
Pinecone 是一家向量数据库公司,刚刚以约 10 亿美元的估值筹集了 1 亿美元。
Shopify、Brex、Hubspot 等公司都在他们的 AI 应用程序中使用向量数据库和 Embedding。那么,它们究竟是什么,它们是如何工作的,以及为什么它们在 AI 中如此重要呢?让我们一探究竟。
我们先看第一个问题,什么是 Embedding?你可能在 Twitter 上已经看到这个词被无数次提及。
简单来说,Embedding 就是一个多维向量数组,由系列数字组成。它们能够代表任何东西,比如文本、音乐、视频等等。我们这里将主要关注文本。

创建 Embedding 的过程非常简单。这主要依靠 Embedding 模型(例如:OpenAI 的 Ada)。
你将你的文本发送给模型,模型会为你生成该数据的向量结果,这可以被存储并在之后使用。
Embedding 之所以重要,是因为它们赋予我们进行语义搜索的能力,也就是通过相似性进行搜索,比如通过文本的含义。
因此,在这个例子中,我们可以在一个向量空间上表示“男人”“国王”“女人”和“王后”,你可以非常容易地看到它们在向量空间之间的关系。
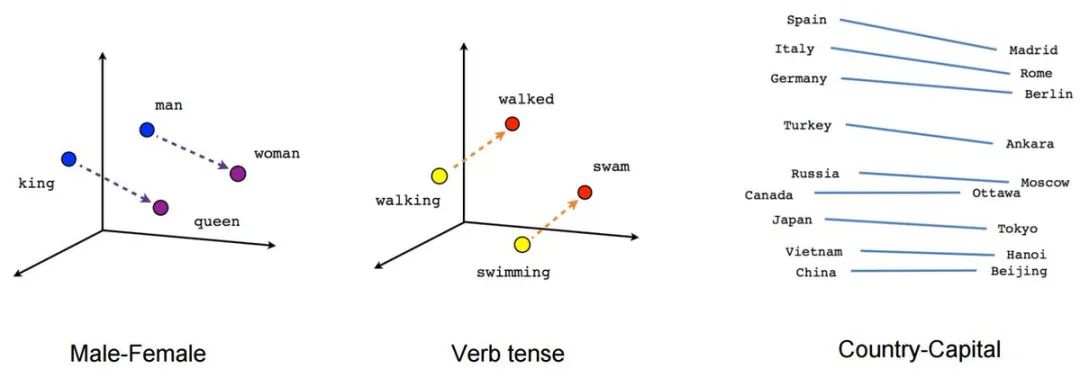
来看一个更直观的例子:
假设你是一个有一大箱玩具的小孩。现在,你想找出一些类似的玩具,比如一个玩具汽车和一个玩具巴士。它们都是交通工具,因此它们是相似的。
这就是所谓的 “语义相似性”—— 表示某种程度上事物具有相似的含义或想法。
现在假设你有两个相关联但并不完全相同的玩具,比如一个玩具汽车和一个玩具公路。它们并不完全相同,但因为汽车通常在公路上行驶,所以它们是相互关联的。
那么,Embedding 为何如此重要呢?主要是由于大语言模型(LLM)存在上下文限制。在一个理想的世界中,我们可以在一个 LLM 提示中放入无限数量的词语。但是,正如许多人所知,目前我们还做不到。以 OpenAI 的 GPT 为例,它限制在大约在 4096 - 32k 个 token。
因此,由于其 “内存”(即我们可以填充到其 token 的词语的数量),我们与 LLM 的交互方式受到了严重限制。这就是为什么你不能将一个 PDF 文件复制粘贴到 ChatGPT 中并要求它进行总结的原因。(当然,现在由于有了 gpt4-32k,你可能可以做到这一点了)
那么,怎么把 Embedding 和 LLM 关联起来解决 token 长度限制的问题呢?实际上,我们可以利用 Embedding,只将相关的文本注入到 LLM 的上下文窗口中。
让我们来看一个具体的例子:
假设你有一个庞大的 PDF 文件,可能是一份国会听证会的记录(呵呵)。你有点懒,不想阅读整个文件,而且由于其页数众多,你无法复制粘贴整个内容。这就是一个 Embedding 的典型使用场景。
所以你将 PDF 的文本内容先分成块,然后借助 Embedding 将文本块变成向量数组,并将其存储在数据库中。
在存储分块的向量数组时,通常还需要把向量数组和文本块之间的关系一起存储,这样后面我们按照向量检索出相似的向量数组后,能找出对应的文本块,一个参考的数据结构类似于这样:
{
[1,2,3,34]: '文本块1',
[2,3,4,56]: '文本块2',
[4,5,8,23]: '文本块3',
……
}
现在你提出一个问题:“他们对 xyz 说了什么?”我们先把问题“他们对 xyz 说了什么?”借助 Embedding 变成向量数组,比如[1,2,3]。
现在我们有两个向量:你的问题 [1,2,3] 和 PDF [1,2,3,34],然后,我们利用相似性搜索,将问题向量与我们庞大的 PDF 向量进行比较。OpenAI 的 Embedding 推荐使用的是余弦相似度。
好了,现在我们有最相关的三个 Embedding 及其文本,我们现在可以利用这三个输出,并配合一些提示工程将其输入到 LLM 中。例如:
已知我们有上下文:文本块 1,文本块 2,文本块 3。
现在有用户的问题:他们对 xyz 说了什么?
请根据给定的上下文,如实回答用户的问题。
如果你不能回答,那么如实告诉用户“我无法回答这个问题”。
就这样,LLM 会从你的 PDF 中获取相关的文本部分,然后尝试如实回答你的问题。
这就简单的阐述了 Embedding 和 LLM 如何为任何形式的数据提供相当强大的类似聊天的能力。这也是所有那些“与你的网站/PDF/等等进行对话” 的功能如何工作的!
请注意 Embedding 并非 FINE-TUNING。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721