
本文根据digoal(德哥)在〖2019 DAMS中国数据智能管理峰会〗现场演讲内容整理而成。

(文末可获取演讲完整PPT)
最近几年我在推过PG的活动中,走过差不多15、16个国内城市,遇到不少参会者问到这样一些问题:
学生非常关心学习PG能从事什么样的工作、未来发展机会如何?
用户特别关心迁移到PG是不是最终状态?它是不是未来的趋势?
作为一个开源数据库,背后是不是有商业公司在控制着它?
所以,我首先会分享PG社区的内容。
如果说99%的开源数据库都是被商业公司控制的,那么PG是那1%。
要说商业公司为什么要把数据库开源出来?为什么要改协议?这个我们先来分析一下:今天你要研发一款数据库,并且得到市场的认可,如果不开源的话,你会发现这个数据库必须要有很好的渠道才能赚钱,所以商业公司选择开源,培养背书群体,扩大生态,收割大客户。
至于为什么要改协议?我们看到许多商业开源数据库都有对应的付费版本,例如企业版,高级周边工具等。随着上云成为了大趋势,“云开源数据库服务”吞噬着开源数据库市场,用户更多选择的是云服务,而不是开源数据库的企业版,这就造成了商业开源公司与云发生利益冲突,改协议是商业开源数据库厂商被迫的选择。
而PG是一个纯社区的数据库,背后没有被任何一家公司所控制。我们来看一下以下这张图:
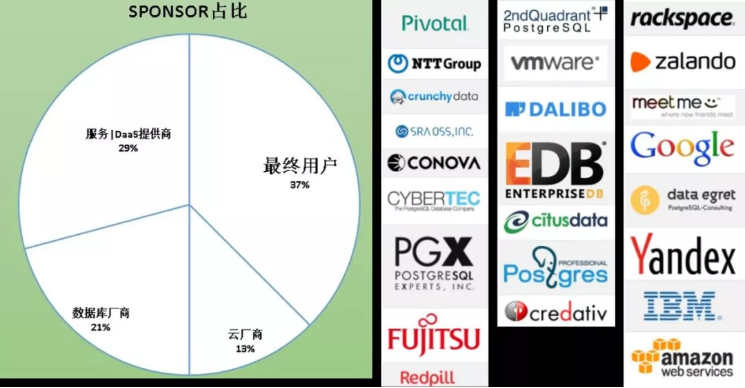
饼图展现的是给PG贡献代码的占比,我们先看数据,后面再跟大家分析一下原因。看图你会发现占最大头的是用户,第二是数据库服务商,这里的服务包括培训、技术支持类的服务等。这两大块加起来就有66%了,剩下的就是数据库厂商和云厂商。
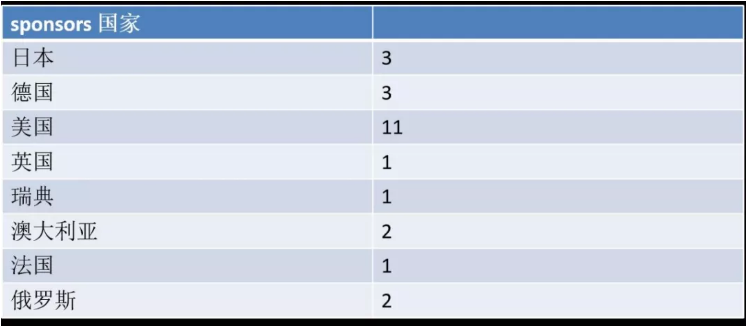
上图是给PG贡献代码的国家分布,上面没有中国有点遗憾,但可能是因为这个至少要贡献两年以上才入列,所以中国估计过两年会出现在这里。
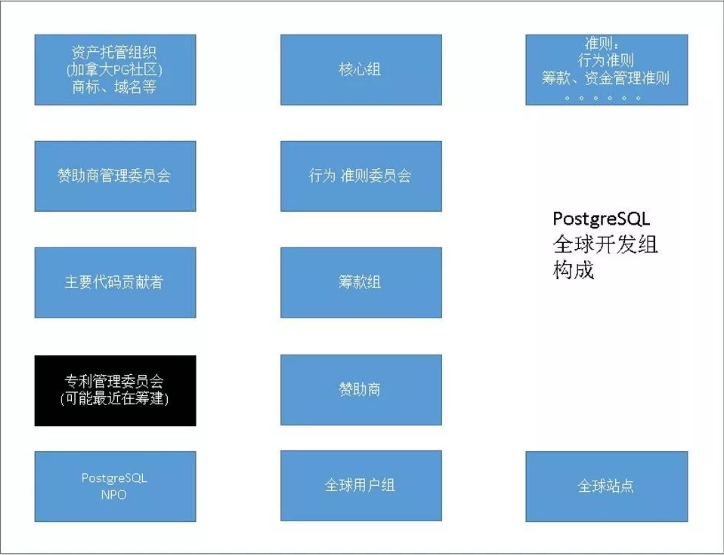
PG作为一个开源的社区数据库活了这么久(追述到ingres的话有43年历史),感觉牙齿不但没掉还越来越锋利。凭什么?PG有组织有纪律,从上图可以看到首先是资产托管组织,包括商标、域名等,每年的开发者峰会在加拿大举办。
另外还有核心组、行为准则团队,类似于组织部,有专门管赞助的委员会、筹款组等等。将来可能会组建专门负责管理专利的委员会,因为作为开源数据库会发现专利可能是一个非常容易存在的漏洞点,PG对专利控制还是比较严格的。
回过头分析刚刚给PG社区贡献代码的企业,他们为什么要持续贡献核心代码?
对于数据库厂商来说,推一款新的商业数据库通常都需要背书,试问小厂产品谁为你背书?
只有技术的厂商,很难挑战已有数据库市场格局。
只有渠道的厂商,需要抓住窗口期,快速占领市场,避免重复造轮子,需要一款可以无法律风险,二次开发与分发的开源数据库。目前达到商业化成熟度的唯有PG。
所以数据库厂商需要通过贡献核心代码,社区所有的用户都可以为之背书。
对于数据库服务提供商来说,开源产品的服务提供商,怎么才能体现他们的能力?谁能证明他们的牛逼?贡献代码,贡献代码之后用PG的那些人就可以为之背书。
对于最终用户来说,他们希望社区长久,期望可以享受免费的、可持续发展的、开源的、不被任何商业公司、不被任何国家控制的企业级的数据库。而且PG用的人越多,越多人背书,使用越靠谱,就像滚雪球一样越滚越大,所以最终用户愿意贡献代码,实际上是在推动开源产品的发展,对客户自己也是有利的。
对于云厂商来说,自己做一款数据库在云上卖需要培养生态,需要市场背书,需要大量研发资源,可能还需要重复造轮子。那么基于PG,就能免去自己培养生态,避免重复造轮子,而且PG的代码基础已经具备商业化基础。另外,不断提供代码也是防止其他厂商控制PG失去市场主导能力的方法。
除了以上这些原因,还有很重要的一点,开源许可独特性。PG的开源许可是类BSD许可,可以随意分发、闭源或开源,可以被用于商业目的或其他场合。

PG开源中心的这行字(见红框),说的是不管怎么使用、拷贝、修改、分发这个软件,只要把这一行放到你的输出版本里面去就行了。是不是活雷锋?所以云厂商选择这么友好的纯社区版本感觉像拣到宝一样。
作为一款开源出来拿去直接用的数据库,PG采用了开放接口的设计,是最具扩展能力的数据库。基于PG的图数据库、流数据库、GIS、时序数据库、推荐数据库、搜索引擎等;围绕PG的应用垂直化插件机器学习、图像识别、分词、向量计算、MPP等,基本上都是使用PG扩展接口扩展出来的。
目前全球都在提高安全、合规、正版化意识,对于数据库厂商、云厂商来说,从长远来看,纯社区具有这么强的可扩展能力的数据库,PG可以说是首选。生态已经摆在这里了,还有不去用的理由吗?
首先,PG是一款远远超越当前关系数据库的多模数据库,因为它的开放性,可以随意扩展。
其次,在内置并行计算方面,我接触过很多用户的数据库就跟蜘蛛网一样,为什么?因为用户的业务需求很多,关系数据库处理不了,需要将数据同步到其他引擎:最常见的有计算平台、搜索引擎,还有一些客户要同步到流计算平台,空间,时序数据库平台等。同步会带来硬件、管理、开发成本的增加,同时会引入数据丢失、延迟等风险。如果数据库提供并行计算、搜索、时空等多模能力的话,没必要把平台建这么复杂。
再次,PG开始在内核中支持存储引擎的扩展,可以解决行存、列存、内存引擎,多样化的多版本控制,等不同场景不同需求的问题。
最后,在芯片支持方面,PG对芯片友好,例如ARM芯片的支持。
以上四方面满足市场的既要又要还要的需求,即:既要SQL通用性,又要NOSQL扩展性,还要多模开发便捷性;既要OLTP又要OLAP。
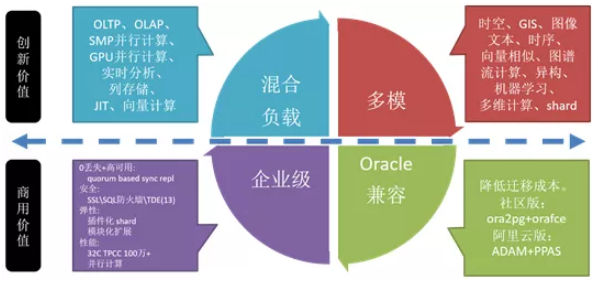
对于数据库的商用价值来讲,首先是能不能扛住企业级的需求,也就是能不能做到零丢失、高可用、安全;弹性这一块就是能不能横向扩展、能不能做模块化;而性能这一块TP、AP都可以跑。Oracle兼容性体现两块:社区版本有这样的插件,加完这个插件在Oracle数据类型然后还有函数,还有操作服务这一块做的兼容,包括包也做的一些。因为用户我见过大量的使用PLsql的存储过程或函数,一个业务部就有上百万行,使用PG的plpgsql可以改造这些oracle plsql存储过程代码。
另一方面吗,阿里云提供兼容Oracle的数据库PPAS(实际上也是基于PG的),我们兼容了PLsql语法,能够减轻用户区改造存储过程到PG的工作,所以说这个东西熟悉之后你会发现PLPgsql能够满足功能差不多,没有会弱到哪里去,其实做得挺好的。
在创新能力上,其实我们刚刚讲到了一块关于边缘计算,边缘计算分两块:基于GPU的并行,对用户是透明的,数据库会根据sql的成本、代价去启动GPU并行计算。
阿里在这里同样开源,阿里因为在线上有很多的用户,包括影像处理、移动跟踪做了GPU加速。这就是创新价值。
多模使得PG这个数据库得以满足那些你曾经想都不敢想的需求。
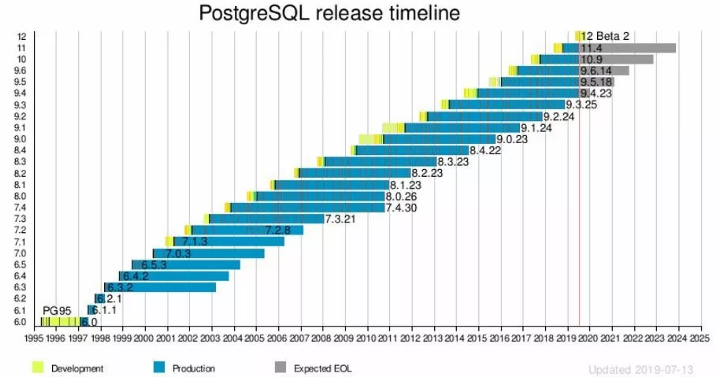
上图展示的是PG版本发布节奏,如果每年股票是这样涨的话大家肯定很开心。作为背后没有商业公司没有驱动的开源数据库,PG每年发一个大版本,每个大版本会持续维护五年,有组织有纪律就是不一样。
PG 11是去年发的,有什么新特性?在此说明一下,我这里说的特性全部基于PG自己,比如基于11以前的版本,其实有很多功能很早之前就已经支撑。
1)分区表增强
hash分区;
支持触发器;
支持默认分区;
允许修改分区字段。
2)并行计算增强
对业务完全透明的并行计算,几乎覆盖所有的场景,平均20倍的提升。
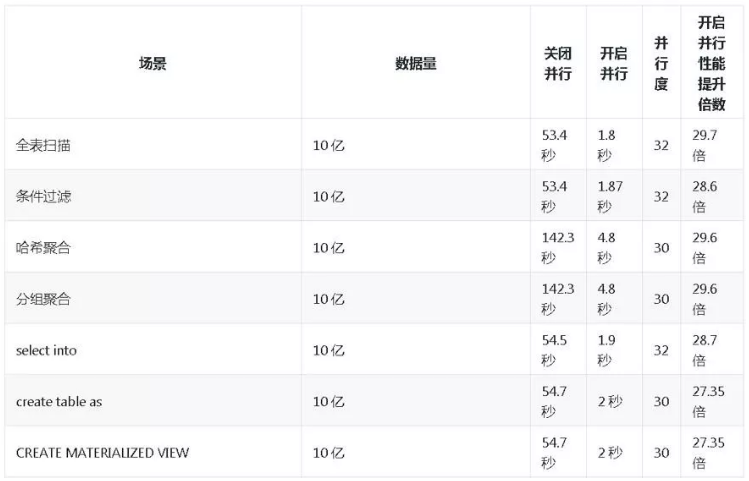

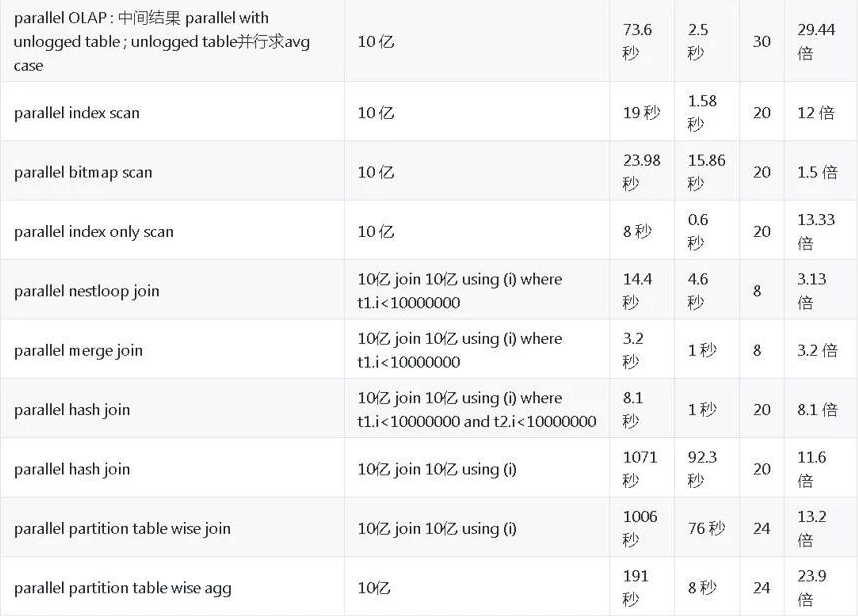
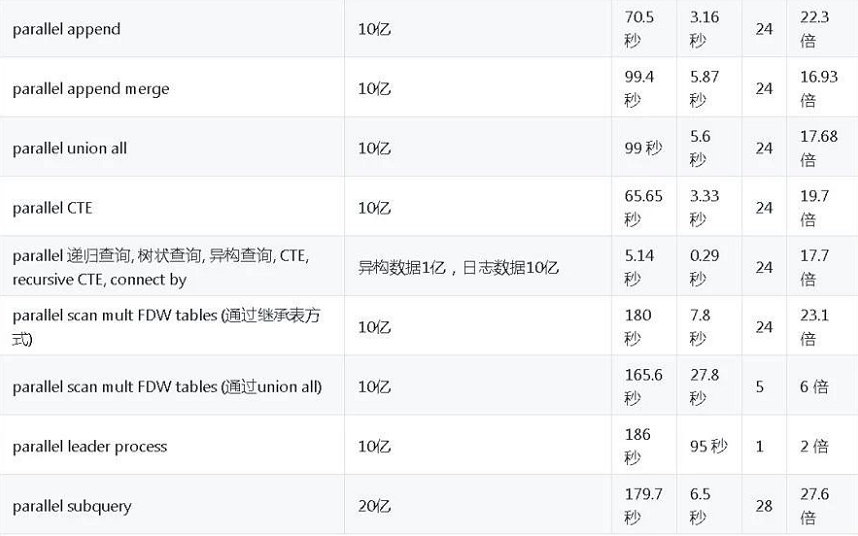
以上这个CASE数据量10亿的表,大家觉得10亿做排序要多久?不到3秒,不开并行需要70多秒。
什么时候要用并行计算?通常是实时分析,复杂查询,马上就要看到结果,原来需要T+1,现在就想做实时。
我们来看一下这些CASE,第一个是最简单的全表扫描,要将近1分钟。开并行只需要1.8秒。
哈希聚合,因为我们做分析一定会涉及到聚合,处理大量的数据,有哈希聚合、分组聚合。10亿记录的聚合需要花多少时间?5秒!不开并行需要140多秒。
做数据分析处理一般流程比较长,会有中间结果。这些中间结果可能是通过create table as这种方式出来的,这种操作能不能支持运行?也可以。同样也是10亿的数据量,差不多1.9秒。
创建索引,想不想很快完成?比如说这个索引膨胀,你想快速重建索引发现性能不行,10亿记录不带并行将近1000秒,开启并行后只需要252秒。
关于聚合的话,数据库会提供一些聚合函数,比如说平均值、标准方差,有些时候发现数据库提供聚合的方式不够用,不能满足你的业务要求。所以的话需要自定义聚合,自定义聚合操作也支持并行,这边也做了两个测试,一个求(count distinct)个数,另一个求count distinct数组元素个数。分别从300,100秒降到了8秒,3秒。
另外还进行了其他复杂查询(join、cte、subquery、排序、分区查询等),不再一一赘述,性能平均提速20倍左右。
3)btree index include索引叶子附加属性
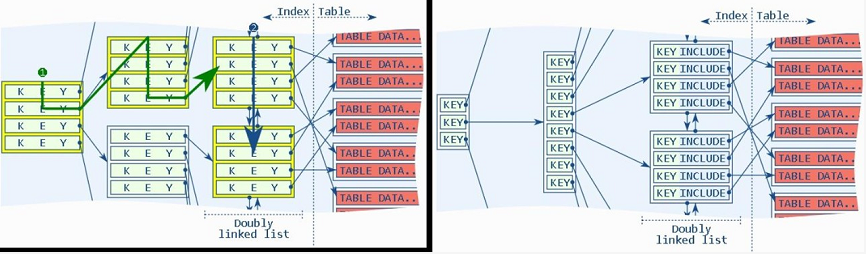
这个特性比较有意思,创建索引的时候一般怎么做?制定字段放进去,这些字段是我要查的。我这里举一个例子说,用非索引组的表,数据怎么存放?写进来没有任何顺序。
比如说有这样的业务做移动对象跟踪,共享单车,我们在手机里可以看历史轨迹,由上报的点组成。一般来说行程会涉及到上千个点。上报的数据是一条一条插进来的,这个世界有很多人同时骑车,也就是说很多人都在上报数据。你去查某一笔订单的轨迹,我们怎么通常怎么优化?在订单号加索引,感觉挺快的。但是有没有想过这个问题在那里?你的数据是无序存储,1000条记录可能是分布在1000个数据块,如果同时有大量并发查询可以把IO打满,即使这个数据在内存,也很容易触达内存带宽上限。
最后怎么解决这个问题?通常建个合索引,可以查出来。当然可以了,但是这里出现另外一个问题,这个Key在索引page的每个层面都是多个Key,他的这种split概率就会增加。但是实际上查询条件就是驱动列,就是你的订单号的哪一列。所以实际上可以创建索引的时候还是用订单号,但是我把你的时间放到leaf page,同一个订单的附加字段的数据被放到了同一个订单所在的叶子里面。这个时候来查询,因为这个数据一千个点只落在三五数据块。Include index相比较索引组织表的好处:我可以创建很多个按你的要求来的索引组织,好像同一份数据有很多数据组织结构一样。然而索引组织表只有一种结构。
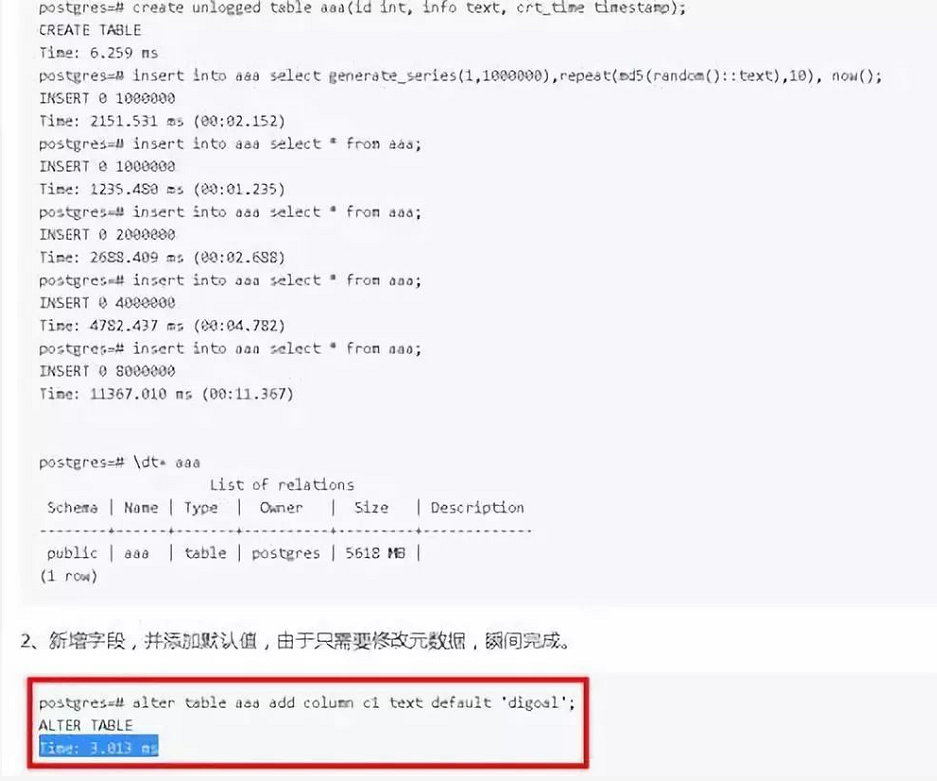
4)添加字段(含默认值)更快
以前添加字段不加否认值就是改一个原数据,以前加默认值做table rewrite所以慢。现在我们会变成甭管加什么字段,甭管是否包括默认值,总之瞬间完成。对用户特别友好。
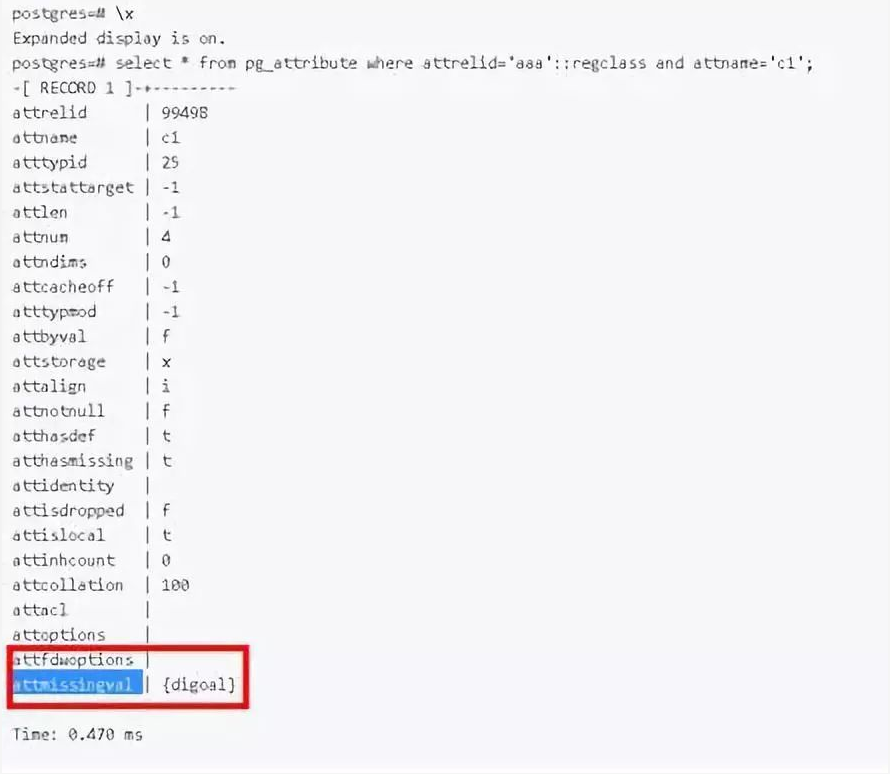
5)支持存储过程
在存储过程中,支持子事务提交。
CREATE [ OR REPLACE ] PROCEDURE
name ( [ [ argmode ] [ argname ] argtype [ { DEFAULT | = } default_expr ] [, ...] ] )
{ LANGUAGE lang_name
| TRANSFORM { FOR TYPE type_name } [, ... ]
| [ EXTERNAL ] SECURITY INVOKER | [ EXTERNAL ] SECURITY DEFINER
| SET configuration_parameter { TO value | = value | FROM CURRENT }
| AS 'definition'
| AS 'obj_file', 'link_symbol'
} ...
1)AM接口
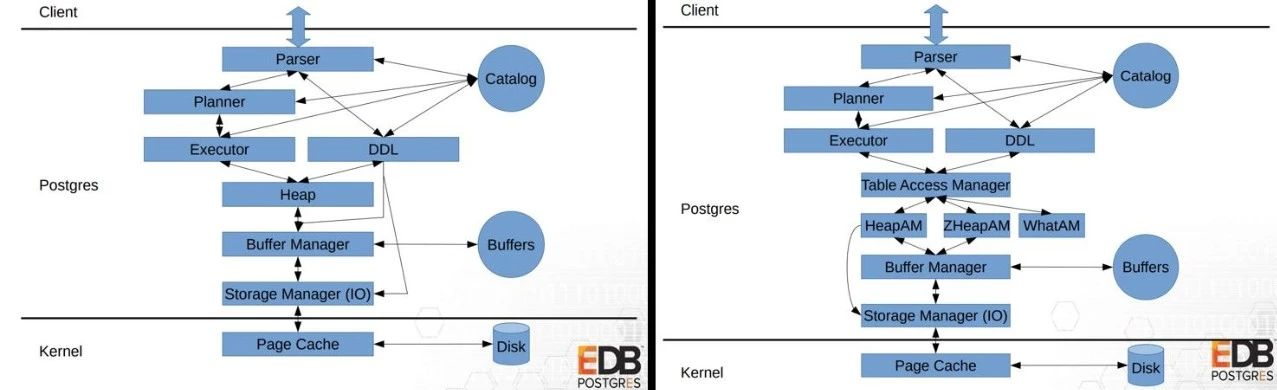
如上图所示,左边是12以前的版本,右边是12版本。12中间加了一层访问方法,这里面有索引方法或表访问方法,剥出来的好处就是我们可以在这个地方加新的数据存储结构,例如加内存表、列存表,压缩表等,都可以在这一层去做。
所以就有了列存的引擎,这里举两个例子,zedstore(列存)和zheap(支持回滚段)。列存压缩率高,支持向量计算,非常适合做批量计算,分析领域的性能提升很明显。
第二就是zheap,把回滚段从数据存储剥离出来,旧的版本拷贝到回滚段去,查到过去的版本去回滚段查,减少膨胀问题。
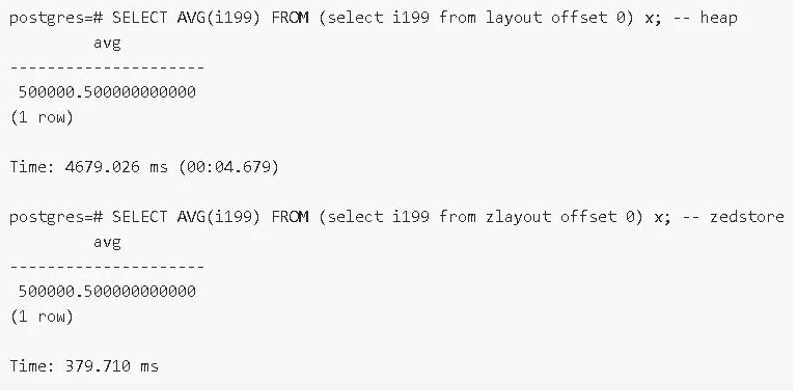
2)分区表-大量分区性能提升
原生分区(包括11的版本)分区很多有性能问题,12这一块已经优化掉,在1000个分区时,查询有提升400多倍。分区越多,性能提升越明显。
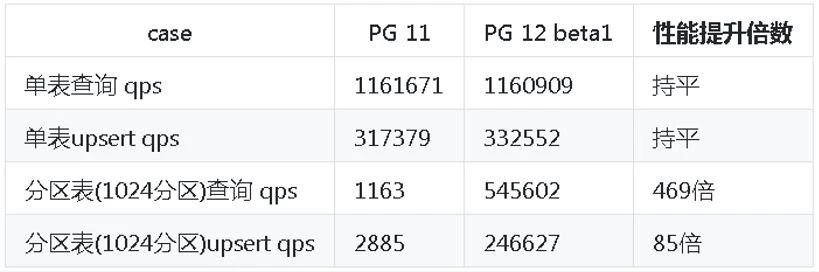
3)GiST index include索引叶子附加属性
正轨迹,时空搜索;
按结果集(索引)聚集存储,消除回表IO放大。
4)CTE 物化、非物化
物化的下推,在12版本里面可以指定要不要物化,如果是物化的话,物化的子句跟外面完全隔离,相当于这一层单独计算。如果指定不要物化,那么优化器会考虑子句外面的条件,可以将条件传递给非物化子句,提前过滤,提高性能。

5)日志采样
日志采样,相当于之前做审计日志,你要么全开,要么全关。实际上有的用户要的是不要所有的采下来,比如说做排错,同类错误不需要都被记录下来,采样就可以了。又比如说查询访问量特别大,如果所有的sql全审计下来会影响性能。使用这个采样的功能,不会影响性能。
6)COPY WHERE
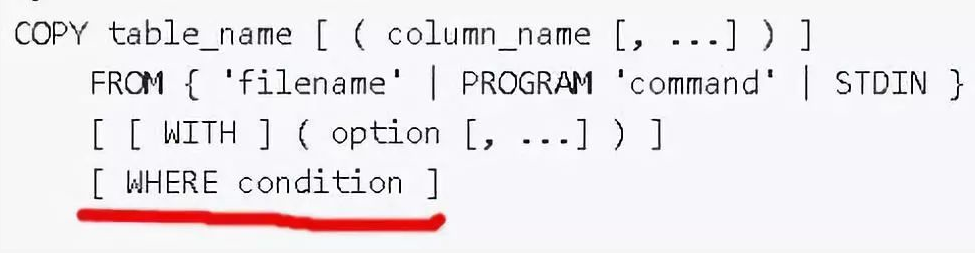

Copy时支持过滤条件,可以在导入数据时过滤不需要的记录。
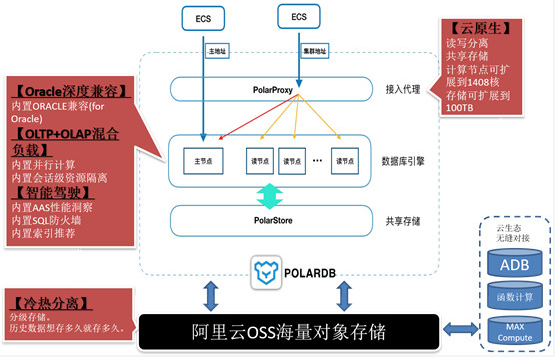
作为阿里巴巴自主研发的下一代关系型分布式云原生数据库,PolarDB目前兼容三种数据库引擎:MySQL、PostgreSQL、高度兼容Oracle语法。计算能力最高可扩展至1000核以上,存储容量最高可达100T。
兼容Oracle语法的引擎:高度兼容Oracle语法,降低Oracle迁移风险、缩短迁移周期,助力企业快速替换Oracle,进入云智能时代。
兼容PostgreSQL的引擎:完全兼容PostgreSQL,支持计算与存储分离、独立伸缩,存储按量付费。业务透明读写分离(该项功能开发中)。适合中大型企业核心业务场景。
感兴趣的朋友可到阿里云官网了解更多详情。
PPT下载链接:https://pan.baidu.com/s/1tdhyP2W9VzGY1PTDm6fWAw








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721