
最近这个公司的程序员们写了个博客,说他们自建了一个专门为地理空间数据构建的数据库来替换 Aurora PostgreSQL 和 PostGIS,并节省了 98% 的云成本。这一说法在各大论坛(以 Reddit 和 HN 为主)里引起了激烈的讨(pēng)论( jī)。
原贴内容
编程的最基本原则是什么?它可能是“不要重复编写代码”,可能是“只要代码能 work,就别乱动”,也有可能是......“不要自建数据库”!
自建数据库是一场噩梦。无论是从原子性、一致性、隔离性和持久性等要求,还是从数据分片、故障恢复和运维管理等操作来看,自建数据库的难度都远超人们想象。
而且,市面上已经有很多经过数十年打磨的优秀数据库可以免费使用。那为什么我们要傻乎乎地从 0 到 1 编写一个数据库呢?
我们的云平台能够同时追踪数以万计的人员和车辆。每次它们的位置更新都会被存储,并通过历史 API 进行检索。随着时间的不同,当前同时连接的车辆数量及其位置更新频率会有很大变化。平台大约有 13,000 个连接,每个连接每秒发送一个更新是很正常的。
而我们的客户使用数据的方式各不相同。有些用例非常简单,例如一家汽车租赁公司想要显示其客户当天的行驶路线。在这种情况下,对于一小时的车程,我们只需要处理 30-100 个位置点,然后对位置数据进行大量聚合、压缩和存储。
当然还有许多其他需求。例如,物流公司希望能够回溯事故发生前的精确时刻;矿山需要精准的现场位置跟踪,知道是哪个工人进入了哪个禁区,精确度高达半米。
之前,我们不了解每个客户需求的颗粒度,所以把每次位置更新都进行一次存储。对于 13,000 辆车来说,每月就是 35 亿次更新,而且这个数字还会继续增长。过去我们一直使用 AWS Aurora 和 PostGIS 扩展来存储地理空间数据,每个月仅仅是数据库的费用就超过了 10,000 美元,而且还会越来越贵。
当然这不能只让 Aurora 背锅。Aurora 在负载情况下的表现很好,只是我们的很多客户都有私有化部署需求,需要运行自己的数据库集群,那这个数据量就很容易超出他们的承载能力。
很遗憾,目前好像没有这样的数据库(如果有的话请告诉我)。很多数据库(比如 Mongo、H2 和 Redis)都支持空间数据类型,比如点和区域,此外还有一些“空间数据库”。但它们大多是位于现有数据库之上的扩展。比如最有名的 PostGIS,就是建立在 PostgreSQL 之上的,还有像 Geomesa 这样的存储引擎,也是在其他存储引擎之上提供了强大的地理空间查询功能。
但这不是我们所需要的。我们的需求是:
极高的写入性能:希望每个节点在一秒内能够处理多达 3 万个位置更新。它们可以在写入之前进行缓冲,从而大大降低 IOPS。
无限并行:多个节点同时写入数据,没有上限。
占用较小的磁盘空间:考虑到数据的量级,希望它们在磁盘上占用尽可能少的空间。
为此,我们不得不接受一些权衡。比如:
对磁盘读取要求不高
我们的服务器是基于内存的架构,针对内存中的数据运行实时流的查询和过滤,速度非常快。
只有当新服务器上线、客户端使用历史 API 、或者用户在我们的数字孪生界面上回溯时间时,才会从磁盘读取。这些磁盘读取需要够快,才能获得良好的用户体验,但它们相对较少且容量较低。
低一致性保证
我们可以接受丢失一些数据。在写入磁盘之前,我们会缓冲大约一秒钟的更新。在极少数情况下,如果一台服务器宕机并由另一台服务器接管,我们可以容忍在当前缓冲区中丢失一秒钟的位置更新。
我们需要存储的主要数据类型是“对象”,包括车辆、人员、传感器和机器等。每个对象都有 ID 标签、位置信息(包括经度、纬度、速度、航向、高度等)和任意的键值对数据(例如燃料水平或当前乘客 ID)。在更新时,可能只需要更改这些字段的子集。
此外,我们还需要存储区域、任务(对象需要执行的任务)和指令(Hivekit 服务器基于传入数据执行的微小空间逻辑)。
我们专门设计了一个进程内存储引擎,它与核心服务器一样,是可执行文件的一部分。它以一种最小化的、基于增量的二进制格式进行写入。单个条目如下所示:
每个块代表一个字节。标记为“flags”的两个字节是一个开关/标识位,包含“是否有纬度”、“是否有经度”、“是否有数据”等信息,告诉解析器在条目的剩余字节中要查找什么。
我们每 200 次写入就存储一次对象的全量数据。在此之间,我们只存储增量数据。这样一来,一个完整的位置更新(包括时间、ID、纬度和经度等信息)只需要 34 个字节,然后我们就可以将约 3000 万个位置更新压缩到 1GB 的磁盘空间中。
我们还维护一个单独的索引文件,将每个条目的静态字符串 ID 和类型(对象、区域等)转换为唯一的 4 字节标识符。这个固定大小的标识符始终位于每个条目的 6-9 地址段,因此检索特定对象的历史记录变得非常快速。
这个存储引擎是我们服务器二进制文件的一部分,因此运行成本并没有改变。变化在于,我们把每月花费 10,000 美元的 Aurora 实例替换成了每月 200 美元的 EBS 卷。我们使用了具备 3000 IOPS 的预配置 IOPS SSD(io2),并将数据更新操作进行了批处理,以实现每个节点和realm(数据集合)每秒进行一次写入。
EBS 具有自动备份和恢复的功能,并提供高可用性保证,我们感觉它的可靠性并不比 Aurora 差。我们每月产生约 100GB 的数据。由于客户很少查询 10 天前的数据条目,我们已经开始将超过 30GB 的数据移动到 AWS Glacier,从而进一步减少了 EBS 的成本。
而这不仅仅是成本问题。通过文件系统写入本地 EBS,比写入 Aurora 速度更快,开销更低,查询速度也大大加快。因为查询并不完全类似,所以很难量化这个差异。但可以知道的是,重新创建一个 realm 特定历史时间点的耗时,从 2 秒减少到了约 13 毫秒。
可能有人会说,这样比,不公平。毕竟 Postgres 是一个通用数据库,具有表达能力很强的查询语言,而我们构建的只是一个游标(cursor),它用于流式传输二进制文件,功能非常有限。确实是这样,但是我也想再一次强调,这就是我们的需求,而且我们想要任何的功能都在了。
关于 Hivekit 的 API 和更多功能,请参考 https://hivekit.io/developers/。
网友热议
98%这个数字立即就刺激了网友们敏感的神经,马上提出质疑,虽然使用 PostgreSQL 或 Elasticsearch 可能不如使用专门构建的解决方案便宜,但将维护成本和自制解决方案的机会成本设定为零并不合理。
HN 热评榜一大哥也先抛出了类似的疑问,这家公司通过自建数据库,实现了 $10k/月到 $200/月,这个数据具体是怎么算的?是否将研发投入、项目投入等等成本包含在内?如果没有包含的话,那 12 万美元/年的 Aurora 成本似乎比自定义数据库的开发/组织时间成本要低。

另外,所谓的成本计算与之前使用 Aurora 的效果不应该放在一起比较,“如果他们能够用一个高级的 KV 存储替代 Aurora 实例,那么他们其实购买了错误的工具。那我还可以说我从开奥迪 A4 换成骑自己组装的自行车上班,每月节省了数百美元的交通费用。”

还有网友表示,“尽管你可能对数据库不太了解(扎心),但是雇用开发人员写新的数据库会花不少钱。维护数据库、处理损失、错误和故障也需要花费。而且,随着需要扩展功能,原开发人员可能已经离职了。使用别人的数据库也不意味着百分之百的正常运行时间和零损失。所以现在就宣称这种做法更划算可能还为时过早。”
更直接点的表示,对对对,省 98% 云成本,但是人力成本涨了 200%。

但是也有读者认为,不能将这些费用简单地算在一起,因为一方面 Aurora 每年的使用成本会随着使用量的增加而增加,另一方面一旦自建的数据库开发完成,后续每年所需的成本只是维护费用。而且切换回 Aurora 的机会成本更高。

再说,就算使用 Aurora,也不可避免地需要花费几乎同等的费用雇佣研发和项目经理维护数据库。这位网友还认为,企业自建的故事每天都在发生,虽然过程很痛苦,但可以帮助企业有效避免云厂商锁定,避免企业陷入云服务是唯一解决方案的陷阱。

总之关于自建还是全托管哪个更省钱这件事,从来都是公说公有理,婆说婆有理。
最“扎心”的质疑在这里,尽管作者在文章中也说了自己就是完全为了满足自己的需求来做了一个这样的系统,对于这家公司所说的“自建数据库”的说法,许多网友表示不赞同。但是网友指出系统中的数据类型单一,由固定宽度字段组成。没有查询语言,查询似乎仅限于一个固定宽度的 ID 和布尔值的位图。由于只有一个数据类型在一个“表”中,所以没有连接操作。除了在形式上符合 ACID 之外,并没有提供任何 ACID 的功能。有位老兄直接说,“我不是批评谁,我觉得他们压根也不需要数据库,他们开发这个就是个可查询日志文件,不是个数据库。”

“似乎每个人都在专注于数据库这个词以及编写数据库所需的工程成本。但实际上,这只是一个日志文件。”

也有网友补充道,“对该文章的主要批评是他们并没有编写一个数据库,而是编写了一个具有有限查询功能的追加日志系统。那么文章叫自建数据库就不合适了。”
不过也有表示认同这家公司说法的网友,认为“一个数据库需要能够存储结构化数据并进行检索”,该公司所描述的符合这个标准。

再说了,许多非 SQL 数据库实际上在其核心不也就是是可查询的日志吗。
还有人说,你写半天,感觉自建的就是一个简化版本的 Cassandra。
还有网友认为,可以理解。他们不在乎丢数据,这就排除了数据库 99% 的 use case 了。

反方小伙伴说,要是看数据库的定义,说它是数据库也不为过。
这句话马上遭到了反驳,你要是这么说的话,我最喜欢的数据库是 slack。
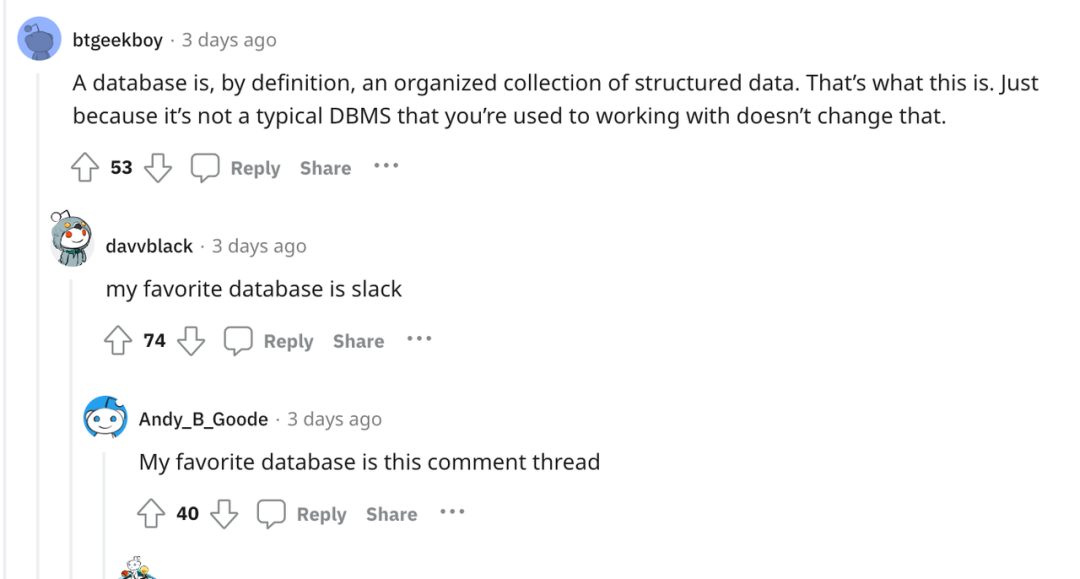
对于自建方案替换云厂商方案的帖子,一般都少不了推荐其他产品的评论。
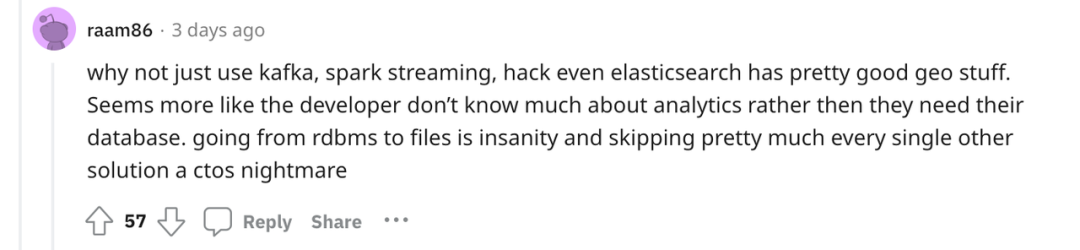
有网友说,针对这样的场景,为啥不用 kafka 之类的流数据管理系统呢。他们对地理数据的处理也很擅长。
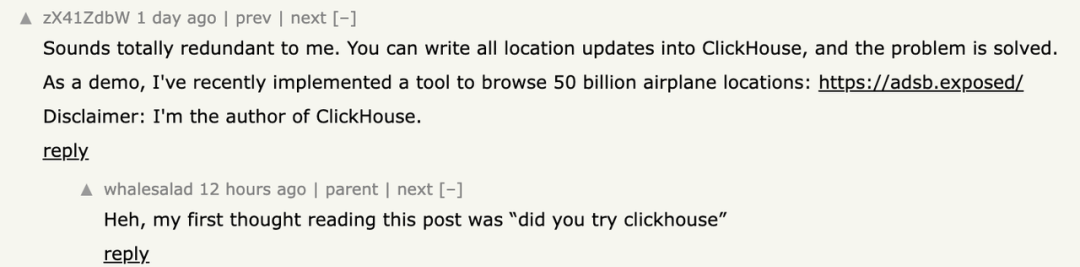
ClickHouse 的作者看到这篇帖子立刻表示,自建的操作略显多余,“可以将所有位置更新写入 ClickHouse,问题就解决了”,并顺便附上了产品 demo(https://adsb.exposed/)。
也有网友推荐 Apache Cassandra、DuckDB、TileDB 的,但是自建有时候似乎是最让自己感到需求被满足的方式。

当然了,管他用啥呢?咱们程序员就喜欢啥都自己干啊,毕竟很多时候自己做的才是最适合自己的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721