
导语:如何充分发挥 SQL 能力,是本篇文章的主题。本文尝试独辟蹊径,强调通过灵活的、发散性的数据处理思维,就可以用最基础的语法,解决复杂的数据场景。
1、初衷
如何高效地使用 MaxCompute(ODPS)SQL ,将基础 SQL 语法运用到极致。
在大数据如此流行的今天,不只是专业的数据人员,需要经常地跟 SQL 打交道,即使是产品、运营等非技术同学,也会或多或少地使用到 SQL ,如何高效地发挥 SQL 的能力,继而发挥数据的能力,变得尤为重要。
MaxCompute(ODPS)SQL 发展到今天已经颇为成熟,作为一种 SQL 方言,其 SQL 语法支持完备,具有非常丰富的内置函数,支持开窗函数、用户自定义函数、用户自定义类型等诸多高级特性,可以高效地应用在各种数据处理场景。
如何充分发挥 SQL 能力,是本篇文章的主题。本文尝试独辟蹊径,强调通过灵活的、发散性的数据处理思维,就可以用最基础的语法,解决复杂的数据场景。
2、适合人群
不论是初学者还是资深人员,本篇文章或许都能有所帮助,不过更适合中级、高级读者阅读。
本篇文章重点介绍数据处理思维,并没有涉及到过多高阶的语法,同时为了避免主题发散,文中涉及的函数、语法特性等,不会花费篇幅进行专门的介绍,读者可以按自身情况自行了解。
3、内容结构
本篇文章将围绕数列生成、区间变换、排列组合、连续判别等主题进行介绍,并附以案例进行实际运用讲解。每个主题之间有轻微的前后依赖关系,依次阅读更佳。
4、提示信息
本篇文章涉及的 SQL 语句只使用到了 MaxCompute(ODPS)SQL 基础语法特性,理论上所有 SQL 均可以在当前最新版本中运行,同时特意注明,运行环境、兼容性等问题不在本篇文章关注范围内。
数列是最常见的数据形式之一,实际数据开发场景中遇到的基本都是有限数列。本节将从最简单的递增数列开始,找出一般方法并推广到更泛化的场景。
1、常见数列
1)一个简单的递增数列
首先引出一个简单的递增整数数列场景:
从数值 0 开始;
之后的每个数值递增 1 ;
至数值 3 结束;
如何生成满足以上三个条件的数列?即 [0,1,2,3] 。
实际上,生成该数列的方式有多种,此处介绍其中一种简单且通用的方案。
-- SQL - 1selectt.pos as a_nfrom (select posexplode(split(space(3), space(1), false))) t;
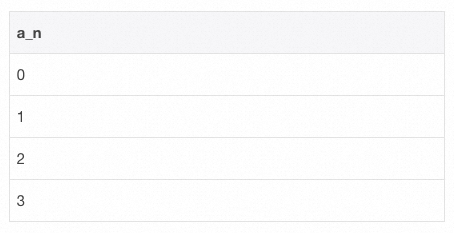
通过上述 SQL 片段可得知,生成一个递增序列只需要三个步骤:
生成一个长度合适的数组,数组中的元素不需要具有实际含义;
通过 UDTF 函数 posexplode 对数组中的每个元素生成索引下标;
取出每个元素的索引下标。以上三个步骤可以推广至更一般的数列场景:等差数列、等比数列。下文将以此为基础,直接给出最终实现模板。
2)等差数列
若设首项 ,公差为
,公差为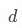 ,则等差数列的通项公式为
,则等差数列的通项公式为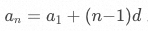 。
。
SQL 实现:
-- SQL - 2selecta + t.pos * d as a_nfrom (select posexplode(split(space(n - 1), space(1), false))) t;
3)等比数列
若设首项 ,公比为
,公比为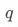 ,则等比数列的通项公式为
,则等比数列的通项公式为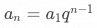 。
。
SQL 实现:
-- SQL - 3selecta * pow(q, t.pos) as a_nfrom (select posexplode(split(space(n - 1), space(1), false))) t;
提示:亦可直接使用 MaxCompute(ODPS)系统函数 sequence 快速生成数列。
-- SQL - 4select sequence(1, 3, 1);-- result[1, 2, 3]
2、应用场景举例
1)还原任意维度组合下的维度列簇名称
在多维分析场景下,可能会用到高阶聚合函数,如 cube 、 rollup 、 grouping sets 等,可以针对不同维度组合下的数据进行聚合统计。
场景描述
现有用户访问日志表 visit_log ,每一行数据表示一条用户访问日志。
-- SQL - 5with visit_log as (select stack (6,'2024-01-01', '101', '湖北', '武汉', 'Android','2024-01-01', '102', '湖南', '长沙', 'IOS','2024-01-01', '103', '四川', '成都', 'Windows','2024-01-02', '101', '湖北', '孝感', 'Mac','2024-01-02', '102', '湖南', '邵阳', 'Android','2024-01-03', '101', '湖北', '武汉', 'IOS')-- 字段:日期,用户,省份,城市,设备类型as (dt, user_id, province, city, device_type))select * from visit_log;
现针对省份 province , 城市 city, 设备类型 device_type 三个维度列,通过 grouping sets 聚合统计得到了不同维度组合下的用户访问量。问:
如何知道一条统计结果是根据哪些维度列聚合出来的?
想要输出 聚合的维度列的名称,用于下游的报表展示等场景,又该如何处理?
解决思路:
可以借助 MaxCompute(ODPS)提供的 GROUPING__ID 来解决,核心方法是对 GROUPING__ID 进行逆向实现。
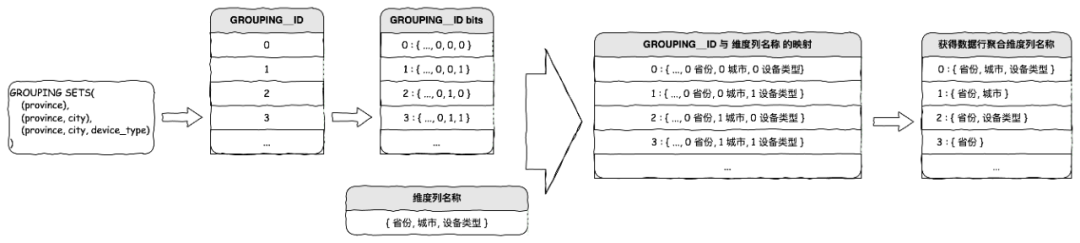
详细步骤如下:
①准备好所有的 GROUPING__ID 。
生成一个包含个数值的递增数列,将每个数值转为 2 进制字符串,并展开该 2 进制字符串的每个比特位。
|
GROUPING__ID |
bits |
|
0 |
{ ..., 0, 0, 0 } |
|
1 |
{ ..., 0, 0, 1 } |
|
2 |
{ ..., 0, 1, 0 } |
|
3 |
{ ..., 0, 1, 1 } |
|
... |
... |
|
|
... |
其中 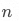 为所有维度列的数量,
为所有维度列的数量,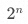 即为所有维度组合的数量,每个数值表示一种 GROUPING__ID。
即为所有维度组合的数量,每个数值表示一种 GROUPING__ID。
②准备好所有维度名称。
生成一个字符串序列,依次保存个维度列的名称,即
{ dim_name_1, dim_name_2, ..., dim_name_n }
③将 GROUPING__ID 映射到维度列名称。
对于 GROUPING__ID 递增数列中的每个数值,将该数值的 2 进制每个比特位与维度名称序列的下标进行映射,输出所有对应比特位 0 的维度名称。例如:
GROUPING__ID:3 => { 0, 1, 1 }维度名称序列:{ 省份, 城市, 设备类型 }映射:{ 0:省份, 1:城市, 1:设备类型 }GROUPING__ID 为 3 的数据行聚合维度即为:省份
SQL 实现
-- SQL - 6with group_dimension as (select -- 每种分组对应的维度字段gb.group_id, concat_ws(",", collect_list(case when gb.placeholder_bit = 0 then dim_col.val else null end)) as dimension_namefrom (select groups.pos as group_id, pe.*from (select posexplode(split(space(cast(pow(2, 3) as int) - 1), space(1), false))) groups -- 所有分组lateral view posexplode(regexp_extract_all(lpad(conv(groups.pos,10,2), 3, "0"), '(0|1)')) pe as placeholder_idx, placeholder_bit -- 每个分组的bit信息) gbleft join ( -- 所有维度字段select posexplode(split("省份,城市,设备类型", ','))) dim_col on gb.placeholder_idx = dim_col.posgroup by gb.group_id)selectgroup_dimension.dimension_name,province, city, device_type,visit_countfrom (selectgrouping_id(province, city, device_type) as group_id,province, city, device_type,count(1) as visit_countfrom visit_log bgroup by province, city, device_typeGROUPING SETS((province),(province, city),(province, city, device_type))) tjoin group_dimension on t.group_id = group_dimension.group_idorder by group_dimension.dimension_name;
|
dimension_name |
province |
city |
device_type |
visit_count |
|
省份 |
湖北 |
NULL |
NULL |
3 |
|
省份 |
湖南 |
NULL |
NULL |
2 |
|
省份 |
四川 |
NULL |
NULL |
1 |
|
省份,城市 |
湖北 |
武汉 |
NULL |
2 |
|
省份,城市 |
湖南 |
长沙 |
NULL |
1 |
|
省份,城市 |
湖南 |
邵阳 |
NULL |
1 |
|
省份,城市 |
湖北 |
孝感 |
NULL |
1 |
|
省份,城市 |
四川 |
成都 |
NULL |
1 |
|
省份,城市,设备类型 |
湖北 |
孝感 |
Mac |
1 |
|
省份,城市,设备类型 |
湖南 |
长沙 |
IOS |
1 |
|
省份,城市,设备类型 |
湖南 |
邵阳 |
Android |
1 |
|
省份,城市,设备类型 |
四川 |
成都 |
Windows |
1 |
|
省份,城市,设备类型 |
湖北 |
武汉 |
Android |
1 |
|
省份,城市,设备类型 |
湖北 |
武汉 |
IOS |
1 |
区间相较数列具有不同的数据特征,不过在实际应用中,数列与区间的处理具有较多相通性。本节将介绍一些常见的区间场景,并抽象出通用的解决方案。
1、常见区间操作
1)区间分割
已知一个数值区间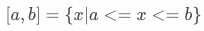 ,如何将该区间均分成 段子区间?
,如何将该区间均分成 段子区间?
该问题可以简化为数列问题,数列公式为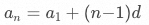 ,其中
,其中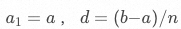 ,具体步骤如下:
,具体步骤如下:
生成一个长度为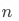 的数组;
的数组;
通过 UDTF 函数 posexplode 对数组中的每个元素生成索引下标;
取出每个元素的索引下标,并进行数列公式计算,得出每个子区间的起始值与结束值。
SQL 实现:
-- SQL - 7selecta + t.pos * d as sub_interval_start, -- 子区间起始值a + (t.pos + 1) * d as sub_interval_end -- 子区间结束值from (select posexplode(split(space(n - 1), space(1), false))) t;
2)区间交叉
已知两个日期区间存在交叉 ['2024-01-01', '2024-01-03'] 、 ['2024-01-02', '2024-01-04']。问:
如何合并两个日期区间,并返回合并后的新区间?
如何知道哪些日期是交叉日期,并返回该日期交叉次数?
解决上述问题的方法有多种,此处介绍其中一种简单且通用的方案。核心思路是结合数列生成、区间分割方法,先将日期区间分解为最小处理单元,即多个日期组成的数列,然后再基于日期粒度做统计。具体步骤如下:
获取每个日期区间包含的天数;
按日期区间包含的天数,将日期区间拆分为相应数量的递增日期序列;
通过日期序列统计合并后的区间,交叉次数。
SQL 实现:
-- SQL - 8with dummy_table as (select stack(2,'2024-01-01', '2024-01-03','2024-01-02', '2024-01-04') as (date_start, date_end))selectmin(date_item) as date_start_merged,max(date_item) as date_end_merged,collect_set( -- 交叉日期计数case when date_item_cnt > 1 then concat(date_item, ':', date_item_cnt) else null end) as overlap_datefrom (select-- 拆解后的单个日期date_add(date_start, pos) as date_item,-- 拆解后的单个日期出现的次数count(1) over (partition by date_add(date_start, pos)) as date_item_cntfrom dummy_tablelateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val) t;
|
date_start_merged |
date_end_merged |
overlap_date |
|
2024-01-01 |
2024-01-04 |
["2024-01-02:2","2024-01-03:2"] |
增加点儿难度!
如果有多个日期区间,且区间之间交叉状态未知,上述问题又该如何求解。即:
如何合并多个日期区间,并返回合并后的多个新区间?
如何知道哪些日期是交叉日期,并返回该日期交叉次数?
SQL 实现:
-- SQL - 9with dummy_table as (select stack(5,'2024-01-01', '2024-01-03','2024-01-02', '2024-01-04','2024-01-06', '2024-01-08','2024-01-08', '2024-01-08','2024-01-07', '2024-01-10') as (date_start, date_end))selectmin(date_item) as date_start_merged,max(date_item) as date_end_merged,collect_set( -- 交叉日期计数case when date_item_cnt > 1 then concat(date_item, ':', date_item_cnt) else null end) as overlap_datefrom (select-- 拆解后的单个日期date_add(date_start, pos) as date_item,-- 拆解后的单个日期出现的次数count(1) over (partition by date_add(date_start, pos)) as date_item_cnt,-- 对于拆解后的单个日期,重组为新区间的标记date_add(date_add(date_start, pos), 1 - dense_rank() over (order by date_add(date_start, pos))) as contfrom dummy_tablelateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val) tgroup by cont;
|
date_start_merged |
date_end_merged |
overlap_date |
|
2024-01-01 |
2024-01-04 |
["2024-01-02:2","2024-01-03:2"] |
|
2024-01-06 |
2024-01-10 |
["2024-01-07:2","2024-01-08:3"] |
2、应用场景举例
1)按任意时段统计数据
场景描述
现有用户还款计划表 user_repayment ,该表内的一条数据,表示用户在指定日期区间内 [date_start, date_end] ,每天还款 repayment 元。
-- SQL - 10with user_repayment as (select stack(3,'101', '2024-01-01', '2024-01-15', 10,'102', '2024-01-05', '2024-01-20', 20,'103', '2024-01-10', '2024-01-25', 30)-- 字段:用户,开始日期,结束日期,每日还款金额as (user_id, date_start, date_end, repayment))select * from user_repayment;
如何统计任意时段内(如:2024-01-15至2024-01-16)每天所有用户的应还款总额?
解决思路:
核心思路是将日期区间转换为日期序列,再按日期序列进行汇总统计。
SQL 实现:
-- SQL - 11selectdate_item as day,sum(repayment) as total_repaymentfrom (selectdate_add(date_start, pos) as date_item,repaymentfrom user_repaymentlateral view posexplode(split(space(datediff(date_end, date_start)), space(1), false)) t as pos, val) twhere date_item >= '2024-01-15' and date_item <= '2024-01-16'group by date_itemorder by date_item;
|
day |
total_repayment |
|
2024-01-15 |
60 |
|
2024-01-16 |
50 |
排列组合是针对离散数据常用的数据组织方法,本节将分别介绍排列、组合的实现方法,并结合实例着重介绍通过组合对数据的处理。
1、常见排列组合操作
1)排列
已知字符序列 [ 'A', 'B', 'C' ] ,每次从该序列中可重复地选取出 2 个字符,如何获取到所有的排列?
借助多重 lateral view 即可解决,整体实现比较简单。
-- SQL - 12selectconcat(val1, val2) as permfrom (select split('A,B,C', ',') as characters) dummylateral view explode(characters) t1 as val1lateral view explode(characters) t2 as val2;
|
perm |
|
AA |
|
AB |
|
AC |
|
BA |
|
BB |
|
BC |
|
CA |
|
CB |
|
CC |
2)组合
已知字符序列 [ 'A', 'B', 'C' ] ,每次从该序列中可重复地选取出 2 个字符,如何获取到所有的组合?
借助多重 lateral view 即可解决,整体实现比较简单。
-- SQL - 13selectconcat(least(val1, val2), greatest(val1, val2)) as combfrom (select split('A,B,C', ',') as characters) dummylateral view explode(characters) t1 as val1lateral view explode(characters) t2 as val2group by least(val1, val2), greatest(val1, val2);
|
comb |
|
AA |
|
AB |
|
AC |
|
BB |
|
BC |
|
CC |
提示:亦可直接使用 MaxCompute(ODPS)系统函数 combinations 快速生成组合。
-- SQL - 14select combinations(array('foo', 'bar', 'boo'),2);-- result[['foo', 'bar'], ['foo', 'boo']['bar', 'boo']]
2、应用场景举例
1)分组对比统计
场景描述
现有投放策略转化表,该表内的一条数据,表示一天内某投放策略带来的订单量。
-- SQL - 15with strategy_order as (select stack(3,'2024-01-01', 'Strategy A', 10,'2024-01-01', 'Strategy B', 20,'2024-01-01', 'Strategy C', 30)-- 字段:日期,投放策略,单量as (dt, strategy, order_cnt))select * from strategy_order;
如何按投放策略建立两两对比组,按组对比展示不同策略转化单量情况?
|
对比组 |
投放策略 |
转化单量 |
|
Strategy A-Strategy B |
Strategy A |
xxx |
|
Strategy A-Strategy B |
Strategy B |
xxx |
解决思路
核心思路是从所有投放策略列表中不重复地取出 2 个策略,生成所有的组合结果,然后关联 strategy_order 表分组统计结果。
SQL 实现
-- SQL - 16select /*+ mapjoin(combs) */combs.strategy_comb,so.strategy,so.order_cntfrom strategy_order sojoin ( -- 生成所有对比组selectconcat(least(val1, val2), '-', greatest(val1, val2)) as strategy_comb,least(val1, val2) as strategy_1, greatest(val1, val2) as strategy_2from (select collect_set(strategy) as strategiesfrom strategy_order) dummylateral view explode(strategies) t1 as val1lateral view explode(strategies) t2 as val2where val1 <> val2group by least(val1, val2), greatest(val1, val2)) combs on 1 = 1where so.strategy in (combs.strategy_1, combs.strategy_2)order by combs.strategy_comb, so.strategy;
|
对比组 |
投放策略 |
转化单量 |
|
Strategy A-Strategy B |
Strategy A |
10 |
|
Strategy A-Strategy B |
Strategy B |
20 |
|
Strategy A-Strategy C |
Strategy A |
10 |
|
Strategy A-Strategy C |
Strategy C |
30 |
|
Strategy B-Strategy C |
Strategy B |
20 |
|
Strategy B-Strategy C |
Strategy C |
30 |
本节主要介绍连续性问题,重点描述了常见连续活跃场景。对于静态类型的连续活跃、动态类型的连续活跃,分别阐述了不同的实现方案。
1、普通连续活跃统计
场景描述
现有用户访问日志表 visit_log ,每一行数据表示一条用户访问日志。
-- SQL - 17with visit_log as (select stack (6,'2024-01-01', '101', '湖北', '武汉', 'Android','2024-01-01', '102', '湖南', '长沙', 'IOS','2024-01-01', '103', '四川', '成都', 'Windows','2024-01-02', '101', '湖北', '孝感', 'Mac','2024-01-02', '102', '湖南', '邵阳', 'Android','2024-01-03', '101', '湖北', '武汉', 'IOS')-- 字段:日期,用户,省份,城市,设备类型as (dt, user_id, province, city, device_type))select * from visit_log;
如何获取连续访问大于或等于 2 天的用户?
上述问题在分析连续性时,获取连续性的结果以超过固定阈值为准,此处归类为 连续活跃大于 N 天阈值的普通连续活跃场景统计。
SQL 实现
基于相邻日期差实现( lag / lead 版)
整体实现比较简单。
-- SQL - 18select user_idfrom (select*,lag(dt, 2 - 1) over (partition by user_id order by dt) as lag_dtfrom (select dt, user_id from visit_log group by dt, user_id) t0) t1where datediff(dt, lag_dt) + 1 = 2group by user_id;
|
user_id |
|
101 |
|
102 |
基于相邻日期差实现(排序版)
整体实现比较简单。
-- SQL - 19select user_idfrom (select *,dense_rank() over (partition by user_id order by dt) as drfrom visit_log) t1where datediff(dt, date_add(dt, 1 - dr)) + 1 = 2group by user_id;
|
user_id |
|
101 |
|
102 |
基于连续活跃天数实现
可以视作 基于相邻日期差实现(排序版) 的衍生版本,该实现能获取到更多信息,如连续活跃天数。
-- SQL - 20select user_idfrom (select*,-- 连续活跃天数count(distinct dt)over (partition by user_id, cont) as cont_daysfrom (select*,date_add(dt, 1 - dense_rank()over (partition by user_id order by dt)) as contfrom visit_log) t1) t2where cont_days >= 2group by user_id;
|
user_id |
|
101 |
|
102 |
基于连续活跃区间实现
可以视作 基于相邻日期差实现(排序版) 的衍生版本,该实现能获取到更多信息,如连续活跃区间。
-- SQL - 21select user_idfrom (selectuser_id, cont,-- 连续活跃区间min(dt) as cont_date_start, max(dt) as cont_date_endfrom (select*,date_add(dt, 1 - dense_rank()over (partition by user_id order by dt)) as contfrom visit_log) t1group by user_id, cont) t2where datediff(cont_date_end, cont_date_start) + 1 >= 2group by user_id;
|
user_id |
|
101 |
|
102 |
2、动态连续活跃统计
场景描述
现有用户访问日志表 visit_log ,每一行数据表示一条用户访问日志。
-- SQL - 22with visit_log as (select stack (6,'2024-01-01', '101', '湖北', '武汉', 'Android','2024-01-01', '102', '湖南', '长沙', 'IOS','2024-01-01', '103', '四川', '成都', 'Windows','2024-01-02', '101', '湖北', '孝感', 'Mac','2024-01-02', '102', '湖南', '邵阳', 'Android','2024-01-03', '101', '湖北', '武汉', 'IOS')-- 字段:日期,用户,省份,城市,设备类型as (dt, user_id, province, city, device_type))select * from visit_log;
如何获取最长的 2 个连续活跃用户,输出用户、最长连续活跃天数、最长连续活跃日期区间?
上述问题在分析连续性时,获取连续性的结果不是且无法与固定的阈值作比较,而是各自以最长连续活跃作为动态阈值,此处归类为 动态连续活跃场景统计。
SQL 实现
基于 普通连续活跃场景统计 的思路进行扩展即可,此处直接给出最终 SQL :
-- SQL - 23selectuser_id,-- 最长连续活跃天数datediff(max(dt), min(dt)) + 1 as cont_days,-- 最长连续活跃日期区间min(dt) as cont_date_start, max(dt) as cont_date_endfrom (select*,date_add(dt, 1 - dense_rank()over (partition by user_id order by dt)) as contfrom visit_log) t1group by user_id, contorder by cont_days desclimit 2;
|
user_id |
cont_days |
cont_date_start |
cont_date_end |
|
101 |
3 |
2024-01-01 |
2024-01-03 |
|
102 |
2 |
2024-01-01 |
2024-01-02 |
引申出更复杂的场景,是本篇文章前面章节内容的结合与变种。
1、区间连续(最长子区间切分)
场景描述
现有用户扫描或连接 WiFi 记录表 user_wifi_log ,每一行数据表示某时刻用户扫描或连接 WiFi 的日志。
-- SQL - 24with user_wifi_log as (select stack (9,'2024-01-01 10:01:00', '101', 'cmcc-Starbucks', 'scan', -- 扫描'2024-01-01 10:02:00', '101', 'cmcc-Starbucks', 'scan','2024-01-01 10:03:00', '101', 'cmcc-Starbucks', 'scan','2024-01-01 10:04:00', '101', 'cmcc-Starbucks', 'conn', -- 连接'2024-01-01 10:05:00', '101', 'cmcc-Starbucks', 'conn','2024-01-01 10:06:00', '101', 'cmcc-Starbucks', 'conn','2024-01-01 11:01:00', '101', 'cmcc-Starbucks', 'conn','2024-01-01 11:02:00', '101', 'cmcc-Starbucks', 'conn','2024-01-01 11:03:00', '101', 'cmcc-Starbucks', 'conn')-- 字段:时间,用户,WiFi,状态(扫描、连接)as (time, user_id, wifi, status))select * from user_wifi_log;
现需要进行用户行为分析,如何划分用户不同 WiFi 行为区间?满足:
行为类型分为两种:连接(scan)、扫描(conn);
行为区间的定义为:相同行为类型,且相邻两次行为的时间差不超过 30 分钟;
不同行为区间在满足定义的情况下应取到最长;
|
user_id |
wifi |
status |
time_start |
time_end |
备注 |
|
101 |
cmcc-Starbucks |
scan |
2024-01-01 10:01:00 |
2024-01-01 10:03:00 |
用户扫描了 WiFi |
|
101 |
cmcc-Starbucks |
conn |
2024-01-01 10:04:00 |
2024-01-01 10:06:00 |
用户连接了 WiFi |
|
101 |
cmcc-Starbucks |
conn |
2024-01-01 11:01:00 |
2024-01-01 11:02:00 |
距离上次连接已经超过 30 分钟,认为是一次新的连接行为 |
上述问题稍显复杂,可视作 动态连续活跃统计 中介绍的 最长连续活跃 的变种。可以描述为 结合连续性阈值与行为序列中的上下文信息,进行最长子区间的划分 的问题。
SQL 实现
核心逻辑:以用户、WIFI 分组,结合连续性阈值与行为序列上下文信息,划分行为区间。
详细步骤:
以用户、WIFI 分组,在分组窗口内对数据按时间正序排序;
依次遍历分组窗口内相邻两条记录,若两条记录之间的时间差超过 30 分钟,或者两条记录的行为状态(扫描态、连接态)发生变更,则以该临界点划分行为区间。直到遍历所有记录;
最终输出结果:用户、WIFI、行为状态(扫描态、连接态)、行为开始时间、行为结束时间;
-- SQL - 25selectuser_id,wifi,max(status) as status,min(time) as start_time,max(time) as end_timefrom (select *,max(if(lag_status is null or lag_time is null or status <> lag_status or datediff(time, lag_time, 'ss') > 60 * 30, rn, null))over (partition by user_id, wifi order by time) as group_idxfrom (select *,row_number() over (partition by user_id, wifi order by time) as rn,lag(time, 1) over (partition by user_id, wifi order by time) as lag_time,lag(status, 1) over (partition by user_id, wifi order by time) as lag_statusfrom user_wifi_log) t1) t2group by user_id, wifi, group_idx;
|
user_id |
wifi |
status |
start_time |
end_time |
|
101 |
cmcc-Starbucks |
scan |
2024-01-01 10:01:00 |
2024-01-01 10:03:00 |
|
101 |
cmcc-Starbucks |
conn |
2024-01-01 10:04:00 |
2024-01-01 10:06:00 |
|
101 |
cmcc-Starbucks |
conn |
2024-01-01 11:01:00 |
2024-01-01 11:03:00 |
该案例中的连续性判别条件可以推广到更多场景,例如基于日期差值、时间差值、枚举类型、距离差值等作为连续性判别条件的数据场景。
通过灵活的、散发性的数据处理思维,就可以用基础的语法,解决复杂的数据场景 是本篇文章贯穿全文的思想。文中针对数列生成、区间变换、排列组合、连续判别等常见的场景,给出了相对通用的解决方案,并结合实例进行了实际运用的讲解。
本篇文章尝试独辟蹊径,强调灵活的数据处理思维,希望能让读者觉得眼前一亮,更希望真的能给读者产生帮助。同时毕竟个人能力有限,思路不一定是最优的,甚至可能出现错误,欢迎提出意见或建议。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721