
作者介绍
索宁,擅长Python开发、MySQL、前端等众多技术领域,曾负责众多企业安全架构解决方案 ,涉猎行业有媒体、出版社、航空运输、医疗、军队、政府、教育等。
本文主题:
Memcached
Redis
RabbitMQ
一、Memcached
1、简介、安装、使用
Memcached 是一个高性能的分布式内存对象缓存系统,用于动态 Web 应用以减轻数据库负载压力。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。Memcached 基于一个存储键/值对的 hashmap。其守护进程(daemon )是用 C写的,但是客户端可以用任何语言来编写,并通过 memcached 协议与守护进程通信。
Memcached 内存管理机制:
Menceched 通过预分配指定的内存空间来存取数据,所有的数据都保存在 memcached 内置的内存中。
利用 Slab Allocation 机制来分配和管理内存。按照预先规定的大小,将分配的内存分割成特定长度的内存块,再把尺寸相同的内存块分成组,这些内存块不会释放,可以重复利用。
当存入的数据占满内存空间时,Memcached 使用 LRU 算法自动删除不是用的缓存数据,即重用过期数据的内存空间。Memcached 是为缓存系统设计的,因此没有考虑数据的容灾问题,和机器的内存一样,重启机器将会丢失,如果希望服务重启数据依然能保留,那么就需要 sina 网开发的 Memcachedb 持久性内存缓冲系统,当然还有常见的 NoSQL 服务如 Redis。
默认监听端口:11211
Memcached 安装

源码安装启动 Memcached 快速部署文档

源码安装 Memcached PHP 客户端

Memcached 启动
memcached -d -m 10 -u root -l 218.97.240.118 -p 12000 -c 256 -P /tmp/memcached.pid
参数说明:
-d 是启动一个守护进程
-m 是分配给Memcache使用的内存数量,单位是MB
-u 是运行Memcache的用户
-l 是监听的服务器IP地址
-p 是设置Memcache监听的端口,最好是1024以上的端口
-c 选项是最大运行的并发连接数,默认是1024,按照你服务器的负载量来设定
-P 是设置保存Memcache的pid文件
Memcached 命令
存储命令: set/add/replace/append/prepend/cas
获取命令: get/gets
其他命令: delete/stats..
Memcached 管理

Memcached memadmin php工具界面化管理安装部署文档
# memadmin php 工具管理(memcadmin-1.0.12.tar.gz)
1、安装memadmin php工具。

2、 登陆memadmin php。
web方式访问:http://IP地址/memadmin/
默认用户名密码都为admin。
2、Python 操作 Memcached
1)安装 API 及 基本操作
python 操作 Memcached 使用 Python-memcached 模块
下载安装:https://pypi.python.org/pypi/python-memcached
import memcache
mc = memcache.Client(['192.168.1.5:12000'], debug=True)
mc.set("foo", "bar")
ret = mc.get('foo')
print ret
2)天生支持集群
python-memcached 模块原生支持集群操作,其原理本质是在内存维护一个主机列表,数字为权重,为3即出现3次,相对应的几率大
mc = memcache.Client([
('192.168.1.5:12000', 3), # 数字为权重
('192.168.1.9:12000', 1),
], debug=True)
# 那么在内存中主机列表为:
# host_list = ["192.168.1.5","192.168.1.5","192.168.1.5","192.168.1.9",]
那么问题来了,集群情况下如何选择服务器存储呢?
如果要创建设置一个键值对(如:k1 = "v1"),那么它的执行流程如下:
将 k1 转换成一个数字
将数字和主机列表的长度求余数,得到一个值 N(N 的范围: 0 <= N < 列表长度 )
在主机列表中根据 第2步得到的值为索引获取主机,例如:host_list[N]
连接 将第3步中获取的主机,将 k1 = "v1" 放置在该服务器的内存中
获取值的话也一样
源码、将字符串转换为数字

3)add
添加一个键值对,如果 key 已经存在,重复添加执行 add 则抛出异常
import memcache
mc = memcache.Client(['192.168.1.5:12000'], debug=True)
mc.add('k1', 'v1')
# mc.add('k1', 'v2') # 报错,对已经存在的key重复添加,失败!!!
4)replace
replace 修改某个 key 的值,如果 key 不存在,则异常
import memcache
mc = memcache.Client(['192.168.1.5:12000'], debug=True)
# 如果memcache中存在kkkk,则替换成功,否则一场
mc.replace('kkkk','999')
5) set 和 set_multi
set 设置一个键值对,如果 key 不存在,则创建
set_multi 设置多个键值对,如果 key 不存在,则创建
import memcache
mc = memcache.Client(['192.168.1.5:12000'], debug=True)
mc.set('name', 'nick')
mc.set_multi({'name': 'nick', 'age': '18'})
6) delete 和 delete_multi
delete 删除指定的一个键值对
delete_multi 删除指定的多个键值对
import memcache
mc = memcache.Client(['192.168.1.5:12000'], debug=True)
mc..delete('name', 'nick')
mc.delete_multi({'name': 'nick', 'age': '18'})
7) get 和 get_multi
get 获取一个键值对
get_multi 获取多个键值对
import memcache
mc = memcache.Client(['192.168.1.5:12000'], debug=True)
val = mc.get('name')
item_dict = mc.get_multi(["name", "age",])
8)append 和 prepend
append 修改指定key的值,在该值 后面 追加内容
prepend 修改指定key的值,在该值 前面 插入内容
import memcache
mc = memcache.Client(['192.168.1.5:12000'], debug=True)
# 原始值: k1 = "v1"
mc.append('k1', 'after')
# k1 = "v1after"
mc.prepend('k1', 'before')
# k1 = "beforev1after"
9) decr 和 incr
incr 自增,将 Memcached 中的某个值增加 N ( N 默认为1 )
decr 自减,将 Memcached 中的某个值减少 N ( N 默认为1 )
mport memcache
mc = memcache.Client(['192.168.1.5:12000'], debug=True)
mc.set('k1', '666')
mc.incr('k1')
# k1 = 667
mc.incr('k1', 10)
# k1 = 677
mc.decr('k1')
# k1 = 676
mc.decr('k1', 10)
# k1 = 666
10) gets 和 cas
这两个方法就是传说中的锁 。为了避免脏数据的产生而生:
import memcache
mc = memcache.Client(['192.168.1.5:12000'], debug=True, cache_cas=True)
v = mc.gets('product_count')
# 如果有人在gets之后和cas之前修改了product_count,那下面的设置将会执行失败,剖出异常
mc.cas('product_count', "899")
本质:每次执行 gets 时,就从 memcache 中获取一个自增的数字,通过 cas 去修改 gets 到的值时,会携带之前获取的自增值和 memcache 中的自增值进行比较,如果相等,则可以提交,如果不相等,那表示在 gets 和 cas 执行之间,又有其他人执行了 gets(获取了缓冲的指定值),如此一来有可能出现非正常的数据,则不允许修改,并报错。
二、Redis
1、简介、安装、使用、实例
Remote Dictionary Server(Redis)是一个基于 key-value 键值对的持久化数据库存储系统。Redis 和 Memcached 缓存服务很像,但它支持存储的 value 类型相对更多,包括 string (字符串)、list (链表)、set (集合)、zset (sorted set --有序集合)和 hash(哈希类型)。这些数据类型都支持 push/pop、add/remove 及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,Redis 支持各种不同方式的排序。与Memcached 一样,为了保证效率,数据都是缓存在内存中。区别的是 Redis 会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了 master-slave (主从)同步。
Redis 的出现,再一定程度上弥补了 Memcached 这类 key-value 内存换乘服务的不足,在部分场合可以对关系数据库起到很好的补充作用。Redis 提供了 Python,Ruby,Erlang,PHP 客户端,使用方便。
官方文档:
http://www.Redis.io/documentation
http://www.Redis.cn/
Redis 安装和使用实例

Redis 源码快速安装文档

Redis 安装目录及各文件作用

配置并启动 Redis 服务


客户端连接命令及命令测试

Redis 的 php 客户端拓展安装

Redis 主从同步

Redis 负载均衡
至于 Redis 的负载均衡,方案有很多:
LVS、keepalived、Twemproxy
有时间再补上吧...
Redis 持久化
Redis持久化方式有两种:
(1)RDB:对内存中数据库状态进行快照;
(2)AOF:把每条写命令都写入文件,类似mysql的binlog日志
RDB。
将Redis在内存中的数据库状态保存到磁盘里面,RDB文件是一个经过压缩的二进制文件,通过该文件可以还原生成RDB文件时的数据库状态。
RDB的生成方式:
(1)执行命令手动生成
有两个Redis命令可以用于生成RDB文件,一个是SAVE,另一个是BGSAVE
SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务器进程阻塞期间,服务器不能处理任何命令请求;
BGSAVE命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求,创建RDB文件结束之前,客户端发送的BGSAVE和SAVE命令会被服务器拒绝。
(2)通过配置自动生成
可以设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令;
可以通过save选项设置多个保存条件,但只要其中任意一个条件被满足,服务器就会执行BGSAVE命令。
例如:
save 900 1
save 300 10
save 60 10000
那么只要满足以下三个条件中的任意一个,BGSAVE命令就会被执行:
服务器在900秒之内,对数据库进行了至少1次修改
服务器在300秒之内,对数据库进行了至少10次修改
服务器在60秒之内,对数据库进行了至少10000次修改
AOF
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态的。
AOF文件刷新的方式,有三种:
(1)appendfsync always - 每提交一个修改命令都调用fsync刷新到AOF文件,非常非常慢,但也非常安全;
(2)appendfsync everysec - 每秒钟都调用fsync刷新到AOF文件,很快,但可能会丢失一秒以内的数据;
(3)appendfsync no - 依靠OS进行刷新,Redis不主动刷新AOF,这样最快,但安全性就差。
默认并推荐每秒刷新,这样在速度和安全上都做到了兼顾。
数据恢复
RDB方式:
RDB文件的载入工作是在服务器启动时自动执行的,没有专门用于载入RDB文件的命令,只要Redis服务器在启动时检测到RDB文件存在,它就会自动载入RDB文件,服务器在载入RDB文件期间,会一直处于阻塞状态,直到载入工作完成为止。
AOF方式
服务器在启动时,通过载入和执行AOF文件中保存的命令来还原服务器关闭之前的数据库状态,具体过程:
(1)载入AOF文件
(2)创建模拟客户端
(3)从AOF文件中读取一条命令
(4)使用模拟客户端执行命令
(5)循环读取并执行命令,直到全部完成
如果同时启用了RDB和AOF方式,AOF优先,启动时只加载AOF文件恢复数据。
2、Python 操作 Redis
python 安装 Redis 模块:
$ sudo pip install Redis
or
$ sudo easy_install Redis
or
$ sudo python setup.py install
详见:
https://github.com/WoLpH/Redis-py
https://pypi.python.org/pypi/Redis
https://Redislabs.com/python-Redis
API 的使用
1) 操作模式
redis-py 提供两个类 Redis 和 StrictRedis 用于实现 Redis 的操作命令,StrictRedis 用于实现大部分官方的命令,并使用官方的语法和命令,Redis 是 StrictRedis 的子类,用于向后兼容旧版本的 redis-py。
import redis
r =redis.redis(host='192.168.1.5', port=6379)
r.set('foo', 'Bar')
print r.get('foo')
2) 连接池
redis-py 使用 connection pool 来管理对一个 Redis server 的所有连接,避免每次建立、释放连接带来的额外开销。默认每个 Redis 实例都会维护着一个自己的连接池。也可以覆盖直接建立一个连接池,然后作为参数 Redis,这样就可以实现多个 Redis 实例共享一个连接池资源。实现客户端分片或有连接如何管理更细的颗粒控制。
pool = redis.ConnectionPool(host='192.168.1.5', port=6379)
r = redis.redis(connection_pool=pool)
r.set('foo', 'Bar')
print r.get('foo')
3) 操作
分为五种数据类型,见下图:
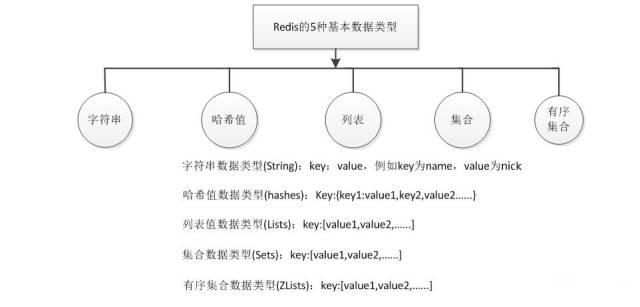
①String 操作,String 在内存中格式是一个 name 对应一个 value 来存储


②Hash 操作,Redis 中 Hash 在内存中的存储格式类似字典。


③List操作,Redis 中的 List 在在内存中按照一个 name 对应一个 List 来存储,像变量对应一个列表。


④Set 操作,Set 集合就是不允许重复的列表。

⑤有序集合,在集合的基础上,为每个元素排序;元素的排序需要根据另外一个值来进行比较,所以对于有序集合,每一个元素有两个值:值和分数,分数是专门来做排序的。

4)管道
默认情况下,Redis-py 每次在执行请求时都会创建和断开一次连接操作(连接池申请连接,归还连接池),如果想要在一次请求中执行多个命令,则可以使用 pipline 实现一次请求执行多个命令,并且默认情况下 pipline 是原子性操作。
见以下实例:
import redis
pool = redis.ConnectionPool(host='10.211.55.4', port=6379)
r = redis.redis(connection_pool=pool)
# pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True)
r.set('name', 'nick')
r.set('age', '18')
pipe.execute()
5) 发布和订阅
发布者:服务器
订阅者:Dashboad 和数据处理
发布订阅的 Demo 如下:
RedisHelper

订阅者:

发布者:

三、RabbitMQ
1、简介、安装、使用
RabbitMQ 是一个在 AMQP 基础上完成的,可复用的企业消息系统。他遵循 Mozilla Public License 开源协议。
MQ 全称为 Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方式。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
流程上生产者把消息放到队列中去, 然后消费者从队列中取出消息。
Producing,生产者, 产生消息的角色.
Exchange,交换器, 在得到生产者产生的消息后, 把消息放入队列的角色.
Queue,队列,消息暂时保存的地方.
Consuming,消费者, 把消息从队列中取出的角色.
消息 Message
RabbitMQ安装

2、使用API操作RabbitMQ
基于队列 Queue 实现生产者消费者模型:
View Code

RabbitMQ 实现

1、acknowledgment 消息不丢失
no-ack = False,如果消费者由于某些情况宕了(its channel is closed, connection is closed, or TCP connection is lost),那 RabbitMQ 会重新将该任务放入队列中。
在实际应用中,可能会发生消费者收到Queue中的消息,但没有处理完成就宕机(或出现其他意外)的情况,这种情况下就可能会导致消息丢失。为了避免这种情况发生,我们可以要求消费者在消费完消息后发送一个回执给RabbitMQ,RabbitMQ收到消息回执(Message acknowledgment)后才将该消息从Queue中移除;如果RabbitMQ没有收到回执并检测到消费者的RabbitMQ连接断开,则RabbitMQ会将该消息发送给其他消费者(如果存在多个消费者)进行处理。这里不存在timeout概念,一个消费者处理消息时间再长也不会导致该消息被发送给其他消费者,除非它的RabbitMQ连接断开。
这里会产生另外一个问题,如果我们的开发人员在处理完业务逻辑后,忘记发送回执给RabbitMQ,这将会导致严重的bug——Queue中堆积的消息会越来越多;消费者重启后会重复消费这些消息并重复执行业务逻辑……
消费者

2、durable 消息不丢失
如果我们希望即使在RabbitMQ服务重启的情况下,也不会丢失消息,我们可以将Queue与Message都设置为可持久化的(durable),这样可以保证绝大部分情况下我们的RabbitMQ消息不会丢失。但依然解决不了小概率丢失事件的发生(比如RabbitMQ服务器已经接收到生产者的消息,但还没来得及持久化该消息时RabbitMQ服务器就断电了),如果我们需要对这种小概率事件也要管理起来,那么我们要用到事务。由于这里仅为RabbitMQ的简单介绍,所以这里将不讲解RabbitMQ相关的事务。
需要改两处地方:
生产者

消费者

3、消息获取顺序
默认情况下,消费者拿消息队列里的数据是按平均分配,例如:消费者1 拿队列中 奇数 序列的任务,消费者2 拿队列中 偶数 序列的任务。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列,这个性能较高的机器拿的任务就多。
消费者

4、发布订阅
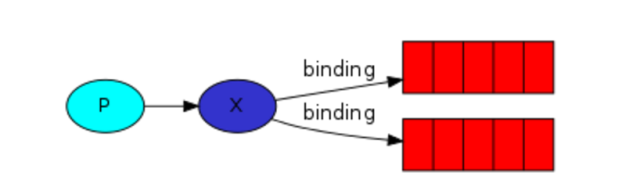
发布订阅和简单的消息队列区别在于,发布订阅者会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ 实现发布订阅时,会为每一个订阅者创建一个队列,而发布者发布消息的时候,会将消息放置在所有相关的队列中。
exchange type = fanout
发布者

订阅者

5、关键字发送
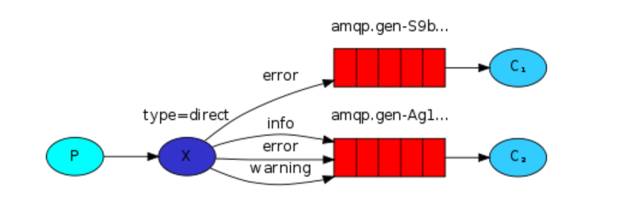
第4步实例中,发送消息必须明确指定某个队列并向其中发送消息,当然,RabbitMQ 还支持根据关键字发送(队列绑定关键字),发送者将消息发送到 exchange,exchange 根据关键字 判定应该将数据发送至指定队列。
exchange type = direct
消费者

生产者

6、模糊匹配
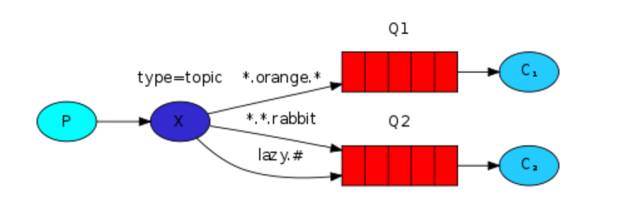
exchange type = topic
在 topic 类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到 exchange,exchange 将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
匹配基本规则及示例:
# 表示可以匹配 0 个 或 多个 单词
表示只能匹配 一个 单词
发送者路由值 队列中
www.suoning.python www.* -- 不匹配
www.suoning.python www.# -- 匹配
消费者

生产者









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721