
唐卓章(zale),华为技术专家,多年互联网研发/架设经验,关注NoSQL中间件高可用及弹性扩展,在分布式系统架构性能优化方面有丰富的实践经验。目前从事物联网平台研发工作,致力于打造大容量高可用的物联网服务。
一、背景介绍
最近微服务架构火得不行,但本质上也只是风口上的一个热点词汇。
作为笔者的经验来说,想要应用一个新的架构需要带来的变革成本是非常高的。
尽管如此,目前还是有许多企业踏上了服务化改造的道路,这其中则免不了“旧改”的各种繁杂事。
所谓的“旧改”,就是把现有的系统架构来一次重构,拆分成多个细粒度的服务后,然后找时间升级割接一把,让新系统上线。这其中,数据的迁移往往会成为一个非常重要且繁杂的活儿。
拆分服务时数据迁移的挑战在哪?
首先是难度大,做一个迁移方案需要了解项目的前身今世,评估迁移方案、技术工具等;
其次是成本高。由于新旧系统数据结构是不一样的,需要定制开发迁移转化功能,很难有一个通用的工具能一键迁移;
再者对于一些容量大、可靠性要求高的系统,要能够不影响业务,出了问题还能追溯,因此方案上还得往复杂了想。
二、常见方案
按照迁移的方案及流程,可将数据迁移分为三类:
最简单的方案,停机迁移的顺序如下:
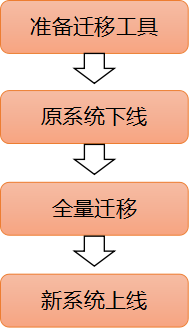
采用停机迁移的好处是流程操作简单,工具成本低,然而缺点也很明显,迁移过程中业务是无法访问的,因此只适合于规格小、允许停服的场景。
业务双写是指对现有系统先进行改造升级,支持同时对新库和旧库进行写入。之后再通过数据迁移工具对旧数据做全量迁移,待所有数据迁移转换完成后切换到新系统。
示意图:
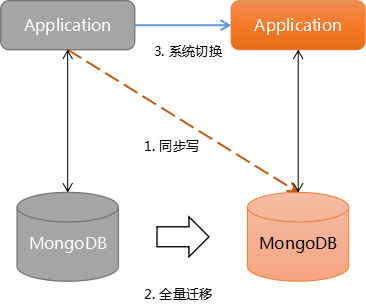
业务双写的方案是平滑的,对线上业务影响极小,在出现问题的情况下可重新来过,操作压力也会比较小。
笔者在早些年前尝试过这样的方案,整个迁移过程确实非常顺利,但实现该方案比较复杂,需要对现有的代码进行改造并完成新数据的转换及写入,对于开发人员的要求较高。在业务逻辑清晰、团队对系统有足够的把控能力的场景下适用。
增量迁移的基本思路是先进行全量的迁移转换,待完成后持续进行增量数据的处理,直到数据追平后切换系统。
示意图:
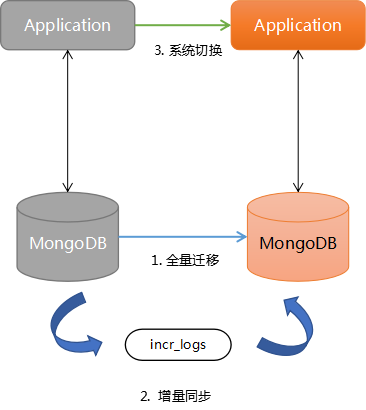
关键点:
要求系统支持增量数据的记录。对于MongoDB可以利用oplog实现这点,为避免全量迁移过程中oplog被冲掉,在开始迁移前就必须开始监听oplog,并将变更全部记录下来;如果没有办法,需要从应用层上考虑,比如为所有的表(集合)记录下updateTime这样的时间戳,或者升级应用并支持将修改操作单独记录下来。
增量数据的回放是持续的。在所有的增量数据回放转换过程中,系统仍然会产生新的增量数据,这要求迁移工具能做到将增量数据持续回放并将之追平,之后才能做系统切换。
MongoDB 3.6版本开始便提供了Change Stream功能,支持对数据变更记录做监听。这为实现数据同步及转换处理提供了更大的便利,下面将探讨如何利用Change Stream实现数据的增量迁移。
三、Change Stream介绍
Chang Stream(变更记录流)是指collection(数据库集合)的变更事件流,应用程序通过db.collection.watch()这样的命令可以获得被监听对象的实时变更。
在该特性出现之前,你可以通过拉取oplog达到同样的目的;但oplog的处理及解析相对复杂且存在被回滚的风险,如果使用不当的话还会带来性能问题。Change Stream可以与aggregate framework结合使用,对变更集进行进一步的过滤或转换。
参考链接:https://docs.mongodb.com/manual/aggregation/
由于Change Stream利用了存储在oplog中的信息,因此对于单进程部署的MongoDB无法支持Change Stream功能,其只能用于启用了副本集的独立集群或分片集群。

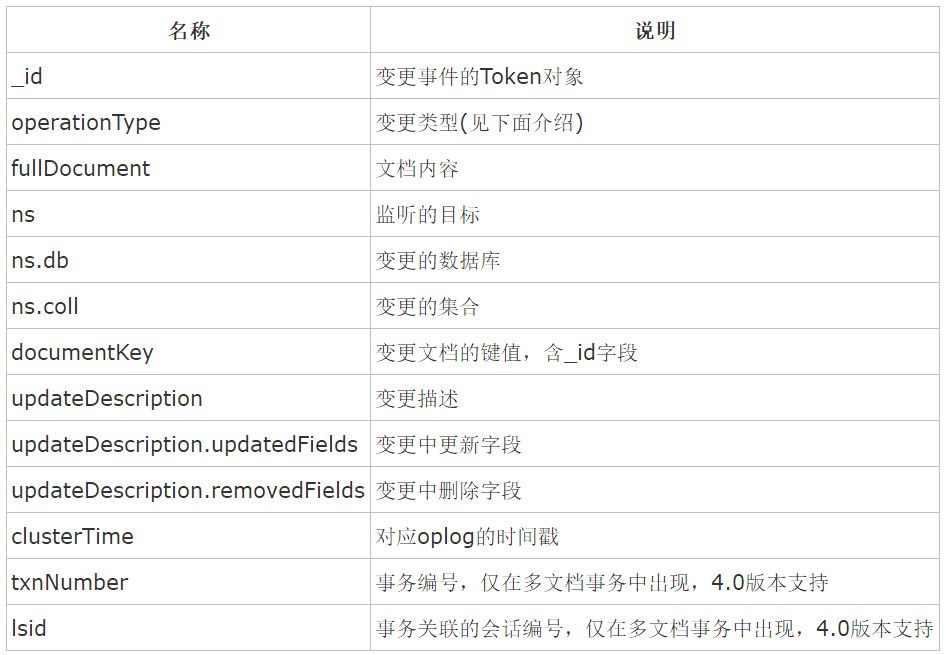
一个Change Stream Event的基本结构如下所示:

字段说明:
Change Steram支持的变更类型有以下几个:

利用以下的shell脚本,可以打印出集合 T_USER上的变更事件:
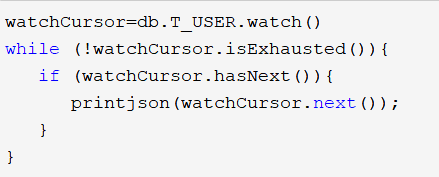
下面提供一些样例,感受一下:
insert事件
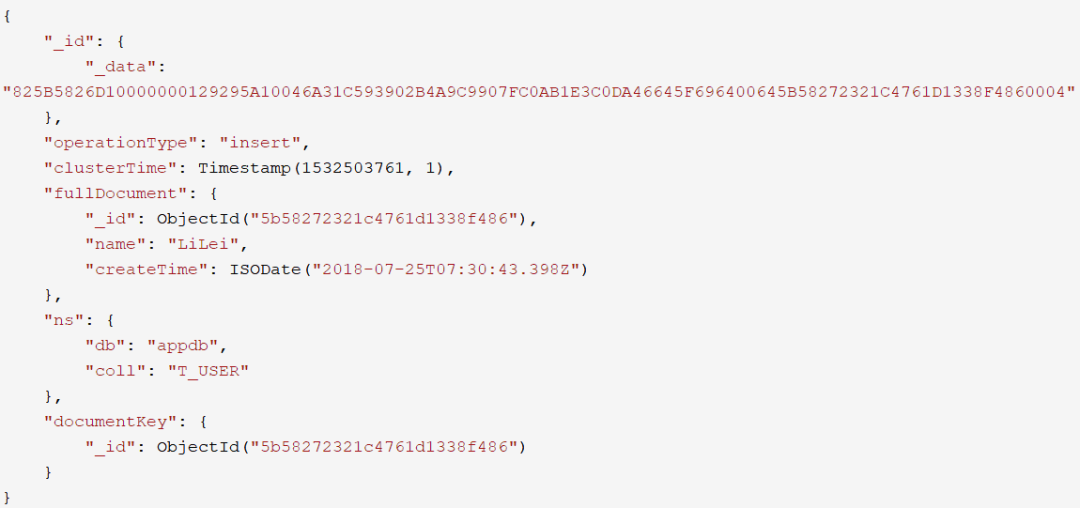
update事件
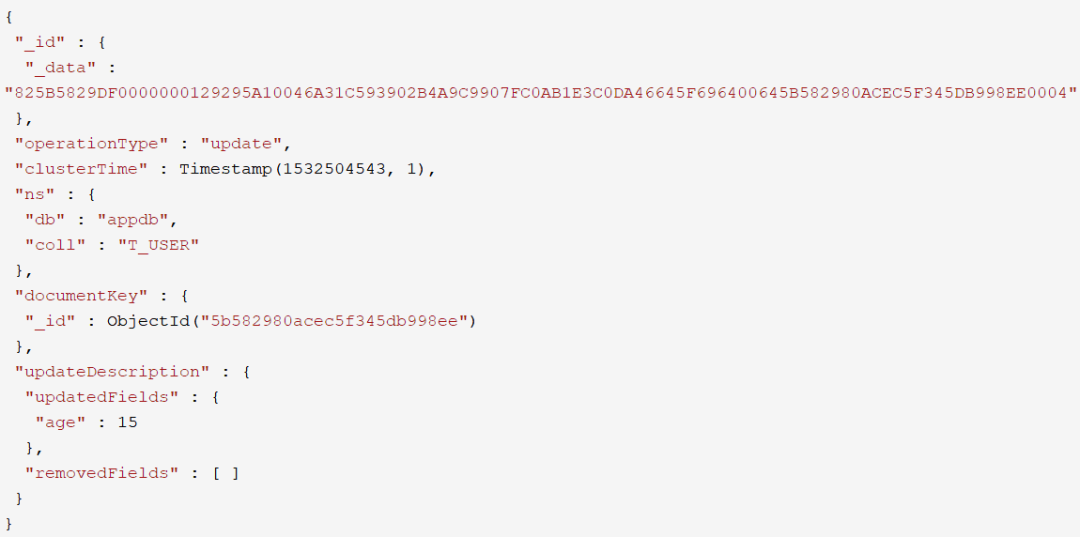
replace事件
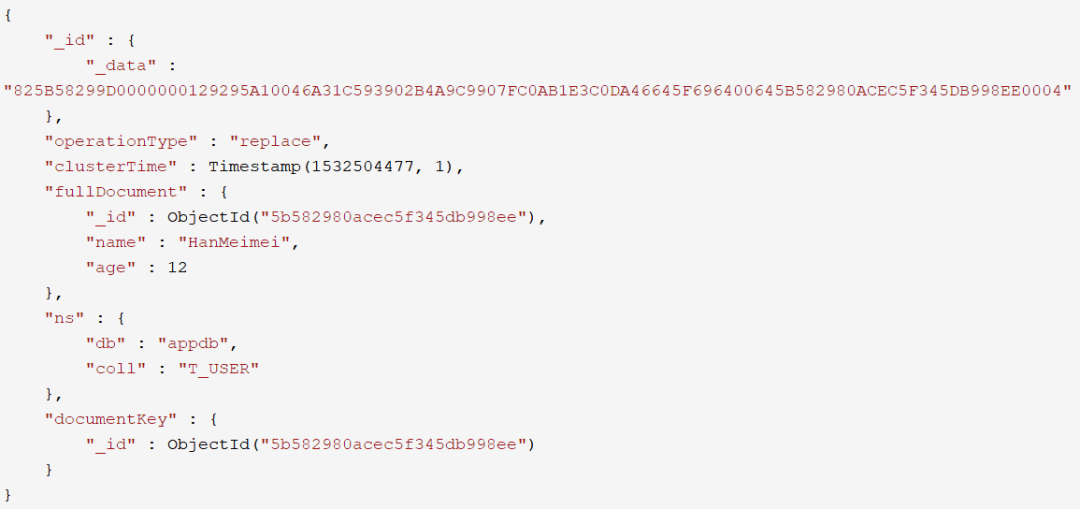
delete事件
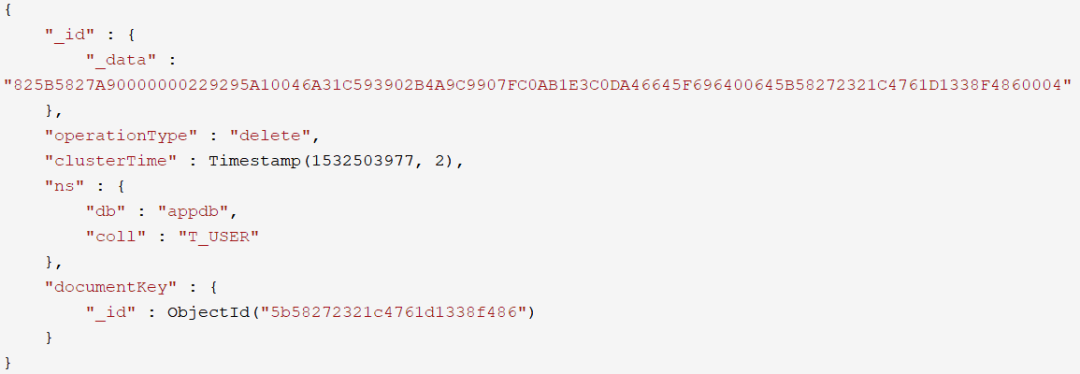
invalidate事件

更多的Change Event信息可以参考:https://docs.mongodb.com/manual/reference/change-events/
四、实现增量迁移
本次设计了一个简单的论坛帖子迁移样例,用于演示如何利用Change Stream实现完美的增量迁移方案。
背景如下:
现有的系统中有一批帖子,每个帖子都属于一个频道(channel),如下表:
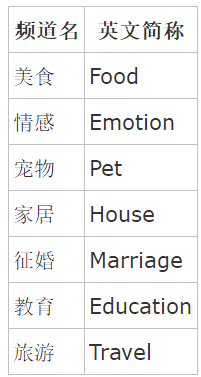
新系统中频道字段将采用英文简称,同时要求能支持平滑升级。根据前面篇幅的叙述,我们将使用Change Stream功能实现一个增量迁移的方案。
相关表的转换如下图:
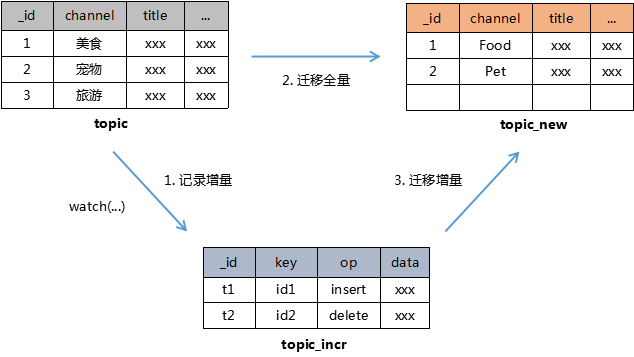
原理
topic是帖子原表,在迁移开始前将开启watch任务持续获得增量数据,并记录到 topic_incr表中;接着执行全量的迁移转换,之后再持续对增量表数据进行迁移,直到无新的增量为止。
接下来我们使用Java程序来完成相关代码,mongodb-java--driver在3.6版本后才支持watch功能,需要确保升级到对应版本:

定义Channel频道的转换表:
public static enum Channel {
Food("美食"),
Emotion("情感"),
Pet("宠物"),
House("家居"),
Marriage("征婚"),
Education("教育"),
Travel("旅游")
;
private final String oldName;
public String getOldName() {
return oldName;
}
private Channel(String oldName) {
this.oldName = oldName;
}
/**
* 转换为新的名称
*
* @param oldName
* @return
*/
public static String toNewName(String oldName) {
for (Channel channel : values()) {
if (channel.oldName.equalsIgnoreCase(oldName)) {
return channel.name();
}
}
return "";
}
/**
* 返回一个随机频道
*
* @return
*/
public static Channel random() {
Channel[] channels = values();
int idx = (int) (Math.random() * channels.length);
return channels[idx];
}
}
为topic表预写入1w条记录:

开启监听任务,将topic上的所有变更写入到增量表:
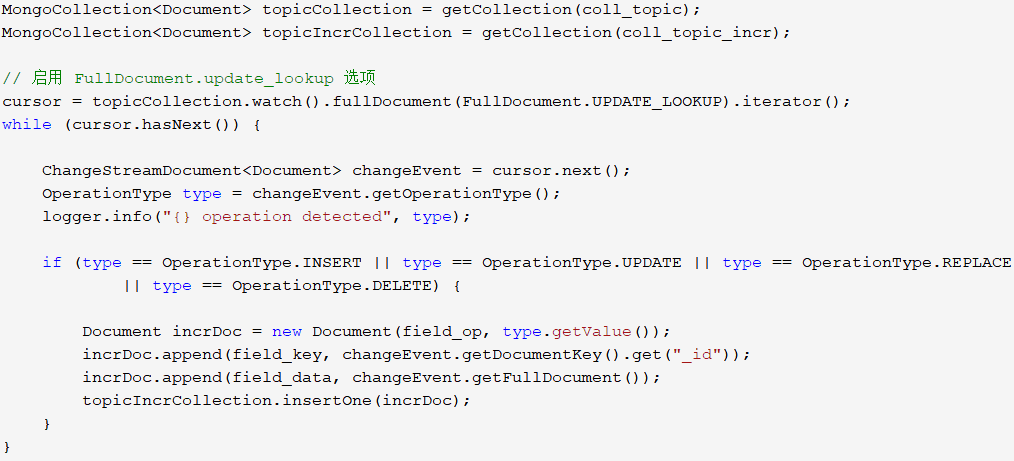
代码中通过watch命令获得一个MongoCursor对象,用于遍历所有的变更。
FullDocument.UPDATE_LOOKUP选项启用后,在update变更事件中将携带完整的文档数据(FullDocument)。
watch()命令提交后,mongos会与分片上的mongod(主节点)建立订阅通道,这可能需要花费一点时间。
为了模拟线上业务的真实情况,启用几个线程对topic表进行持续写操作:

ChangeTask实现逻辑如下:

每一个变更任务会不断对topic产生写操作,触发一系列ChangeEvent产生:
doInsert:生成随机频道的topic后,执行insert;
doUpdate:随机取得一个topic,将其channel字段改为随机值,执行update;
doReplace:随机取得一个topic,将其channel字段改为随机值,执行replace;
doDelete:随机取得一个topic,执行delete。
以doUpdate为例,实现代码如下:

启动一个全量迁移任务,将topic表中数据迁移到topic_new新表:

在全量迁移开始前,先获得当前时刻的的最大 _id 值(可以将此值记录下来)作为终点,随后逐个完成迁移转换。
在全量迁移完成后,便开始最后一步:增量迁移。
注:增量迁移过程中,变更操作仍然在进行。
final MongoCollection<Document> topicIncrCollection = getCollection(coll_topic_incr);
final MongoCollection<Document> topicNewCollection = getCollection(coll_topic_new);
ObjectId currentId = null;
Document sort = new Document("_id", 1);
MongoCursor<Document> cursor = null;
// 批量大小
int batchSize = 100;AtomicInteger count = new AtomicInteger(0);
try {
while (true) {
boolean isWatchTaskStillRunning = watchFlag.getCount() > 0;
// 按ID增量分段拉取
if (currentId == null) {
cursor = topicIncrCollection.find().sort(sort).limit(batchSize).iterator();
} else {
cursor = topicIncrCollection.find(new Document("_id", new Document("$gt", currentId)))
.sort(sort).limit(batchSize).iterator();
}
boolean hasIncrRecord = false;
while (cursor.hasNext()) {
hasIncrRecord = true;
Document incrDoc = cursor.next();
OperationType opType = OperationType.fromString(incrDoc.getString(field_op));
ObjectId docId = incrDoc.getObjectId(field_key);
// 记录当前ID
currentId = incrDoc.getObjectId("_id");
if (opType == OperationType.DELETE) {
topicNewCollection.deleteOne(new Document("_id", docId));
} else {
Document doc = incrDoc.get(field_data, Document.class);
// channel转换
String oldChannel = doc.getString(field_channel);
doc.put(field_channel, Channel.toNewName(oldChannel));
// 启用upsert
UpdateOptions options = new UpdateOptions().upsert(true);
topicNewCollection.replaceOne(new Document("_id", docId),
incrDoc.get(field_data, Document.class), options);
}
if (count.incrementAndGet() % 10 == 0) {
logger.info("IncrTransferTask progress, count: {}", count.get());
}
}
// 当watch停止工作(没有更多变更),同时也没有需要处理的记录时,跳出
if (!isWatchTaskStillRunning && !hasIncrRecord) {
break;
}
sleep(200);
}
} catch (Exception e) {
logger.error("IncrTransferTask ERROR", e);
}
增量迁移的实现是一个不断tail的过程,利用 **_id 字段的有序特性 ** 进行分段迁移;即记录下当前处理的_id值,循环拉取在该_id值之后的记录进行处理。
增量表(topic_incr)中除了DELETE变更之外,其余的类型都保留了整个文档,因此可直接利用replace + upsert追加到新表。
最后,运行整个程序。
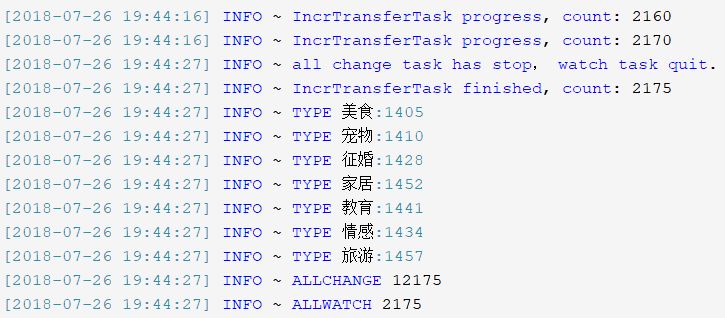
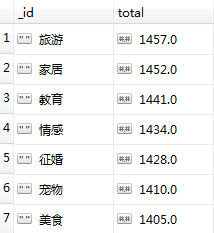
查看topic表和topic_new表,发现两者数量是相同的。为了进一步确认一致性,我们对两个表的分别做一次聚合统计:
topic表

topic_new表

前者输出结果:
后者输出结果:
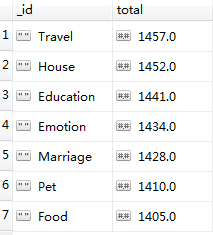
前后对比的结果是一致的。
五、后续优化
前面的章节演示了一个增量迁移的样例,在投入到线上运行之前,这些代码还得继续优化:
写入性能,线上的数据量可能会达到亿级,在全量、增量迁移时应采用合理的批量化处理;另外可以通过增加并发线程,添置更多的Worker,分别对不同业务库、不同表进行处理以提升效率。增量表存在幂等性,即回放多次其最终结果还是一致的,但需要保证表级有序,即一个表同时只有一个线程在进行增量回放。
容错能力,一旦watch监听任务出现异常,要能够从更早的时间点开始(使用startAtOperationTime参数),而如果写入时发生失败,要支持重试。
回溯能力,做好必要的跟踪记录,比如将转换失败的ID号记录下来,旧系统的数据需要保留,以免在事后追究某个数据问题时找不着北。
数据转换,新旧业务的差异不会很简单,通常需要借助大量的转换表来完成。
一致性检查,需要根据业务特点开发自己的一致性检查工具,用来证明迁移后数据达到想要的一致性级别。
BTW,数据迁移一定要结合业务特性、架构差异来做考虑,否则还是在耍流氓。
六、小结
服务化系统中扩容、升级往往会进行数据迁移,对于业务量大,中断敏感的系统通常会采用平滑迁移的方式。
MongoDB 3.6版本后提供了Change Stream功能以支持应用订阅数据的变更事件流,本文使用Stream功能实现了增量平滑迁移的例子,这是一次尝试,相信后续这样的应用场景会越来越多。
MongoDB-ChangeStream
https://docs.mongodb.com/manual/changeStreams/
Use-ChangeStream To Handle Temperature
https://www.percona.com/blog/2017/11/22/mongodb-3-6-change-streams-nest-temperature-fan-control-use-case/
作者:唐卓章(zale)
来源:Mongoing中文社区订阅号(ID:mongoing-mongoing)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721