

一、背景
备份对数据库系统非常重要。当数据由于人为或意外的原因导致被误修改、误删除时,可能会造成服务显示错误或无法访问,进而给业务造成很多损失。部分情况下我们可以通过服务器上的日志立即进行恢复,但是服务器上的日志不会永久保留。如果需要查看整个库中的数据时,日志恢复就不能满足我们的需求。这时如果有一份合适的全量备份将数据库中的数据恢复到指定的时刻,则业务可以立即恢复,挽回损失。所以备份对数据库系统而言是一项必不可少的功能。
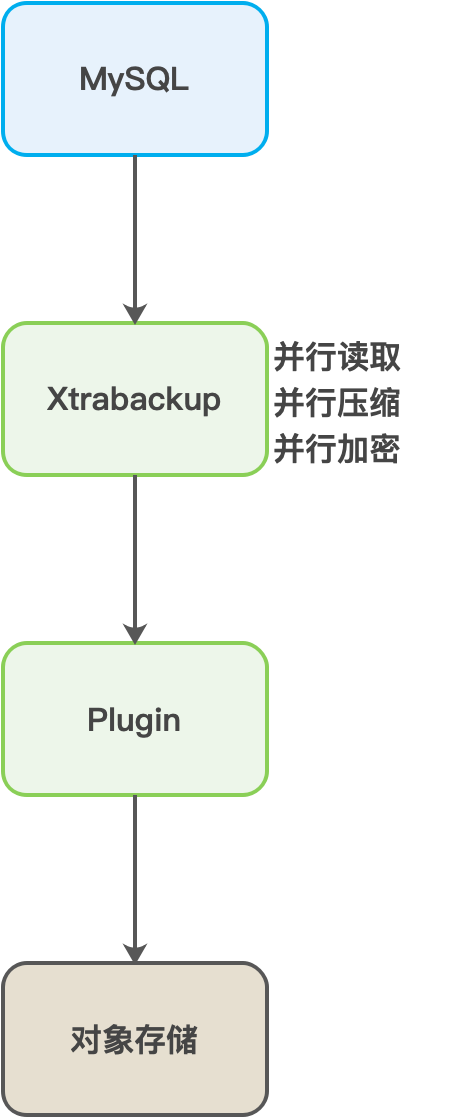
平台老的数据库备份系统采用中转方式进行备份。备份的流程如下:
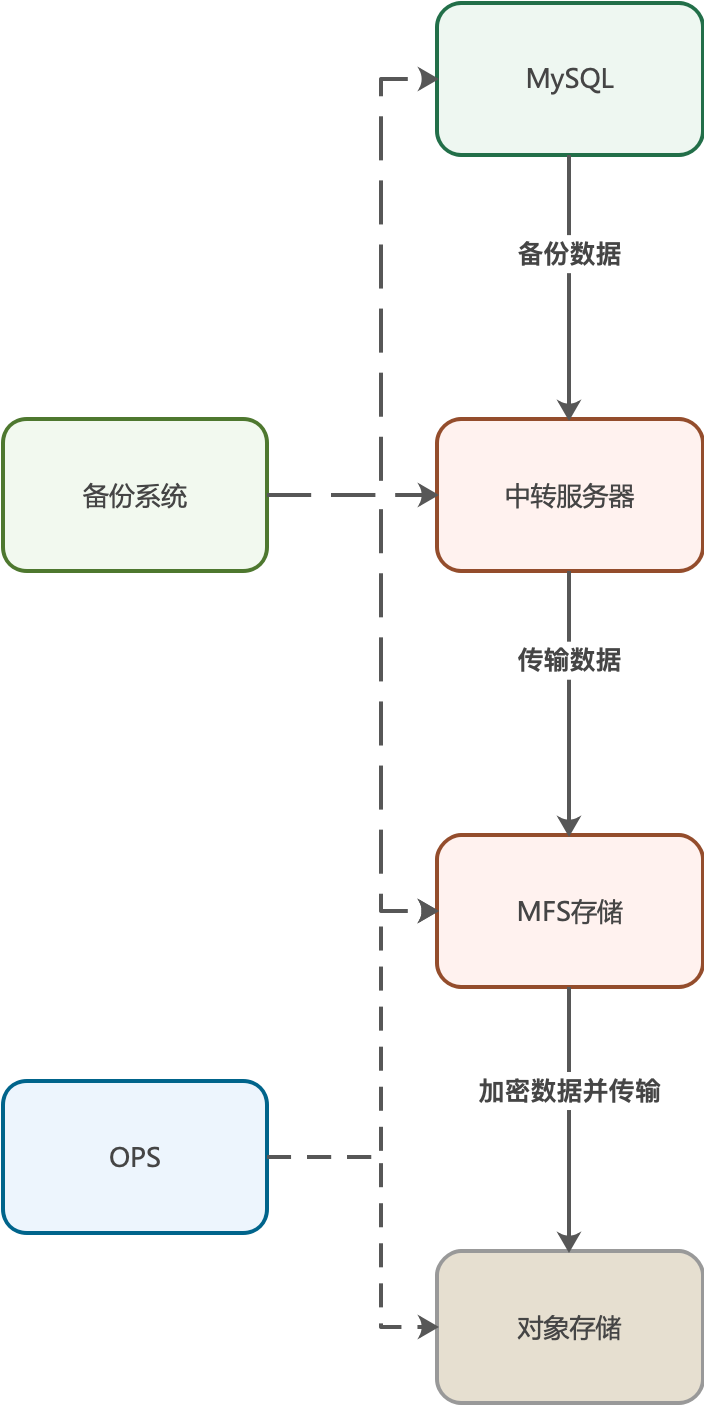
备份系统在中控机上发起备份任务。
备份系统选取相对空闲的【中转服务器】。
备份系统选取合适的【目标实例】。
备份系统在【目标实例】上执行xtrabackup命令,将数据库中的数据传输到【中转服务器】。
等传输完成,备份系统再将数据进行打包、压缩,并上传至【MFS存储】。
OPS会定期将【MFS存储】上的备份文件进行加密,并统一上传至【对象存储】。
老的备份系统在小规模的数据库上运行并没有发现太大的问题,但是随着业务增长,数据库的规模越来越大,备份系统也就暴露出越来越多的问题,有些问题甚至非常严重,会影响到线上数据库服务的稳定性,因此优化和解决这些问题迫在眉睫。
二、问题
经过我们的调研发现老的备份系统存在如下问题:
备份系统依赖ssh服务的稳定性。如果传输中间网络抖动会造成备份批量失败,那就需要清理临时文件,并重传备份。中控机与各个目标服务器之间的ssh连通性非常重要,而中控机上也会有各种各样的服务,这就导致备份任务受到影响的概率比较大。
备份效率比较低,统一限速为30MB/s。由于线上服务器环境比较复杂,高性能的服务器和低性能的服务器共存,并没有针对高性能服务器适配较高的备份速度。
中转服务器存在性能瓶颈。备份过程依赖中转服务器,如果中转服务器磁盘空间不足,则备份将会被推迟,导致备份效率较低。中转服务器的资源也需要进行预分配和回收。随着业务规模的增大,对中转服务器的需求也变大,备份周期也变的越来越大,备份失败的原因超过80%都是和中转服务器相关。
没有对备份文件进行全生命周期的管理。备份系统只是将备份文件传输到MFS存储之后就结束了,由OPS将备份文件上传到对象存储,故不能针对不同重要性级别的备份设置不同的清理策略。
手动恢复效率低下。老的备份系统并没有将恢复做到完全自动化,对象存储上备份文件的下载需要等待OPS完成,才可以进行恢复操作。
备份完成耗时非常长。一个备份从生成到上传到对象存储中间经历太多模块,如果中转服务器出现问题且不可恢复时,那样整个服务器上尚未上传的备份就会全部失效,备份的完整性受到很大的影响,进而会影响后续的恢复时效和可用性。
系统扩展性不足。无论是性能、可用性还是针对不同版本的数据库,老系统均未考虑到扩展性和兼容性。
以上这些问题,不仅会影响数据库备份的时效性和可用性,甚至会影响数据库服务的稳定性和安全性,备份永远是数据库服务最后的护城河,一旦决堤将对业务产生灾难性的后果。
1、分析
通过对上面提到的问题进行综合分析,团队内部总结出了以下两种解决方案:
对老系统进行修复。主要是修复一些严重的bug,但是有的问题难以从根本上解决,而且由于该系统前后经过多人维护,代码风格、逻辑实现不统一,需要投入大量人力去熟悉和修复,成本很高但收效甚微。
重构备份恢复系统。从架构设计上避免老系统的根本问题,并且可以考虑应对未来十年数据库体量的增长。但是在新系统完全接入之前,也需要维护老系统,对其存在的重大bug优先进行修复,确保可用性。
综合考虑成本以及公司未来发展对数据库备份系统的需求,我们更倾向于从根本上解决问题,重构整个备份恢复系统。故针对新系统我们提出了更高的要求,除了避免老系统的各种问题,还要在系统可用性、稳定性、时效性、安全性方面达到一个全新的突破。
1)针对老的备份系统问题
针对老的备份系统存在的问题,我们的设计方案如下:
依赖自动化平台的http通信,仅在备份发起和结束时进行通信,备份过程中只做进度通知,进度通知失败也不影响备份,即使网络抖动也对备份服务无影响。
针对高性能的服务器自动适配较为合适的备份速度,不再统一限速,充分发挥高性能服务器的性能。
去除对中转服务器的依赖,数据库备份流式传输到对象存储上。这样既可以节省大量的服务器成本,又可以方便对对象存储上的备份文件进行全生命周期的管理,缩短备份流程的耗时,并且保证备份的可用率。
个性化备份文件保留策略,针对不同等级的服务配置不同的保留策略,并允许特殊服务进行自定义配置。
备份和恢复需要做到全流程自动化。为了验证备份的可用性,需要定期对备份文件做恢复演练。
2)考虑其他问题
为了防止单个对象存储资源不可用导致备份服务无法进行,新系统需要支持快速切换到其他存储资源。
为了适配各种版本的MySQL和Xtrabackup,新系统需要兼容各种版本的Xtrabackup和MySQL。
备份的过程中会对服务器产生一定的压力,可能会和服务器上面的服务争抢资源。为了避免这种情形系统需要支持负载保护,即如果服务器上某种资源使用率超过指定限额时,立即终止备份,优先保证服务的稳定性。
在选取备份实例时,老系统未考虑到备份实例上服务器的状况,所以新系统需要支持根据配置优选选取符合条件且数据库压力较小的实例。
新系统需要支持扩展任务,可以支持其他类型的备份,例如:逻辑备份、单表备份等,也需要支持其他类型数据库的备份恢复。
考虑业务未来的增量的需求,服务需要做到高性能、高可用、高扩展性,即使未来数据库体量增长十倍也可以轻易支撑。
针对新系统的目标和需求确认完成后,我们就开始设计新系统的架构。
三、设计
1、大背景
目前我们正在构建一套全新的的平台,大体的架构和通讯协议已经完成,基础组件已经开始陆陆续续构建中。由于备份恢复系统需求处于第一位,所以也是这个平台需要完成的第一个大的功能模块。整个平台的架构图如下:
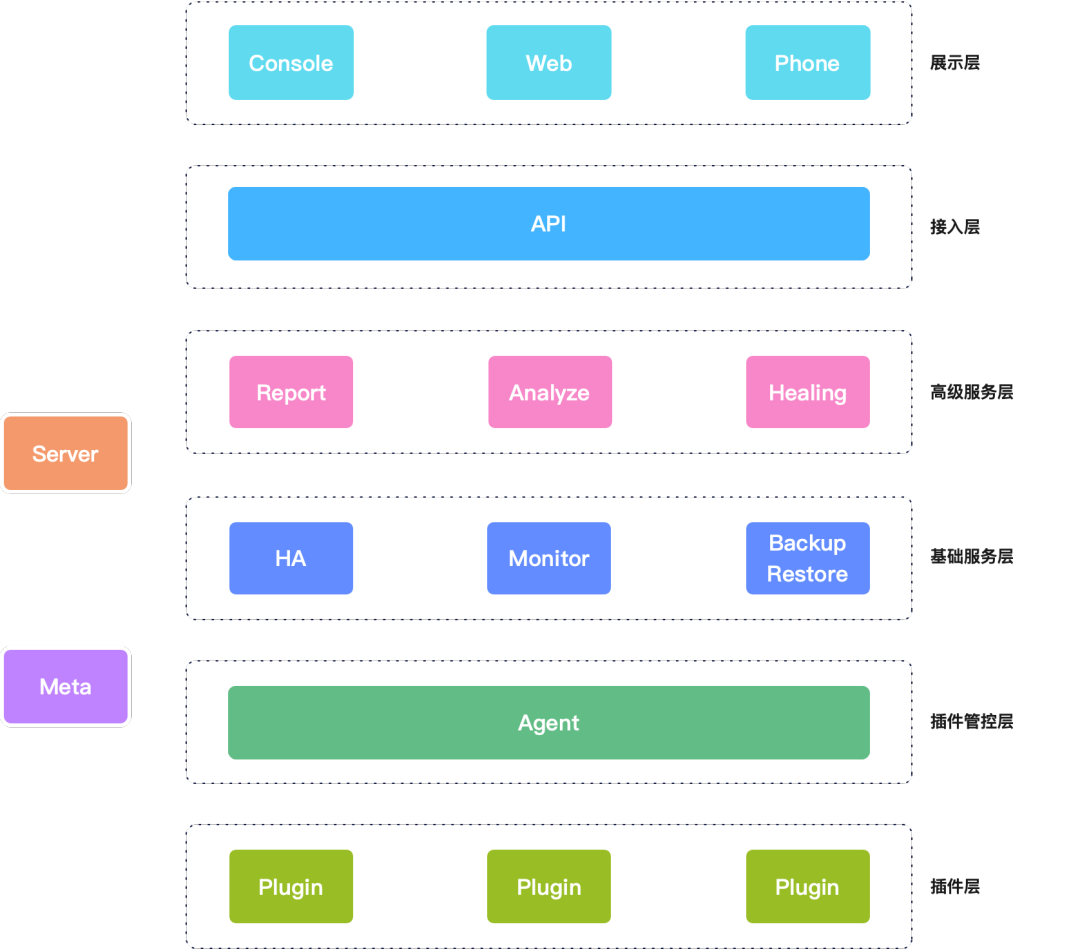
整个平台架构分为不同层级,每一层负责不同的功能,每一层的各个模块之间是独立部署,且不会互相依赖,各个模块均可以横向扩展。同层级模块之间可以相互调用,上层模块可以调用下层模块,但是下层模块不可以随意调用上层模块。在所有模块中有两个例外:Server是整个平台的管控模块,负责管控平台所有模块,也是平台第一个需要启动的模块;Meta是平台的元数据中心,负责为其他模块提供元数据服务;这两个模块是独立存在,不属于任何层级。整个平台不存在单点的模块,所有模块均具备高性能、高可用、高扩展性。下面介绍一下整个平台架构:
插件层,属于最底层服务,负责执行各种任务,备份恢复任务实际就是在这一层执行的。
插件管控层,主要负责管理插件。
基础服务层,实现了各种平台基础的服务。图中举例列出三个基础模块,高可用模块(HA)、监控模块(Monitor)、备份恢复模块(BackupRestore)。其中备份恢复模块(BackupRestore)就是本次要重点绍的备份恢复系统。
高级服务层,主要是提供各种高级的功能,图中举例列出的分析模块(Analyze)、报告模块(Report)、自愈模块(Healing)等。
接入层,是展示层的入口,也是其他业务访问平台的入口,主要具备三个功能:请求转发、权限认证、安全防护。
展示层,是展示平台的功能和信息。
目前整个平台分层架构已经初步构建完成,在平台分层架构的基础之上我们设计了备份恢复系统的架构。
2、流程架构设计
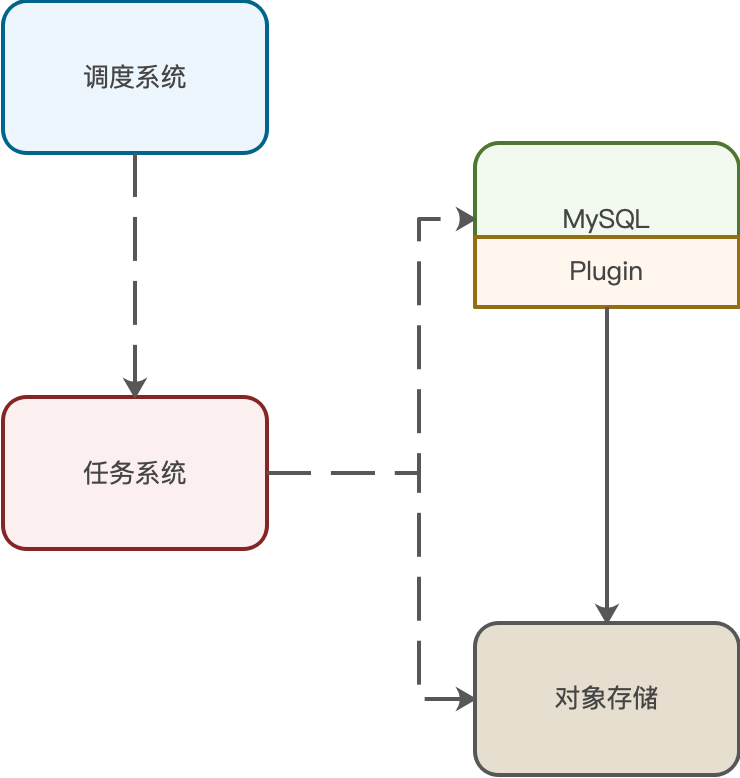
整个备份恢复系统分为三个大的模块:
调度系统,主要负责定时生成备份/恢复演练任务,并负责调度任务执行,记录任务调度信息。
任务系统,主要负责选取备份/恢复演练实例,向Plugin发送执行任务请求,记录任务执行的结果。
Plugin,主要负责执行任务,监控服务状态。
需要说明的是:
调度系统是一个通用的任务调度框架,负责所有任务的调度执行。备份任务、恢复任务等任务只是接入了调度系统里面,是任务系统中的一个实现。定时生成备份任务、恢复任务的触发器也是在调度系统里面。
任务系统是负责各种任务的实现,只要实现了指定的调度接口,就可以接入调度系统,由调度系统调度任务执行。
本文只关注备份、恢复任务的实现,调度系统和任务系统的详细实现将在后续文章里面展示出来。
现在我们从备份原理开始,从整个流程上拆解一下,看看我们是如何实现高性能的备份恢复数据库。
3、高性能备份
1)备份原理

备份的本质是将源端某一时刻数据快照通过通道传输到存储介质上。源端可以是数据库,例如MySQL、Redis、PostgreSQL等,也可以是文件等数据。中间通道可以是各种协议,例如http、ssh、tcp,也可以是linux管道协议。数据流在通道传输的过程中也可以做各种附加操作,例如压缩、加密、限速等。存储可以是各种介质,本地磁盘、对象存储、HDFS等。
备份的流程可以归纳为:数据从源端读取,经过通道进行处理,然后再上传到存储上。恢复流程则是备份的逆向过程。
以下仅以Xtrabackup备份MySQL为例进行说明:
2)源端实现高效率读取
为了实现高性能的MySQL备份恢复,首先需要理解xtrabackup是如何进行备份。
① Xtrabackup备份流程
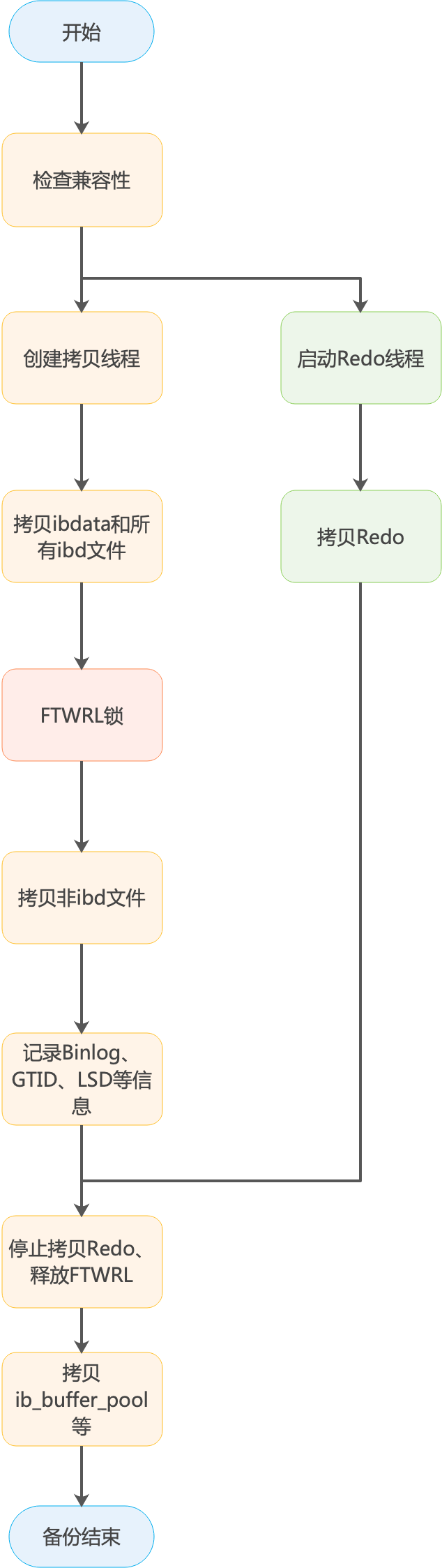
Xtrabackup会首先检查兼容性,并派生出拷贝Redo线程,从最新的checkpoint LSN开始,拷贝Redo。
Xtrabackup会创建拷贝ibd文件的线程,一直不停的拷贝ibd文件,直到所有的文件都拷贝完成。
Xtrabackup会加FTWRL(FLUSH TABLES WITH READ LOCK),这一步会将所有的表锁住,期间数据库不可读写,用于备份Myisam等非Innodb引擎表。在percona版本的mysql中会用binlog锁,在mysql 8.0版本中同样也新增加了备份锁,这些锁更轻量级,影响更小。
拷贝非Innodb文件,主要是MyISAM表和frm文件。
记录Binlog、GTID、LSN等元数据信息。
拷贝Redo线程退出,并释放FTWRL锁,拷贝ib_buffer_pool等。
备份结束。
通过对xtrabackup的备份流程进行梳理,可以大致了解源端是如何进行备份的。那该如何提高源端的备份效率呢?
② 备份文件格式
Xtrabackup备份结果支持两种备份文件格式tar和xbstream,在新版本(8.0+)中只支持xbstream格式。以下对两种文件格式进行简单分析:
第一种:tar格式
tar格式是操作系统的通用格式,其文件结构如下:

tar中文件头部定义如下:
/* tar Header Block, from POSIX 1003.1-1990. *//* POSIX header. */struct posix_header{ /* byte offset */char name[100]; /* 0 */char mode[8]; /* 100 */char uid[8]; /* 108 */char gid[8]; /* 116 */char size[12]; /* 124 */char mtime[12]; /* 136 */char chksum[8]; /* 148 */char typeflag; /* 156 */char linkname[100]; /* 157 */char magic[6]; /* 257 */char version[2]; /* 263 */char uname[32]; /* 265 */char gname[32]; /* 297 */char devmajor[8]; /* 329 */char devminor[8]; /* 337 */char prefix[155]; /* 345 *//* 500 */};
可以看出tar格式只是将文件与文件打包在一起,每个文件的头部标识了文件的属性、来源、大小等信息,比较简单。由于tar格式是操作系统的通用格式,所以有很多工具可以进行处理。
第二种:xbstream格式
xbstream文件是Xtrabackup工具的专属格式,需要用xbstream命令解压。xbstrem格式文件结构如下:

xbstream文件块定义如下:
typedef struct {uchar flags;xb_chunk_type_t type;uint pathlen;char path[FN_REFLEN];size_t length;size_t raw_length;my_off_t offset;my_off_t checksum_offset;void *data;void *raw_data;ulong checksum;ulong checksum_part;size_t buflen;size_t sparse_map_alloc_size;size_t sparse_map_size;ds_sparse_chunk_t *sparse_map;} xb_rstream_chunk_t;
可以看出xbstream文件块中不仅包含了文件名、文件数据块,以及块在文件中的offset、checksum等信息。文件存储结构方式的不同导致xtrabackup在tar格式和xbstream格式下的备份行为上有着很大的区别:
tar格式下的xtrabackup只能串行读取文件,不能并行读取,必须等到一个文件读取完成才能读取另一个文件;tar格式文件解压时也必须是按照打包文件顺序串行解压。由于xbstream数据块中包含块的所有信息(文件名和offset等),所以xtrabackup可以并行读取文件,将文件块格式化成xbstream文件块,最后将所有的xbstream文件块流式打包到一起。xbstream格式文件解压时,由于xbstream文件块中包含文件名和offset信息,xbstream可以并行将文件块按照offset顺序写入到对应的文件中。所以xbstream格式具备极高的传输性能。
tar格式下的xtrabackup只能先将redo备份到临时目录下,也就是将redo临时存储到当前服务器上,只有在备份过程结束时才会将临时目录下redo上传到存储上。如果服务器上的redo生成过多,可能会导致磁盘容量不足的问题。
所以为了追求更高的性能,必须使用xbstream格式。
③ 压缩和加密
由于是使用工具流式向对象存储上传输备份数据,所以备份数据必须要经过加密,以保证数据的安全性。压缩则可以减少备份文件的大小,从而可以节省存储成本。目前加密和压缩的实现方式有三种:
使用Xtrabackup自身支持的加密和压缩方式。xtrabackup目前只支持quicklz压缩算法(新版本中支持zstd和lz4,quicklz将会废弃掉),加密只支持AES算法,有AES128、AES192、AES256三种秘钥长度可选;
在通道处进行压缩和加密,也就是在xtrabackup数据流出之后,在上传到对象存储之前进行处理。对于源端不支持压缩和加密的功能可以选择这种方式;
部分存储可能支持透明压缩或加密数据,应用可以直接读取或写入数据。
以下是三种实现方式的对比:
|
压缩 |
加密 |
|
|
Xtrabackup |
当前版本只支持quicklz,压缩和解压速度较快,但压缩比一般。 |
加密只支持AES算法,且可以实现并行加密,速度较快。 |
|
通道 |
可以支持更多的压缩算法,例如zstd、lz4、gzip等,部分算法压缩比较高。通道也可以实现并行压缩。但是一般情况下压缩比和压缩速度不可兼得,压缩比高的压缩算法的压缩速度比xtrabackup的最高压缩速度较低。 |
通道可以支持更多的加密算法,也可以执行并行加密。但是加密的最高速度比xtrabackup的最高加密速度要低。 |
|
存储 |
部分存储支持,具体实现和目标存储相关。 |
部分存储支持,具体实现和目标存储相关。 |
首先为了防止数据泄露,对备份加密的需求是必须要有的,只有经过加密的备份文件才可以上传到存储,否则不符合安全规范的要求。密钥是由安全部门负责,平台不能存储密钥,故我们不能选取存储支持加密的方式。其次AES的加密强度可以满足我们的需求。而压缩需求并不是追求极限的压缩比,高效的压缩效率和解压效率也是我们的目标之一,所以我们选择使用xtrabackup原生支持的压缩和加密方式。
源端实现了高性能的读取、压缩、加密之后,在备份上传的过程中也需要实现高效率的上传,才可能实现最大的备份速度,否则上传就成为整个备份过程的瓶颈。
3)通道实现高效率上传
如何才能实现高效率上传?这就需要我们了解对象存储上传的原理。
对象存储支持块上传,即将数据文件分割成N个块,每次上传请求只上传文件的一块数据,等到所有数据块上传完成,最后再合并成一份文件,这就是并行上传的原理。其中每个块都需要进行编号,只要块的编号顺序是正确的就可以无序上传,最后会合并成正确的数据文件。根据对象存储上传原理,我们设计了备份数据上传的流程。
上传流程设计如下:
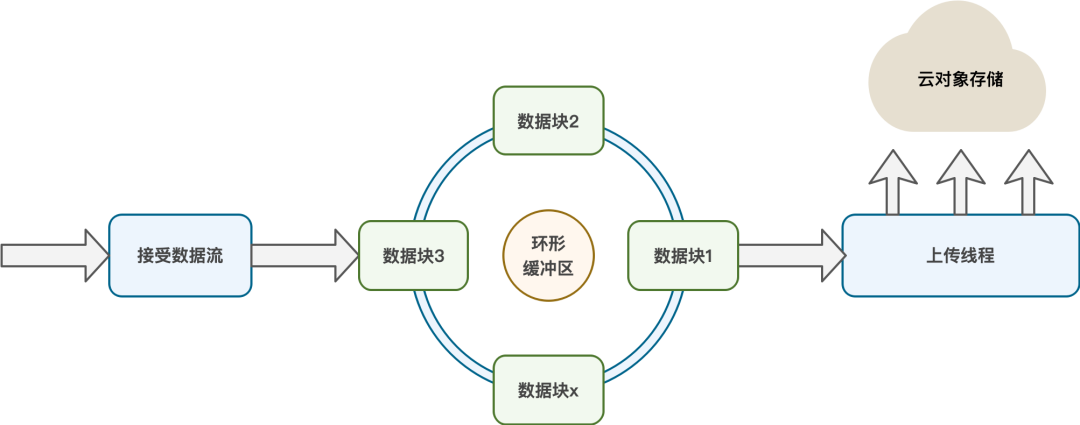
上传流程说明如下:
通道不停地接受xtrabackup传入过来的数据流。
通道将数据流按照一定大小切割成数据块,并对每个数据块进行编号,然后将编号之后的数据块放入到环形缓冲区中。
上传线程不停地从环形缓存区中获取数据块。
上传线程将数据块并发上传到对象存储。
等到所有数据块上传完成,最后将所有已上传的数据块合并成一个文件。
使用环形缓冲区可以确保上传是异步执行(因为块序号已经确认故可以无序上传),并且缓冲区不会无限膨胀。在其他资源不受限制的情况下,通过这种方式上传数据可以极大的提高上传的速度。
然而我们线上的服务器并非都是高性能服务器,同样存在一些性能较低的服务器。有些服务器上的资源是共享的(一机多实例)。如果某个服务器上的数据库备份时,占用较多的服务器资源,那样服务器上的数据库响应耗时会增长,甚至超时。为了避免这种情况,我们需要考虑如何做好备份,既能完成数据库备份,但是又不会影响数据库的响应。就好比空气一样,虽然存在但是业务感觉不到,同样也是必不可少的功能。
4、备份无感知
既然要做到备份无感知,那就不能把服务器的所有资源都用来做备份。毕竟线上数据库可用性的优先级是高于备份需求的,所以我们需要做好限速,将备份速度设置为一个合理的阈值才能避免影响服务。那么如何做限速呢?
1)限速
针对单个任务的限速目前有两种方式:
|
优点 |
缺点 |
|
|
xtrabackup限速或shell限速 |
工具自带限速使用比较简单、方便 |
xtrabackup在高并行的情况下无法有效限速;shell限速比较简单粗暴,不能做复杂的限速 |
|
通道限速 |
可以支持复杂的限速策略 |
需要自研,有开发成本 |
为了后面可以支持较为复杂的限速策略,我们期望可以投入一定的成本,为后面复杂的限速策略打好基础。
自定义限速的原理如下:
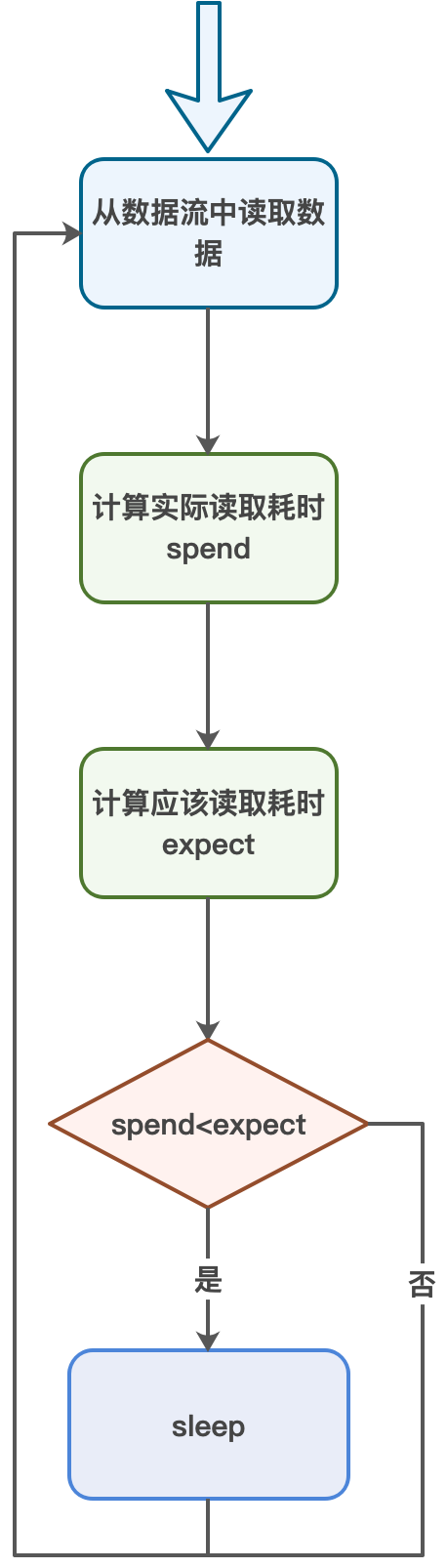
通道从数据流中读取一块数据。
计算读取这块数据实际耗时,记为spend。
计算读取这块数据应该耗时,记为expect。
如果spend<expect,那就表明读取数据流速度比预期快,需要进行sleep,expect-spend就是需要sleep的时间。
反之如果spend>expect,则表明读取数据流速度比预期慢,那就无需sleep,继续进行读取。
通过计算每次读取的数据流的应该耗时(expect)与实际耗时(spend)相比,可以计算出是否需要sleep。这种限速方法其实就是通过限制读取单位数据块的耗时做到限制数据传输速度。
有了限速之后,但是有些情况下备份还是在和服务争抢资源,导致备份无法完成,业务同样也收到了影响。具体原因一方面是由于需要备份的数据库实例比较多,数据库实例之间的数据量相差很大,并不是所有的实例的备份都可以在低峰期完成,有些处于业务高峰期的实例也会进行备份;另一方面则是由于存在着业务突发流量,导致本不应是高峰期的请求,变成高峰期的请求。以上两种普遍情况造成备份与数据库争抢线上服务器资源,严重时会造成数据库无法响应。那应该如何防止这种情况发生呢?
2)防止服务器过载
数据库备份需求的优先级是低于线上数据库可用性的优先级,所以即使在备份期间也需要尽力保证线上服务的可用性。当服务器资源不足时,手动去终止备份,其实业务已经受到影响了。只有在服务器资源不足时立即终止备份,才能及时避免业务受损。为了避免备份与数据库争抢资源,我们需要在数据库服务器资源不足时,由程序判断立即终止备份,避免影响业务正常的请求。
数据库服务器资源中与数据库密切相关的大致分为四个维度:磁盘IO,CPU,网卡,内存。磁盘IO和数据库是密切相关的,如果IO使用率过高,则数据库无法正常写入和读取,IO操作耗时较高则会极大的提高数据库的响应时间。查询的比较、排序等操作是重度依赖CPU资源,如果CPU使用率过高,则数据库无法正常响应。内存资源不足数据库进程会使用swap,响应时间开始升高,严重时可能会被系统Kill(OOM)。一般来说万兆网卡不太会是瓶颈,但是我们现在依然有一些服务器使用千兆网卡,网卡资源不足容易造成数据库响应延迟升高。
总之每种资源都需要确保在合理的使用范围内,避免因为资源不足造成各种问题。为了更快检测出资源的使用率,针对每个维度派生出一个线程,进行检测,一旦检测出某个资源使用率超过阈值则迅速结束备份任务,快速返回失败。
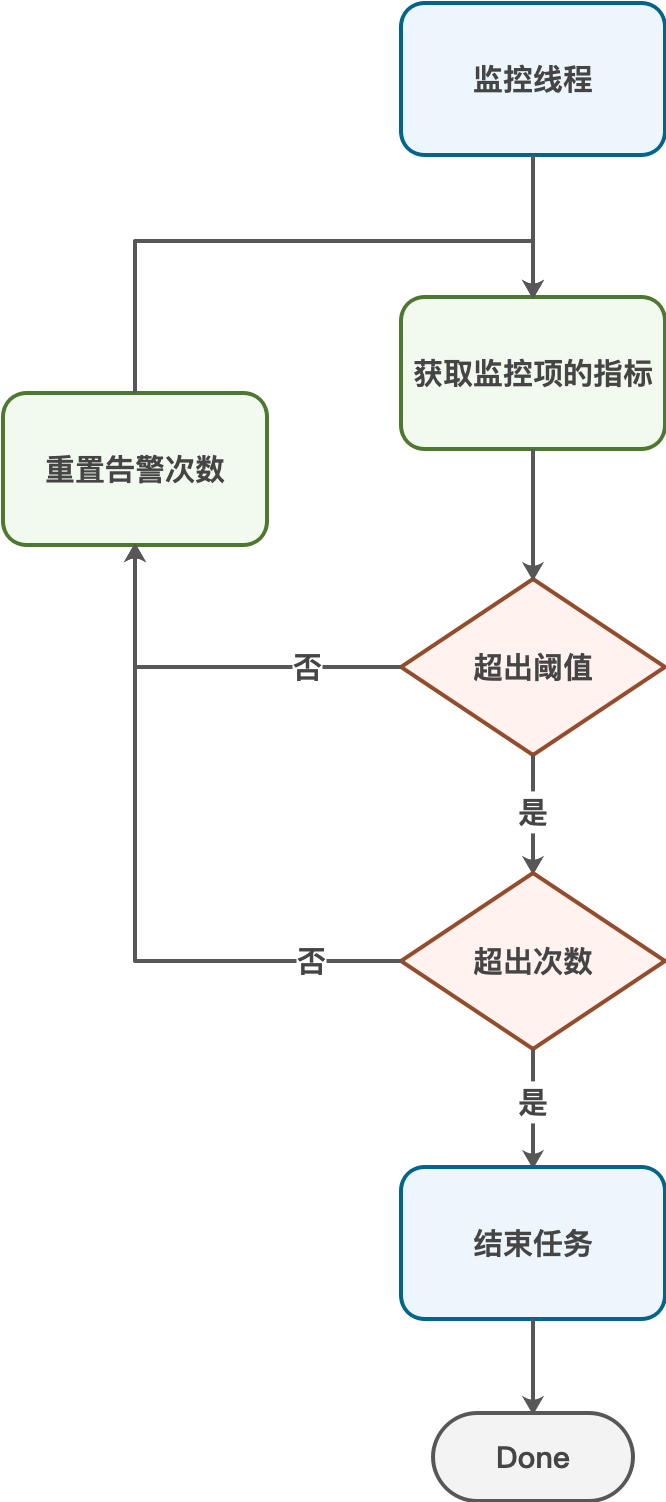
监控线程会根据配置,获取监控项的指标,即资源的使用率。
将资源使用率与设定的阈值进行对比,如果超出指定阈值则告警次数累加,否则将告警次数清零。
如果告警次数连续超过次数阈值,则终止备份任务,返回错误信息,否则sleep一段时间,进入下一轮检测。
通过监视服务器核心资源的使用情况,保证在备份期间服务器的资源使用率是处于一个合理的范围。如果一旦某项资源使用率连续超过阈值则立即终止备份,保护线上服务的稳定性。
虽然有负载保护可以最大程度的保障数据库的可用性,但是数据库备份的成功率也需要保障。如果面临需要恢复数据但不存在可用的备份时,就可能会面临更加严重的损失。假如备份数据库时,备份了整个数据的99%,只剩最后1%没有备份,而这时又来了一波请求造成服务器资源不足,这就需要立即终止备份,避免影响线上业务。但是回滚备份过的数据也是需要成本的。所以有没有一种办法既可以提高备份的成功率,减少终止备份的次数,又可以避免影响线上业务?
3)备份动态限速
有同事提出希望可以调整备份速度,当发现数据传输速度太快影响服务时,可以降低限速,这样备份依然可以继续进行,但是我觉得这并不是最终的需求。调整备份速度的原因一般都是设置的速度太高,导致占用了太多的资源,影响了服务。然而一般当人工发现问题时,其实服务已经受到影响了。不过如果我们设置较低的备份速度,虽然可以避免这种情况,但又会导致备份耗时比较长,性能较高的服务器不能体现出优势。
假如备份速度是可以动态调整的,如果当前服务器可用资源较少时,那可以自动减少备份速度,避免备份占用过多的资源;如果服务器资源比较充足时,可以自动提高备份速度,缩短备份时长。如此一来,既可以保证业务请求不受影响,响应时间得到保证,又可以保证备份的速度,提高备份的成功率,所以我们需要做到动态限速。动态限速的本质是在限额资源内最大化效率。
动态限速是备份程序根据当前服务器的资源使用情况在不影响业务使用的情况下自主决定采取最适合的备份速度。动态限速的基础是需要可以自由调整数据传输的速度,只有限速的阈值可以动态调整,才能做到动态限速。由于前面我们定义了复杂的限速策略,而备份限速其实就是expect,只要调整expect就可以做到动态限速。增加expect,则备份速度就会增加,减少expect,备份速度就会减少,并且是实时生效的。
做到了可以自由调整限速阈值之后,接下来只需要根据当前服务器各项资源使用率实时计算出最合适的速度,将expect设置成最合适的速度就可以做到动态限速。我们认为与备份速度密切相关服务器资源项如下:CPU利用率、IO利用率、网卡利用率。后来也考虑了将部分数据库状态(thread_running等)作为限速项加入到其中。通过不断地获取限速项的指标,与阈值相比较,从而计算出最适合的备份速度。
动态限速的原理如下:
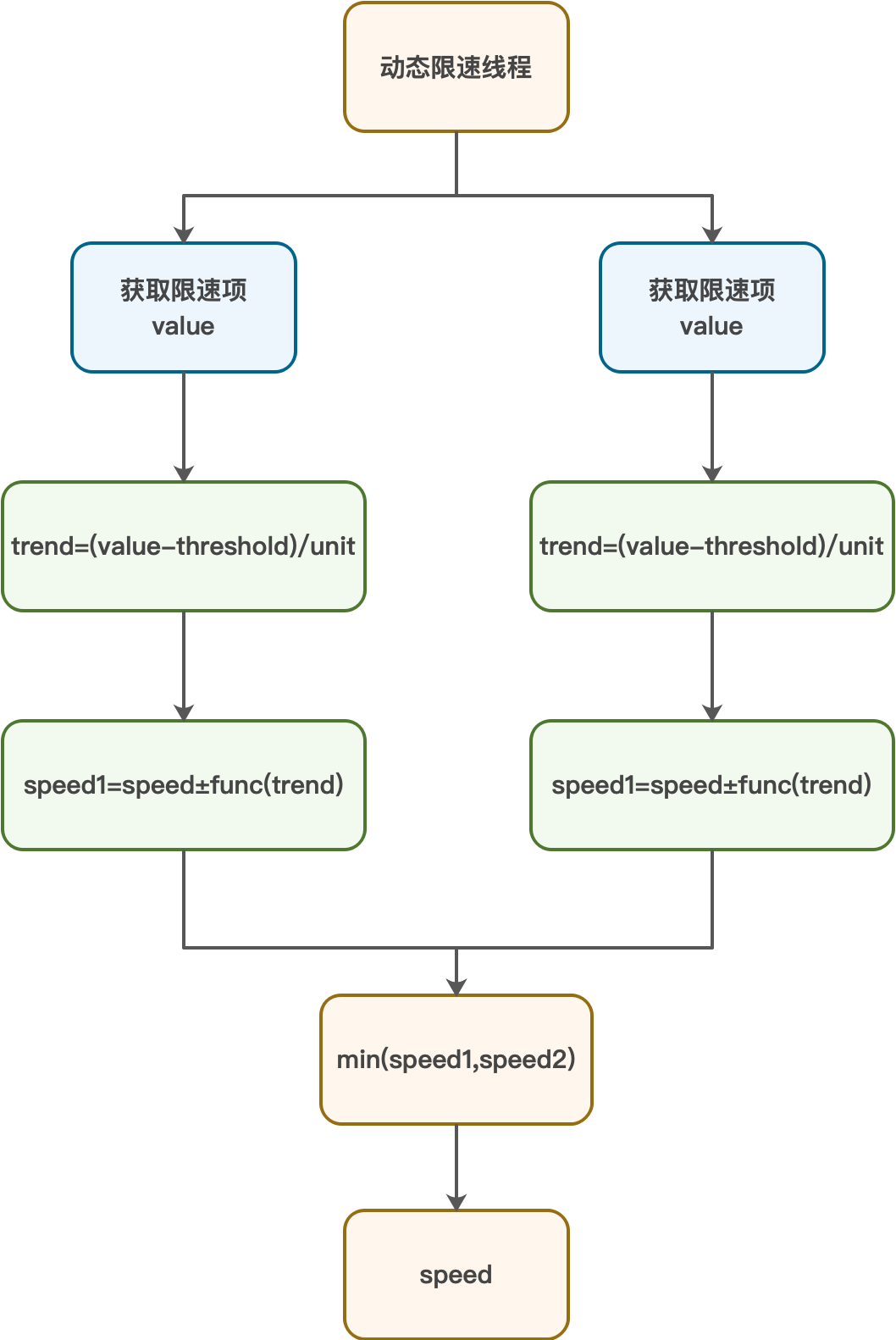
说明:
threshold:每个限速项都会设置一个最大的阈值,超过阈值则需要减速。
unit:单位值,为了统一trend的衡量标准,需要将所有限速项当前值与阈值的差值转换为份数,即是差值包含多少份unit。
trend:限速增减的趋势,大于0表示需要减少trend个单位速度,小于0则表示需要增加trend个单位速度。
单位速度:计算动态速度时,每次增减速度的最小数量。
speed:当前备份的速度。
speedX:某个限速项的计算出来的合适的备份速度。
func:根据算法、trend和speed计算出最适合的备份速度。
目前func中设计的算法有如下四种:
rand:随机算法,在限速阈值和当前备份速度之间随机选取一个值,由于这个算法在部分场景下计算出来的速度不太稳定,故一般情况下不再采用。
times:倍数算法,当前备份速度增减单位速度的倍数(trend)作为合适的备份速度,目前降速使用这个策略;
dichotomy:二分算法,选取到阈值和当前备份速度中间的值,作为合适的备份速度;
fixed:固定值,根据趋势(trend)当前备份速度只增减单位速度作为合适的备份速度,目前提速时使用这个策略;
动态限速流程如下:
动态限速线程会实时探测不同限速项的利用率value;
计算限速项的趋势值(trend),对比每个限速项的限速阈值,计算出当前值与阈值的差值并除以单位值(unit);
针对每个限速项,根据算法、当前速度(speed)和当前限速项的趋势值(trend)计算出每个限速项的最合适速度speedX;
综合所有限速项的speedX,选取最小的备份速度即为当前速度。
通过实现动态限速可以保证在不影响线上业务访问数据库的情况下,最大化的保证备份的速度和成功率。这个是我们备份成功率较高的关键原因。
5、其他
通过实现全流程的优化,我们做到了高效率的备份,并且备份过程中资源使用率是可控的,备份过程业务基本无感知。不过业务还提出了一些其他的个性化的需求。
1)个性化清理策略
业务期望成本不增加或者增加极少的情况下,可以最大化业务的可恢复时间范围。为此我们设计了稀疏的清理策略,可以在全量备份数量增加极少的情况下,最大程度的增加业务的可恢复时间范围。
稀疏清理策略:每个集群可以自定义N个连续时间段内的保留个数。在每个时间段内可以设置间隔几天保留多少份数全量备份,但是要求当前时间段内的全量备份数量一定是小于上一个时间段内的全量备份数量。
举个例子,这是平台某个集群的清理策略:

当前集群的备份列表中:
最近十天内无论有多少个备份全部保留。
10-90天之间每隔3天保留一个备份,其他备份则清理。
90-180天之间每隔6天保留一个备份,其他备份则清理。
180天-5年之间每隔15天保留一个备份,其他备份则清理。
5年之后的只保留最近三个备份。
通过以上稀疏的保留策略,可以看到在增加非常少的全量备份的情况下,可以恢复到很早的备份时间。
2)通用存储
随着公司业务的变更,可能会从一家云存储厂商变成另外一家云存储厂商,而我们不可能专门为一家云存储厂商开发一套程序。安全部门也要求我们有一些数据库的不能将备份传输到云上,只能将备份传输到公司指定的存储上。由于以上两个场景,我们需要开发一套通用的存储接口,底层存储只需要实现相应的接口,就可以无缝接入到当前备份流程中,无需做任何额外的变动,成本极低。

最上层是一套通用存储接口,下层分为对象存储、非对象存储和中转存储。
其中对象存储根据通用存储接口实现了对象存储接口,只要根据各个云存储的sdk实现了对象存储的接口,就可以接入到系统中。
非对象存储,例如本地磁盘、HDFS、Ceph等,可以根据情况实现通用存储接口,也可以无缝接入到系统中。
中转存储本身并不是可以存储数据的存储,但是可以将数据方便的转发到其他实现了通用存储接口的存储上。中转存储比较类似于存储网关,但是相比存储网关缺乏一些高级特性。
通用存储的接口代码如下:
type Storage interface {// 打开链接OpenClient() error// 关闭连接CloseClient() error// 打开一个文件读句柄,可以配置一些选项OpenFileReaderConfig(filePath string, config interface{}) error// 读取数据Read(p []byte) (int, error)// 关闭文件读句柄CloseFileReader() error// 打开一个文件写句柄,可以配置一些选项OpenFileWriterConfig(filePath string, config interface{}) error// 写入数据Write(p []byte) (int, error)// 刷新缓存Flush() error// 关闭文件写句柄CloseFileWriter() error// 递归获取目录文件信息DirectoryStats(dirPath string, arg interface{}) (DirectoryStat, error)// 创建目录MakeDirectory(dirPath string) error// 删除目录/文件,如果是目录则递归删除Remove(dirPath string) error// 清理数据:存储可能存在一些【垃圾数据】需要清理Clean() error}
只要实现指定的方法就可以无缝接入存储。
3)任务通知
任务执行成功或者失败我们期望得到通知,便于进行下一步操作。但是由于数据库的大小不同导致备份和恢复的耗时差距非常大。如果任务长时间运行没有收到通知,可能会让我们以为Plugin在执行任务时挂掉或者没有通知到系统,需要频繁去检查任务执行情况,所以我们期望任务在进行过程中,对于一些耗时比较长的阶段可以进行进度的通知,让我们知道任务在运行并且可以大概预测出任务的完成时间。
得益于Plugin支持自定义限速的功能,我们在限速流程中增加了任务通知的功能。每次通知的内容需要包括当前传输的数据量以及预估的进度信息。通知有两种维度的计算方式:
数据量,每传输一定量的数据进行通知一次;
时间,每隔一段时间进行一次通知;
通知的流程如下:
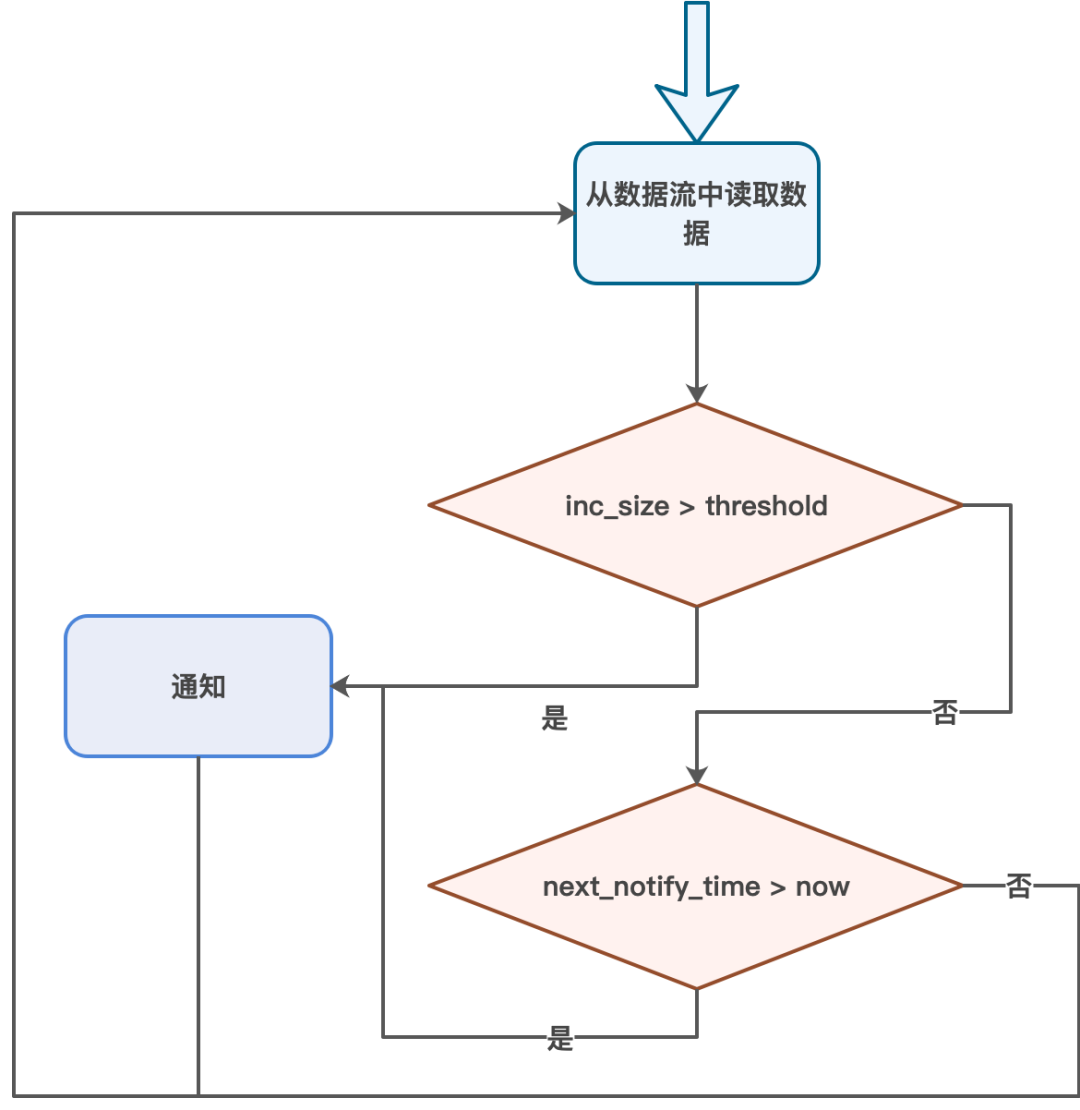
通道每从数据流中读取一定量的数据;
通道会检查距离上次通知开始,已经读取了多少数据量inc_size;
如果inc_size比设置的阈值大,则发起通知;
如果下次通知时间next_notify_time比当前时间大,则发起通知;
6、高性能恢复
备份不是目标,恢复才是目标,极致的恢复才是终极目标。恢复是备份的逆向过程,由于所有操作的原理都大致相同,这个不再赘述了。但是有一点需要注意:流式解压备份文件的xbstream需要xtrabackup8.0+版本才可以支持。
数据库恢复同样也支持业务各阶段通知的功能。我们通过记录任务各阶段的起始时间,可以确认哪一个阶段耗时比较高。接下来可以针对耗时比较高的部分做重点的优化,也可以量化出优化的结果。
下面是线上某个1TB的实例进行恢复时,恢复操作各阶段的耗占比:
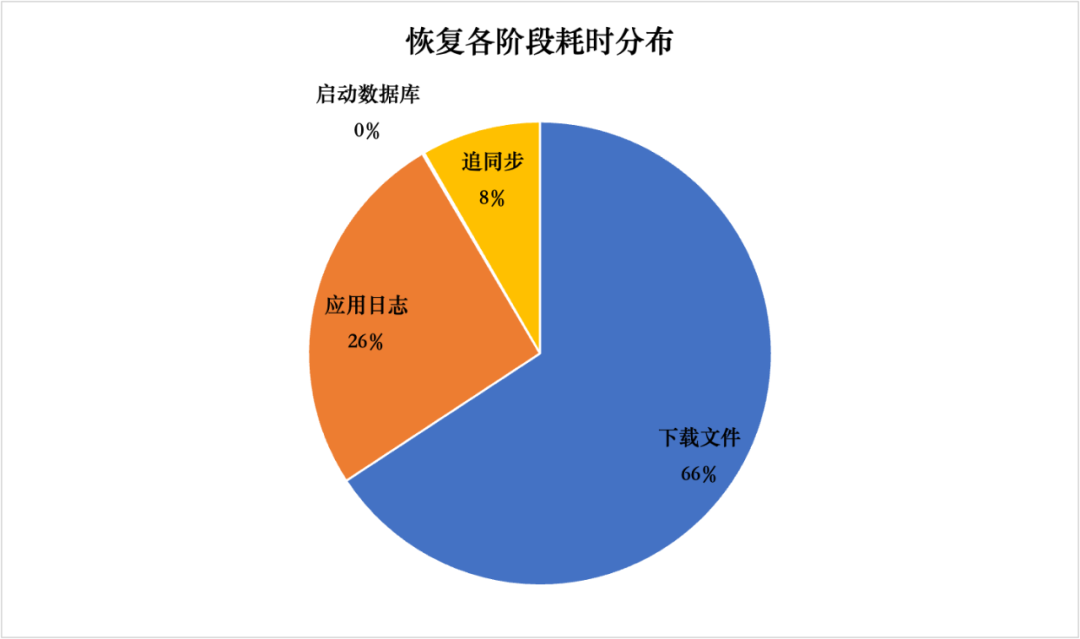
通过查看各阶段耗时我们可以看出耗时占比最高的是在下载文件阶段。
7、恢复演练
备份的可靠性需要验证,只有验证过的备份才是可靠的。恢复演练会根据集群的重要性级别定期生成恢复演练任务,抽检数据库备份进行实际恢复,以确认备份是否真的有效。恢复演练的恢复目标服务器是我们的恢复机,除此之外恢复演练的流程与数据库恢复的流程完全相同,这里也不再赘述。
四、效果
1、备份效果
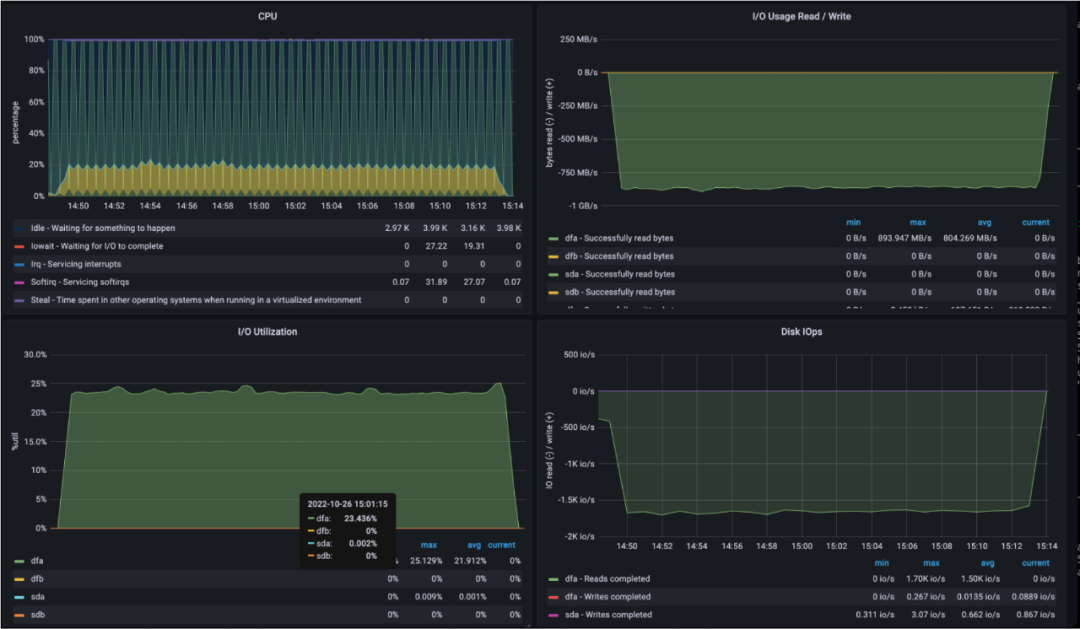
上图为数据库非加密备份的测试,可以看出数据传输的平均速度大约为860MB/s。
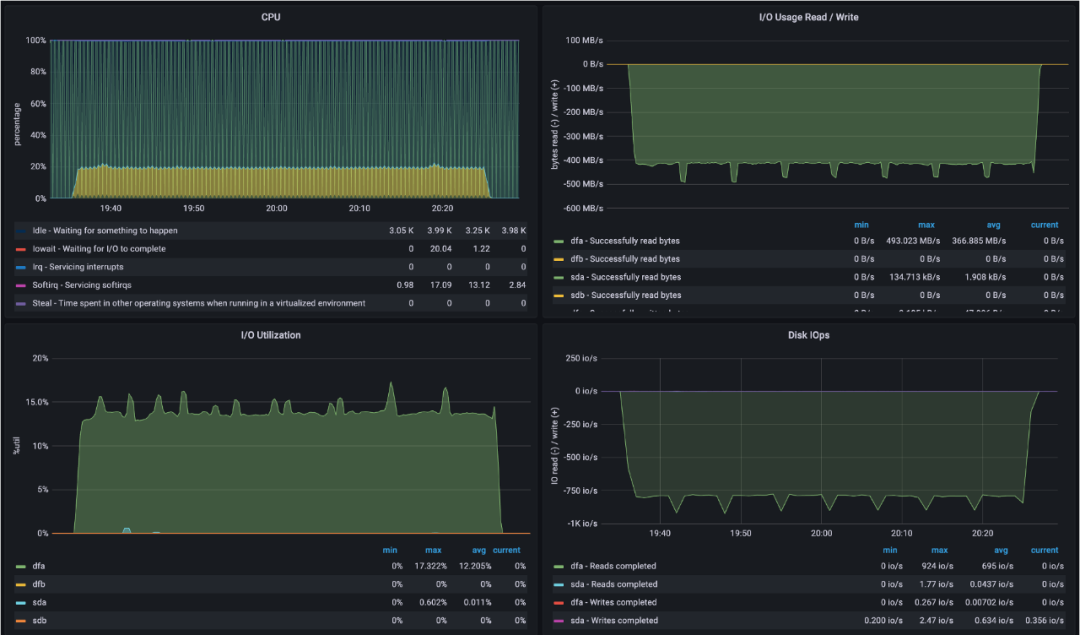
上图为数据库加密备份的测试,可以看出数据传输的平均速度大约为420MB/s。
|
系统 |
备份速度(MB/s) |
提升 |
|
新系统(加密) |
420 |
13倍 |
|
新系统(非加密) |
860 |
27+倍 |
|
老系统 |
30 |
- |
通过对各阶段的优化我们可以看出备份性能提升非常明显。对于非加密的备份,最高可以提升到至少2TB/小时(860*3600/1024/1024),加密备份效果提升也很明显。
2、恢复效果
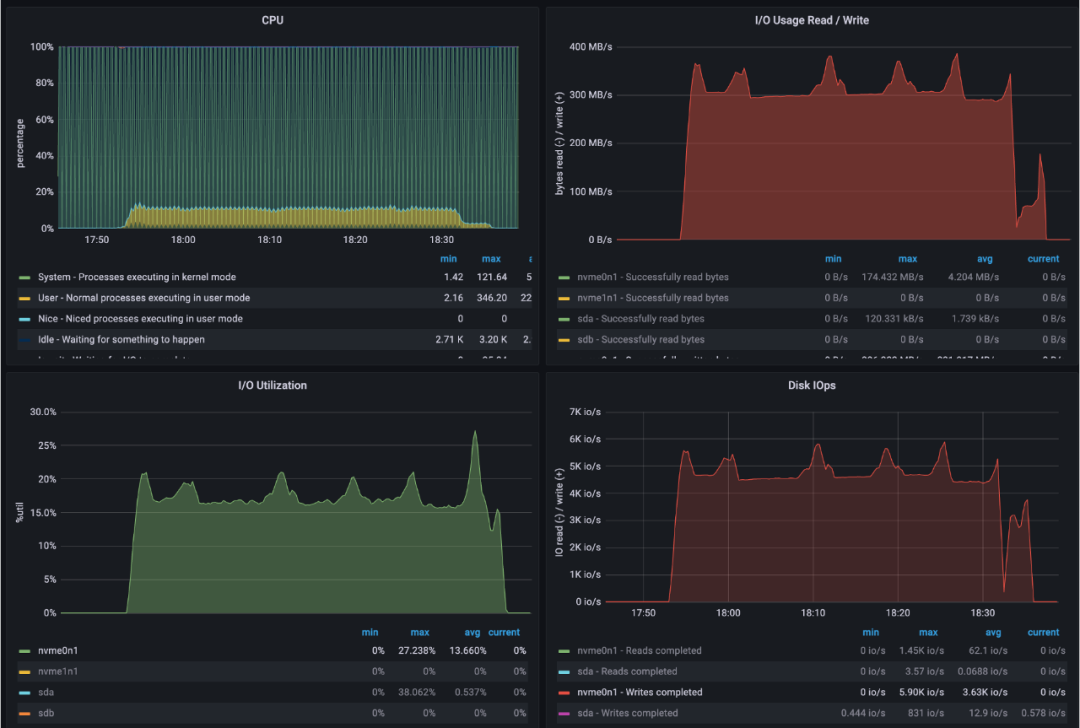
上图为数据库加密恢复的测试,可以看出数据传输的平均速度大约为300MB/s。
|
系统 |
恢复速度(MB/s) |
提升 |
|
新系统(加密) |
300 |
10倍 |
|
老系统 |
30 |
- |
数据库恢复的效果提升也是非常明显,可以达到1TB/小时(300*3600/1024/1024)。备份恢复系统已经多次在线上快速恢复业务,大大缩短业务受影响的时长。
3、动态限速
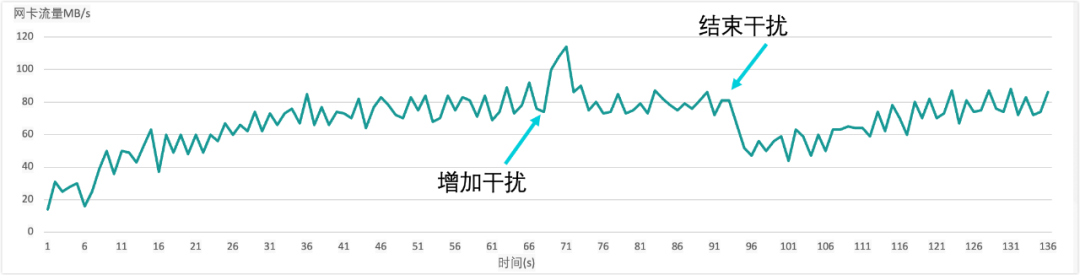
上图是展示动态限速的效果,模拟开始进行数据库备份,并在传输中间加上干扰,查看是否达到效果。为了更好的看出效果,我们只测试网卡维度的动态限速效果。动态限速的提速算法是固定值算法 (即每次只提升一个较小的固定值),降速算法是倍数算法(即每次下降非常快)。
由图可以看出:
当数据库开始备份时,速度是缓慢上升,直到达到限定的阈值(80MB/s)。这也和我们的要求吻合,我们不希望一开始就对服务器产生太大的压力。
在70s时,在测试机上增加干扰(从测试机向其他服务器传输一个文件,限速30MB/s)。这时可以看到网卡流量迅速上涨到110MB/s,大约两秒之后就迅速下降到80MB/s。这表明动态限速在资源超过阈值时,会立即限速,直到速度降低到设定的阈值,而实际的传输速度为50MB/s。这也符合我们的要求:如果资源利用率超过阈值时,立即降速,缓解资源使用的压力,不能影响线上服务。
在90s时,在测试机上结束干扰(测试机上停止传输文件)。这时可以看到网卡流量迅速降到50MB/s,之后网卡流量缓慢上升,逐渐恢复到80MB/s。这也符合我们的要求,恢复需要缓慢上涨。
五、其他思考
动态限速的模块不仅仅可以应用于备份恢复的场景,只要操作可以提速和降速,并且需要确保当前服务稳定的场景下,均可以使用这个模块。
资源总是有限的,但是如何能让资源充分发挥作用呢?如果Linux系统可以以更友好的方式动态分配资源,那么根据不同服务的需求综合部署服务,是否可以极大的提高资源利用率?
六、总结
备份恢复系统通过对各个环节进行优化,提高的提升了备份、恢复的效率,可以满足我们的需求。整个系统的各个组件(包括不限于通用存储、动态限速、个性化清理策略等),都是被独立出来的,也可以应用到其他的业务中。
参考资料
https://www.gnu.org/software/tar/manual/html_node/Standard.html
https://www.percona.com/doc/percona-server/8.0/management/backup_locks.html








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721