
背景
分库分表是大型互联网应用经常采用的一种数据层优化方案,常见的分库分表中间件如 sharding-jdbc、mycat 都已经比较成熟,基本上可以应对我们一般的分库分表需求。
做过分库分表的同学应该知道,在给业务系统做分库分表改造过程中,难的不是如何使用这些组件进行分库分表,而是如何将非分库分表的系统平滑的升级成一个分库分表的系统,升级期间业务不可暂停,升级过程及升级后风险可控,这个过程就像是给飞行中的飞机更换引擎,处理不好会产生重大的业务事故。
去哪儿网机票辅营业务就经历过从主从读写分离系统升级到分库分表系统的过程,并在多次迭代过程中形成了一种与业务轻相关的平滑的分库分表方案,后续业务升级分库分表只需通过配置切换就可以将单库单表系统瞬切至分库分表系统。
一、原始问题
去哪儿网有自研的分库分表中间件 qdb,是基于数据源进行分库分表的,它和那些开源的分库分表中间件一样,只解决了如何进行分库分表问题,没有解决如何将一个非分库分表系统升级至分库分表系统过度的问题。如果我们直接使用 qdb 进行分库分表,不做任何过度方案,那么将有以下问题:
升级过程中如果出现部分数据错误,如何回滚?如做回滚,新数据可能在回滚前落入新库,回滚后落入旧库,一部分数据在用户层面将看不到;如果错误只出现一次还好,可以通过洗数解决;但如果升级过程反复发现 bug,反复修订,一定会对业务造成影响;
迁移至分库分表后,为了保证数据被查询到且保证查询的性能,一般情况下 sql 的查询条件需要带上分表(片)键,但一个已经运转多年的业务系统它的 sql 肯定不能完全满足这个要求,如果进行全量的 sql 改写将是一个巨大的工作量,且有些业务场景根本就无法进行 sql 改写,比如辅营交易系统表的分表键一般是自身业务的订单号,但它有根据第三方券码查订单的客观需求( 一般是三方回调接口中)。
如何确定分库分表后的系统数据业务等价于分库分表前的系统。
解决了这三个问题也就能顺利的从单库单表迁移至分库分表了。
二、第一次平滑迁移至分库分表的实践
简单来说第一次进行分库分表的平滑升级,其主要思路是:
对数据进行双写;在分表键的基本之上增加了分表键映射的概念,通过 sql 条件分析自动或手动路由控制数据读写单库单表或分库分表;
再通过一种特殊的事务来实现的两套系统的一致性;
通过 iff 来确定两套数据库系统数据是等价的。
这3个点分别对应解决上述的三个问题。
为了方便理解后续内容,有必要对 mybatis 和 mybatis-spring 的一些原理作一些简单介绍,读者如果非常了解 spring 事务和 mybatis 的原码则可以跳过这一部分。
1)mybatis的整的框架
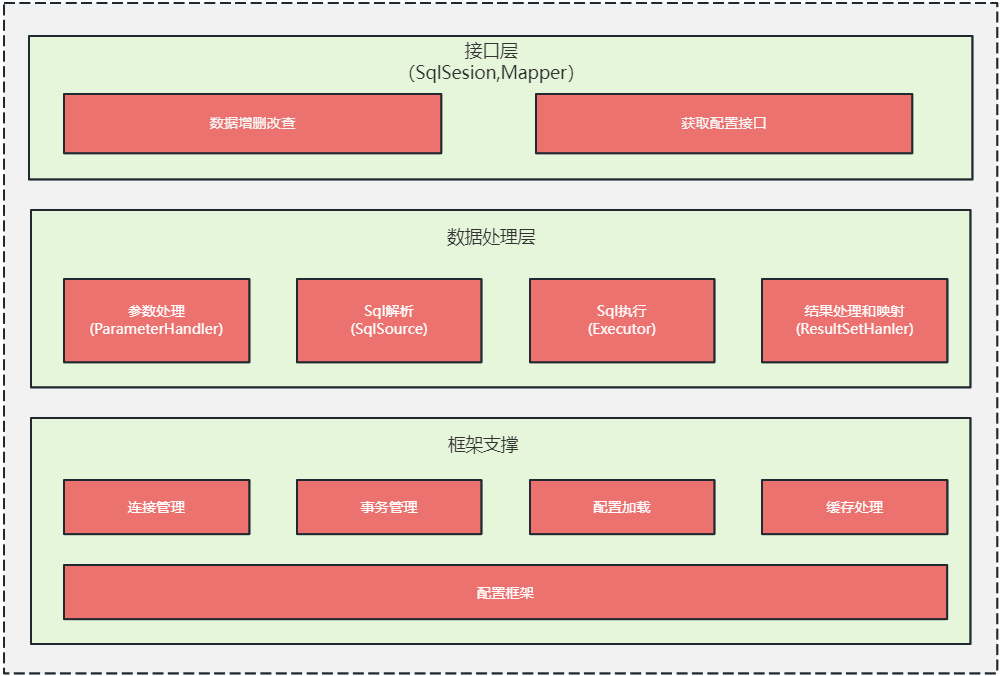
接口层:是 mybatis 提供给开发人员的 api,其主要是 SqlSession 对象, 开发人员通过 SqlSession 和 Mapper 接口来操作数据;平时我们做业务开发的时候感知不到 SqlSession,只是声明了一下 Dao 层的 Mapper 接口,就可以在 Spring 容器中拿到对应 Mapper 接口的实现来操作数据,这是因为框架帮我们做了很多事情,实际内部就是通 SqlSession 完成的,只是这个 SqlSession 的操作过程封装到了一个实现了 Mapper 接口的动态代理中,mybatis-spring 框架在扫苗包路径的时候将 Mapper 对应的动态代理实现注入到了 Spring 容器;对这块原理感兴趣的读取可以查询 mybatis 源码中 MapperProxy 及其相关类的实现。
数据处理层: mybatis 的核心实现,主要是参数处理及 sql 解析、映射、执行、结果构建,详细处理流程见后文说明。
基础支撑层: 主要包括连接管理、事务管理、配置加载和缓存处理,将他们抽取出来作为最基础的组件,为上层的数据处理层提供最基础的支撑。
2)Mybatis-Spring及Mybatis的处理流程
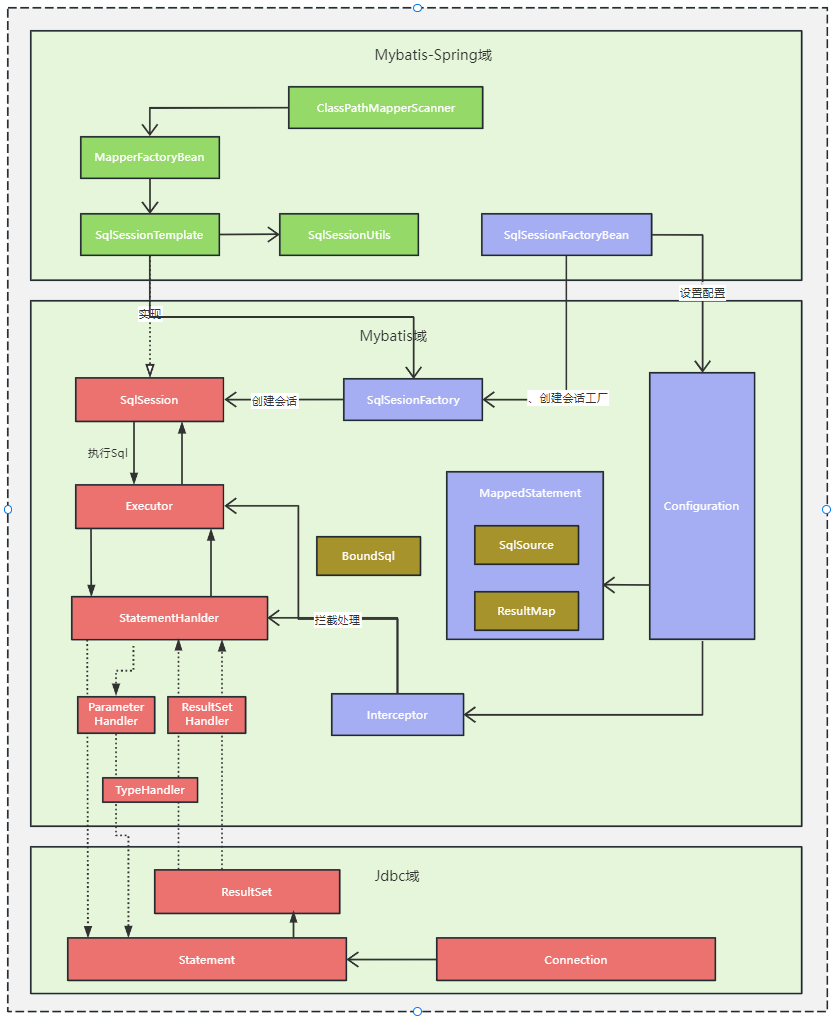
对这个图中涉及的原理做一个简单解释,读者如果对细节感兴趣,在随意起一个使用了 mybatis-spring 的项目,将图中关点节点打上断点观察即可。
sql执行流程流程解释(红色组件部分)
① 由 SqlSession 开始, SqlSession 如上文所提及的是 mybatis 开放给用户顶层 api,它定义了 sql 操作的一个会话;SqlSession 通过Executor来完成操作;
② Executor 是调度核心,它负责SQL语句的生成,调用 StatementHandler 访问数据库,查询缓存的维护,将 MappedStatement 对象进行解析,sql 参数转化、动态 sql 拼接,生成 jdbc Statement 对象;
③ StatementHandler 封装了 JDBC Statement 操作,负责对 JDBCstatement 的操作,设置参数、将 Statement 结果集转换成List 集合,是真正访问数据库的地方;在 StatementHandler 和 JDBC Statement 之间可以通过:
ParameterHandler 负责将用户传递的参数转换成;
ResultSetHandler 负责将 JDBC 返回的 ResultSet 结果集对象转换成 List 类型的集合;处理查询结果;
TypeHandler 负责 java 数据类型和 jdbc 数据类型之间的映射和转换。
Dao接口对应bean的创建及调用实现(绿色部分)
① ClassPathBeanDefinitionScanner 负现扫苗由 @MapperScan 注解描述的包路径,对符合条件的 Dao 接口通过 Spring 的 BeanDefinitionRegistry 进行注册,并将 BeanDefinition 的 beanClass 属性设置为 MapperFactoryBean;
②大家在业务代码中通过 Spring 容器拿到的 Dao 的实际其实就是 MapperFactoryBean 的通过调用 FactoryBean 接口的 getObject() 获取的;
③ getObject() 方法是通过 SqlSession 的 getMapper 方法(参数是 Dao 接口的类名)获取到了,前文提到过了 MapperProxy 实例,它体质就是动态代码调用 SqlSession,只是调过过程中的参数是由环境、Configuration 及上下文中获取;
④MapperFactoryBean 的 SqlSession 一般就是 SessionTemplate,SessionTemplate 是 Mybatis-Spring 给的 SqlSession 的标准实现,它的核心功能是通过 SqlSessionFactory 来获取实际的 SqlSession 和对 SqlUtils 对获取过程进行拦截;
⑤ SqlUtils 对获取 SqlSession 的拦截主要目的就是联结 Spring 的事务处理环境,它会判定如果是在事务环境中,同一事务下通过 SqlSessionHolder 复用 SqlSession。
SessionFactory的注入(蓝色部分)
①SqlSessionFactoryBean 对过继承 Spring 的扩展接口FactoryBean、InitializingBean 在 Spring 初始化 bean 的时候SqlSessionFactoryBean 通过调用自身的 buildSqlSessionFactory 来构建 SqlSessionFactory,这个构建过程要么是通过 xml 要么是通过注解,构建的时候也完成的 Configuration 的设置,这个Configuration 主要包括了 MappedStatement 和 Interceptor(插件)。
② MappedStatement 就是用来存放我们 SQL 映射文件中的信息包括 sql 语句,输入参数,输出参数等等。一个 Dao 方法对应一个 MappedStatement 对象。
③ Interceptor 就是 mybatis 的插件,它通过责任链模式实现,可分别在 Executor 阶段或 StatementHanlder 执行价段进行拦截。
升级期间继续保留的单库单表数据库,同时按新的规则建立分库分表。在辅营业务系统中,分库是以业务线为依据的,基本按照一个业务线一个库来划分,分表是以辅营系统自身的订单号为依据,以月为单位进行划分的(单号中含日期信息)。
所谓数据双写,就是当业务需要进行数据进行增删改的时候,同时对两套数据库进行增删改;当业务需要读数据的时候,只需对一套数据库进行读即可。当我们确定在所有情况下,对分表进行读写与对单表进行读写是等效的时候,我们就可以下线单表那套数据源了。
这个双写的过程不是由业务代码来完成的,而是通过 mybatis 插件来实现。使用 mybatis 插件来拦截 sql,更换 sqlSession 及改写 sql,可以覆盖当下所有的 sql 及未来可能出现的 sql,同时开关切换可细化到 DAO 层的一个具体方法上,单库切换成分库的过程就可以最小粒度到一条条Sq的l执行上,在渐近性升级过程中,可以一步一确认了,通过监控和日志观察,如发现存在问题可以立马切回,将发生错误的负面影响降到最低。
另外,借助于去哪儿的配置中心 qconfig 的部分推送功能,可以将线上的应用进程先小部分切换,待确定稳定后再推送到全部实例。
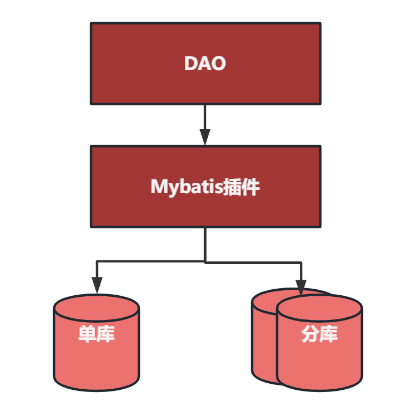
双写思路看着简单,但要真正实现双写并不容易,中间会引出新的技术问题:
第一个问题是,在 mybatis 内部如何正确切换执行的目标库;
第二个问题是,在 mybatis 内部如何对 sql 的执行过程进行复制并用分库的执行结果替换掉原有的执行结果。
对于第一个问题
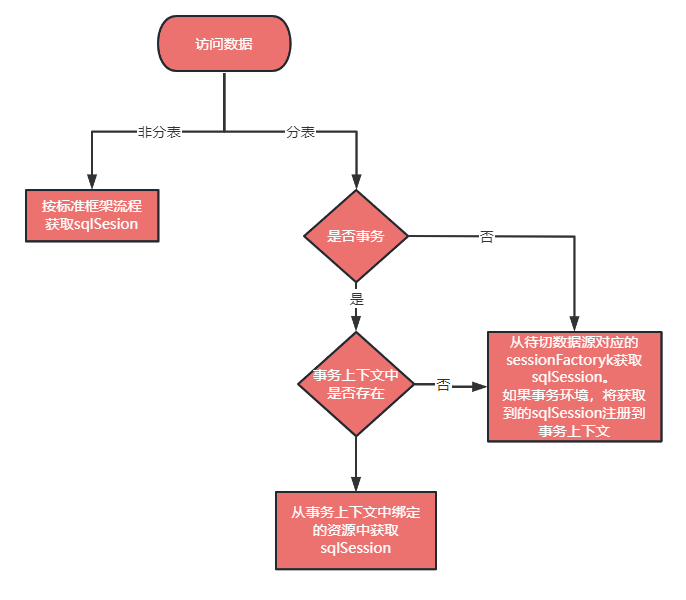
我们第一版本的做法是直接从待切数据源(分表)中重新获取 sqlSession,通过 Spring 的事务管理 api 来判定当前是否属于事务环境,如果是事务环境,则先从线程上下文中获取,如果不存在再从待先切数据源中获取。
在事务环境下,我们需要将切换过来的连接的autoCommit 属性设置为 false(autoCommit 属性为 true 的时候相当于是自动提交事务,基本就是一条sql执行在一个事务里,在事务环境下它需要为false,业务开发平时感知不到这个值的设置是因为 spring 事务框架自动帮我们做了这件事。
现在由于我们自己从新的数据源中捞了一个不在标准 Spring 流程的连接,所以需要自己补一下这个连接的维护), 在事务提交时再设置成 false(相当于归还连接池时进行复位了),这期间连接的获取和释放得小心,切过来的那个连接的 ConnectionHolder 和 SessionHolder 都需要补一下引用记数的维护,因为它在 Spring 和 mybatis 标准处理之外,如果不作处理就会出现连接泄露或复用了已经关闭的连接。
对于第二个问题
这个处理包括解代理、复制参数、根据参数构建新的 statement、再通过反射调用来实现 sql 在待切数据源上执行。为什么重新构键一个 statement呢?这是因为 statement 是 jdbc 提供的操作数据库的接口和概念,一个 statement 是和一个 connection 相关连的,既然双写阶段两个 connection 同时存在,那么 statement 也是有两个,分别来做两个库的执行。
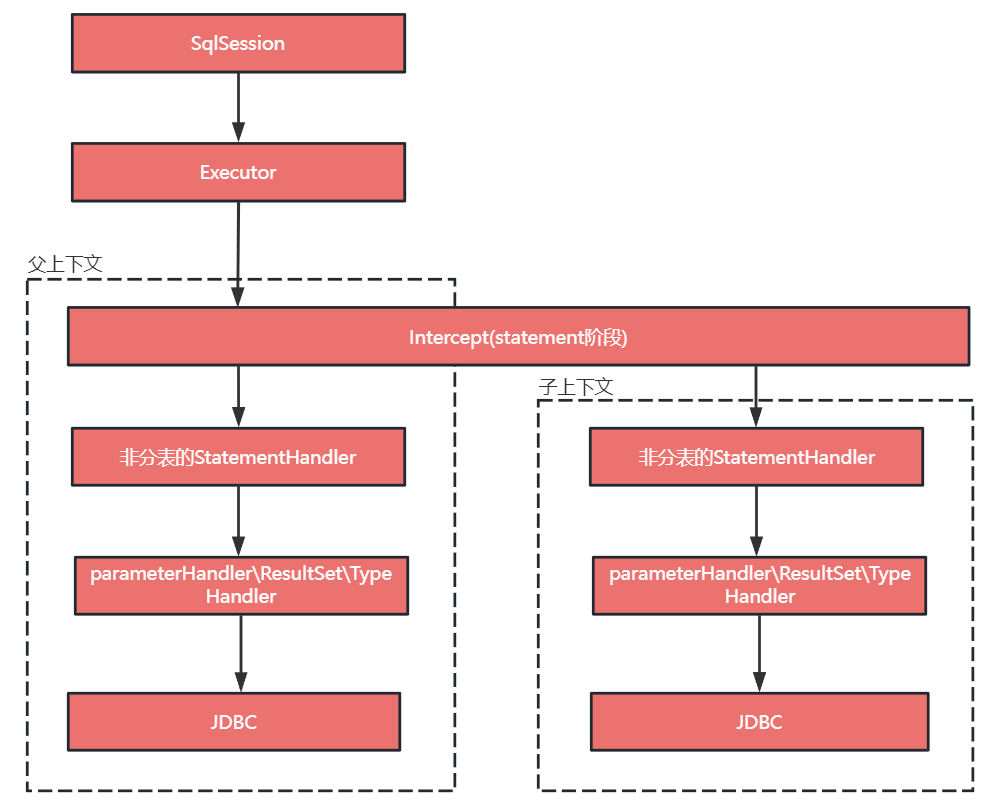
为了解决 mybatis 插件内部再次调用 sql(再次调用是原于下文中分表键的处理)出现上下文间的干扰,我们定义 sql 执行的父子上下文的概念,父上下文感知不到子上下文的存在,子上下文对变量做的任何修改、覆盖或添加只在子上下文中有效,在父上下文环境下都是无效的,这相当于给子上下文开了一个安全的环境,在内部执行的 sql 不会对外层环境产生破坏。
第二个问题是由我们的技术实现方案带来的新问题,所谓的上下文干扰一般包含分库分表中间件内部基于 ThreadLocal 做的一些变量记录,在 mybatis 插件内部再次调用另一条 sql 时可能就会出插件内调用的 sql 的上下文污染了原将要执行 sql 上下文。
双写其实可以在 mybatis 外部进行的, 在 mybatis 外部进行时就没有那么复杂的 statement 的复制和其参数的构建过程,但由于当时我们系统 mybatis 外部调用入口多且不统一,且先前在 Dao 层做了很多特殊注解和功能,这些功能没有考虑有两个完全一样的 Dao 的情况,直接在 mybatis 外部进行双写,改动太多其负面影响也不好预估,所以才在 mybatis 插件内部做了双写的实现。
通常不含分表键条件的 sql 来查询数据是不可避免的,一般的分库分表中间件对这种 sql 都是进行全表广播,其性能自然不太理想。为了解决非分表键全表广播的问题,我们提出了映射键的概念,映射键是相对分表键而言的,在 sql 查询中如不含分表键,就找映射键,再通过映射键到分表键,然后根据分表键计算出分表的物理坐标,最后通过分库分表中间件 sql 路由引导的 api (这里的概念如果不了解后面有解释)来引导分库分表中间件完成查询。映射键的映射关系维护在独立的映射表中,这个映射自身也是分表的,分表规则就是映射键的值的 hash。
举个例子,比如通过券码(couponId)查订单,那么这里的券码(couponId)就是映射键, 券码(couponId)的具体的值就是映射键的值,辅营自身的订单号(orderId)就是分表键,couponId→orderId 就形成了一个映射, 我们在 sql 查询中就可以只包含 couponId。除了这种直接映射外,还有一个间接映射,在辅营系统中,表面是按订单号进行分表的,本质是按订单号中的时间条件进行分表的,在上下文已知业务线的情况下,如果查询条件中包含订单号的创建时间,那么就算不含分表键和映射键也是可以对物理表坐标进行定位的,从而减少 sql 全表广播的可能。
sql 执行过程可以抽象如下图:
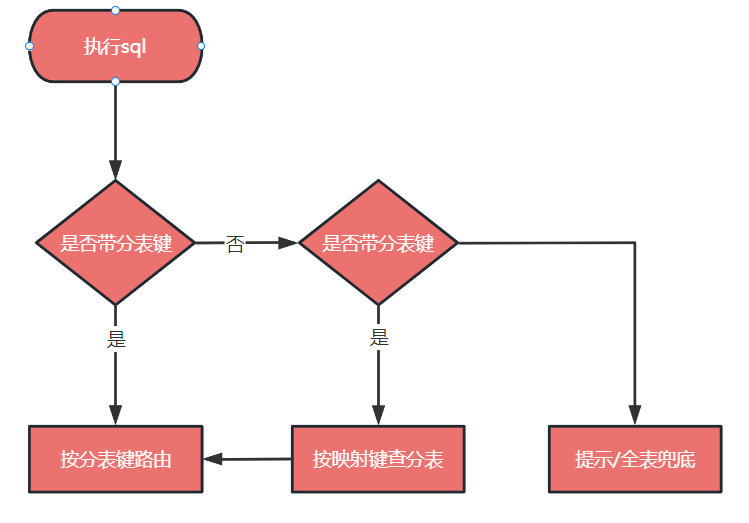
映射键思想的提出使得我们不用改写所有的 sql,大大提高了分库分表的适用范围。在实际开发过程中,还有一种 sql 也是无法改写的,那就是全表数据扫苗,比如我们要定期扫苗待过期的券码,在分库分表环境下应该怎么做呢?
这里我们通过提供了一种手工定位和迭代所有物理库和物理表的 api,把形如 selectAll 的查询需求转化为对物理库和物理表下数据的分批访问,用户通过设置回调函数来处理每一批数据。
diff 是指的是对单库单表和分库分表的内容进行比较,如果 diff 的结果一样,且主分是在一个事务中则可验证分库分表前后系统在业务上是等价的。然而,要做到这两点好像是不可能的,特别是事务,事务应该只在一个数据库会话中才是有效的。
理论上追求的是严紧、是必然;工程上追求的是可行、是可然和近然。接下来我们看一下 diff 和事务是如何实现的。
对于 diff,同步 diff 肯定影响性能,也不能进行采样化解,毕竟我们要确定全部数据是否一致;而异步 diff,可能由于读取的时间点不一样数据已经被改变了,这样就算 diff 结果显示不一致也不能说明同一时刻的数据是不一致的。
我们最终的 diff 方案是离线 diff 加实时 diff 相结合的方式,通过 diff 一段时间,如果 diff 差异是收敛的说明细节的修订是有效的, 当24小时内偶发个位级别的不一致,我们就可以认为两边数据上基本等价了(实际上,我们最终 diff 差不多是0)。
离线 diff 就是对两套数据源当日之前的数据进行全量 diff,实时 diff 是指对当下数据操作进行 diff。实时 diff 先 diff 数据修改的返回结果,如果在数据增删改过程都不一样,那么数据读的过程就没必要进行 diff 了,毕竟在过度阶段双写是必然要进行了,直接拿双写的结果进行 diff 是没有额外性能开销的,待双写 diff 达到完全一致时,再有选择的分批对读进行 diff。为了不影响性能,读 diff 是异步的,前面也说过读 diff 不一致不能完成说明是数据是不一致的,但是可以作为一种参考,当 diff 出现不一致时我们打印出两边的线程堆栈来排查可能的不一致的原因。我们最终以离线 diff 的为判定依据,实时 diff 还是多用于排查问题和确认问题。
再来说一下事务,事务用来保证两个地方的一致性。第一个是映射表与业务表的一致性,两方表任何一方漏数据必然导至业务在某个查询下检索不到数据,所以对于映射表的操作是和业务表的操作强绑在一个事务中。第二个是单库与分库在进行双写时也需要在一个事务中,这里显然要使用到分布式事务,传统的几种分布式事务都不适用我们的场景,不是需要一定的业务侵入配合就是性能上有影响,我们在这里采用了一种特殊的"分布式"事务的设计,既满足了性能要求,又能尽量做到一致性。其实现原理参见下图:
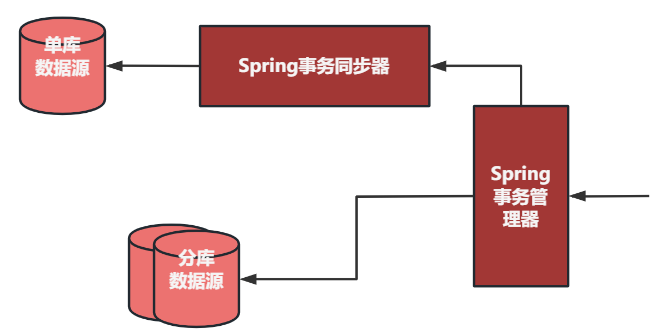
事务管理器只能设置一个 DataSoure,当在事务环境下需要对另外一个数据源进行操作时,会将另一个数据源中获取的 connection 包在一个 Spring 的事务同步器中,并将这个 connection 的 autoCommit 属性设置为 false, 在同步器的回调函数 beforeCompletion 中分别增加 SqlSessionHolder 和 ConnectionHolder 引用计数(不增加会被 Spring和 mybatis 框架错误回收,到 afterCompletion 环节时连接就可能是已经关闭状态), 在 afterCompletion 回调函数中根据事务状态对这个 connection 做提交或回滚,并分别将 SqlSessionHolder 和 ConnectionHolder 引用计数减一,将 autoCommit 重置为 true。
这个相当于一个数据源使用的 spring 事务框架事务,另外一个借助它的扩展手工处理事务, 虽然从严格意义上来说它们不是一个完整的事务,但是两个事务关联在一起只有后者(手工的那个)提交失败,前者提交成功才会引发不一致,出现这种情况的时间窗口很小,且在前者与后者间加段监控可以监测到这种现象的出来。我们上线后通过观察没有出现过这种情况,只在人为测试制造这种 case 的时候才会出现,其他情况两个事务的状态完全一致。
三、新的问题
上述设计虽然帮助我们完成了辅营交易数据库从单库单表平滑迁移到分库分表,但是也存在一些后续问题,这些问题主要表现在以下方面:
测试开发不友好,分库分表的设计很重,如果所写的测试关系到数据层的话则需要依赖一整套分库分表环境,这个环境的建立是有成本的,结果大家只是依赖公共的测试环境,多人依赖测试数据容易有冲突,且对于本地测试极度不友好,集中表现在写本地单元测试时,启动一套分库分表过程很慢。
维护成本有点高,这个与方案本身的关系可能不太大,主要是技术实现细节上造成的。早期,主分之间的路由判定依赖于大量的注解和配置中心的配置,还有项目中的各种配置,新加分表关注点很多,如果不是很了解原理和技术的实现细节很容易错配,从而导致事故。
不好复用,实现上有一些业务侵入,比如依赖从spring 容器中取数据源的 bean; 分库分表规则也是一次性的,如果未来有变化也没有扩展点,比如说从一月分一次分表,改为一周分一次分表,那么就会出现新旧不兼容。这套代码也不好做到从一个项目迁一到另一个需要分库分表的项目中直接复用,迁代码需要大量修订。
正因为上述问题的存在,我们在辅营 DDD 重构微服务拆分过程中,将这个分库分表方案进行组件化。除了方便方案更好的复用外, 在易用性上做了很多的提升,可以很方便的切换单库和分库的环境,也可以很方便的修改分库规则。
这对于新建的 DDD 项目是非常提效的,结合单测工具,在项目初建的时候可以完全只考虑业务领域模型问题,将分库分表后置,待业务逻辑跑通后,先配置单库验证订单数据的完整生命周期,无误后再通过一点配置就切换至分库分表环境了,且在开发过程中如表结果发生表数量表结构的变化可以随意修改分表规则配置,不会引起业务代码的改写。
四、分库分表平滑迁移组件化
如何将这个方案组件化,并且让大家在接入的时候做到最少知道,不必关心组件自身原理和实现细节呢?
在谈具体实现过程前,再给大家普及一些分库分表中间件原理的基础知识,了解这部分的同学可以跳过。
1)关键名称解释
分⽚键: ⽤于分⽚的字段,是将数据库(表)⽔平拆分的关键字段。
逻辑表: 是指一组具有相同逻辑和数据结构表的总称。
物理表: 与逻辑表对应,一个 order_form 可以被拆成多个物理表。
分片策略: 分⽚键 + 分⽚算法, 分片策略是 sql 进行路由的依据。
2)分库分表中间件的基本原理
当我们执行一条 sql 的时候,分库分表中间件会对这条 sql 进行分析,根据配置的分片策略将数据路由到对应的物理表,具体过程如下图。

一般的分库分表中间件都是在 Datasource 层面做数据库的路由,内部一般维护一个 dataSourceMap 的对象,key 就是分库时的分片键; 在 connection 或 statement 上做分表的路由,在 Resultset 上做结果数据的 merge。
1)设计定位
本着不重复造轮子的原则,我们基础的分库分表能力还是借助现有的分库分表中间件,我们要做的是辅助分库分表中间件适配更多的 sql 场景和做好 sql 分发,所以我们定位在分库分表中间件上层做 plus。
2)设定切入点
组件化要求尽量做到对业务透明,为了满足这一要求就要从现有数据层中找核心概念(接口)进行扩展,我们来看看数据层一些核心概念及其所属的位置。
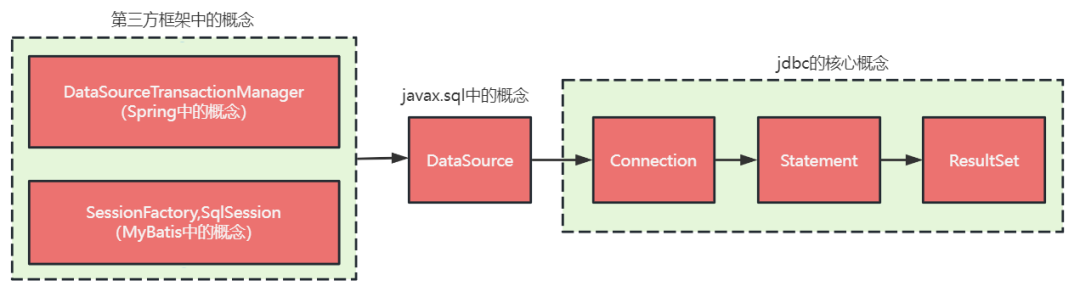
一般分库分表中间件都是从 DataSource 或 connection 之后开始做扩展的, 由于我们的系统中固定使用了 Spring 和 MyBatis,所以我们可以从 Spring 和 Mybatis 开始做扩展,这样双写或多写逻辑就可以在 mybatis 外部进行,实现上更容易,且不用改变 mybatis 内部的默认逻辑,没有 mybatis 本身升级所带来的兼容风险,同时可以对 mybatis 做一次增强,例如根据用户配置的分片键默认生成一批常见的 sql 映射到 BaseMapper 中,减少业务研发日常编写代码工作量(关于对 mybatis 增强这块不在本文讨论的范围,有兴趣的同学可以去看 mybatis-plus 的原码,原理是相同的)。
3)路由引导
是指对分库分表中间件分发 sql 的过程进行引导,使其按期望的过程进行,具体来说就在逻辑表转化成物理表的过程中指定转换的范围。根据前面介绍的分库表分中间件的原理,这个 api 就算中间件不提供也可以自己适配一个出来,通常可以通过自定义分片策略来造出来。去哪儿的分库分表中间件 qdb 直接提供了路由干预的 api,或者说是手动路由 api。
4)sql路由
sql 路由是实现整个分库分表增强的核心,在执行流程到达分库分表中间件之前先通过我们的组件进 sql 路由,具体路由过程见下图所示:
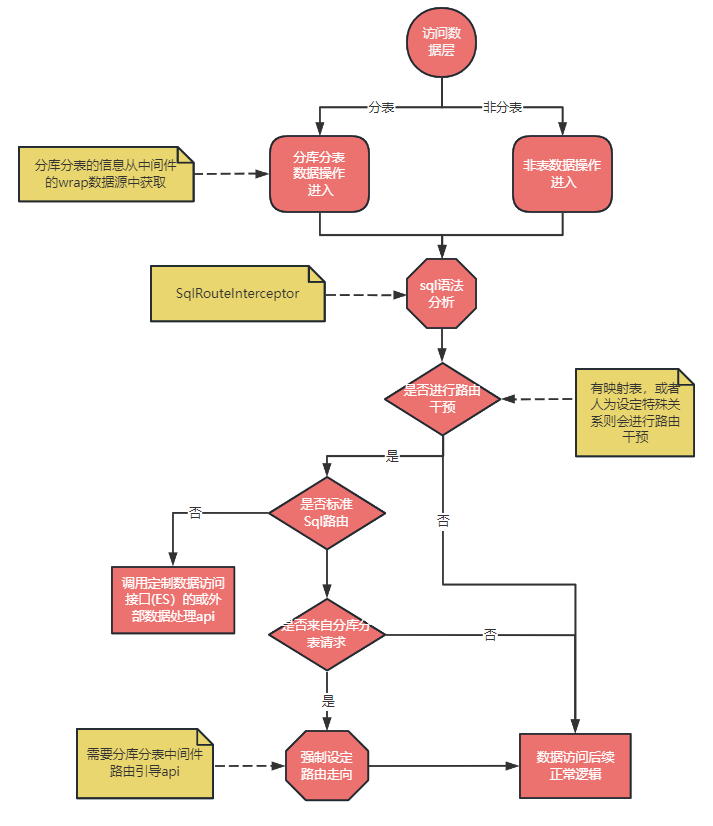
注意该图路由范围仅画出分库分表中间件之上的部分,分库分表中间件内部如何路由对我们来说是透明的, 也就是说我们是可以按需更换分库分表中间件的。
流程解读:
对于走分库还是非分库是在最开始的时候由用户配置来决定,如果用户配置中有分库分表中间件,走分库分表逻辑;如果是单库则走单库逻辑;如果分表库和非分表都有则两个各配置配置一个 SessionFactory,分库的 SessionFactory 管理的表走分表库逻辑,单库的 SessionFactory 管理的表走单库逻辑;这一点与辅营交易现有的 SessionFactory 的分工是不同的,辅营交易现有分库分表上实现上,主表库的 SessionFactory 还管理着分表库的表。
值得说明的一点的是,在我们的设计里不强调全局表和广播表的概念,取之以单独的主库表替代,这种方式经营成本更低,缺点是表分别位于分表库和主表库中,无法进行 join 查询。事实上,我们在划分表空间时,根据 DDD 结果也会尽量将同一个业务领域的表划分到一起,以便其可以进行 join 查询;所以一般不会出来主表库要和分表库进行 join 的场景。
无论是分表还是单表,执行流程都会进入 SqlRouteInterceptor (mybatis的插件),都会进行路由干预,因为主表库至少也是有读写分离控制要求的嘛。
是否进行路由干预是由有无映射表逻辑或业务层面调用路由干预 api 来进行判定的,如果没有那么直接走后面逻辑即可,如果有,则对 sql 类型和条件进行判定,对于有复杂查询条件的 sql 查询可以走 ES 和数据组宽表查询的接口(初版没有开发这个功能,后续可按情况添加)。
对于有映射表逻辑的 sql 操作,先从映射表中找出分表键,然后再能通过分库分表中间的路由引导 api 来指导分库分表中间的执行。
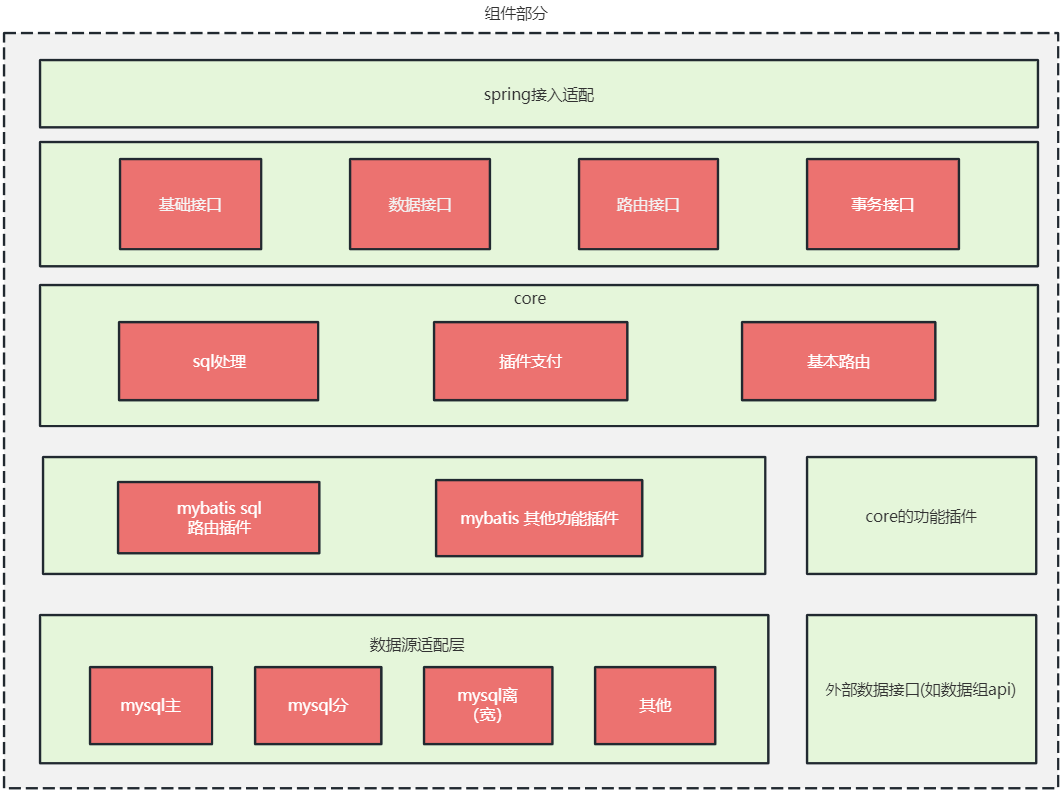
总体来说一共分为三层。
接入层:负责给应用接入提供稳定和兼容的接口, 其中的 spring 接入适配是在项目稳定后再视情况开发,一般是在 spring 环境上提供一些注解和 starter;
core 层: 路由逻辑的核心实现,并基于路由逻辑建立生命周期,提供插件化的扩展点,使外围功能可以以插件的方式开发;
存储层: 负责最终 sql 的执行,数据的最后落地, 与接入层配合实现事务,主要由数据源和 mybatis 组成。
在实际编码实现过程中将 core 层和存储层放在一个工程 qmall_db_core 中, 将接入层单独放入另外一个工程 qmall_db_shell; 处于接入 层的 api 都会在后续版本升级过程中保证向下兼容。下面对核心部分实现和接入部分实现加以说明,存储部分的实现主要是对 mybatis 做的增强,不在本文讨论范围内。
1) 核心代码流程
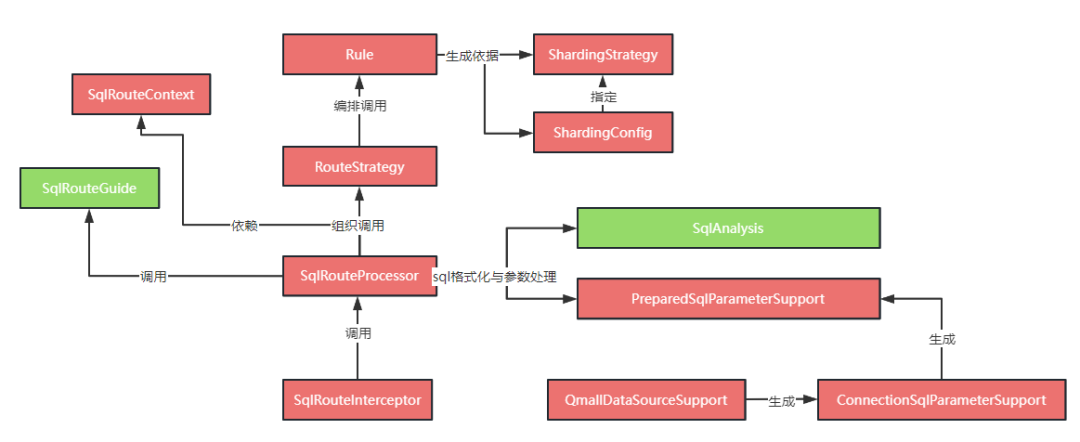
以 SqlRouterInterceptor(mybatis插件)为 sql 进入路由的入口, QmallDataSourceSupport 为参数处理的入口。SqlRouteProcessor 用于组织协调各组件进行路由干预。SqlRouteProcessor 隔离了对 mybatis 的依赖(也就是它之后的调用不依赖于 mybatis),汇集了宏观路由流程。其主要流程如下:
调用语法分析行到 SqlInfo, SqlInfo 中包含了后续 sql 路由分析的所有数据结构,如sql中含有的查询条件、sql中关系到的表和列、sql的类型等;
调用参数处理,将 DAO 中传递的参数填充到 SqlInfo 结构中, 以使后续流程可以很方便的找到列或条件对应的实参值;
根据 SqlInfo 的内容选择合适的路由策略 RouteStrategy,选择的路由策略过程就是匹配得分最高的一个策略,比如有两个读的策略,一个是按分片键路由,一个是按映射键路由,当 sql 条件中有分片键时会优先命中分片键路由,而没有分片键的时候将命中映射键路由,路由也可以定制化,当对于某个特殊的 sql 想走 es 索引时可以针对这个 sql 的 Dao 名加方法特定命中一个走 es 索引的路由;
路由策略根据操作的类型来组织路由规则,对于写是所有路由规则都执行,对于读只要一个规则判定成功就返回,这个写的路由规则通常就是维护映射键的映射表数据,而读的路由规则是从多个映射键中选择一个可行的映射规则找到映射键的值,然后通过映射键的值找到分表键的值,通过分表键加分片策略算出待查数据的物理坐标;
根据计算出物理坐标,调用分库分表的路由中间件的引导 api 来执行路由引导,这个引导 api 就是图中定义的 SqlRouteGuide 接口,不同的分库分表中间件可以对这个接口进行实现来完成与本组件的基础能力对接。(完整对接还要有配置适配上的对接)
2)关键点
语法分析与参数填充的实现
语法分析主要借助 druid 的语法分析工具对 sql 进行解析并提取出期望的数据结构。参数填充这里使用了一些技巧,应用在接入本组件设置数据源的时候显式或隐式的将这个数据源包装成 QmallDataSourceSupport 的子类实现,通过 QmallDataSourceSupport 来获取的 connection 是一个被包装后的 ConnectionSqlParameterSupport 实例,这个实例在执行 prepareStatement 方法的时候返回的是我们通过动态代理 PreparedStatement 接口的实例,其实际调用过程是通过实现了 InvocationHandler 接口的 PreparedParameterSupport 类完成, PreparedParameterSupport 类的作用是前面的 PreparedStatement 实例在调用各种 set 方法时记录下当时的参数的位置 ,这个位置与占用符的位置刚好是一一对应的(sql 语法解释出来的内容顺序要与 sql 字符串中占位符的顺序一致),所以可以非常准确的将参数回填时 SqlInfo 这个结构中。
有人可能要问,为什么不直接分析 mybatis 内部的那个参数结构呢?这个试过但有各种坑,mybatis 在 DAO 的参数处理过程中它自己会做一些处理,map 中有值相同 key 不同的重复内容且从那个 map 获取不到 key 也会抛异常,另外我们的设计也不太想和 mybatis 内部数据结构有耦合,否则若 mybatis 升级把这个数据结构改动了我们这个系统不就用不了啦。其实,还有一种实现就是使用自定义 mybatis 的 ParameterHandler,这个实现方式我们也做过,两相比较,还是包装代理 Connection 的方式更好,因 Connection 是可以执行流程中被很容易拿到的,附带一些功能很方便,而且与 mybatis 没有任何关系,就算不用 mybatis 用 springjdbc 这套方案仍然是有效的。
路由策略RouteStartegy、路由规则Rule、分片策略间的关系
路由策略是由一组路由规则组成的,选择不同的路由策略就像选择不同的数据库索引。路由规则是决定数据如何路由的原子单元,比如一个映射键可以构建一个路由规则,多个映射键就构建多个路由规则,一条sql中是可能包括多个映射键的,它就有多个路由规则,这多个路由规则共同构成一个路由策略。对于写逻辑多个映射关系都需要维护,所以写逻辑的路由规则必须都生效;对于读逻辑只需要通过一个映射键到找了分表键,后面的映射键的路由规则就不需要执行了,所以读的时候只需要一个路由规则有效即可。路由规则是由配置的分库分表规则动态生成的,分库分表规则使用到了不同的分片策略。
配置定义
我们来看一下分库分表规则在我们这个组件中如何定义的?
在项目的 resource 目录下放置一个 sharding.properties 的配置文件,内容如下:
#库的前缀(这么做完全是为了照顾qdb的配置)db.prefix=qmall_supply_#分库配置db.index.qmall.flight={dbIndex: 0}db.index.qmall.inter={dbIndex: 1}db.index.qmall.ticket={dbIndex: 2}db.index.qmall.hermes={dbIndex: 3}#分表键配置sharding.user_info=[{shardingKey: 'last_name',intervalMonth:2,hashCount:0,startTime: '2020-11-01'},{shardingKey: 'last_name',intervalMonth:2,hashCount:2,startTime: '2024-07-01'},{shardingKey: 'last_name',intervalMonth:2,hashCount:1,startTime: '2021-07-01'},{shardingKey: 'last_name',intervalMonth:1,hashCount:2,startTime: '2022-07-01'}]sharding.supply_order=[{shardingKey: 'supply_order_id',intervalMonth:1,hashCount:2,startTime: '2022-11-01', hashGroupReg: '20[0-9]{2}(0[1-9]|1[0-2])[0-9]{6}'}]sharding.supply_order_ext=[{shardingKey: 'supply_order_id',intervalMonth:1,hashCount:2,startTime: '2022-11-01'}]#分表键日期提取正则(视情况可选)shardingKey.extract.date.pattern={supply_order_id: '20[0-9]{2}(0[1-9]|1[0-2])'}#映射键配置, priority越大,优先级越高, priority不可出现相同的值table.supply_order=[{mapKey: 'business_order_id', type: 'one2many', priority: 1, maintain: 'auto_manual'}]table.user_info=[{mapKey: 'id', type: 'one2one', priority: 1},{mapKey: 'phone', type: 'one2one', priority: 1, maintain: 'auto_manual'}]
从这个配置文件中我们可以看到,分库配置按我们内容业务线,分表配置是由分表键配置和映射键配置组成,分表键的分片算法配置项中目前只按我们自身业务需要支持的 hash 分片和时间分片,这两者可以同时使用。不知道读者有没有注意对于同一张表,我们可以有多条分片规则配置,它们主要是 startTime 不同,startTime 的含义是本条分片配置生效的起始时间,其作用时间范围直至出现下一个大于当前的 startTime,下一个 startTime 不出现则表示当条规则持续生效。一张表只有分表键配置存在时,映射键配置才有意义。正因为配置存在这样一些特点,我们可以通过配置平滑的把一个单表变成一个分表。比如,要将 supply_order 表从单表切换成分表,只需按下面进行分表配置即可
sharding.supply_order=[{shardingKey: 'supply_order_id',intervalMonth:0,hashCount:1,startTime: '2000-01-01'},{shardingKey: 'supply_order_id',intervalMonth:1,hashCount:2,startTime: '2023-11-01', hashGroupReg: '20[0-9]{2}(0[1-9]|1[0-2])[0-9]{6}'}]
第一条配置作用时间是2000-01-01至2023-11-01,这期间是没有分表的;第二条配置作用从2023-11-01开始,每间隔一个月hash分两张表;这样就相当于业务无感知的从单表过渡到分表了。对于单库和分库的切换则使用的是多环境打包完成的,不同环境激活的是不同的数据源,单库激活的是单库的数据库连接池,多库激活多库的连接池。
sharding.properties 这个配置文件也可以在不同环境中存在不同的内容;这样就可以很方便的做到本地测试用单库,测试和线上环境使用分库分表了。注意要将不同环境的分表键及映射键的规则定义一致,这样在单库上能跑通的 sql 在分库分表环境上也不会有任何问题(因为只要分表的配置规则相同,即使底层数据源是单库或者没有用分库分表中间件,我们内部的那些路由判定规则一样会执行,不符合要求的 sql 是能暴露出来的)。
那么可能有人要问,你这里定义的分库分表规则,分库分表中间件里也定义了规则,两者有冲突怎么处理?
答案是没冲突。在决定开发配置的时候,我们就思考:
新的组件是对已有分库分表中间件做 plus,所以必然会有一些新的配置需求,这些新的配置需求最好能很直观的与已有分库分表配置关联;
不要对已有分库分表中间件的配置文件做修改或对其有代码侵入,否则会增加用户的学习成本,而且从长期来看也会形成耦合,一旦分库分表中间件有大版本升级就不方便跟进了。
为此,我们做了两件事:
我们的组件不直接依赖任何底层数据源或分库分表的配置,只依赖 sharding.properties,数据源按标准接口接入即可。
分库分表中间件的配置统一使用自定义分片策略配置,由我们的组件根据不同的分库分表中间件的自定义分片策略接口来实现具体的分片,然后在分库分表中间件的配置文件中只配置我们自己的分片策略。
第一件事是划清了本组件与分库分表中间件的边界,即双方只按标准接口对接;第二件事相当于是让分库分表中件间通过自定义策略的方式将它的分库分表规则委托给我们的组件,从而避免两头配置上的冲突,也就是最终如何分库分表将以我们的配置解释为准。
接入层分为四部分,限于篇幅,这里简单说明一下。
基础接口
自定义 DataSouce 和自定义 SessionFactoryBean。自定义 DataSouce 主要作用就是将对外部传入 DataSouce 进行包装,它的功能包括识别是否分库数据源、读写分离、多数源事务关联。SessionFactoryBean 的主要功能是组建初始化入口、自动生成分表、扫描 mybatis 的 mapper 文件初始化 mapper 实例。
数据接口
主要有两个,一个是 DAOTemplate,模仿的是 JDBCTemplate, 与其不同的是它能很方便在分库分表环境下写各种临时 sql,适合测试场景写一条只在测试时才用的 sql 或一次性 sql;另一个是 BaseMapper, 它自带基础的增删改查功能,业务的 Mapper 继承于它可以省写很多常见的操作。
路由接口
提供了手动指定路由过程的接口,如使用 SqlRouteHelper.runOnSpecificContext (SqlRouteCondition condition, Runnable runnable), 则 runnable 的运行过程中其内部的 sql 路由将受 condition 的影响,condition 的内容为是否走从库、走哪个物理库、哪些逻辑表、哪些物理表,这四方面内容可部分指定也可全部指定;除此之外,还提供了一些用于排查路由问题或数据问题的静态方法,比如通过映射键找分片键,通过映射键的值获取 db 索引等。
事务接口
事务接口是对 DataSourceTransactionManager 与 TransactionTemplate 的继承,用于实现上文所提到的“分布式”事务。
总结
本文介绍了两次进行平滑分库分表的设计,第一次是在已经运行多年的系统上进行分库分表改造,这个过程为了求稳,主要采用了双写加 diff 的方式通过一条条的 sql 切换来降低升级过程中的风险,同时对于不支持分表键查询的 sql 采用了映射键和映射表的方式解决。
第二次是在从旧系统拆分出新系统过程中,新系统也有分库分表需求,为了照顾新系统的易用性以及初始编码过程中可能出现的变化,减少底层分库分表的变化对上层业务编码的返工,在承接第一次方案的设计的基础上将方案进行了组件化。基于开发成本和开发时间的考虑,目前产出尽管不通用,但他完成了我们当时的首要目标——完成业务应用的 DDD 和微服务拆分。
通过本文介绍,我相信读者应该看到一种可能,那就是从单库单表系统至分库分表的系统的平滑过度是可能被中间件解决的。本文的产出是专用的,但思想通用的,随着实际场景的复杂,可能还会遇到更多问题,这需要我们开发者的更多的努力。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721