
由于read、write、update、delete是数据库中最主要且频繁进行的操作,所以并发执行这些操作时不被阻塞则显得非常重要。
为了达到这种目的,大部分数据库使用多版本并发控制(Multi-Version Concurrency Control)这种并发模型。这种模型能够将竞争减少到最低限度。
一、MVCC是什么
Multi Version Concurrency Control (MVCC)是这样的一种算法:通过对同一个对象维护多个版本,提供一种很好的并发控制技术,这种技术能够使READ和WRITE操作不发生冲突。
这里的WRITE指的是UPDATE和DELETE,不包含Insert是因为新插入的记录可以通过各自的隔离级别进行保护。每个WRITE操作使对象产生一个新版本,每个并发读操作依赖于隔离级别读取对象不同的版本。
由于READ和WRITE操作同一个对象的不同版本,所以这些操作不需要将对象完全锁住,因此这些操作能够并发执行。当然当两个并发事务WRITE同一个记录时,这些锁竞争还是会存在的。
当前大部分数据库系统都支持MVCC。这个算法的核心是对相同对象维护不同版本,因此不同数据库创建并维护多版本的方式不同,其实现方式也不同。相应地,数据库操作和数据存储也发生变化。
实现MVCC最常见的方法:PostgreSQL使用的方法、InnoDB和Oracle的使用方法。下面我们会详细讨论PG和InnoDB的实现方式。
二、PostgreSQL中的MVCC
为了支持多版本,PG对每个对象(PG术语:Tuple)增加了额外的字段:
xmin:进行插入或更新操作事务的事务ID。UPDATE中,对tuple的新版本分配该事务ID;
xmax:进行删除或更新操作事务的事务ID。UPDATE中,对当前存在的tuple分配该事务ID。新创建的tuple,该字段默认为null。
PostgreSQL将所有数据存储在HEAP中(每页默认8KB)。新记录的xmin为创建该记录的事务的事务ID;老版本(进行update或delete)其xmax为进行操作的事务的ID。会有一个链表将老版本和新版本连接起来。在回滚的过程中,老版本记录可以被重用;依赖于隔离级别,READ语句读取一个老版本记录进行返回。
例如下面两条记录:T1(值为1)、T2(值为2),通过下面3步对记录的创建进行演示:
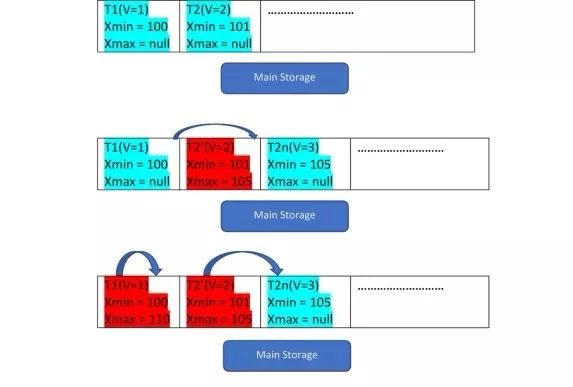
从图中可以看出,数据库中初始时存在两个记录:1和2。
第二步,将2更新为3。此时创建一个新值,并存放到同一个存储区域的下一个位置。老版本2为其xmax分配该事务的ID,并且指向最新的版本记录。
同理,第三步,当T1被删除时,对记录进行虚拟删除(为其xmax分配当前事务ID),该操作不存在创建新记录版本。
下面,通过实例讲解每个操作如何创建多版本,不用加锁如何实现事务的隔离级别。下面例子中使用默认隔离级别“READ COMMITTED”。
三、INSERT
每次insert一个记录,都会新创建一个tuple并将其存储到表文件的页中。
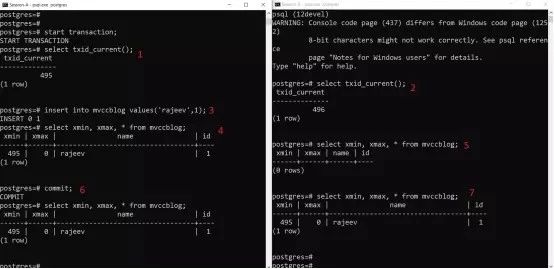
可以看到:
Session-A开启一个事务,其事务ID为495;
Session-B开启一个事务,其事务ID为496;
Session-A插入一个tuple,存储到HEAP;
新tuple的xmin为495,而xmax为null;
由于Session-A的事务没有提交,session-B看不到第3步插入的值;
Session-A提交
都可以看到新插入的tuple。
四、UPDATE
PostgreSQL的UPDATE不是“IN-PLACE”更新,不会将现有对象更新替换为新值,而是新创建一个新对象。因此UPDATE涉及以下几步:
将当前对象标记为deleted;
插入对象的一个新版本;
将对象的老版本指向新版本。
因此,即使许多记录保持不变,HEAP也会占用空间,就像新插入另一个记录一样。

如上所示:
Session-A开启一个事务,其事务ID为497;
Session-B开启一个事务,其事务ID为498;
Session-A更新一个现有记录;
Session-A可以看到tuple的最新版本而Session-B看到另一个老版本。Session-A看到新记录的xmin为497,xmax为null;Session-B看到老版本xmin是495,xmax为497即Session-A的事务ID。这两个tuple版本都存在HEAP中,如果空间允许甚至存在同一页中;
Session-A提交事务,老版本消失;
现在所有会话都可以看到记录的同一个版本。
五、DELETE
DELETE操作和UPDATE类似,只是不会添加一个新版本。如UPDATE,只是将当前对象标记为已删除。
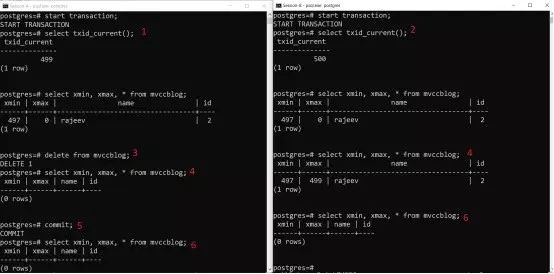
Session-A开启一个事务,事务ID为499;
Session-B开启一个事务,事务ID为500;
Session-A删除现有记录;
Session-A看不到当前事务已删除的记录;Session-B看到老版本,其xmax为499,499的事务删除的该记;
Session-A提交事务,老版本记录消失;
所有会话都看不到之前的老版本。
可以看到,这些操作都不会直接删除现有记录,如果需要会添加一个附加版本。
我们来看看SELECT在多版本中怎么执行:依赖于隔离级别,SELECT需要读取tuple的所有版本直到找到合适的tuple。假设有一个tuple T1,被更新为新版本T1’,然后再被更新为T1’’:
SELECT操作进入这个表的heap中,首先检查T1,如果T1的xmax事务已提交,查找该tuple的下一个版本;
T1’也被提交,查找下一个版本;
最后找到T1’’看到xmax未提交或者为null,然后T1’’的xmin可见,最后读取T1’’这个tuple。
可以看到需要遍历该tuple的3个版本才能找到合适的可见版本,直到VACUUM进程回收了打上delete标签的记录。
六、InnoDB中的MVCC
为了支持多版本,InnoDB对行记录又额外维护了几个字段:
DB_TRX_ID:插入或更新航记录的事务的事务ID;
DB_ROLL_PTR:即回滚指针,指向回滚段中的undo log record。
与PostgreSQL相比,InnoDB也会创建行记录的多版本,但是存储老版本的方式不同。
InnoDB将行记录的老版本存放到独立的表空间/存储空间(回滚段)。和PostgreSQL不同,InnoDB仅将行记录最新版本存储到表的表空间中,而将老版本存放到回滚段。回滚段中的undo log作用:用来进行回滚操作;依赖于隔离级别,进行多版本读,读取老版本。
例如,两行记录:T1(值为1),T2(值为2),可以通过下面3步说明新记录的创建过程:
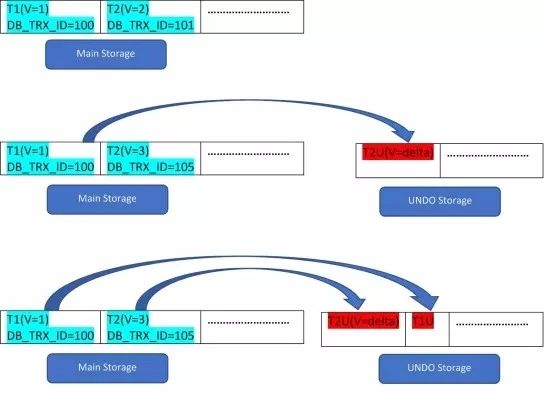
从上图可以看到,初始时,表中有两条记录1和2。
第二阶段,行记录T2值2被更新为3。此时记录创建一个新版本并替代老版本。老版本存储到回滚段(注意,回滚段中的数据仅包含更改值,即delta value),同时新版本行记录中的回滚指针指向回滚段中的老版本。和PostgreSQL不同,InnoDB更新是“IN-PLACE”。
同理,第三步,删除T1然后将其标记为虚拟删除(仅在行记录指定的一个bit位上打上delete标签)并在回滚段中插入一个对应的新版本。同样回滚指针指向回滚段中undo log。
从表面上看,所有操作表象与PostgreSQL相同,只是多版本在内部存储方式不同。
七、MVCC:PostgreSQL vs InnoDB
MVCC:PostgreSQL vs InnoDB
下面分析PostgreSQL和InnoDB的MVCC主要不同在哪几方面:
PostgreSQL仅更新tuple老版本的xmax,因此老版本的大小和相应插入的记录大小相同。这意味着,如果一个older tuple有3个版本,那么他们大小都相同(如果更新的值大小不同,每次更新时实际大小就不同)。
InnoDB的老版本存储到回滚段,且比对应的插入记录小,因为InnoDB仅将变化的值写到undo log。
INSERT时,InnoDB会向回滚段写入额外的记录,而PostgreSQL仅在UPDATE中创建新版本。
回滚时,PostgreSQL不用任何特定内容,需注意老版本的xmax等于update该记录的事务ID。因此在并发快照中该记录认为是alive的直到该事务ID的事务提交。
而InnoDB,一旦回滚,需要重新构造对象的老版本。
PG中,老版本占用的空间仅在没有并发快照使用时才可以被回收,此时被认为dead。然后VACCUM可以回收空间。VACCUM可以手动触发也可以依赖于配置在后台任务中触发。
InnoDB的undo log分为INSERT UNDO和UPDATE UNDO。事务提交后,就会立即释放INSERT UNDO。当没有其他并发快照使用时,才可以释放UPDATE UNDO。InnoDB没有显示VACUUM操作但是有类似的PURGE回收undo log。
如前所示,PostgreSQL延迟vacuum存在很大影响。即使频繁执行delete,它将会引起表膨胀造成占用的存储空间暴增。这还会造成到达一个点后,需要执行一个高额代价的操作VACUUM FULL。
即使所有记录都是dead状态,PostgreSQL的顺序扫描也会扫描对象所有的老版本,直到执行vacuum将dead的记录删除。这是PG中常见且经常讨论的问题。主要PG将一个tuple的所有老版本都存储到同一个存储区域。
而InnoDB,除非需要,否则不需要读取undo log。如果所有undo记录都已失效,那么只需要读取所有对象的最新版本既可。
PostgreSQL独立存储索引,并将索引连接到HEAP中的真实数据。因此即使没有更改索引,有时也需要更新索引。随后这个问题被HOT(Heap Only Tuple)解决,但是仍有限制,如果相同页空间不足,则退回到正常UPDATE操作。
InnoDB由于使用聚集索引,不会有这样的问题。
八、结论
PostgreSQL的MVCC有一些缺点,尤其是具有频繁UPDATE/DELETE负载时,会引起表膨胀。因此决定选择PG时,需要慎重配置VACUUM。
PG社区已经意识到这个问题,已经开始涉及基于undo的MVCC(暂命名为ZHEAP),我们在未来版本可以看到这个特性。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721