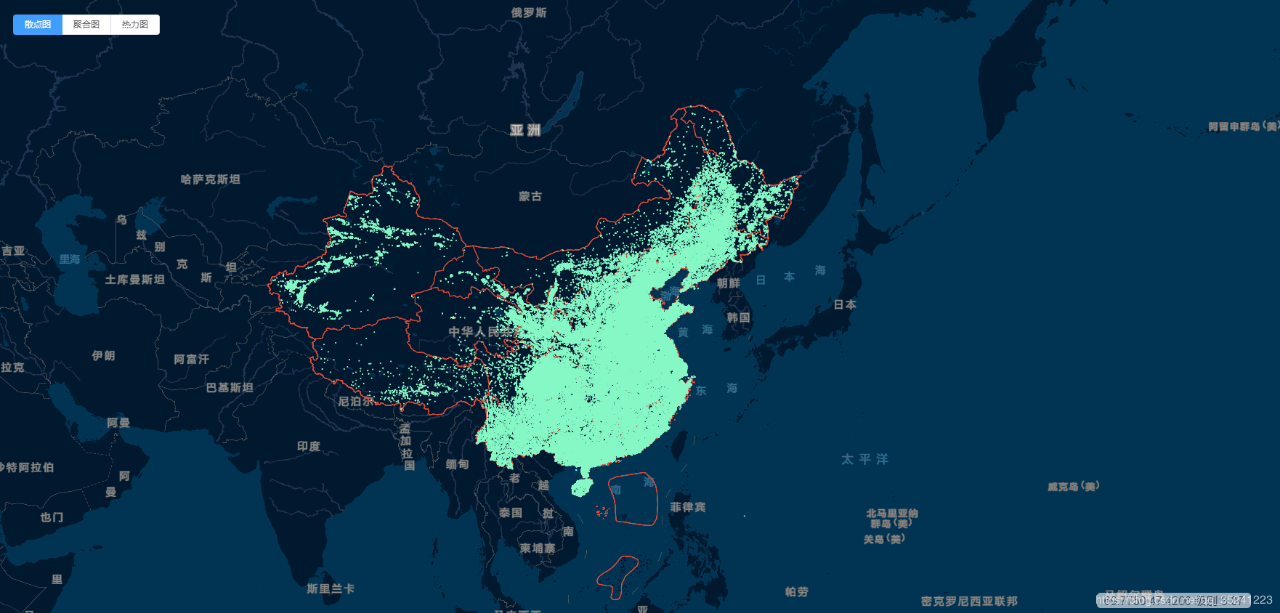
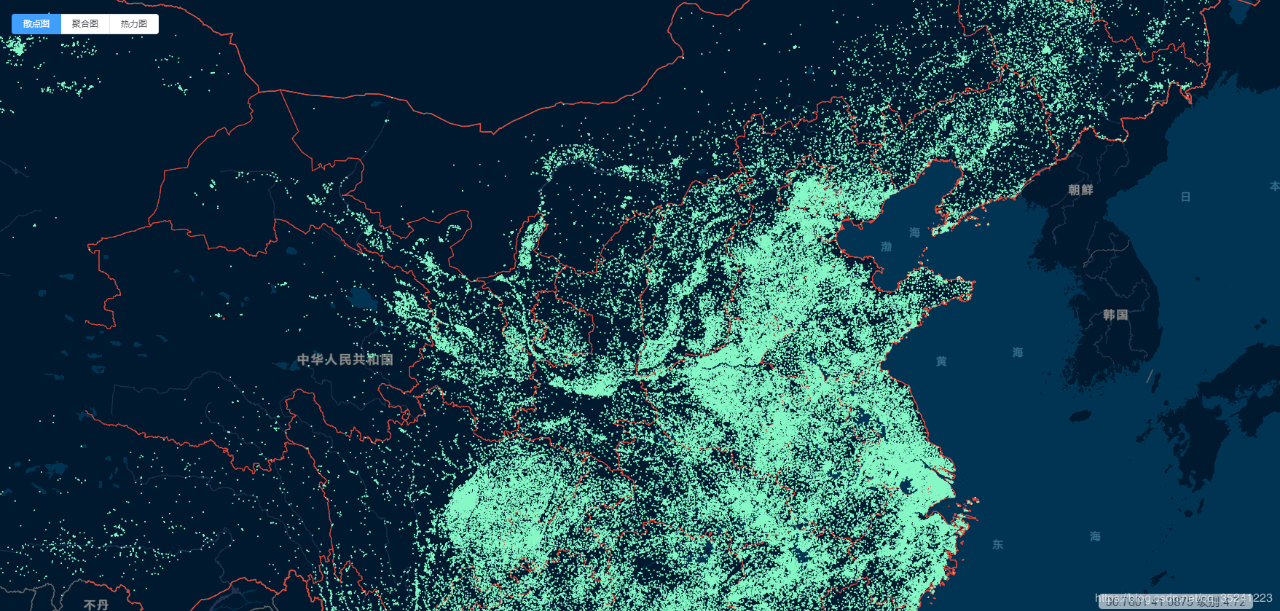
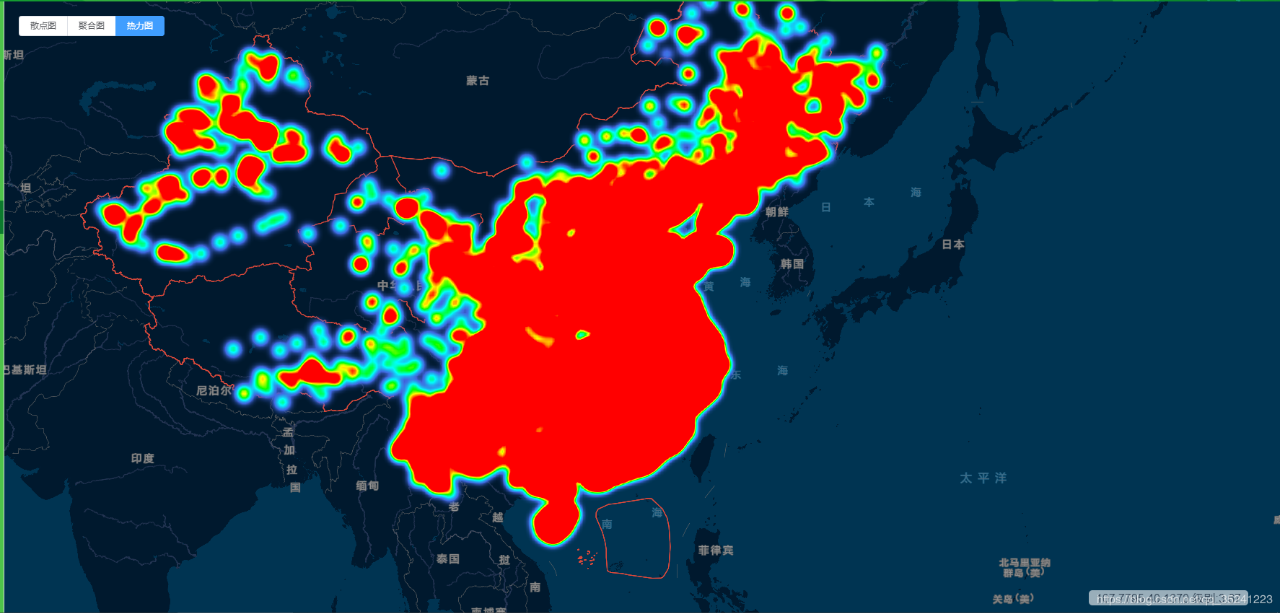
示例:
数据量: 本示例数据量为300万点要素;
抽稀过滤方法:基于随机数抽稀过滤,将random字段添加到字段中,同时利用该方法结合经验值,实时抽稀过滤展示(例如:<4级:0.2,4-6级:0.4,7-9:0.7,>10不抽稀过滤);
数据展示方法: 实时矢量切片,结合根据级别抽稀过滤。
效果图:
以上优化方法仅为个人的一些经验以及思路,有错误的地方欢迎留言,一起交流,向您学习。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721