
数据库方案

缓存解决方案
为了解决检查用户名唯一性的数据库调用的性能问题,可以引入了高效的 Redis 缓存。

import org.redisson.Redisson;import org.redisson.api.RedissonClient;import org.redisson.config.Config;import org.redisson.api.RMap;public class UserExistenceChecker {// Redis hash map name to store user informationprivate static final String USER_HASH_NAME = "users";public static void main(String[] args) {// Create a Redisson clientRedissonClient redisson = createRedissonClient();// Retrieve the hash map to store user informationRMap<String, String> users = redisson.getMap(USER_HASH_NAME);// Add a user to the hash mapusers.put("user123", "someUserInfo"); // Here "someUserInfo" could be a JSON string, UUID, etc.// Check if a user existsboolean exists = users.containsKey("user123");System.out.println("User 'user123' exists? " + exists);// Check for a non-existent userexists = users.containsKey("user456");System.out.println("User 'user456' exists? " + exists);// Shutdown the Redisson clientredisson.shutdown();}// Helper method to create a Redisson clientprivate static RedissonClient createRedissonClient() {Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379") // Adjust to your Redis address.setPassword("yourpassword"); // Provide your Redis password if anyreturn Redisson.create(config);}}
这个方案最大的问题是内存占用过大,假设每个用户名大约需要15字节的内存,如果要存储10亿个用户名,就需要15GB的内存。
总内存 = 每条记录的内存使用量 * 记录数 = 15 字节/记录 * 1,000,000,000 条记录 = 15,000,000,000 字节 ≈ 15,000,000 KB ≈ 15,000 MB ≈ 15 GB
布隆过滤器方案

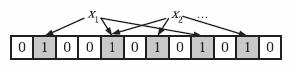
import org.redisson.Redisson;import org.redisson.api.RBloomFilter;import org.redisson.api.RedissonClient;import org.redisson.config.Config;public class UserExistenceChecker {// Name of the Bloom Filter in Redisprivate static final String BLOOM_FILTER_NAME = "user_existence_filter";public static void main(String[] args) {// Create a Redisson clientRedissonClient redisson = createRedissonClient();// Retrieve or create a Bloom Filter instance// Expected number of elements and false positive probability are parametersRBloomFilter<String> bloomFilter = redisson.getBloomFilter(BLOOM_FILTER_NAME);bloomFilter.tryInit(100000L, 0.001); // Initialize the Bloom Filter with expected elements and false positive rate// Add a user to the Bloom FilterbloomFilter.add("user123");// Check if a user existsboolean exists = bloomFilter.contains("user123"); // Should return trueSystem.out.println("User 'user123' exists? " + exists);// Check for a non-existent user (might falsely report as true due to Bloom Filter's nature)exists = bloomFilter.contains("user456"); // Assuming not added, should ideally return false, but could be a false positiveSystem.out.println("User 'user456' exists? " + exists);// Shutdown the Redisson clientredisson.shutdown();}// Helper method to create a Redisson clientprivate static RedissonClient createRedissonClient() {Config config = new Config();config.useSingleServer().setAddress("redis://127.0.0.1:6379"); // Adjust to your Redis address// .setPassword("yourpassword"); // Provide your Redis password if anyreturn Redisson.create(config);}}
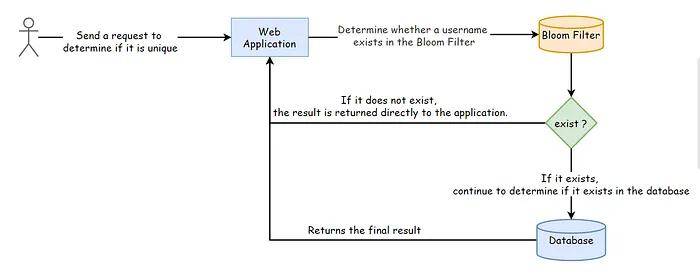
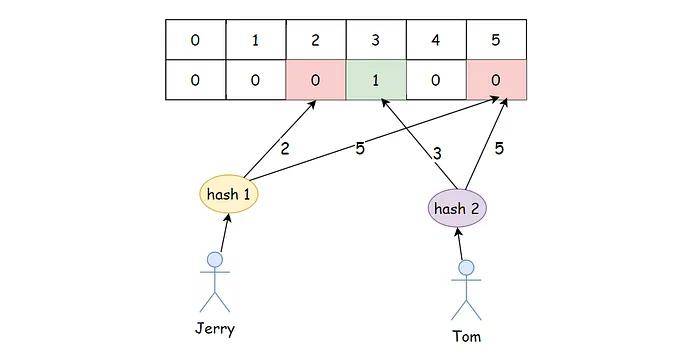
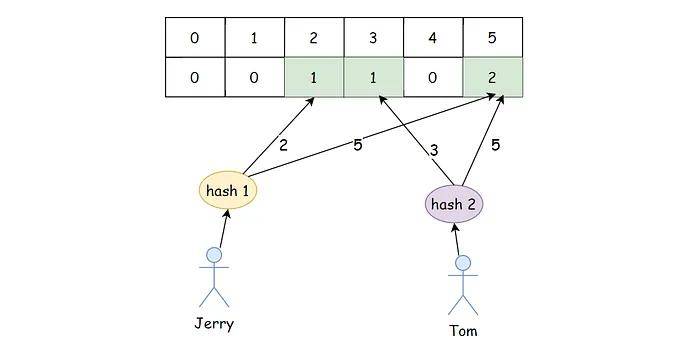
总结








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721