
本文根据张威老师在〖2023 Gdevops全球敏捷运维峰会-北京站〗现场演讲内容整理而成。(文末有PPT获取方式,不要错过)

讲师介绍
张威,字节跳动图数据库团队架构师,从事图数据库研发,主要Focus存储层,设计并研发第三代分布式图存储层。
分享概要
一、ByteGraph简介
二、ByteGraph 2.0架构介绍
三、ByteGraph 2.0当前问题
四、ByteGraph 3.0解决方案
五、ByteGraph 3.0架构介绍
六、ByteGraph未来展望
七、Q&A
一、ByteGraph简介
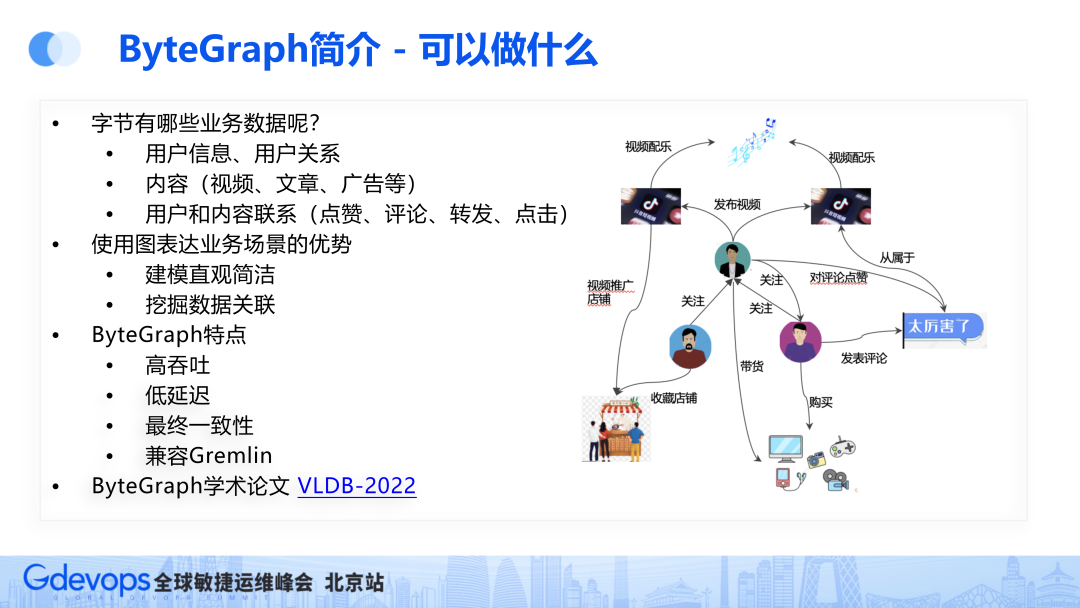
1)字节有哪些业务数据呢?
用户信息、用户关系
内容(视频、文章、广告等)
用户和内容联系(点赞、评论、转发、点击)
用户与用户、用户与内容之间存在关系,用图能够清晰表达这些关系以及点赞、关注等场景。
2)使用图表达业务场景的优势
建模直观简洁
挖掘数据关联
3)ByteGraph特点
高吞吐
低延迟
最终一致性
兼容Gremlin
产品ByteGraph自2018年开始自主研发,截至目前仍持续更新换代。前一代产品的相关论文已经发表在VLDB-2022,下一代的论文也正在路上,欢迎大家关注。
查询接口,即用户怎么使用数据库。

1)Gremlin简介
和SQL语言不同,使用数据库时需要使用一种名为Gremlin的查询语言,这是一种图灵完备的图遍历语言。
相较Cypher等查询语言,Gremlin的功能更全面,上手较为容易,使用更加广泛。主流云厂商图数据库都提供了Gremlin支持。
2)数据模型
有向属性图
点和边上都可以携带多属性,支持动态加减属性列(体验与MySQL的DDL语句较为类似)
举个例子,写一条用户A所有一跳好友中满足粉丝数量大于100的子集。
g.V(vertex(A.id, A.type)).out('好友').where(in('粉丝关注').count().is(gt(100))).toList()
首先定位用户A在图中的点,其次求一跳查询中的所有邻居,判断入度邻居数量是否大于100,拉取满足条件的所有用户。在这个语句中,out是找到用户好友;where是一个条件查询,查询该用户的所有好友;in是粉丝数。这句话整体较为易懂。
2018年的业务发展比较迅猛,同时大家偏向接受简单的事务,Gremlin语言顺应这种需求,所以在业务应用的规模逐渐变大。
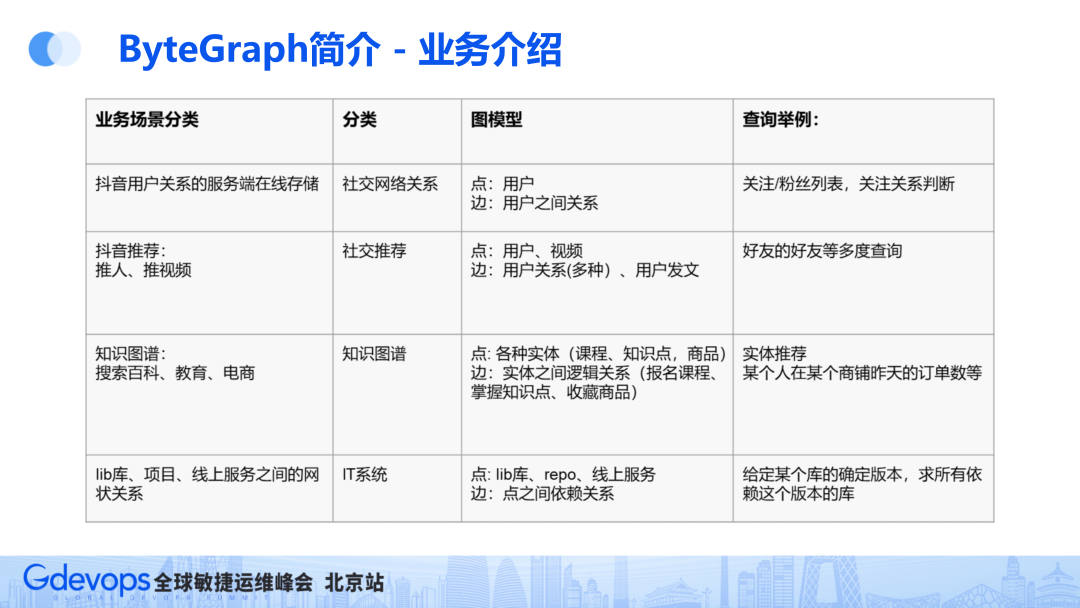
抖音的用户关系(点赞、粉丝等)
抖音推荐(好友在看、好友赞过等场景)
知识图谱(搜索百科、教育、电商团队进行实体推荐)
内部业务(微服务标准链路开发等)
除此之外,抖音的支付场景也比较多,所以也具备一些风控业务。比如产生一笔转账记录,我们需要确认这位用户是否套现,所以要根据该次请求去检测环路,这个过程也应用了图数据库。
目前我们支持超过1000个业务集群,服务器规模已经达到上万台。
二、ByteGraph 2.0架构介绍
当前架构从2018年左右开始搭建,如下图所示分为三层。第一层是查询层 GQ(Graph Query Engine),第二层是存储引擎层GS(Graph Storage Engine),底层则是依赖分布式KV。受到TiDB影响,这种架构在当时非常流行。
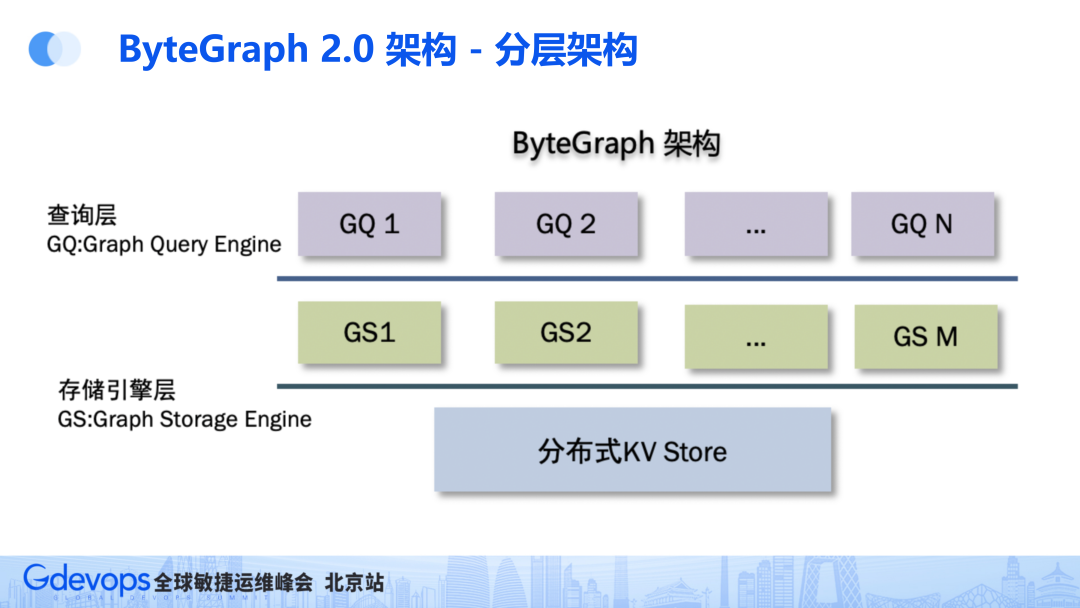
这套架构分为三层,这样做的好处就是每一层都可以独立扩展。
如果查询语句比较复杂,则扩展最上面的查询层;如果内存不足,则扩展内存层;如果存储资源增多,则扩展最下层的分布式KV。这个架构设计具备云时代特征,弹性很好,但也存在层次较多等问题(后文会提到)。
在查询引擎方面,我们为用户提供Gremlin语句。加入Gremlin后,整体与传统数据库类似,首先通过Parser转为AST,然后生成物理计划,最后通过执行器去执行。
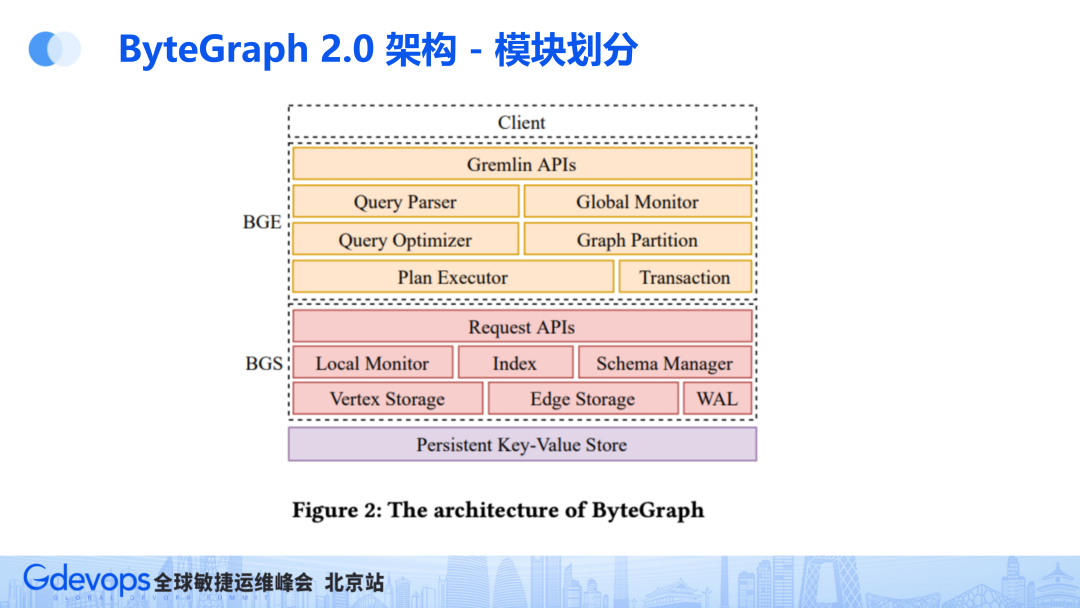
由于ByteGraph是一个分布式数据库,所以分片策略在Graph Partition模块,事务则与分布式事务类似。
存储引擎方面,存一张图不外乎是存点或边,所以将其抽象为两种,一种是纯点,一种是纯边。
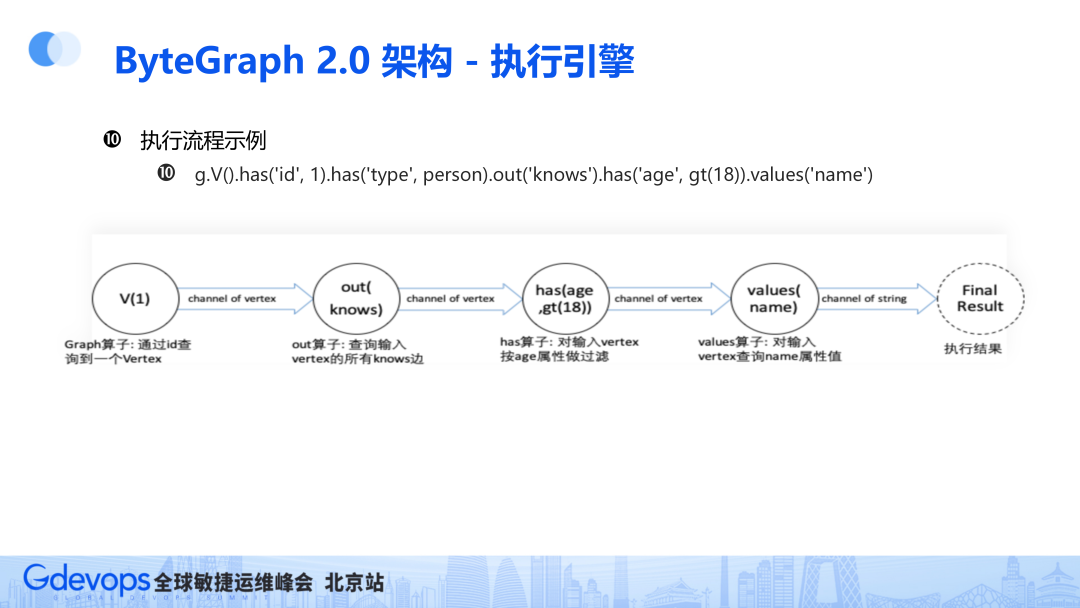
执行流程示例:
g.V().has('id', 1).has('type', person).out('knows').has('age', gt(18)).values('name')
整体语句的意思是找到用户认识的超过十八岁的人,并得到他们的名字。这是一个典型的图查询。
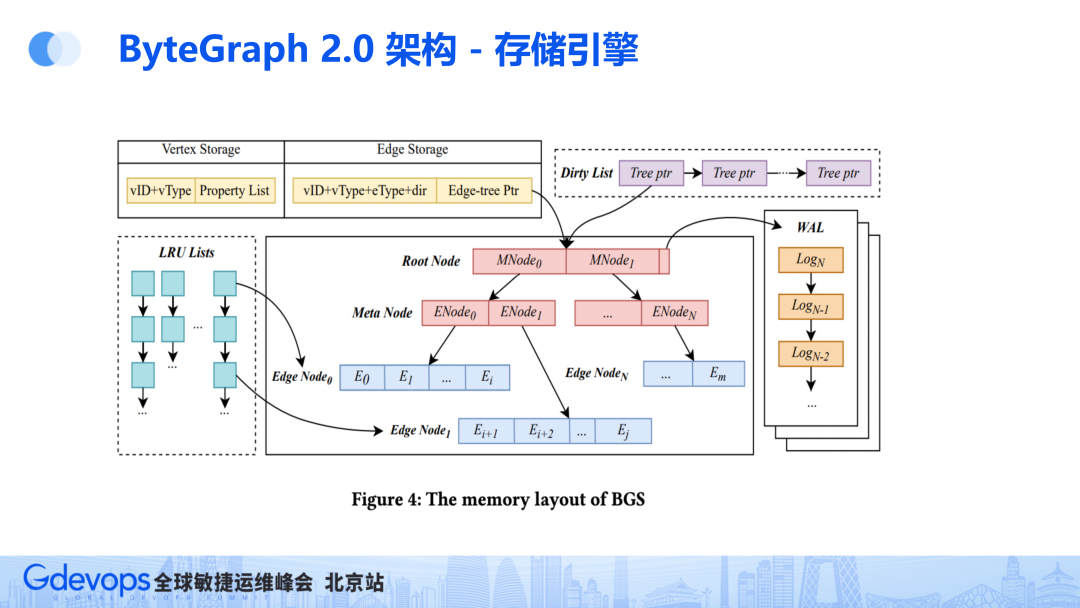
存储引擎包括Vertex Storage(点存储)和Edge Storage(边存储)。
点比较简单,即使包括很多属性,数据量也不大,所以将顶点和类型等属性存储在KV中。
边则比较复杂,比如抖音大V这种具有几百万粉丝的用户,将他几百万个粉丝的边及其属性存到KV显然是不太可能的,会导致写入放大或读取放大,这种情况对KV很不友好。
所以将边按邻接表聚合成为Edge Stroage,再把Edge Stroage组织为Btree,有自己独立的WAL,多个Edge stroage形成一个森林,这样访问不同的邻接表的时候,无需做并发管理。
其它的部分和传统的BTree存储引擎一样(例如InnoDB),共享全局的LRU负责缓存淘汰和Dirty List 负责刷脏。
三、ByteGraph 2.0当前问题
依赖分布式KV部署的带来的成本开销。
1)冗余副本
目前都是3机房3/5副本。如果使用支持EC的池化存储系统作为存储底座,可以将副本数量降低为3机房2副本,节约30%-60%成本。
2)LSM Tree KV 存储引擎本身的问题 (写放大/Compaction造成的CPU消耗)
多层缓存冗余:LSMT(BlockCache)和GS(BufferPool))内部都有大容量缓存模块,缓存了同一份热数据,统一缓存资源能有较高的系统利用率和系统性能;
内存/CPU预留:基于LSM Tree带来的BlockCache以及Share Nothing架构带来的3份Compaction消耗导致存储机型也需要预留CPU/Memory,导致无法使用高密度存储机型,这进一步带来了整体TCO放大;
磁盘预留写放大高(40倍):基于LSM Tree带来写放大开销,在某些场景写能到几十倍,需要预留更多的磁盘资源,导致磁盘利用率低。
分层过多:从上到下来看,Graph 整体为计算层 -> 内存层 -> KV-Proxy 层 -> KV-Server 层,数据写入会穿透四层,cache miss 时数据查询也会穿透四层,延迟和 CPU 开销都难以优化到极致,业务要求更低的延迟;
多跳性能难以做到极致:随着各种社交推荐、风控业务的发展,两条以上的邻居的召回需求增多,例如好友推荐(查询好友的好友)、风险图判断等,当前计算和存储解耦的设计导致在多跳查找中会有大量的RPC开销,难以保障性能;
Per Vertex级别的WAL:细粒度的分片导致分布式事务无法做1PC优化,用户需要优化分布式事务的性能。
单跳/多跳查询是ByteGraph的优势场景,其Workload对于Scan One Hop能力尤其看重(也是线上典型场景)。ByteGraph的数据模型为属性图模型,边上会有若干属性,最基础的Get One Hop算子的物理计划会 会拆解为读取KV 若干Page,然后扫描Page内部的若干条边。
典型的Scan请求经常是只需要根据一列属性过滤然后返回某几列属性,不需要扫描全部的属性列,但是当前Page内是按行存储的,即使只需要部分列,也需要扫描全部的数据,内存访问需要在page内随机跳转,导致内存延迟高,内存带宽高,难以优化性能。
延迟可控的主从同步:当前我们的主从机房的数据一致性为最终一致(通过转发流量),我们需要有一个log based主从同步,为用户提供延迟可控的主从一致性,甚至强一致性读取(满足一些业务写后读的需求)。
四、ByteGraph 3.0解决方案
1)利用EC技术降低副本数量
延续Graph 2.0的 Shared storage设计,继续拥抱弹性,替换KV -> DFS 池化存储,利用低成本ByteStore 3AZ 两副本技术(利用EC)取得成本收益,利用高密度存储机型,进一步降低TCO。
LSMT -> BwTree 合并2.0 GS层Btree引擎/分布式KV的LSMTree引擎,自研基于DFS的BwTree存储引擎,减少写放大,从几十倍可以降低为 2~3倍,减少Compaction开销。
基于Share Storage 架构,避免3份Compaction开销,降低磁盘层开销,弹性扩缩容。
2)利用DFS层简单的Append Only Write API, 减少磁盘层预留的CPU和内存,使用高密度存储机型,进一步降低TCO
合并进程:合并查询引擎和存储引擎为一个进程,减少穿透层数,减少多跳查询RPC开销
减少分片数量:增大分片粒度,主推单分片一主多从架构,非必要不分片(利用Bare-Metal大内存机器来满足性能),如果必须分片,采取Hash 分区的做法进行负载均衡,经过上述调整,事务的1PC比例大幅度增加。注意:在图数据库多跳查询的场景,一定是分片越少(意味着网络通信的大大降低),性能越高。
Btree Page内列存,增强cache locality
自研新一代Pipeline执行引擎,减少通信拷贝开销,感知Numa调度
单分片Tablet级别WAL主从同步,减少2.0架构Vertex 粒度WAL带来的,写入QPS和写流量转发带来的overhead
五、ByteGraph 3.0架构介绍
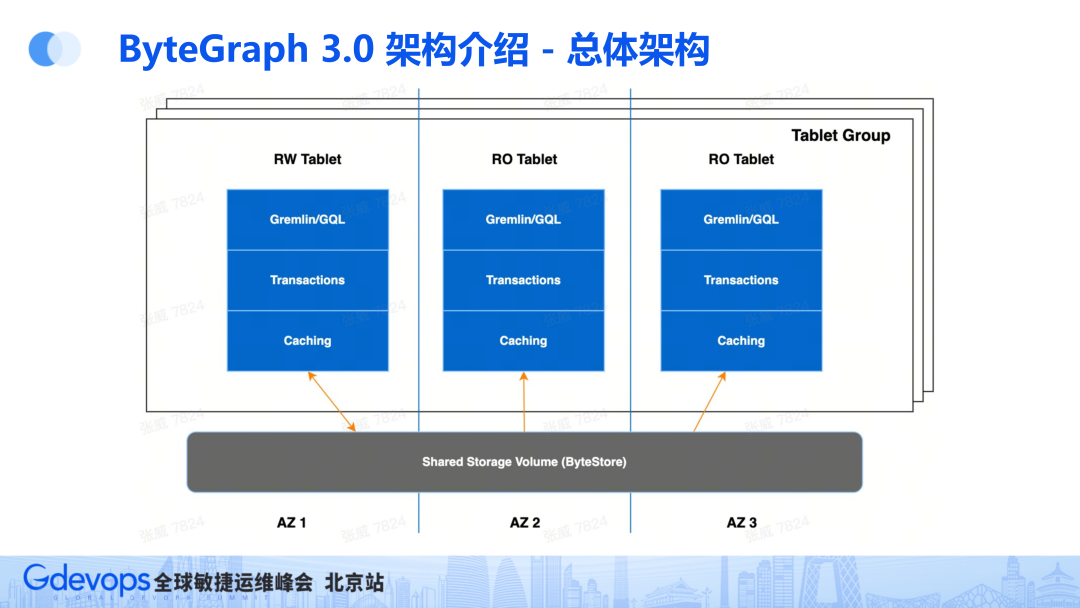
3.0架构将查询引擎和存储引擎合并,类似于MySQL由SQL层和存储引擎层构成。同时为了顺应潮流,做了专门针对图形的查询语言GQL。
整体架构类似Amazon/PolarDB的shared storage架构,shared storage层是基于 byteStore 存储构建,虽然架构相同,但是存储引擎实现细节完全不同,BG3.0是基于DFS自研的BwTree,有更高的性能和更低的写入放大。
数据分为若干Tablet(一般情况默认就一个Tablet,非必要不分片),每个Tablet中存放一部分图的hash分片,每个Tablet有RW和RO,通过共享的Journal 同步数据,数据持久化多副本交给Append Only Blob层解决,可用性通过上层 RW 和 RO 快速切换解决。
注意:这套架构里面没有Proxy,我们将Proxy内置在Tablet内部,第一是为了减少部署Proxy的开销,第二我们可以一主多从模式下减少穿透层带来的开销,提供更高的性能。
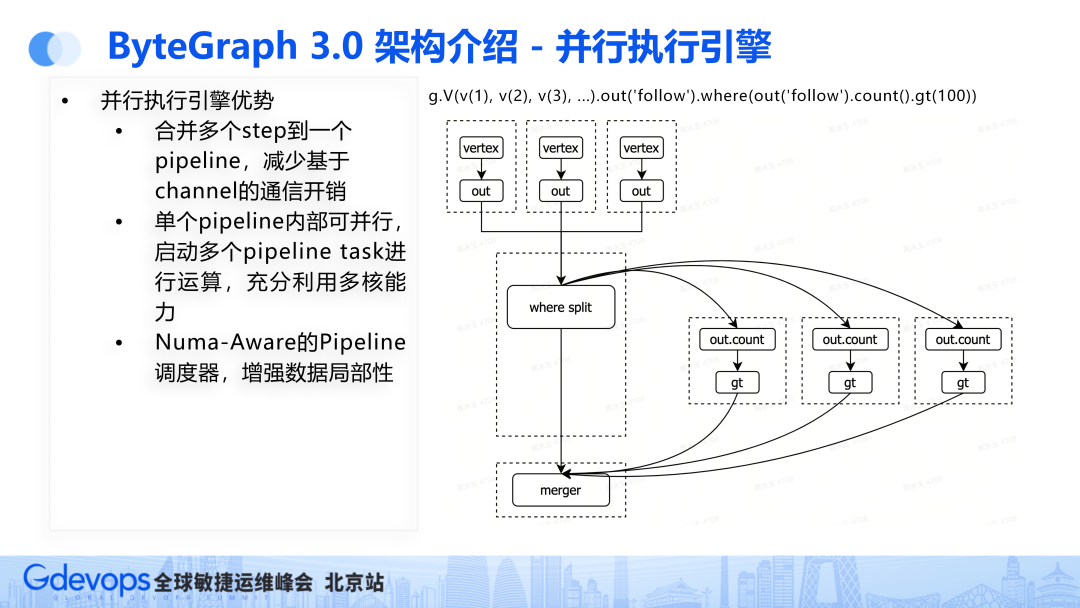
新版的pipeline执行引擎将多个step合并成一个pipeline,减少基于channel的通信开销;
单个Pipeline内部可以提供数据并行,启动多个pipeline task进行运算,充分利用多核能力;
开发numa的piple line task调度器,增强数据局部性。
存储引擎模块分为查询引擎层和存储引擎层(重点关注),整体存储引擎是一个基于共享存储的BwTree存储引擎,支持主从同步。
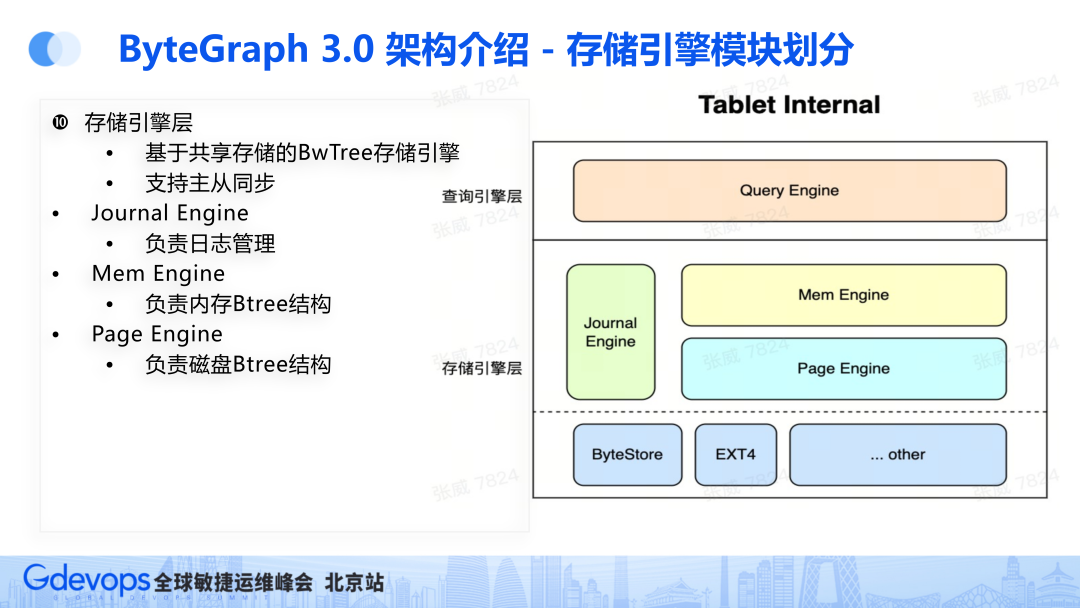
Journal Engine负责日志管理
Mem Engine 整体功能和GS2类似,负责内存Btree 结构
Page Engine负责磁盘Btree结构
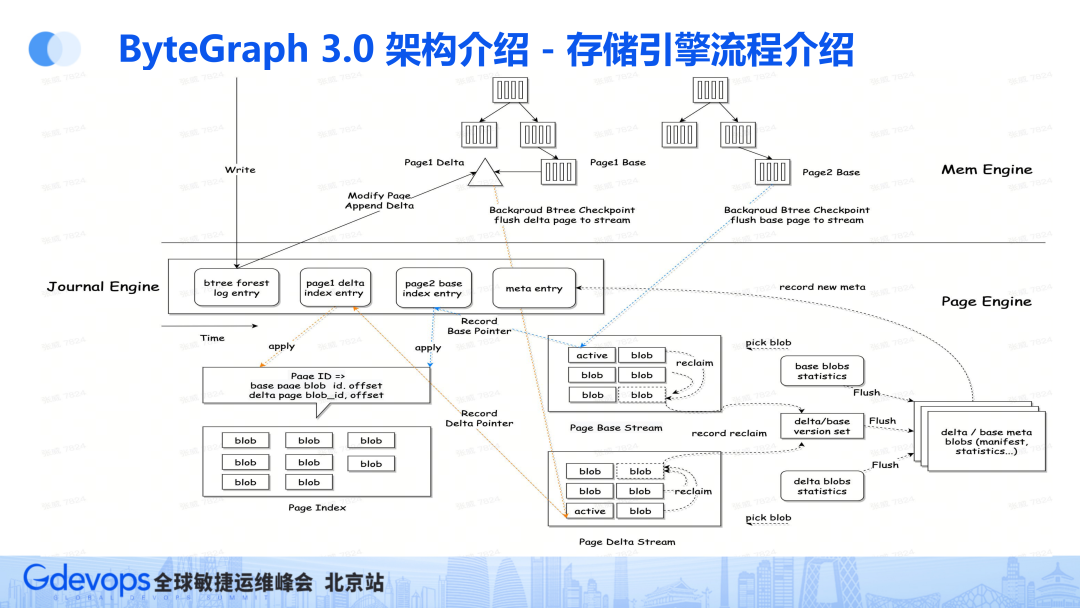
Mem Engine大部分和2.0一样,图分为点和边,边按邻接表聚合成为Edge Stroage,其它的部分和传统的btree存储引擎一样,共享全局的LRU负责缓存淘汰和dirty list 负责刷脏。
不同点:
WAL: 每个btree都有自己的WAL,现在多个Btree共享一条WAL,聚合写入,增大1PC事务比例
点也会按hash规则,也存成若干个btree,减少元数据开销
Flush带宽优化:另外为了减少Flush的流量,我们每个Page上还会挂一个Delta,Flush的过程中对于Dirty Page我们会Base Delta轮转下刷
Page内列式存储:为了提升GetOneHop Scan能力,我们会把点或者边的上的属性按列聚合存储,增强内存访问的locality,加强scan能力
Page Engine 整体分为 Page Index 和 Page Data 模块,接受mem engine 的 page checkpoint流量。
Page Index 作为索引,存储 Page ID 到 Page 实际地址,支持增量落盘,默认情况下全内存缓存,读取索引做到无IO,提供高效查询。
Page Data 存储实际的Page Base/Delta数据,按更新频率不同冷热分离,分别写入Page Base Stream / Page Delta Stream,各自独立GC,目标是减少写放大。
整体写入流程:Memory Engine 的 Btree Page 在做Flush Dirty (Checkpoint)的时候,写入Page Engine,进入到Page Engine内部后,根据是Base/Delta写入不同的Stream的Active Blob,写入成功后,得到BlobID和 Offset,然后更新Page Index 和对应的Blob的统计信息,Page Index/统计信息通过WAL保证持久化,整体完成后写入返回
整体读取流程:Memory Engine Cache Miss,读取Page Engine,先查询Page Index,得到该Page 对应的Base/Delta的地址(BlobID, Offset),然后直接发起IO读取对应Blob,保证至多两个IO
主从复制流程:RW节点和RO节点基于共享存储做主从同步,共享Page Index 和 Page Data,RO节点和RW节点的会有一定的延迟。(注意:Page Index WAL 和 Memory Engine WAL 共享一路Journal做RO同步,通过header来区分,方便统一按一条日志回放的逻辑,方便处理)
先进的reclaim策略:
Base/Delta分离:Delta 更新比较快,Base更新慢,GC Delta 的时候没必要搬运Base,因为Base 大概率是冷的没有更新,分不同的Stream独立GC可以减少整体写放大
基于统计信息的Reclaim:我们为每个Blob维护BlobStatistic(包括Usage,Last Update Time,随着写入更新,定期checkpoint )用来指导空间回收。Pick Blob时同时参考更新频率和Usage两个指标,进行加权,例如可以选择Usage最低的Blob进行GC,或者选择Usage 相对低,但是更新频率低的Blob 进行GC (Min Decline GC)。
六、ByteGraph未来展望
存储成本降低30%-50%;
在单分片场景下,多跳召回场景上可提供数倍于原有系统的性能。
补齐3.0功能,持续上量,持续优化内部业务&火山引擎的服务性能和使用体验。
作为统一存储底座,向上支撑图数据库查询引擎,全图计算引擎,图训练DataLoader等。
打造Single-Engine生态:提供一体化图数据服务。随着图数据库,GNN,图计算越来越广泛的使用,用户对于“图数据的统一存储,处理,流动”有了更高的要求,ByteGraph 3.0 存储层希望提供一套融合多种场景的存储解决方案,通过统一的存储格式,帮助用户打通图数据库、GNN、图计算系统以及Spark/Hadoop生态,真正做到一站式处理。
Q&A
Q1:我想问一下关于Bw-Tree的实现,这是参照微软2013年那篇论文实现的吗?
A1:不是微软的Bw-Tree,大家谈到Bw-Tree一般会想到抓人眼球的Delta node。但我们的Bw-Tree聚焦点并不在此,主要借鉴其中的三项内容:第一个是内存设计;第二个是磁盘设备,微软有一篇介绍配置如何存到磁盘上的论文,我们借鉴了磁盘设计并进行优化;第三个部分是内存中Delta的实现细节上可能不完全一样。
Q2:演讲中介绍到磁盘预留写放大高有40倍左右,目前优化效果如何?主要受益于哪个措施?
A2:写放大能做到两三倍。比如Compaction是写放大的原因,因为每一层都是上一层的10倍,如果有6层,那一次写入推到最后一层就是60倍的情况。这是因为Compaction除了回收垃圾,还会做排序。
Q3:ByteGraph2.0到3.0的计划中提到多跳场景下从 RPC调用,尽可能编程进程调用。我的理解是单机大类型的场景下,数据都在同一台机器,成本确实会减少。但是如果机器很多,还是会产生开销,请问是否进行将亲和性比较强的数据放到同一台机器上此类优化措施?
A3:这个问题很好,我们做图数据库主要是优化多跳的性能,否则就和SQL数据库没有区别了。你的问题在于亲和性,比如将用户和用户的粉丝存储在一起,这很好。但更常见的情况是粉丝群体高达几百万,不太可能都放在一台机器上,还会可能产生流量不均匀等问题。
我们的优化手段秉持着大力出奇迹的理念,换大内存,将BTree的配置从行切成列,由此同一条边的开销占用内存会降低。总之,比起数据分布,我们更希望使用工程优化手段。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721