
一、前言
UUID,想必诸位都已耳熟能详,此文旧饭新炒一下,从DBA的角度聊聊UUID在PostgreSQL中的利与弊。
二、分析
UUID即"通用唯一标识符",用于生成一个唯一的标识符,类似于我们的身份证号。
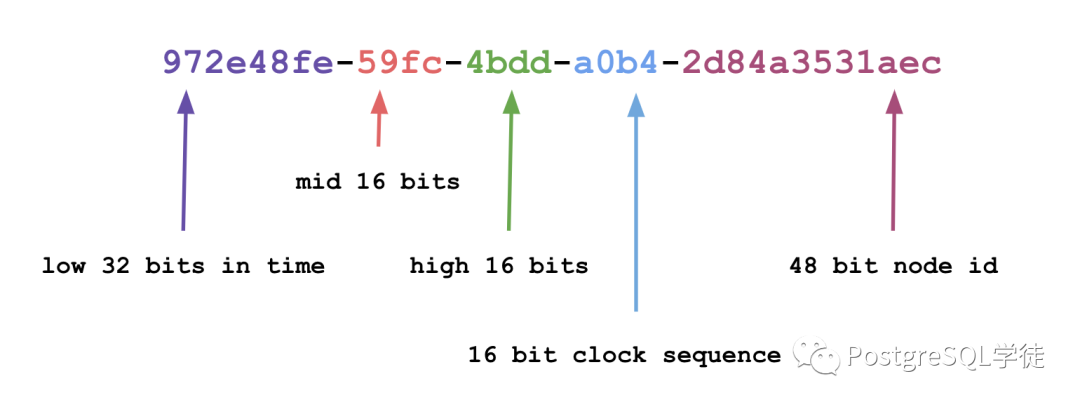
Primary key UUID_v1 example
具体算法以及各个版本的差异此处表过不提。在PostgreSQL中,低版本可以用"uuid-ossp"或者pgcrypto插件,13以后原生就提供了 gen_random_uuid() 函数用于获取UUID (v4版本)。那么细分到PostgreSQL数据库中,从DBA以及可维护性角度来分析的话,UUID是否推崇?作为替代,序列/bigint之类是否可行?我大致列了三点危害:WAL膨胀、索引膨胀、性能损失。
这一点我写在了最前面,是因为这个危害带来的影响最为可观,并且最为常见。UUID因其自身的无序性和唯一性,选择率很低,因此往往都会在相应列上创建索引,用于加快检索,而WAL膨胀的原理——FPI也正是因为索引的存在,页面的首次变更要记录FPI。假如是序列,由于数据是顺序生成的,因此每次涉及到一个页面的变更。
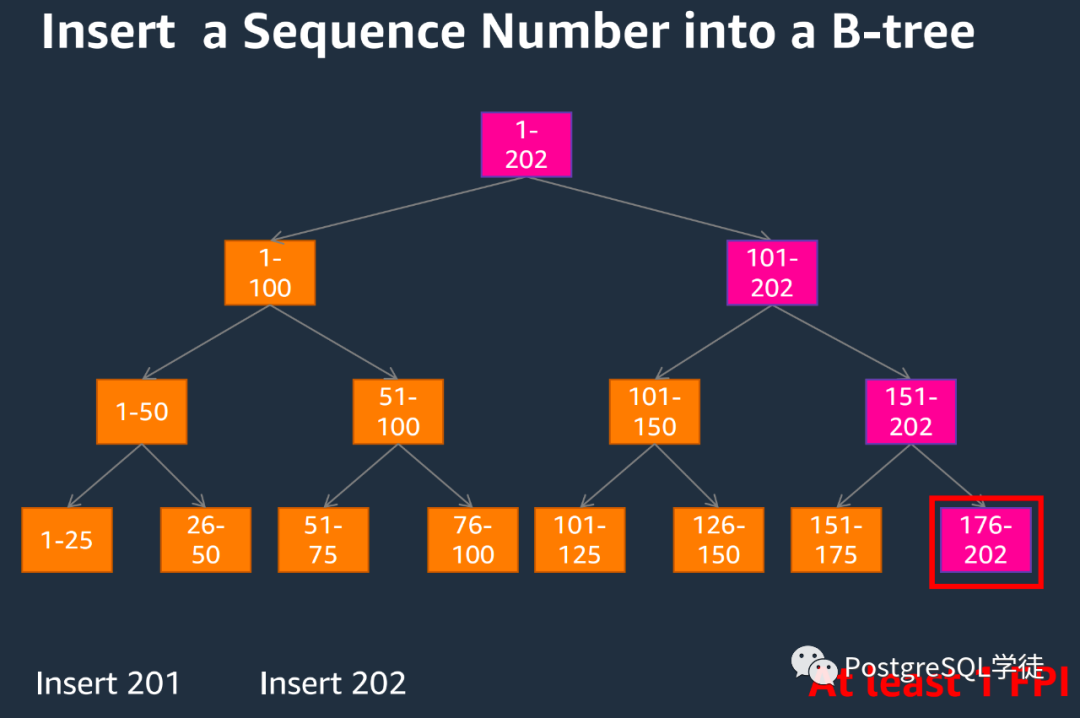
假如是UUID,由于数据的无序性,会导致索引叶子节点频繁分裂、合并,致使WAL的膨胀。
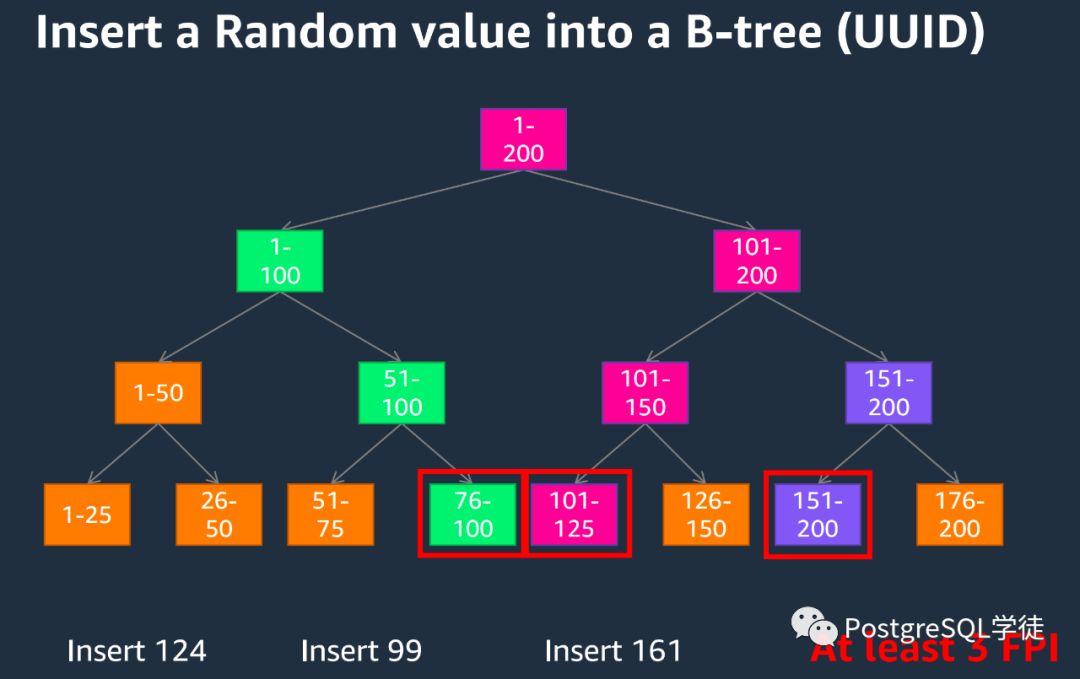
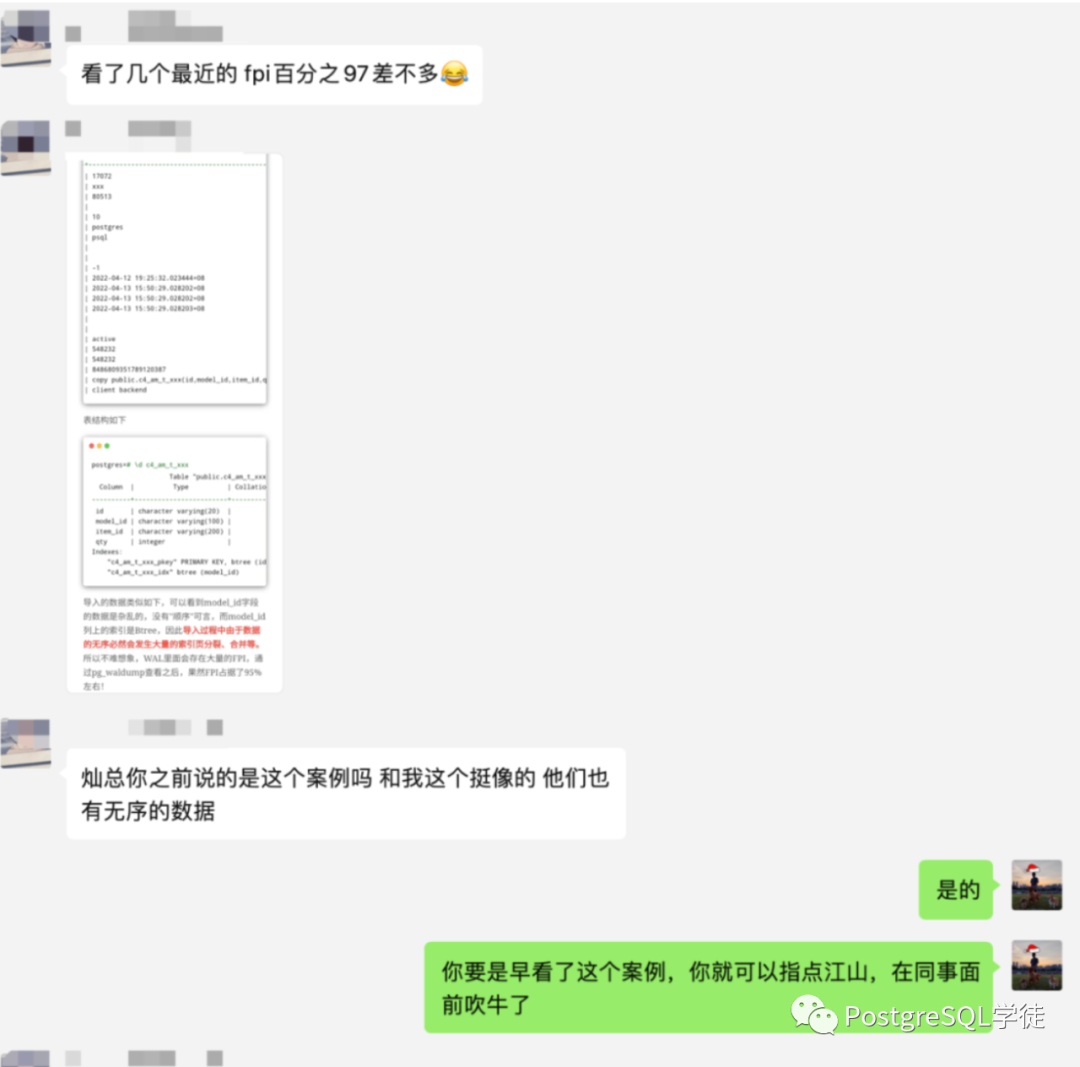
这个危害是最常见的,我碰到过无数案例都是UUID主键索引导致的,诸如copy导入慢如牛马、主备延迟巨大、存储急剧上升等。
三、索引膨胀
索引膨胀和WAL膨胀类似,由于索引叶子页面频繁分裂、合并,会导致大量的空洞、碎片,可以通过查询pgstattuple.leaf_fragmentation作为索引膨胀的依据,不仅导致索引效率的降低,还会降低性能(之前我也写过一篇生产案例,讲述了索引膨胀带来的危害)索引碎片可以参考之前的站在开发者角度聊聊索引日常。
四、性能损失
性能损失这个gap其实大多数人也能想到,UUID的字节更大,产生UUID的开销也往往更高,同时序列也对高并发生成的场景做了大量优化(cache),可以看到二者的一个产生效率。
postgres=# create sequence test_seq;CREATE SEQUENCEpostgres=# explain analyze select nextval('test_seq') from generate_series(1,10e6);QUERY PLAN-------------------------------------------------------------------------------------------------------------------------------Function Scan on generate_series (cost=0.00..12.50 rows=1000 width=8) (actual time=2631.336..9060.781 rows=10000000 loops=1)Planning Time: 0.081 msExecution Time: 9551.244 ms(3 rows)postgres=# explain analyze select gen_random_uuid() from generate_series(1,10e6);QUERY PLAN---------------------------------------------------------------------------------------------------------------------------------Function Scan on generate_series (cost=0.00..12.50 rows=1000 width=16) (actual time=2590.397..27123.855 rows=10000000 loops=1)Planning Time: 0.062 msExecution Time: 27814.464 ms(3 rows)
另外一个是cybertech的例子,都是一千万行数据,一个是序列,一个是UUID,性能差了一倍。
locality=# EXPLAIN (BUFFERS, ANALYZE, TIMING OFF) SELECT COUNT(id) FROM records; ---序列,顺序产生QUERY PLAN------------------------------------------------------------------------------------------------------------------------------------Aggregate (cost=202422.47..202422.48 rows=1 width=8) (actual rows=1 loops=1)Buffers: shared hit=27332Index Only Scan using records_id_idx on records (cost=0.43..177422.46 rows=10000002 width=8) (actual rows=10000000 loops=1)Heap Fetches: 0Buffers: shared hit=27332Planning Time: 0.056 msExecution Time: 777.764 msrows)locality=# EXPLAIN (BUFFERS, ANALYZE, TIMING OFF) SELECT COUNT(uuid_v4) FROM records; ---UUIDQUERY PLAN------------------------------------------------------------------------------------------------------------------------------------------Aggregate (cost=213506.47..213506.48 rows=1 width=8) (actual rows=1 loops=1)Buffers: shared hit=8562960Index Only Scan using records_uuid_v4_idx on records (cost=0.43..188506.46 rows=10000002 width=16) (actual rows=10000000 loops=1)Heap Fetches: 0Buffers: shared hit=8562960Planning Time: 0.058 msExecution Time: 1430.684 msrows)
差异很明显,shared hit是数量级的差异。当执行index only scan的时候,需要去检索visibility map,一个8KB页面用2bit标记all_visible,因此每个vm页面可以缓存32768个页面,也就是256MB大小的表,因此对于序列(第一条SQL),通过索引判断元组可见性的时候,由于堆表中值也是相邻的,因此一个vm页面就可以一次性判断N条索引中元组的可见性。
而UUID,由于自身值的无序性与唯一性,索引中相邻的值在堆表页面中往往都是分散的,因此需要涉及到大量的vm页面扫描与置换,注意缓存命中并非意味着没有成本(获取锁、哈希表查找等一系列步骤),因此这也是一个潜在的性能损失点。
The answer is that because looking up pages in shared buffers is not free – it involves grabbing a lock, running a hash table lookup on a relatively large hash table, and doing a memory write to mark the pages as being looked at – index-only scan will hang onto a reference to the visibility map page it had to look at last time, and if the next index tuple happens to need the same page, we can skip all that work, and just read the bit we need off of it. Some of you might see where this is going…
答案是,因为在共享缓冲区中查找页面不是免费的——它涉及到获取锁,在相对较大的哈希表上运行哈希表查找,并进行内存写入以将页面标记为正在查看——index only scan 将挂起对上次必须查看的可见性映射页面的引用,如果下一条索引元组碰巧需要同一页面,我们可以跳过所有这些工作,只读取我们需要的部分。
另外由于著名的局部性原理(Locality),在计算机科学领域中应用程序在访问内存的时候,倾向于访问内存中较为靠近的值。局部性是出现在计算机系统中的一种可预测行为。系统的这种强访问局部性,可以被用来在处理器内核的指令流水线中进行性能优化,如缓存,内存预读取以及分支预测,UUID也会使局部性原理大打折扣。
五、小结
当然这篇文章最开始就声明了是站在DBA的角度来看待UUID,并非全盘否定UUID,比如UUID对安全就有好处(可以根据序列推断你大致的数据顺序),另外由于序列自身的诸多黑洞(序列空洞、孤儿序列等),还有在分片模式下序列也不行(雪花算法、百度uid-generator等),UUID自然就成为了一个更好的选择,或者你的主键并非由数据库生成而是应用程序,UUID也更适合,因此我们要辩证地看待。我在写开发规范的时候,也写明了推荐使用序列作为替代。
另外一个有趣的点是,Oracle和PostgreSQL的行为相反,我问了我们Oracle的大腿子同事:
Oracle中推荐使用sys_guid,虽然也会有索引分裂、写放大这些问题,但是热块的问题更加严重,因此作为折中还是选择了sys_guid。而PostgreSQL我是写明了不建议使用UUID,但貌似我没怎么碰到热块的问题,难道这里面有什么玄机吗?亦或是PostgreSQL没有支持到那么高的并发?
This is a question... 等有空分析一下这二者的差异(有读者愿意指点迷津也可以给我留言,感谢解惑)。
当然了,为了规避前文所说的问题,你也可以选择使用有序UUID:
https://github.com/tvondra/sequential-uuids,以及UUID v7,v6 和 v7 ( https://github.com/fboulnois/pg_uuidv7提供了v7的支持 ) 都有考虑可排序性,解决 UUID 应用时最常遇到的数据库性能问题。
参考资料
https://www.reddit.com/r/PostgreSQL/comments/mi78aq/any_significant_performance_disadvantage_to_using/
https://www.cybertec-postgresql.com/en/unexpected-downsides-of-uuid-keys-in-postgresql/








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721