
作者介绍
伊翼,网名“小wing”,野生PG爱好者,从事数据库相关工作已近十年,目前供职于全球最大的通讯设备供应商。
原标题:《当FDW遇上GO》
FDW(Foreign Data Wrapper)是PostgreSQL(下文简称PG)中一项非常有意思的技术,通过它可以将PG变成一个通用的SQL引擎,使得用户可以通过SQL访问存储在PG之外的数据。本文将介绍一下PG的FDW,并探讨一下用GO语言来实现一个第三方数据源的FDW的经验与实践。
一、FDW的前世今生
随着一个企业/组织的IT体系的日益增大,往往会不可避免地在多个应用之间需要进行数据共享与交换。
通常我们希望这些应用的DAC(Data Access Code)能够简单直观一些。然而不幸的是,即使是在同一个企业或组织的内部,不同应用所涉及到的数据往往会存储在不同的数据源中——可能是不同厂商的DBMS产品,也可能是根本不支持SQL的异构数据存储中。因此,往往随着应用规模的增大,多个应用之间数据访问关系就会变得像下图一样杂乱无章:

随着社会的信息化推进,上述问题逐渐成为业界的共性课题。因此数据库业界在2001年对于该课题给出了一个积极的响应,这就是SQL/MED扩展标准(该标准的第一个版本为 ISO/IEC 9075-9:2001,目前最新版本为 ISO/IEC 9075-9:2016)。
SQL/MED标准旨在建立一个解决此类课题的技术规范:即应用程序可以通过统一且标准的方式(SQL)去访问存储在不同数据源中的数据,且数据源本身对应用透明。在理想情况下,SQL/MED标准希望达成的效果如下图所示:
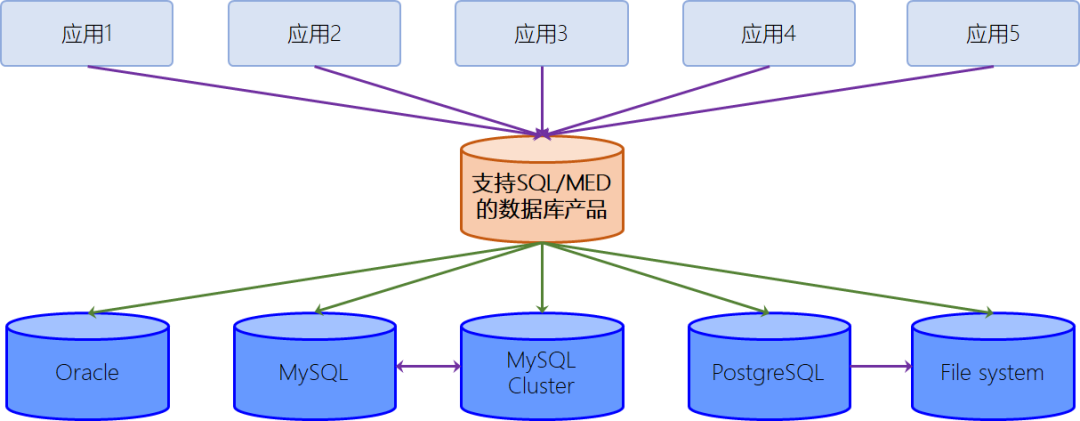
需要注意的是SQL/MED标准对于解决上述问题实际上定义了两套技术规范,一个是Foreign Data Wrapper,另一个则是datalink 类型(它与PG中的dblink以及Oracle中的Database Link不是一回事,尽管其目的有相似之处)。
dblink:
https://www.postgresql.org/docs/10/static/dblink.html
Database Link:
https://docs.oracle.com/cd/B28359_01/server.111/b28310/ds_concepts002.htm
本文的剩余部分将主要围绕FDW来展开说明。
PG对于FDW的支持早在10年前就已经开始了。
社区从2009年推出8.4版本中首先就已经提供了对FDW的创建语句以及Foreign Server的创建语句的语法支持(但未实现实际的功能)。到了2011年社区推出9.1版本时正式对外公开了支持FDW功能的内部接口,从而让扩展的编写者可以利用这些接口为不同的数据源编写FDW的实现。并且在接下来的7年内,社区每一次PG的版本升级都会带来FDW的功能提升——尽管这些功能增强不一定总是体现在语法层面。
比如,在最初的版本中,FDW仅仅只能将远端数据源的数据原封不动地拉至PG中;但到了最近的两三个版本中,借助FDW已经可以实现将更多地运算(如JOIN,聚合等)下推至远端数据源,并能够对远端数据源的数据进行更新。
注: 前提是远端的数据源(特别是异构数据源)本身要能够具备这些被下推的能力(JOIN、 聚合、数据更新等等)
截止到目前为止,全世界已有成百上千种数据源有了相应的FDW实现,从传统的文件系统到各种新型的Nosql数据库,甚至还包括互联网上的Web Service。在PG社区官方的wiki页中罗列了一部分较常见的数据源的FDW。
PG社区官方wiki页:
https://wiki.postgresql.org/wiki/Foreign_data_wrappers
另外值得一说的是,尽管基于SQL/MED标准的FDW技术的初衷是为了统一异构数据源的访问方式。但是,随着这些年PG的FDW内置功能(core functionality)支持将越来越多的运算下推到远端执行,同时还有一个获得社区官方支持的用于访问远端PG服务器的FDW扩展postgres_fdw也变得越来越强大。
postgres_fdw:
https://www.postgresql.org/docs/10/static/postgres-fdw.html
PG社区核心团队的大佬 Bruce Momjian在2016年给社区写了一封邮件提议了一个基于FDW技术的分布式水平扩展方案(即通称的所谓“Sharding”方案),与此同时,老爷子还撰写了一份PPT专门阐述这个想法。基于“对现有PG代码改动最小”这一原则,目前社区已经基本上认可了基于FDW的Sharding方案作为PG源生的分布式实现方案。
邮件链接:
https://www.postgresql.org/message-id/20160223164335.GA11285%40momjian.us
PPT链接:
http://momjian.us/main/writings/pgsql/sharding.pdf
PG源生的分布式实现方案:
https://wiki.postgresql.org/wiki/Built-in_Sharding
事实上,基于FDW的Sharding方案在实现和落地方面,日本技术者显然走得很远。比如,实现FDW核心功能的patch最早就是由日本的花田茂提出的。
参考链接:
https://www.postgresql.org/message-id/20101125163436.96F6.6989961C%40metrosystems.co.jp
2017年,NTT DATA分享了他们在基于PG 9.6做的Sharding方案——简而言之就是PG的表继承 + postgres_fdw。其概念和架构分别如下所示:
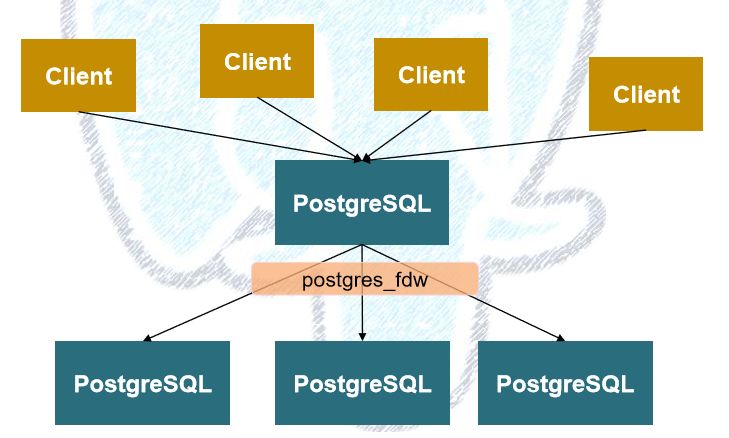
概念图
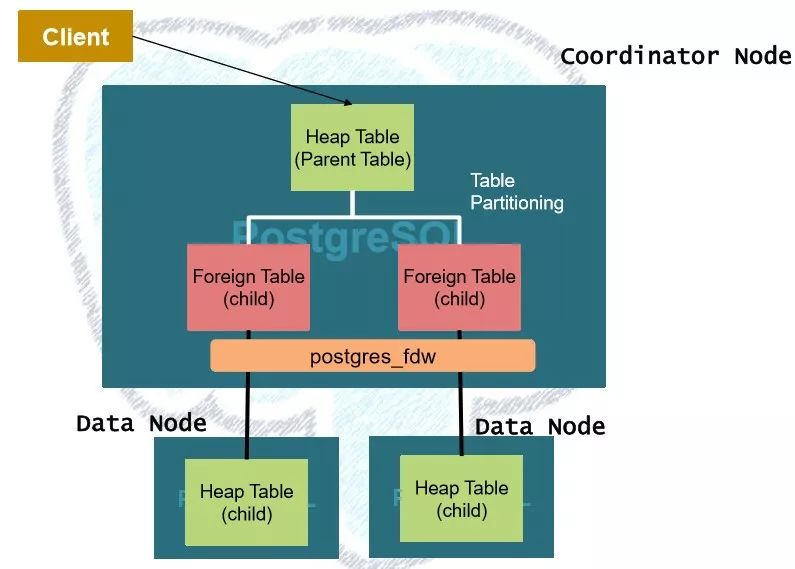
架构图
FDW技术应用到了Sharding上,这恐怕也是SQL/MED标准制定者最初没有设想到的吧。但既然社区已经选取FDW这条技术路线作为PG的内置Sharding方案,那么在可预见的未来,社区必然会继续完善FDW的核心功能并积极地增强postgres_fdw扩展的功能。
二、揭秘FDW
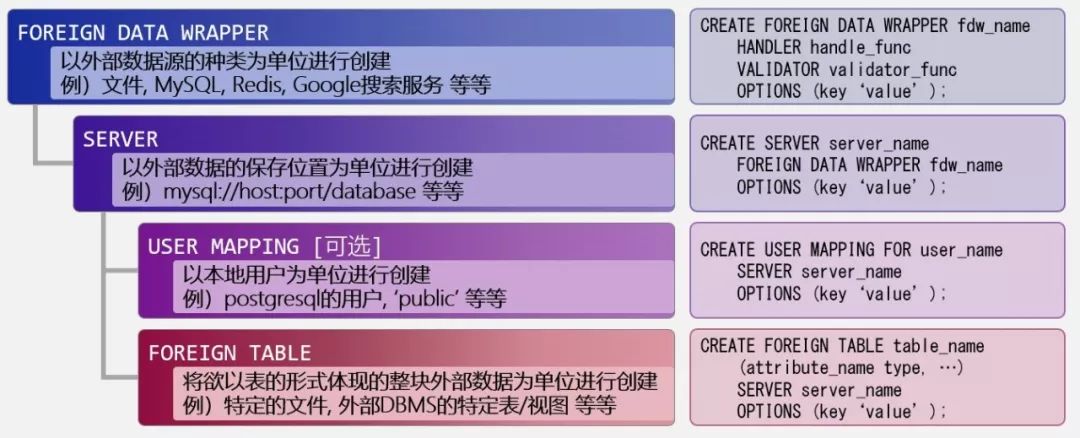
使用FDW的核心就在于使用外部表(FOREIGN TABLE)。尽管面向不同数据源的FDW实现各有不同,但是受益于SQL/MED定义的标准,创建不同数据源的外部表的方法都是一样的,分别需要在PG端依次创建以下几个数据库对象:
向PG安装某个数据源的FDW扩展;
使用CREATE FOREIGN DATA WRAPPER语句创建该数据源的FDW对象;
使用CREATE SERVER语句创建该数据源的服务器对象;
使用CREATE USER MAPPING语句创建外部数据源用户与PG用户的映射关系(这一步是可选的。比如外部数据源根本没有权限控制时,也就无需创建USER MAPPING了);
使用CREATE FOREIGN TABLE语句创建外部表。
之后就可以使用 SELECT 语句按照访问普通表的方式访问外部表;如果该数据源支持写操作且它的 FDW 也已实现支持写操作的相关接口,则也可以使用 INSERT,UPDATE 或 DELETE 语句去更新外部表。
上述过程中,运用FDW创建的数据库对象可以简要地用下图来概述:
上一小节介绍了FDW的通用用法,这里将简单说明一下该用法中提及的几个数据库对象的作用:
FOREIGN DATA WRAPPER对象
对应的DDL语法:
https://www.postgresql.org/docs/10/static/sql-createforeigndatawrapper.html
是一个纯粹的抽象概念,创建该对象的实质是向PG注册了某个数据源的FDW所实现的两个自定义函数——该FDW所实现的所有接口的注册函数(在CREATE FOREIGN DATA WRAPPER语句中称为HANDLER)以及该FDW的所支持的选项验证函数(在CREATE FOREIGN DATA WRAPPER语句中称为VALIDATOR)。
该对象被创建后,语句中制定的HANDLER与VALIDATOR会被添加至系统表pg_proc(保存所有自定义函数的元数据)中,且两者的OID以及该FOREIGN DATA WRAPPER对象的名称与OID一同被保存至系统表pg_foreign_data_wrapper中。
pg_proc:
https://www.postgresql.org/docs/10/static/catalog-pg-proc.html
pg_foreign_data_wrapper:
https://www.postgresql.org/docs/10/static/catalog-pg-foreign-data-wrapper.html
通常FOREIGN DATA WRAPPER对象的创建过程是直接包含在了安装FDW扩展的CREATE EXTENSION语句中,从而在安装时被自动执行,无需数据库用户在使用中单独执行。
需要补充说明的是,HANDLER的作用是将该FDW实现的一系列fdw回调函数的地址打包返回给PG,从而使PG之后访问外部表时可以调用这些访问外部数据的函数。而所谓的fdw回调函数则是指PG手册所提及的下述接口的实现:
GetForeignRelSize
GetForeignPaths
GetForeignPlan
BeginForeignScan
IterateForeignScan
EndForeignScan
等等......
参考链接:
https://www.postgresql.org/docs/10/static/fdw-callbacks.html
关于这些回调函数的作用,会在后文介绍,此处暂略。
FOREIGN SERVER对象
对应的DDL语法:
https://www.postgresql.org/docs/10/static/sql-createserver.html
表示的是外部数据源的数据库对象,比如可以在CREATE SERVER时通过选项指定数据库所在服务器的IP地址等信息。FOREIGN SERVER对象被创建后,相关的元数据被保存在系统表pg_foreign_server中。
pg_foreign_server:
https://www.postgresql.org/docs/10/static/catalog-pg-foreign-server.html
FOREIGN TABLE对象
对应的DDL语法:
https://www.postgresql.org/docs/10/static/sql-createforeigntable.html
将外部数据源的数据组织为表的形式,这样的表就被称作为外部表,它可能对应的是外部异构RDBMS的一张表,也有可能是文件系统上的某一个文件、一个建立在企业网中的微服务,或是一个互联网上的Web API。具体如何对应,取决于这个数据源的FDW实现。
当外部表对象被创建后,它与PG中的普通表一样,元数据都会被保存在系统表pg_class中,只是它的relkind字段会以“f”进行标识;同时,该表在也会在系统表pg_foreign_table被保存一条记录,它存储了该表在pg_class的OID与该表所属的FOREIGN SERVER的OID的对应关系。
pg_class:
https://www.postgresql.org/docs/10/static/catalog-pg-class.html
pg_foreign_table:
https://www.postgresql.org/docs/10/static/catalog-pg-foreign-table.html
从9.5开始,PG提供了一个新的语法IMPORT FOREIGN SCHEMA支持用户批量导入外部数据源的外部表,以省却一个一个CREATE FOREIGN TABLE的繁琐。当然,前提是该数据源的FDW实现中需要实现IMPORT FOREIGN SCHEMA所对应的回调函数。
有了上述外部对象相关的元数据支持,当一个查询试图访问外部表以获取外部数据源的数据时,FDW在整个查询的执行过程中就可以发挥下述作用:
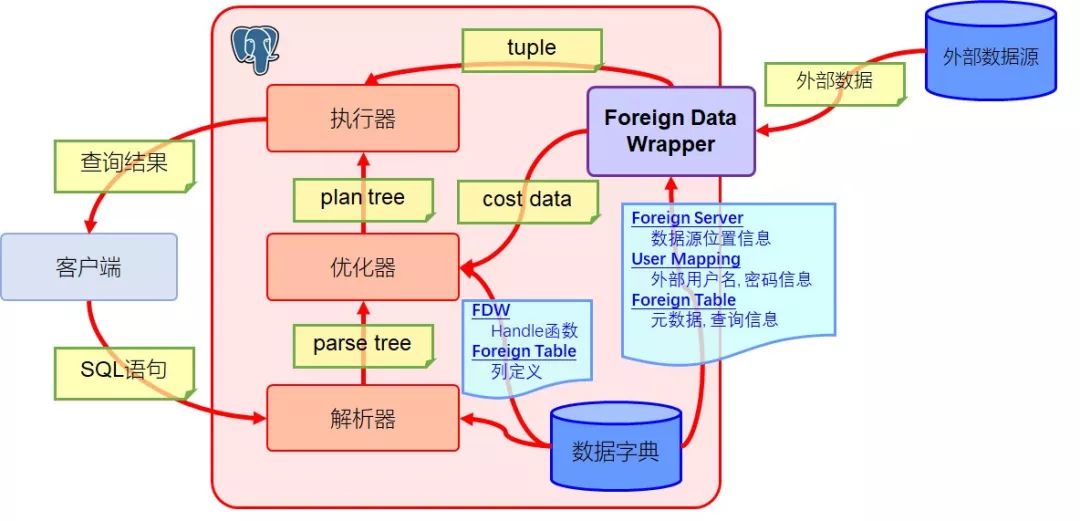
而在此图中,FDW得以介入整个执行过程的奥秘就在于回调函数。
如上文所说,一个FDW实现的核心就是实现一组回调函数。有了这些回调函数的帮助,在查询外部表对象的执行过程中就可以将运行逻辑切换至自定义的扩展代码中,进而遵照PG的内部机制实现对外部数据源的访问。
截止到PG 10.0,PG提供的FDW回调函数接口已有20余个。FDW的实现者需要根据外部数据源自身的能力(比如是否支持写操作,以及是否支持在外部数据源端执行JOIN操作等等)对这些接口有选择性地予以实现。
这些接口中,最核心的接口有7个。无论外部数据源自身能力如何,这7个接口是实现通过外部表对象访问该数据源的必须接口。它们的接口定义如下:
typedef void (*GetForeignRelSize_function) (PlannerInfo *root, RelOptInfo *baserel, Oid foreigntableid);
typedef void (*GetForeignPaths_function) (PlannerInfo *root, RelOptInfo *baserel, Oid foreigntableid);
typedef ForeignScan *(*GetForeignPlan_function) (PlannerInfo *root, RelOptInfo *baserel, Oid foreigntableid, ForeignPath *best_path, List *tlist, List *scan_clauses, Plan *outer_plan);
typedef void (*BeginForeignScan_function) (ForeignScanState *node, int eflags);
typedef TupleTableSlot *(*IterateForeignScan_function) (ForeignScanState *node);
typedef void (*ReScanForeignScan_function) (ForeignScanState *node);
typedef void (*EndForeignScan_function) (ForeignScanState *node);
我们知道, 一条查询语句在PG中会经历三个大的阶段:
Parser: 包含对SQL的语法解析,语义校验,查询重写;
Optimizer: 生成查询计划;
Executor: 按照经典的火山模型执行查询计划的算子并向上“吐”数据。
火山模型:
http://dbms-arch.wikia.com/wiki/Volcano_Model
上述这七个回调函数主要在Optimizer和Executor阶段进行“介入”。如下所示:
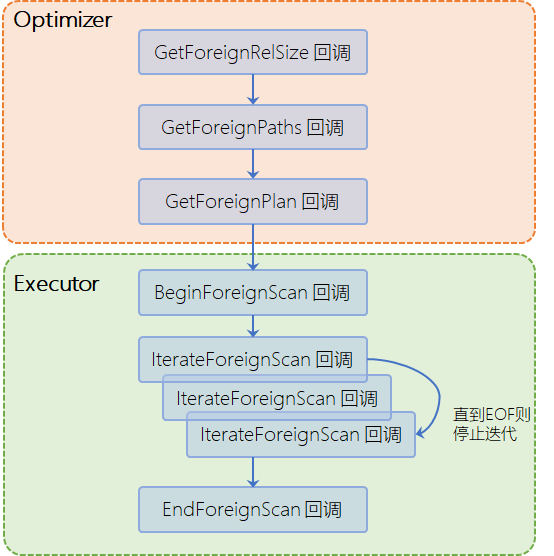
需要注意的是,上图仅仅是显示这些回调函数被调用的时序顺序。图中的箭头并不意味着两个回调之间存在相互调用关系。事实上这些回调函数都是由PG的Optimizer和Executor进行调用。
这七个回调函数详细的调用时机以及作用总结如下:
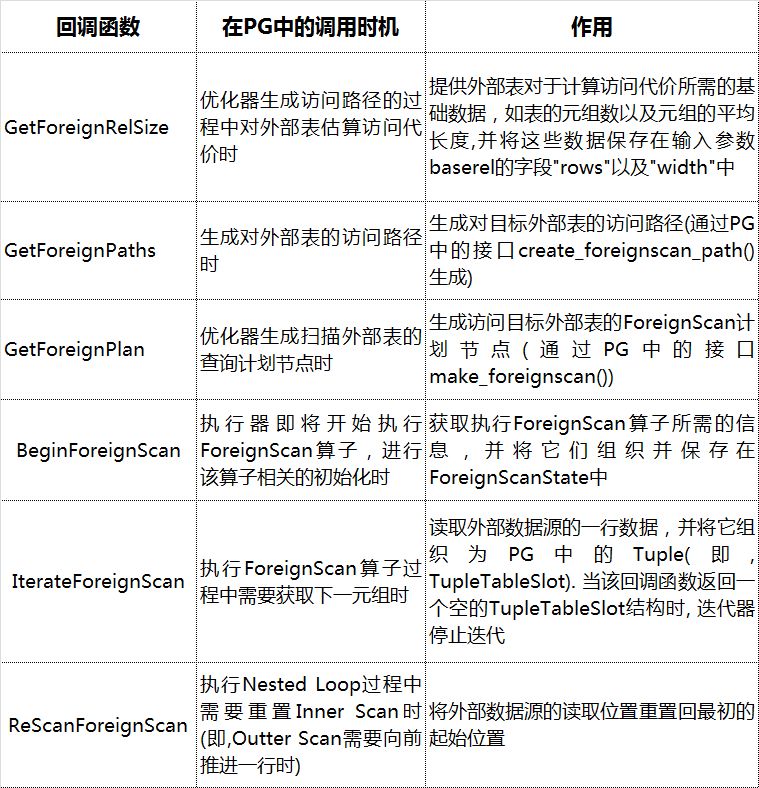
如上文所述,回调函数本身是由PG来调用的,各回调函数之间并不会产生彼此的互相调用。因此就产生了一个衍生的问题——如果在FDW的实现想要在这些回调函数之间传递数据怎么办?PG在设计回调函数的接口时也充分考虑到了这一点:
Optimizer阶段
在Optimizer阶段执行的三个回调函数都会传入一个RelOptInfo结构体作为输入参数,该结构体专门有一个字段可供FDW使用:
typedef struct RelOptInfo {
...(上略)...
void *fdw_private;
...(下略)...
} RelOptInfo;
因此如果FDW的实现需要在Optimizer阶段的回掉函数间传递数据时,只需要自行申请内存存储临时数据后将指针挂在上述字段即可。
Executor阶段
在Optimizer阶段执行的回调函数都会传入ForeignScanState结构体。在PG中,各种Scan算子都会有一个对应的State结构体,用于存放算子相关的状态数据。考虑到不同数据源的FDW实现可能会需要带一些自定义数据,因此ForeignScanState结构体也专门有一个字段可供FDW使用:
typedef struct ForeignScanState
{
ScanState ss;
List *fdw_recheck_quals;
struct FdwRoutine *fdwroutine;
void *fdw_state; /* 存放各FDW实现的私有状态数据 */
} ForeignScanState;
与RelOptInfo的fdw_private字段类似,FDW的实现只需申请内存存储临时数据后将指针挂在fdw_state字段即可。
从Optimizer到Executor
如果FDW的实现中想把一些数据从Optimizer阶段带到Executor阶段,会比上面的两个途径略显复杂。
在PG 9.5中,这样的私有数据传递是通过下述方法实现的:
存入私有数据
在回调函数GetForeignPlan()的实现中必须为后续的Executor创建一个ForeignScan算子(这也是GetForeignPlan()最主要的作用)。由于ForeignScan中有一个fdw_private字段,因此FDW的私有数据可以通过该字段进行存放。
不过,与RelOptInfo结构体不同的是,ForeignScan算子的fdw_private字段是一个List *类型。这是考虑到了FDW的实现中可能想传多个毫无关联的数据结构给后续的Executor,那么如果仅仅是一个void *势必就要重新做内存分配并且还得做拷贝操作,但实际上FDW只是希望找地方挂一下私有数据即可,因此用List *的话,对于传递多个结构体的情况将更为方便。
只是,List *里按什么样的顺序去挂怎样的数据,这是PG的接口无法定义的了。这必须依赖于FDW的实现自己去严格按照挂数据的顺序以及类型去取数据,这样的接口设计其实是耦合度较高的。不过除了这个方法似乎也没有更好的方法,因此直到现在的PG 10.3版本中,ForeignScan算子的fdw_private字段仍然保持着这样的设计。
获取私有数据
在Executor执行BeginForeignScan()回调函数时,利用传入的ForeignScanState结构体的ss字段(ScanState类型)访问其中的ps字段(PlanState类型)的plan字段(ForeignScan类型),进而获取到ForeignScan类型中挂着的存放私有数据的List,最后解开这个List即可获取在Optimizer阶段传递的私有数据。
以上介绍了执行对外部表查询时所涉及到的回调函数之间的数据传递方式,其他的回调函数之间的数据传递方式就此略过。
就这样,对于一个外部数据源而言,只需要实现了上述的7个回调函数,就可以在PG上用SQL语句对于该外部数据源进行简单的查询。
当然,如果要真的尝试去实现这些回调函数,还是需要通过PG的一些专门面向FDW提供的接口来与PG进行交互,比如在上一节中提及的make_foreignscan()和create_foreignscan_path()就属于这些接口;手册上的Foreign Data Wrapper Helper Functions章节也有一些关于实现FDW时可能会用到辅助函数的说明。
Foreign Data Wrapper Helper Functions章节:
https://www.postgresql.org/docs/10/static/fdw-helpers.html
此外,上文所说这些回调函数如果要让PG能够知晓且调用到,是需要有一个注册机制。这个注册机制就是通过上文提及的CREATE FOREIGN DATA WRAPPER语句中用HANDLER关键字指定的UDF函数来实现。这个UDF函数的逻辑很简单,参考一些现成的FDW实现即可,此处不再赘述。
三、如何用Go实现一个FDW
到目前为止,本文介绍了PG中的FDW的历史以及运行机制,接下来聊一个有趣的话题——如何用Go语言来实现一个FDW。
由于PG以C语言写成,因此其内部公开的接口(无论是FDW的回调函数接口还是供FDW使用的内部接口)都是面向C语言设计的,因此用C语言实现FDW是最自然的选择。
但是用C语言实现有着一个比较令人头痛的问题——开发效率低下。通常我们有可能需要基于一个Idea来为一个新的数据源编写一个FDW以实现PG与新数据源的对接,但是若用C语言编写FDW就很容易使我们迅速陷入一些实现的细枝末节,从而丧失了开始编写FDW时的趣味,这个问题主要是源于C语言在开发效率上的一些先天性不足:
需要编码者自行分配/释放内存;
字符串设计过于底层缺乏必要的抽象和封装,使得字符串处理必须小心翼翼;
标准库函数的功能过于薄弱,许多看上去很基础的功能要么必须由编码者重新造轮子,要么必须依赖来源并不是那么靠谱的第三方库。
为了将FDW的开发者从繁琐的底层细节中解放出来,广大PG爱好者也做了不少实践:比如有一个叫做"Multicorn"的FDW框架,它封装了FDW相关的底层细节使得开发者们可以用Python快速地编写FDW。尽管这是一个很棒的开源项目,但遗憾的是,这个框架依赖于PG的PL/Python,但这个组件往往并非在安装PostgreSQL时默认安装的,甚至在编译PG源码时,它也默认不会参与编译,而且它至今仍然不是一个受信的存储过程语言组件。
“Multicorn”参考链接:
http://multicorn.org/
PG的PL/Python:
https://www.postgresql.org/docs/10/static/plpython.html
考虑到Go语言与C语言之间相对友好的交互机制(比起Java的JNI机制要友好很多),而且相对于C语言的三个缺点,GO语言都可以在语法层面或者内置功能层面可以很好地应对,更何况在语法层面GO语提供了诸多类似defer、go routine等简化编码复杂度的利器,因此使用Go语言可以帮助我们相对快速地实现一个FDW。
需要注意的是,此处提及的使用Go语言编写FDW的概念严格意义上说应该是使用cgo来编写FDW。为了简单化概念,因此本文将继续使用"Go语言"来称呼,但需要牢记Dave Cheney所撰写 cgo is not Go。
cgo is not Go:
https://dave.cheney.net/2016/01/18/cgo-is-not-go
回调函数的cgo实现
由于实现FDW的核心就在于实现那一系列回调函数。参照cgo的官方介绍,我们用cgo实现FDW的回调函数时通常只需要做以下几件事情:
在实现回调函数的go文件中声明import "C",这是使用cgo所必须的;
按照回调函数的接口规格予以GO语言的函数定义。PG的回调函数接收的都是PG内部的数据类型,因此在定义函数时参数应依照cgo中映射C语言数据类型的规则进行声明;
将刚刚定义的GO语言函数的函数名按cgo的规则在注释中予以导出;
使用GO语言实现该回调函数的逻辑。
↑cgo的官方介绍:
https://github.com/golang/go/wiki/cgo
↓我的个人项目 douban_fdw:
https://github.com/xiaowing/douban_fdw
比如,在我的个人项目douban_fdw中,对于回调函数GetForeignRelSize_function,用cgo实现的代码示例如下:
//export doubanGetForeignRelSize
func doubanGetForeignRelSize(root *C.PlannerInfo,
baserel *C.RelOptInfo, foreigntableid C.Oid) {
var referredAttrs *C.Bitmapset
// Collect all the attributes needed for joins or final output.
targetlist := (*C.Node)(unsafe.Pointer(baserel.reltargetlist)) // TODO: member field of 'RelOptInfo' changed in 9.6
C.pull_varattnos(targetlist, baserel.relid, (**C.Bitmapset)(unsafe.Pointer(&referredAttrs)))
// Add all the attributes used by restriction clauses.
restrictNum := int(C.list_length(baserel.baserestrictinfo))
for i := 0; i < restrictNum; i++ {
rinfo := (*C.RestrictInfo)(unsafe.Pointer(uintptr(C.list_nth(baserel.baserestrictinfo, C.int(i)))))
C.pull_varattnos((*C.Node)(unsafe.Pointer(rinfo.clause)), baserel.relid, (**C.Bitmapset)(unsafe.Pointer(&referredAttrs)))
}
// check if the name of the referred attrs are valid
attributesRetrieved := referredFieldsValidator(foreigntableid, referredAttrs)
C.bms_free(referredAttrs)
baserel.fdw_private = Save(attributesRetrieved)
baserel.rows = C.double(MovieRankingTop250Num)
}
不过,虽然从道理上实现FDW的回调函数就这几个步骤,但实际实现起来,其中还是有不少坑的。而上述的示例代码正好体现了这一过程中几个最大的坑:
无法直接使用的PG接口
通常情况下,在cgo编程时我们可以用形如C.xxx的形式直接使用原本在C语言中定义的类型,函数等等。但是如果碰上了C语言的宏定义,这种方法就失效了。如果尝试用C.xxx来使用一个宏,将会引发一个编译错误。
这个问题会给我们使用PG的接口带来一定麻烦,比如对于PG中的List类型,PG的代码中提供了一个宏foreach来方便开发者遍历List:
#define foreach(cell, l)
for ((cell) = list_head(l); (cell) != NULL; (cell) = lnext(cell))
在原本PG代码中,则可以使用下述方式来方便地遍历List foreach (cell, list)
{
.../* ~(对当前遍历地元素进行处理, 代码略)~ */
}
但是在cgo实现中,上述宏无法使用,且就算将该宏展开后仍然有宏定义嵌套,因此不得不采用别的迂回方法来遍历List。在上文的示例代码中遍历List的方式就变成了下述形式——先获取元素个数,再挨个取第n个元素进行处理:
restrictNum := int(C.list_length(baserel.baserestrictinfo))
for i := 0; i < restrictNum; i++ {
rinfo := (*C.RestrictInfo)(unsafe.Pointer(uintptr(C.list_nth(baserel.baserestrictinfo, C.int(i)))))
...(代码略)...
}
此外, 除了极具代表性的foreach宏,PG代码中随处可见的ereport宏函数,heap_close宏函数,以及各种类型的SQLSTATE宏(如ERRCODE_FDW_ERROR)等都无法在cgo代码中直接使用,需要迂回解决。
指针类型的强制类型转换
在上文的示例代码中,有类似以下的代码:
这是由于PG的pull_varattnos()函数接收的是一个Node *类型,但如果直接用baserel.reltargetlist得到的是一个List *类型,因此需要做强制类型转换。
注:根据PG代码,这样的转换逻辑上是允许的,因为PG中大量的类型都是Node的派生类型。
但是,GO语言中并不允许指针类型之间的强制转换,如果不得不转的话必须用unsafe。Pointer类型进行过渡。这就造成了只要代码中涉及类似的强制类型转换,代码就会变得冗长。
符合cgo规范的GO指针传递
在上文第二章的第四点中,我们曾介绍过FDW的回调函数之间如何传递私有数据。由于我们是用Go语言来实现FDW的回调函数,因此很自然会涉及到一个问题:使用Go语言创建的私有数据(通常指结构体之类)如何进行传递?
本来这个问题不该成为一个问题,因为根据我们之前的描述,把GO语言的结构体挂在相应的PG数据类型中即可。然而很遗憾的是,从GO 1.6开始,cgo的规范对于GO运行时内存中的指针向C语言运行时传递进行了很严格的限制(详讯Rules for passing pointers between Go and C)。在此处的FDW回调函数之间传递私有数据这个场景下,我们无法直接将一个存在于GO运行时的指针直接挂在一个PG的结构体中并让其带着往下传递。
Rules for passing pointers between Go and C:
https://github.com/golang/proposal/blob/master/design/12416-cgo-pointers.md
这个问题的解决可以借鉴来自日本的GO语言大咖mattn所提供的一个解决方案(参考链接:https://github.com/mattn/go-pointer)。简而言之就是需要传递一个GO指针到C运行时中时,先利用cgo从C语言侧申请一个字节的内存,之后在一个全局哈希表中建立这个字节的地址与GO语言结构体的映射。这样在PG的数据结构的字段中保存的仍然是C运行时的地址,但当回调函数被调用,控制流程回到GO语言侧时,就可以通过映射关系顺着保存的C语言地址找到对应的GO语言结构体。
上文示例中的语句baserel.fdw_private = Save(attributesRetrieved)就是在利用mattn提供的解决方案做这样的映射传递。
不过,在mattn的解决方案中,对于全局哈希的访问是通过mutex来确保并发安全的。在应用到PG的场景时,由于一个会话对应于一个进程,因此这样的互斥是没有必要,可以去除。
如何构建
由于FDW的实现本质上就是一个PG的扩展( Extension ),因此FDW的构建首先应当寻求利用PG的Extension Building Infrastructure。
PG的Extension Building Infrastructure:
https://www.postgresql.org/docs/10/static/extend-pgxs.html
那么,当我们使用cgo编写FDW时,我们就可以为FDW代码编写类似下面这样的Makefile:
MODULES = {模块名}
EXTENSION = {FDW名}
DATA = {数据库对象的安装sql脚本名}
# {自定义变量声明}
# {cgo模块的构建规则定义}
PG_CONFIG = pg_config
PGXS := $(shell $(PG_CONFIG) --pgxs)
include $(PGXS)
需要注意的是,pg_config是PG提供的用于获取安装环境信息的一个命令。它可以返回一个PG安装环境中的相关信息,如:PG的库文件安装路径,PG的二进制文件的安装路径,该PG的版本号等等。
通常,一个利用Extension Building Infrastructure的Makefile最终会需要用到全局的PGXS Makefile,而该全局Makefile的路径则需要由pg_config来提供,因此在类似上文这样的Makefile之前,必须首先确保PG安装环境中的pg_config命令的路径(即,PG的安装目录中的bin目录)一定要在用户的PATH环境变量中。
此外,在编写FDW时我们的cgo代码会需要调用PG内部的一些函数,因此我们的代码会需要依赖PG的内部头文件以及相关的动态库。cgo本身提供了一些变量让开发者指定编译/链接时的选项:
CGO_CFLAGS 指定编译时选项;
CGO_LDFLAGS 指定链接时选项。
利用这些选项,再加上先前所述的pg_config命令,我们就可以在上述Makefile的变量声明部分指定FDW所需依赖的编译/链接时变量了。
而对于Makefile的构建规则定义,只需要定义好cgo代码的编译规则和对应的命令,以及FDW安装/卸载时的一些文件移动/删除的命令即可。这些与大部分Makefile并无区别,故不再详述。
以上就是对使用GO语言实现FDW的简单介绍。不过还需要再三强调的是,虽然使用GO语言实现FDW在编写代码的效率上会大大提高,复杂度也会有显著降低。但是必须牢记的是,GO调用C语言代码以及C语言回调GO代码都会导致栈的切换(stack switch),进而带来较显著的性能下降。因此,与Multicorn框架所建议的一样——对于一些性能攸关的场景(如作为PG官方sharding方案的postgres_fdw),最好还是使用纯C语言来编写。
四、总结与展望
综上所述,尽管PG的FDW以及SQL/MED规范就目前而言,还是一个比较小众的技术话题。但是我们可以看到从PostgreSQL 9.2到10.0,每一个PG版本的升级都会带来FDW功能的大幅度增强,因此可以相信随着基于postgres_fdw的Sharding方案日趋成熟,FDW技术将会得到越来越多的关注。毕竟Writing a FDW is fun!
参考资料:
PeterEisentraut, "SQL/MED and PostgreSQL"[EB/OL],
https://wiki.postgresql.org/images/4/4c/SQLMED-FOSDEM2009.pdf,2009
FlorianSchwendener, "SQL/MED and More: Management of External Data in PostgreSQLand Microsoft SQL Server"[EB/OL],
https://wiki.hsr.ch/Datenbanken/files/SQLMED_and_More_Schwendener_Paper.pdf,2011
花田茂, "外部データラッパによるPostgreSQLの拡張"[EB/OL],
https://www.slideshare.net/babystarmonja/postgre-sql-11764943,2012
BerndHelmle, "Writing A Foreign Data Wrapper"[EB/OL],
https://wiki.postgresql.org/images/6/67/Pg-fdw.pdf,2012
澤田雅彦, "FDW-based Sharding Update and Future"[EB/OL],
https://www.slideshare.net/masahikosawada98/fdwbased-sharding-update-and-future,2017
BruceMomjian, "The Future of Postgres Sharding"[EB/OL],
https://momjian.us/main/writings/pgsql/sharding.pdf,2018








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721