
一、快速冷却的市场
21 年是有史以来数据库融资最火的一年,22 年上半年开始似乎还延续着势头,Timescale,Dbt Labs,Starburst,DataStax,SingleStore 都完成了上亿美金的融资。不过马上随着宏观环境的每况愈下,下半年就再也没有出现中后期数据库公司的融资事件了。早期项目里,值得一提的是 Neon 3000 万美金,以及 MotherDuck 4750 万美金的融资,但这两者都是全明星创始团队,一上来就到 A 轮。
相同的情绪也蔓延到了国内,年初还有沿着 21 年惯性 SelectDB 超 3 亿人民币天使轮这样破纪录的融资事件,接着整个行业就冻结了,直到临近年底,才又看到 Greptime 几百万美金的融资。
年末 MariaDB 通过 SPAC 上市,也立马一路从 11 块跌到 3 块出头。他的股价表现就是今年数据库融资市场的缩影,出道巅峰,一路向下。虽然融资环境大不如前,但数据库行业的发展相比去年却有更多的亮点。
二、年度技术 - Velox
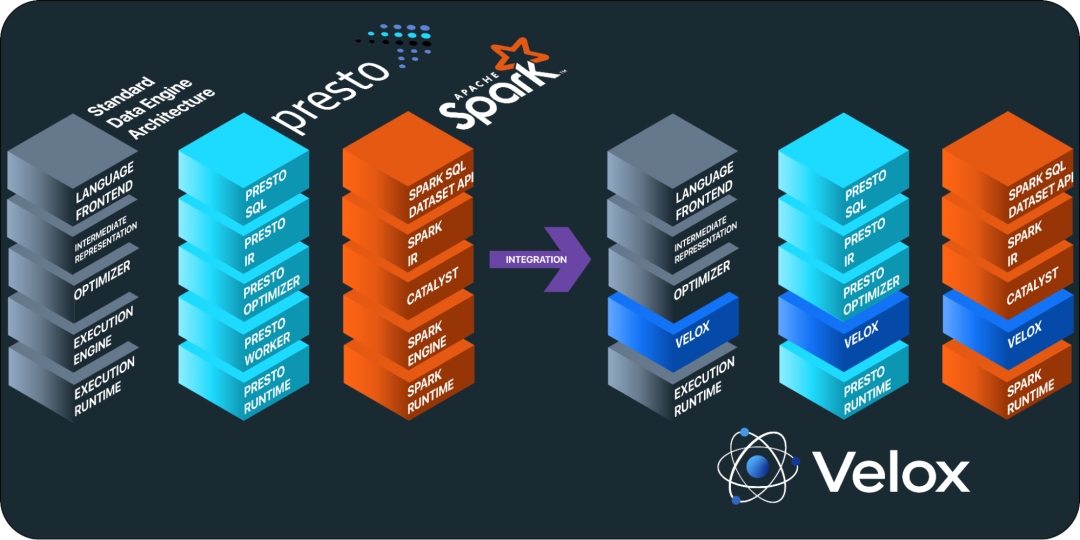
每一个数据库都需要一个执行引擎(Execution Engine),之前不同的数据库系统都是各自研发的,比如 Presto 一个, Spark 一个。但这些执行引擎要实现的功能又都是类似的。Velox 就把这些通用的能力提取了出来,封装出了一个库(Library),主要的组件包括:
Type - 通用类型系统。
Vector - 基于兼容 Apache Arrow 列式内存的向量化能力。
Expression Eval - 表达式运算,也包括利用前面提到的向量能力。
Function - 函数框架。
Operators - 算子,比如 SQL 数据库里的 TableScan(全表扫描),Project (映射),Filter(过滤),Aggregation(聚合),Order (排序),Join(连接)。
IO - 和 IO 系统对接。
Resource Management - 计算资源管理。
Velox 作为一个执行引擎,需要效率优先,兼顾工程,所以采用了 C++ 来实现。其实 Velox 也可以简单理解成数据库引擎里的 C++ STL 库,而就像 STL 库之于 C++ 一样,Velox 之于数据库引擎也有里程碑式的意义。
要理解这点,我们要看一下数据库引擎的架构,处理一条 Query 的流程大致是 Language Frontend -> IR -> Optimizer -> Execution Engine -> Execution Runtime。其中 Language Frontend + IR 大家已经都统一到了 SQL,而在 SQL 方言里,也有逐渐收敛到 PostgreSQL 的趋势,所以数据库引擎的前端已经基本标准化了。而一旦 Velox 把 Execution Engine 标准化,那么剩下的就是 Optimizer 和 Execution Runtime,这两块也正是引擎之间真正的差异化点。
物理世界中最接近数据库的应该是 F1 ,我们也就用 F1 来个类比。

Language Frontend + IR 相当于驾驶指令集;Optimizer 相当于策略,比如进站两停还是三停,用干胎还是雨胎;Execution Engine 相当于车身材料,齿轮,尾翼 ,传动轴等整套传动系统;Execution Runtime 相当于悬挂硬度,齿轮比等的调校;不同的 F1 赛道 + 天气这些环境因素则相当于不同的业务场景。

在有了标准化的 Velox 之后等于是大家装车的部件都是一样的,研发数据库引擎就像是把 F1 比赛的竞争简化成了「策略 (Optimizer)+ 调校(Execution Runtime)」 和「赛道+天气(业务场景)」的适配。这带来的结果自然是各个车队拼命卷前面两块,每条赛道的最快圈速被不断刷新。
当然现在市面上主流的数据库都拥有了自己的 Execution Engine,要替换成 Velox 的可能性并不大,但新的数据库项目就很有可能采用 Velox 了。毕竟有了它,像给数据库加入向量能力,大概花几周就搞定了,就像车队不需要自己做风洞试验去研发尾翼,只要研究如何把现成的尾翼安装到合适的位置。
三、年度功能 - ReadySet
ReadySet 是创始人 Jon Gjengset 基于他在 MIT 的博士论文 「Partial State in Dataflow-Based Materialized Views」创立的公司。简单来说,就是做了一层 Cache,但和 Redis 这种专门的缓存数据库不同的是,ReadySet 是和 MySQL / PostgreSQL 协议兼容的,所以对于应用来说,是完全透明的,所以也可以把 ReadySet 看作 MySQL / PostgreSQL 本身的一部分。有了 ReadySet,应用就不需要写额外的 Cache 处理逻辑,这可不得了,一下子解决了计算机科学两大难题之一的缓存失效(准确的说不完全是,但差不多能覆盖 95% 的场景)。

ReadySet 虽然是一个独立产品,但是从它的形态上归类为数据库的一个功能点更为合适。事实上 PlanetScale 就借鉴了 ReadySet 的思路,给自己的数据库加上了 PlanetScale Boost 的功能。

ReadySet 相关的资料很全,ReadSet 的代码开源在了 https://github.com/readysettech/readyset,如果技术人员想快速了解大致实现,推荐阅读 How PlanetScale Boost serves your SQL queries instantly (https://planetscale.com/blog/how-planetscale-boost-serves-your-sql-queries-instantly)。而对于非技术人员来说,通过 Jon 博士论文附录里图书馆的类比,也能知道个大概。
ReadySet 是近两年学术界到工业界眼前一亮的成果转化,估计接下来其他数据库都会相继引入这套技术方案。
四、年度数据库 - Neon

从产品侧来说,Neon 是 PostgreSQL 版的 PlanetScale,一样把引擎开源,一样主打 Serverless 和 Developer Workflow,但从技术侧来说,Neon 采用的是更加现代的架构,他的存储引擎在顶层设计上就考虑了 Branching 这样的功能点 (也被作为它产品的主要差异化点,专门放在了网站一级页面)。
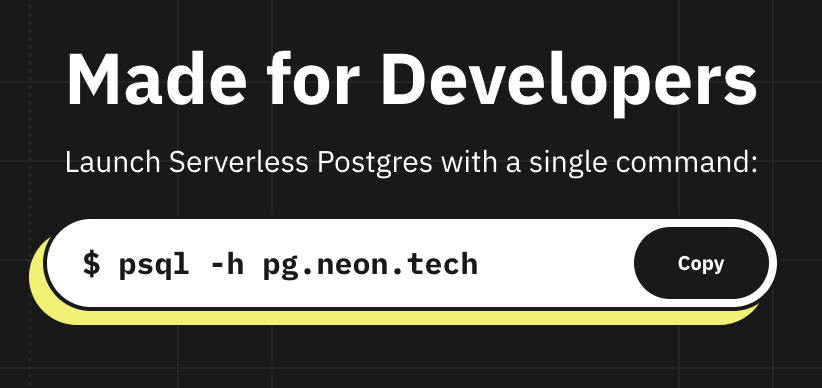
Neon 的另一个亮点是它的上手体验,是试下来最快能完成从创建到连接上数据库的整个流程:
像 PlanetScale 这样基于分布式中间件的数据库还会存在和原生 MySQL 兼容的问题,而 Neon 的存算分离架构则完全没有这个问题,Server 层直接用的就是 PostgreSQL 本身的 Server 层。Neon 的另外一个优势是它是基于 PostgreSQL 的,这使得它在企业场景的上限会高许多。另外 Neon 虽然目前针对的是 TP 场景,但它的架构结合 PostgreSQL 本身的扩展性,也有拓展到 AP,时序数据库这些的空间。
五、其他数据库盘点
Google Cloud 今年发布了同样基于 PostgreSQL 协议的 AlloyDB,整体架构是 AWS Aurora 的升级版。AlloyDB 采取了和 Aurora, Neon 类似的基于 WAL 的存算分离架构,不过 AlloyDB 在 TP 基础上先点了 AP 的技能树,而不是像 Neon 点了 Developer Workflow。AP 的场景确实更为广阔,但市面上 HTAP 数据库也有几个了,而且 AlloyDB 又是闭源的,所以在前面还是把年度数据库给了更具原创性和开放度的 Neon。
在 AlloyDB 推出之前,Google Cloud 拥有的 TP/AP 数据库产品线:
原生 (vanilla) OLTP MySQL, PostgreSQL, SQL Server - Cloud SQL。
云原生数仓 OLAP - BigQuery。
云原生分布式 OLTP 数据库 - Cloud Spanner。
而 AlloyDB 和这三者的能力都有交集,就像

确实是 Alloy (合金)嘛。

云原生数仓的王者也卷入 HTAP 赛道,之前的几家都是从 TP 切入 AP,Snowflake 应该是第一个从 AP 切入 TP 的数据库。Snowflake 做 HTAP 有几个优势:
渠道(Distribution)。
本身的产品力和整套平台。
AP 切 TP 更匹配大客户画像,愿意给 100 分 AP + 60 分 TP 买单的公司比 60 分 AP + 100 分 TP 的公司要多不少。
但从 AP 切同样也面临挑战:
公司总是先有 TP 系统,之后业务规模上去后再引入 AP 系统。一开始很难去说服研发团队 / DBA 用一个数仓出身的数据库来接管在线业务,何况 Snowflake 又卖的那么贵。
如果后续想再换 TP 系统也很难,TP 是 AP 的上游,通常都是上游强势。而且 TP 是在线系统,AP 是离线系统(排除极少量反向 ETL),换 TP 相当于给飞行中的飞机换引擎。而想推动 TP 更换 Unistore 的一定是大数据团队,但单纯站在 TP 团队的角度,缺少能够打动他们更换成 Unistore 的价值点。
所以对于研发组织来说,在畅想 Unistore 能带来的生产力提升前,先要评估是否有配套的生产关系保障。理想中,AP + TP 数据放在一起,组织间的数据更加通畅了。但现实中却很可能是:
TP 数据库团队不掰应 Unistore 这样 AP 出生的混血系统(就像 AP 团队不掰应 TP 出生的混血系统)。
AP 团队利用 Unistore 拓展 TP 场景,和 TP 团队开始打架,重复建设。

如果只是扫了一眼 Richard Hipp 博士的 2022 Recap(https://sqlite.org/forum/forumpost/df285a4182688791),可能会觉得是挺平常的一年。
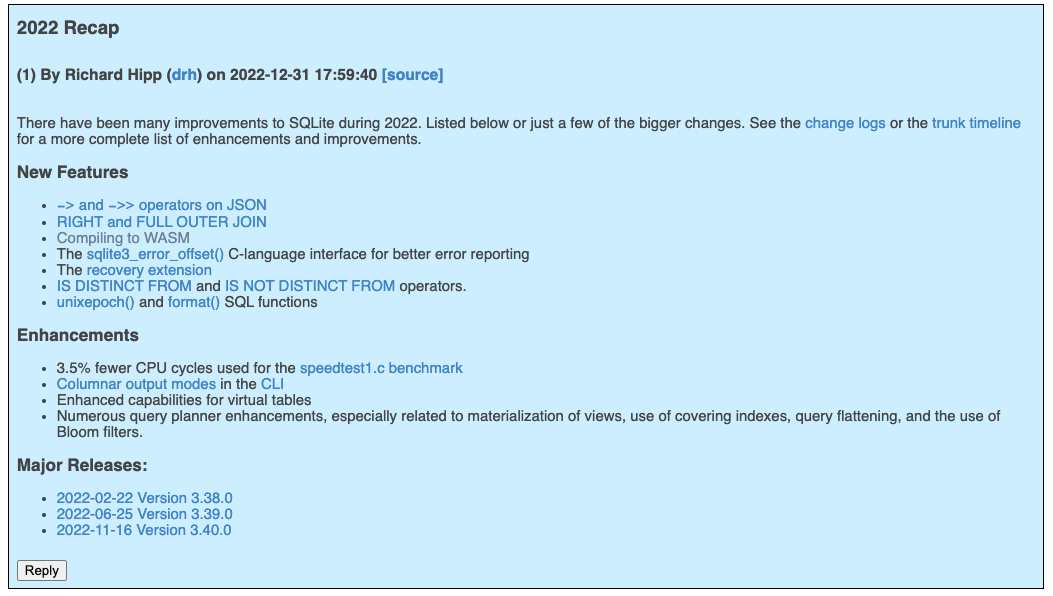
其实 22 年 SQLite 的生态又往前迈了一大步,社区中最大的演进是 SQLite WASM 成为了官方项目。

商业方面,Cloudflare 推出了基于 SQLite 的 D1,搭配它的 Cloudflare Worker。

Litestream 的作者 Ben Johnson 加入了 fly.io,随后又推出了开源的 LiteFS。

LiteFS 是一个专为 SQLite 构建的,基于 FUSE 的文件系统。有了 LiteFS,你只要花上 10 分钟,就可以搭好一个全球分布式 SQLite。
AP 版 SQLite - DuckDB 22 年同样发展迅速。
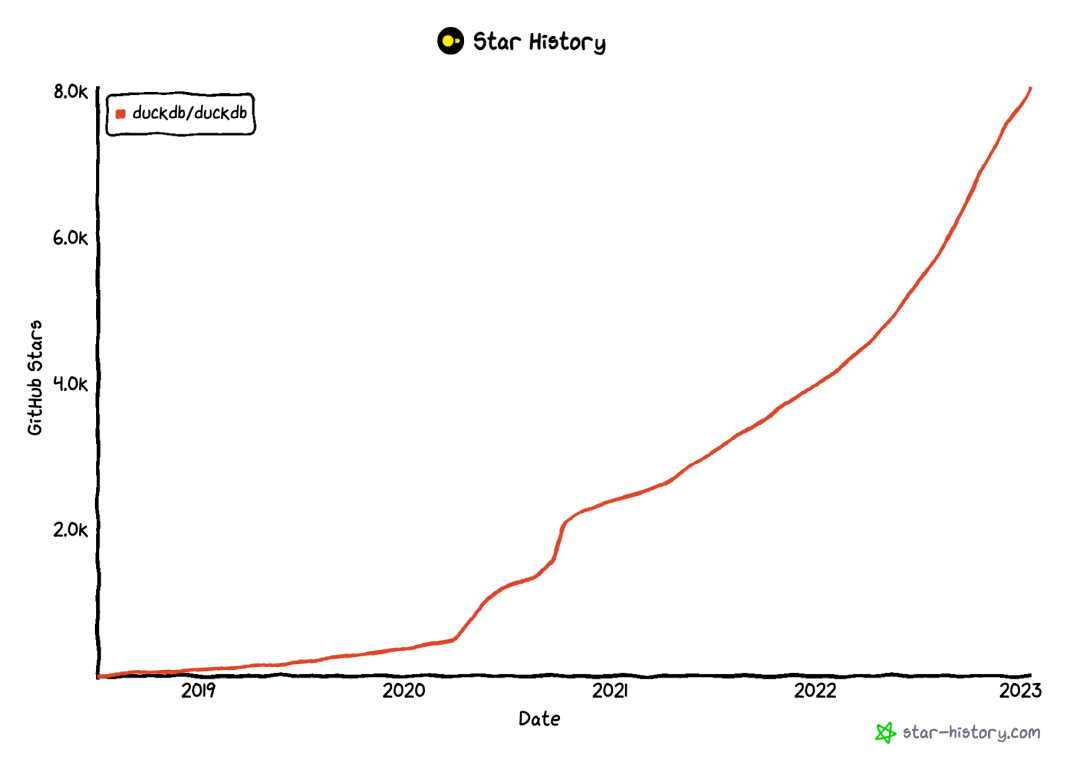
基于 DuckDB 的商业公司 MotherDuck 聚拢了一支全明星团队,在 22 年的大环境下,还能年底一上来就融了 4750 万美金。

来展望一下 SQLite 基础技术的演进路线:
SQLite + WASM,SQLite in your Browser (2022)
SQLite + WASM + LiteFS,Globally Distributed SQLite in your Browser(2023)
SQLite + WASM + LiteFS + DuckDB ,Globally Distributed HTAP in your Browser(2023/2024)
而在基础技术演进的过程中,行业也会去探索杀手级解决方案。在「MotherDuck,从 SQLite 走向数据届的 Docker」里展望过 MotherDuck 可以成为数据届的 Docker。更广义的讲,应该是以 SQLite 或者类似架构 (比如 DuckDB)为底座的方案能成为数据届的 Docker。Datasette (https://datasette.io/) 这个项目已经展现了这方面的可能性,只是还需要更好的产品化。
PostgreSQL 22 年虽然在 DB-Engines 年度排名里下降了一位,排在 Snowflake,BigQuery 之后,位居第三,但还是所有开源数据里表现最好的。而且在 Stack Overflow 的年度最喜爱数据库评选中,PostgreSQL 还拿下了第一。

另外从职业开发者的使用比例看,PostgreSQL 这次还略微超过了 MySQL。
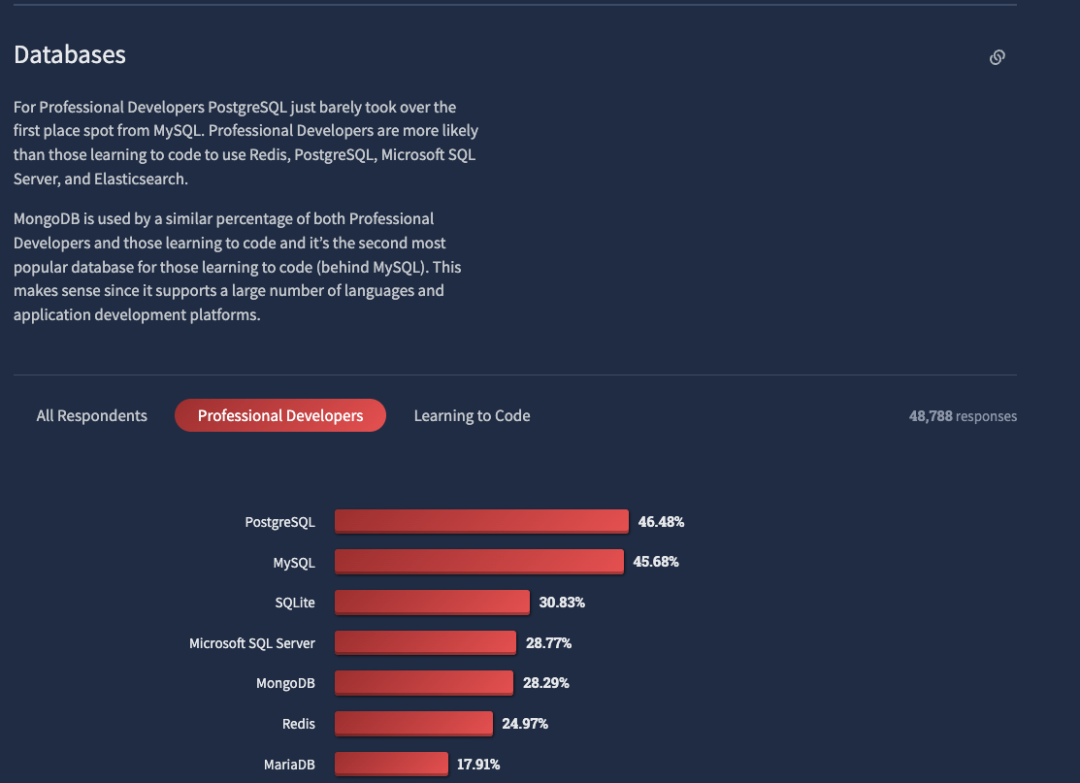
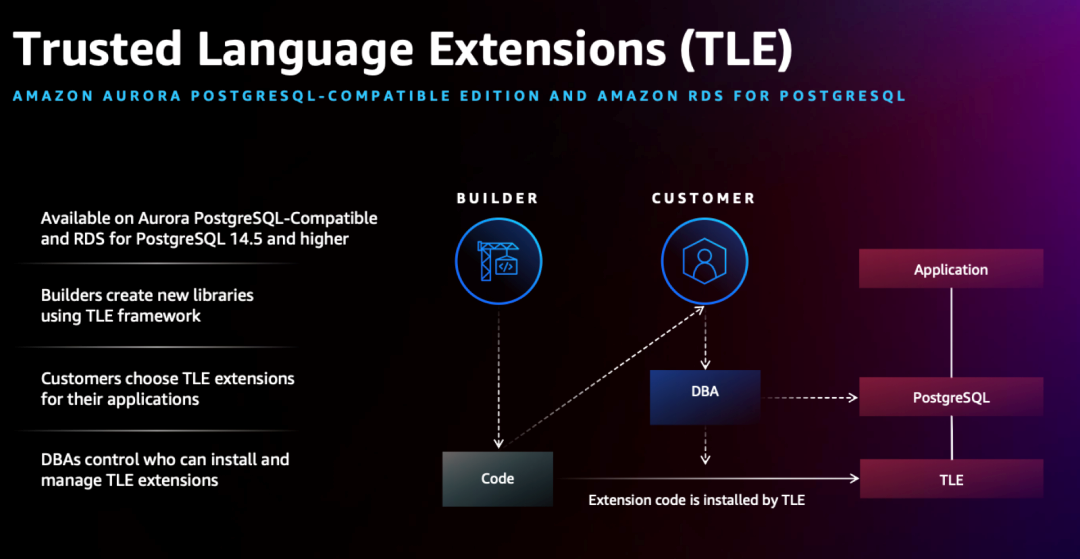
前面提到的新数据库 AlloyDB,Neon 都属于 PG 阵营的,就连 Snowflake 的语法也大多继承自 PG。另外像 Supabase,Render 这些提供 PostgreSQL 服务的 PaaS 平台也在继续蓬勃发展;AWS 在 re:Invent 上也推出了 针对 PG 的 Trusted Language Extensions (TLE)。
还是去年讲 PostgreSQL 的那条公式:
PostgreSQL = MySQL + 穷人版 (ClickHouse + MongoDB + Elasticsearch + InfluxDB) + Geospatial + Multi-tenancy
PostgreSQL 有出色的架构,严谨的代码,独立而专业的社区,时间是站在 PostgreSQL 的这边。就是希望 17 年提的 64 bit XID 可以早日合进主干。

六、数据库趋势
21 年 PlanetScale 从 Vitess 托管数据库转型到面向应用开发者主打 Developer Workflow,22 年继续做文章,相继推出了 Revert 以及类似 ReadySet 的 Boost。

当然今年 PlanetScale 迎来了一个知音/对手,同样主打 Developer Workflow 的 Neon。两者的宣言也很类似

最主要的区别一个是 MySQL 系,一个是 PostgreSQL 系。看来 MySQL 和 PostgreSQL 的相爱相杀是没完没了了,从原生 MySQL vs PostgreSQL,到分布式的 TiDB vs CockroachDB,再到云原生的 AWS Aurora vs GCP AlloyDB,现在又有主打开发者工作流的 PlanetScale vs Neon。
22 年 AWS re:Invent 2022 数据线最重磅的发布并不是数据库,而是 DataZone - A data management service to catalog, discover, share and govern data。

数据库引擎功能日趋强大,整个数据栈愈发复杂,就需要更好的方向盘,导航仪,刹车板这一套驾驶系统来驾驭他们。引擎厂商素有收购数据库客户端工具的传统,MongoDB 收购 Compass,Databricks 收购 Redash,还有 22 年 ClickHouse 收购 Arctype。但整体上还缺少像 Oracle Enterprise Manager, SQL Developer, SQL Server Management Studio 这样全面的工具。
所以相对于引擎市场的饱和,数据库工具赛道反而有更多的空间。公有云大厂要通过 DataZone 这样的服务打通整条数据产品线的任督二脉;数据库厂商要打造自己的数据库 IDE,提供一站式的数据库使用体验;而像 Bytebase 这样的产品,则是让团队能用一套统一的数据库开发流程,完成云上云下,不同的云,不同的数据库种类,各种各样的数据库开发活动。
融合的好处是减少异构系统因为数据同步带来的延迟,不一致,打破数据之间的孤岛。最理想的情况,最上游 TP 数据库一个变更, CI 的运行报告能反馈对于 BI 报表的影响,甚至能评估出 reverse-ETL 链路对于自己的影响,就像扔出一个回旋镖,转了一圈还能回到自己手上。
当前数据库技术正在融合,SQL 语言统一,执行引擎统一,基于日志的存储统一,这使得数据库引擎可以在一套大的框架下,去处理不同场景。之前提到的 PostgreSQL,通过插件的组装,已经可以基本承载各种业务场景。云上我们已经看到了 AP + TP 的 HTAP,AP + Lake 的湖仓一体,那这三者融合在一起的 ALT 还会遥远么?

2019 年前后,因为当时 Oracle 一直在推 Autonomous Database(自治数据库)的概念,于是在国庆期间阅读了相关领域的论文和产品资料,最后得出的结论是这东西还不成熟,建议团队应该投入更多在 HTAP 上(不过最后资源还是倾斜到了自治数据库,毕竟 AI 能讲出一个更好的故事








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721