
云雨雪,一台无情的编码机器,一个写博客的乐子人,梦想是让这痛苦压抑的世界绽放幸福快乐之花,向美好的世界献上祝福。个人公众号《神独自在的技术生活》。
前言
笔者负责的核心运算系统在运维的时候,被投诉运算不出数据,同事上手运维,一波索引优化给系统干崩溃了。
本质就是索引操作不当,Navicat的编辑索引其实就是合并了删除新增两条命令,问题就出在索引删除后,SQL过慢超过了网关的60s超时时间,页面响应失败。由于表数据量过大,SQL过慢,直接阻塞,连接池也满了,数据库创建新连接时直接报经典错误Communications link failure,一系列连锁反应后,宣告系统中断。
这种情况其实非常无奈,最好的法子就是等待索引创建完毕,此时即使Kill trx_id也无济于事,还有新的SQL加入。但是笔者也不能束手无策,坐着干等,于是临时建了新表,跑了一版最新的数据,代码指向新表,来保证新加入运算的数据没有问题,这个过程大概花了2小时,后续又花了2小时来处理历史数据。
一、故障报告截选
xxxx-xx-xx 11:52 业务方反馈订单交付没有运算到数据,IT响应用户并开始定位问题。
xxxx-xx-xx 12:00 IT定位问题发现是订单交付实时运算变慢,选择临时对用户需求的数据进行单独处理。
xxxx-xx-xx 12:20 远程调用线上接口,对该行数据进行处理,问题解决完毕。
xxxx-xx-xx 14:08 由于频繁收到业务方的数据缺失问题,开始盘点订单交付现存问题,问题如下:
1. 部分表数据由于数据膨胀,导致计算的速度已不能支持实时的计算架构,该问题直接导致业务方发现数据丢失(其实不是丢失,而是没算到那里,只是现状是丢失)。
2. 部分SQL定位后,极慢,影响了运算速度。
3.交期查询页面速度慢,超过网关限时会导致页面报错。
xxxx-xx-xx 16:15 业务方再次提出数据丢失和慢的问题,IT选择临时对线上大表进行优化,但是处理索引不当,导致索引在变更的时候失效。因为大表查询过慢,交期列表查询过慢,页面超时报错。
xxxx-xx-xx 17:05 由于大表过大,无法进行操作,无论是改索引,还是处理数据均无法操作。选择临时新建一张表,跑一版数据后,代码指向新表,保证页面运行。并重新优化交期列表查询,提升列表查询速度。
xxxx-xx-xx 18:02 IT验证通过,并告知业务方服务已恢复,业务方使用后发现不影响操作,但是部分数据存在问题。
xxxx-xx-xx 20:37 IT定位后,将历史数据进行处理后输入新表,验证无误后告知业务方处理完毕。
二、MySQL数据表现状
当时处理得比较匆忙,最近笔者把这张大表拖到测试库,针对性地进行了一些测试。这是一张一亿多行数据的表,表数据图截取的Navicat界面。
后文中会用table_name替换真正的表名od_no_order_product_storage_plan_detail_copy2_copy1,虽然知道读者肯定会吐槽,但是测试表忘了改名了,等想起来也嫌麻烦不想弄第二次了。
查询索引SHOW INDEX FROM table_name;两种创建索引的方式,唯一的区别是CREATE INDEX不可操作主键。CREATE INDEX index_name ON table_name (column_name);ALTER TABLE table_name ADD INDEX index_name (column_name);
当前表创建索引如下:

count语句用时:

用上索引覆盖的语句效率:

不用索引的效率:

删除索引时间几乎等于无,因此后续实验仅考虑创建索引。


三、MySQL操作实验记录
常规可以使用:
查询正在执行的进程 SELECT * FROM information_schema.PROCESSLIST where length(info) >0
查询是否锁表 show OPEN TABLES where In_use > 0;
查看正在锁的事务 SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
查看等待锁的事务 SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
查询正在执行的事务:SELECT * FROM information_schema.INNODB_TRX
删除事务线程 kill (trx_mysql_thread_id)
如果要看很详细的,可以获取 InnoDB 引擎的状态信息:SHOW ENGINE INNODB STATUS,以下是截取返回信息中的其中一段,是同一个SQL对应事务的两次查询结果。
第一次---TRANSACTION 93275186, ACTIVE 6 sec fetching rowsmysql tables in use 1, locked 124978 lock struct(s), heap size 2597072, 3308094 row lock(s), undo log entries 544721MySQL thread id 4873714, OS thread handle 139964454049536, query id 238156684 10.40.148.80 root updatingUPDATE od_no_order_product_storage_plan_detail_copy2_copy1 set is_delete=1 WHERE type='通讯'-------第二次---TRANSACTION 93275186, ACTIVE 155 sec fetching rowsmysql tables in use 1, locked 1772258 lock struct(s), heap size 80273616, 102147669 row lock(s), undo log entries 9524891MySQL thread id 4873714, OS thread handle 139964454049536, query id 238156684 10.40.148.80 root updatingUPDATE od_no_order_product_storage_plan_detail_copy2_copy1 set is_delete=1 WHERE type='通讯'--------
这段日志表示正在进行的一个 MySQL 事务的状态信息,解释如下:
TRANSACTION 93275186, ACTIVE 155 sec fetching rows:这部分指示了当前事务的信息。TRANSACTION 表示这是一个事务。93275186 是事务的标识符。ACTIVE 155 sec 表示事务处于活动状态,已经持续了 155 秒。fetching rows 表示正在获取行。
mysql tables in use 1, locked 1:表示正在使用的 MySQL 表数为 1,其中被锁定的表数为 1。
772258 lock struct(s), heap size 80273616, 102147669 row lock(s):这部分提供了有关锁的信息。772258 lock struct(s) 表示该事务涉及 772258 个锁结构。heap size 80273616 表示锁结构在内存中的大小。102147669 row lock(s) 表示该事务涉及 102147669 个行级锁。
undo log entries 9524891:表示事务的撤销日志条目数。
MySQL thread id 4873714, OS thread handle 139964454049536, query id 238156684 0.40.148.80 root updating:这部分提供了关于 MySQL 线程的信息。MySQL thread id 4873714 表示当前线程的 MySQL 线程标识符是 4873714。OS thread handle 139964454049536 表示操作系统中对应的线程句柄是 139964454049536。query id 238156684 表示当前查询的标识符。10.40.148.80 表示客户端的 IP 地址。root 表示当前查询的用户。updating 表示正在进行的操作是一个更新操作。
综上所述,这段日志表示正在进行的一个活动状态的事务,该事务正在更新名为 od_no_order_product_storage_plan_detail_copy2_copy1 的表,将 type 字段为 '通讯' 的行的 is_delete 字段设置为 1。
1)一个索引更新语句接着并行执行另一个非索引更新语句


索引更新先执行,接着执行非索引更新的,可以发现,后来全表扫描的非索引更新语句被锁住,猜测原因是因为两者扫描数据集有交集。
2)两个非索引更新表锁表
顺序执行如下两个没有用到索引的SQL的Update语句:
UPDATE table_name set is_delete=1 and update_time='2023-08-22 20:17:23' WHERE type='通讯'
UPDATE table_name set is_delete=0 and update_time='2024-01-22 20:17:23' WHERE type='外协'

第二个SQL因为被等待锁超时直接挂掉了。
在 MySQL 中,默认的锁等待超时时间是50秒。这意味着当一个事务在等待锁超过50秒时,MySQL 将自动终止该事务,并抛出一个死锁错误。这个超时时间可以通过参数 innodb_lock_wait_timeout 进行配置。
可以通过以下命令来查看当前的锁等待超时时间:SHOW VARIABLES LIKE 'innodb_lock_wait_timeout';
如果需要更改默认的锁等待超时时间,可以使用以下命令:SET GLOBAL innodb_lock_wait_timeout = 60; -- 将锁等待超时时间设置为60秒
但要注意的是修改这个值可能会影响系统的性能和并发处理能力,因此应谨慎调整。
3)两个索引更新集不相交


以上数据来源于两个都用到了索引的更新语句,如上显示当更新数据集不相交的时候,更新不会阻塞。
4)两个索引更新集相交
首先准备下数据,将UPDATE detail_test set master_id='9' WHERE market_code_name='白牌',创建索引master_id,接着先后执行下面两个语句:
UPDATE detail_test set storage_bom_code='bom1' WHERE market_code_name='白牌'
UPDATE detail_test set remark='666欧规' WHERE master_id='9'


测试结果如上图,决定更新是否互相锁住的根本原因就是,更新集是否相交,如果命中索引,那更新集局限于索引的数据范围,相比全表会小不少。
以下是加索引后查询的三种状态,master_id字段类型是varchar(200),这里图一因为隐式类型转换,导致索引失效走了全表。

图二是查询条件查出来即使没有实际数据被检索,也就是查询结果数为0。MySQL仍然会执行查询计划,并且通常会估计检索一行数据的成本,因此,row字段仍然显示为1。

图三就是正常索引记录,filtered表示通过查询条件获取的最终记录行数占通过type字段指明的搜索方式搜索出来的记录行数的百分比。

1)先Create Index再Update最后Select

结论是毫无影响,三个SQL并行运行。
2)修改表字段结构再操作Update
修改字段A的数据结构为varchar(1000)

这里通过SHOW FULL PROCESSLIST得知两个更新语句被锁住。

通过查询正在执行的事务:SELECT * FROM information_schema.INNODB_TRX,发现两个Update语句连事务都没有发起,当前事务的trx_tables_locked有值说明也锁住了表。

在SHOW OPEN TABLES(https://dev.mysql.com/doc/refman/5.7/en/show-open-tables.html)结果中,也可验证表已被锁。
In_use字段在表中表示表锁或锁请求的数量。例如,如果一个客户机使用锁表t1写的表获得一个锁,那么In_use将是1。如果另一个客户端问题锁表t1写,而表仍然锁定,客户端将阻塞等待锁,但是锁请求导致In_use为2。如果计数为零,表是打开的,但目前没有使用。
Namelocked字段表示表名是否被锁定。如果Namelocked字段的值为1,则表示表名已经被锁定,可能有其他会话正在执行对该表的DDL操作,比如重命名、删除等操作。这意味着在表名被锁定期间,其他会话可能无法对该表执行相同类型的DDL操作,直到锁被释放。
查询不受影响,MVCC的快照读立大功,具体原理见八股文口语化讲解MySQL。

这里让我比较意外的是,这个SQL没有因为innodb_lock_wait_timeout超时,我猜是没有开启事务的原因。

1)先Update再Create Index最后Select
更新语句,没有用到索引。

查询语句同样没有用到索引。

更新语句之后增加索引,该DDL语句会被锁住,同时锁住后面的查询语句。

更新语句锁释放后,增加索引和查询并行执行,这里可以看到查询快于增加索引语句结束。

2)先Update再Drop Index最后Select
顺序反过来测试一下,先执行UPDATE语句,此时用到了索引。

再删除语句用到的索引,DROP INDEX master_idx ON table_name;
接着乘着DROP INDEX被阻塞的时候执行索引查询SELECT * FROM table_name WHERE master_id='6'
此时会发生如下现象,当前运行事务只有Update一个:

SHOW FULL PROCESSLIST;中显示Drop Index和Select语句都在等待锁释放。

注意这里,很有趣的一点是明明Drop Index比Select早运行,但是还是被后来的Select锁住了,这应该是个优化,希望有大佬解答原理。

3)先Delete再Drop Index最后Select
首先保证删除用到了索引。

这里能看到和Update不同的是,Delete不会锁Select语句。

并且和Update有着相同的优化,明明Drop Index比Select早运行,但是还是被后来的Select锁住了。

四、TiDB配置对比MySQL说明

TiDB的表数据是通过DataX直接同步过来的,还是很快,数据量是12.2G,比MySQL同样数据的表大了600MB,我猜测是分布式数据库做的一些用空间换时间的优化,以及数据存储上的一些差异。

MySQL测试机器用的16G,配置buffer pool是8G,并发8,算是常规配置,之前有写过如何配置从零开始的SQL修炼手册-实战篇,TiDB即使是测试,配置也远超MySQL,所以性能是没必要强行对比。
五、TiDB增删索引
MySQL5.7:

TiDB的索引可以调,但是默认的也比5.7的快多了。

SHOW VARIABLES LIKE '%tidb_ddl_reorg%';
//当添加索引操作的目标列被频繁更新(包含 UPDATE、INSERT 和 DELETE)时,调大上述配置会造成较为频繁的写冲突,使得在线负载较大;同时添加索引操作也可能由于不断地重试,需要很长的时间才能完成。此时建议调小上述配置来避免和在线业务的写冲突。
SET @@global.tidb_ddl_reorg_worker_cnt = 4;
SET @@global.tidb_ddl_reorg_batch_size = 256;

//当添加索引的目标列仅涉及查询负载,或者与线上负载不直接相关时,可以适当调大上述变量来加速添加索引:
SET @@global.tidb_ddl_reorg_worker_cnt = 16;
SET @@global.tidb_ddl_reorg_batch_size = 4096;
将默认参数拉高后的效果并不是很明显,我之前测试别的数据时效果明显一些,这部分性能评估可能和数据量和TiDB本身的执行策略有关,暂时不深究。
六、TiDB操作实验记录
首先设置单条查询的内存使用限制-默认1G,设置为3G,SET GLOBAL tidb_mem_quota_query = 3221225472;不然Update语句老报错。

按照顺序执行SQL后,得到的结果和MySQL居然是不一样的,这是我没想到的。在删除索引的语句后,查询语句理所当然地执行了全表扫描。

这里打开TiDB Dashboard的慢查询页面仔细看一下各个SQL的执行过程。

首先最晚开始的查询语句,却是最早执行完毕的,和MySQL不一样的是完全没有被锁住,而是直接走了全表查询。
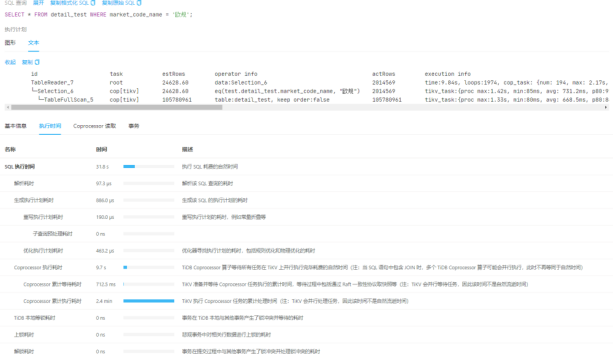
Update语句是最先执行的语句,用到了SQL,并发起了事务。
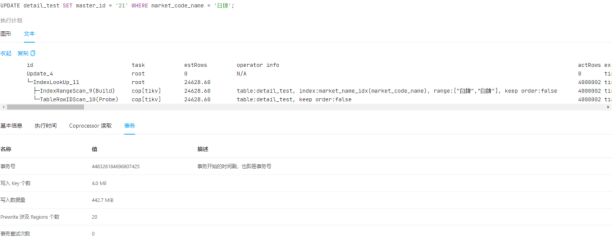
Drop Index语句的执行详情让我蚌埠住了,完全没有锁,说删就删了。
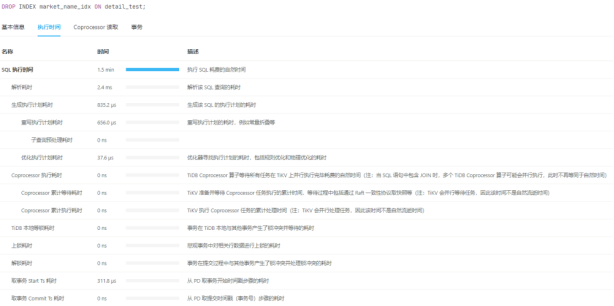
关于TiDB的没搞太明白,这里也不深究了。主要也是因为线上TiDB出问题几乎没有,除了写入并发量难以优化之外,别的也没啥说的。
七、实验结论
尽管实验比较粗糙,但是还是可以得出一些结论,简单总结一下。
DML语句尽量命中索引,缩小更新数据范围,避免全表扫描或者更新数据集相交从而锁住后续DML语句。
给Update或者Delete的字段增加索引不会锁,但是删除索引会锁表并且会阻塞命中索引的查询语句。
修改表字段结构的操作会锁全表,但是只影响DML语句不影响查询语句。
八、故障回顾
具体细节记不太清楚了,说实话我没复现出来,当时明明只是删除了索引,但是增加索引这一步迟迟没有成功,数据库像是被打崩了。按照我上面的实验结论来讲,增加索引是可能正常执行的,很奇怪。
因为当时我主要负责这个项目,所以是我拉着同事去做的解决,我当时是双管齐下,我去解决数据库的响应问题,他去临时创建表做备用方案。当时操作数据库的细节我忘了,只记得非常卡,什么操作都没用,也有可能是我太着急了,反正这条路是断了。也是着急恢复系统,所以直接启用备用方案,让PM去安抚用户,我和同事开发测试上线,跟领导汇报情况,真是裂开了。
事后也是没有能成功复现当时那种奇怪的现象,比较可惜。接下来用一段话来总结这次令人难忘的线上事故,注意嗷,这是重点。
令人难忘的线上事故,还是挺多的,因为是容器化部署,像是遇到JVM之类的OOM或者CPU满了的问题,通常会触发自动重启,一定程度上减少了中断的时间。所以我自己觉得还是数据库上面的问题更严重些,违规操作数据库之类的。
去年底我负责的核心系统也就是订单交付就出现了这么一起长达两小时中断的事故。起因是用户投诉数据过了十几分钟还没有运算出来,经过排查后发现是运算太慢了,再定位是发现有一张MySQL表数据膨胀到亿级,导致SQL查询缓慢从而拖累了运算速度。
当时直接交给同事处理,同事在测试环境修改了索引发现速度变快,于是直接操作了正式库索引。于是索引失效造成了一系列连锁反应,首先是日志疯狂告警,提示运算失败,然后用户所在的网页端因为调用网关超时而报错,投诉蜂拥而来。我通过日志定位到是数据库连接失败,发现Navicat连接异常慢,还有几率出现连接失败,查询进程发现查询大表的索引失效。为了尽快恢复线上环境,临时关闭了实时运算,kill掉所有事务,增加了一张临时表,本地重跑了一版数据放到新表,并修改代码指向新表,测试无误后上线。上线后接着处理这段时间的历史数据,并恢复实时计算,中断时间大约是两小时。
事后写了故障报告,复盘了下这次的处理,做得不好的地方就是一开始在纠结数据库的问题,总是想接着操作数据库,浪费了很多时间。做得好的地方就是双管齐下,同时启用了备用方案,临时建新表,并修改代码指向新表,也算是快速解决了问题。
最后我自己做了一些实验去避免线上操作的问题:
索引一般不要轻易删除,增加索引问题不大。
绝对不能修改表和字段数据结构,会直接锁住DML语句。
DML语句尽量命中索引,更新数据集相交会导致DML语句争夺锁造成等待。公司对这种情况也做了权限管控,通过堡垒机做了权限管控和监控,还有自研开发服务平台来控制数据库的链接权限。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721