
本文根据商永星老师在〖deeplus直播:大规模数据库运维的化繁为简之术〗线上分享演讲内容整理而成。(文末有回放的方式,不要错过)
作者介绍
商永星,vivo互联网高级数据库研发工程师。
1.背景
近年来,有关数据泄露相关的新闻事件屡见不鲜,不断地引发大众的讨论和担忧。各家企业都或多或少在承受相关的数据安全风险,这种可能性会给企业运行带来额外的风险,包括大众的质疑以及政府的处罚等。
Facebook超5亿用户个人数据遭到泄露;
Elector Software投票应用泄露超650万以色列选民个人数据;
T-Mobile数据失窃,超过1亿用户的个人信息被泄露售卖;
亚马逊因违反GDPR被重罚7.46亿欧元……
从现有的事件统计来看, 数据库未得到正确配置和黑客攻击相对来说是比较主要的诱因;在这种严峻的个人信息保护形势背景下,各国都在强化健全相关的法律合规机制。
1.2.1 现行法律与合规
国内:个人信息保护法、数据安全法、网络安全法
海外:GDPR(EU,一般数据保护条例), PDPB(India,个人数据保护法),DBNL(US,数据泄漏通知法)
1.2.2 工业和信息化部关于互联网行业市场秩序专项整治行动
2021年7月工信部组织的专项整治行动中,威胁数据安全的问题,主要体现在:
用户数据收集
用户数据传输
用户数据存储
未按法律法规要求建立数据安全管理制度和采取必要的安全技术措施,将会遭到包括曝光、约谈、下架、停止网络接入、行政处罚等在内的处罚。
对于工信部的整改要求,我们梳理了目前的现状以及可能遭遇的风险:
整改时间紧张
时间方面紧张,留给内部处置的时间只有两个半月,而整改本身涉及范围和难度都很大;
涉及项目模块广
包括互联网团队的所有部门,相关应用模块超过300个;
规定本身可能变化、更新
整改的规定或者说要求可能会随实际情况发生变化、更新,需要及时对变化的要求进行转化、同步。
问题实际上就是聚焦在这几个部分,什么是敏感数据,怎么发现它并进行脱敏,以及整体需要怎么去适配。基于这些难点,我们的最终目标就是借此次整治机会,建立一个长期有效的数据安全管理制度和体系。
2.敏感数据字段发现
2.1 定义
首先需要定义或者说确定哪些数据可以认为是敏感数据:
用户的个人信息,在近几年发生的数据泄漏事件中,大众也更关注此类信息的受侵害程度;
对厂商而言,设备以及设备的相关数据,如操作记录,imei等唯一标识也存在敏感风险。
而且,从上述数据衍生而出的,例如:
内容平台发表或存储的数据;
用户行为和特征衍生而出的用户画像;
财务账务数据。

这些都属于会显著引起大众关注的场景。
2.2 数据分级规范
针对这种复杂的敏感数据态势,vivo针对《个人信息保护法》,《数据安全法》中赋予企业的合规责任和义务制定了具体的分级规范;简而言之,就是会按照影响的强度和范围对数据字段进行划分,这个定级是具体到字段级别:
对企业运行的影响;
对用户个人隐私、权益的影响。
其中可能引发负面影响和侵害用户权益、隐私的风险等级以上的数据都需要进行不同程度的脱敏。
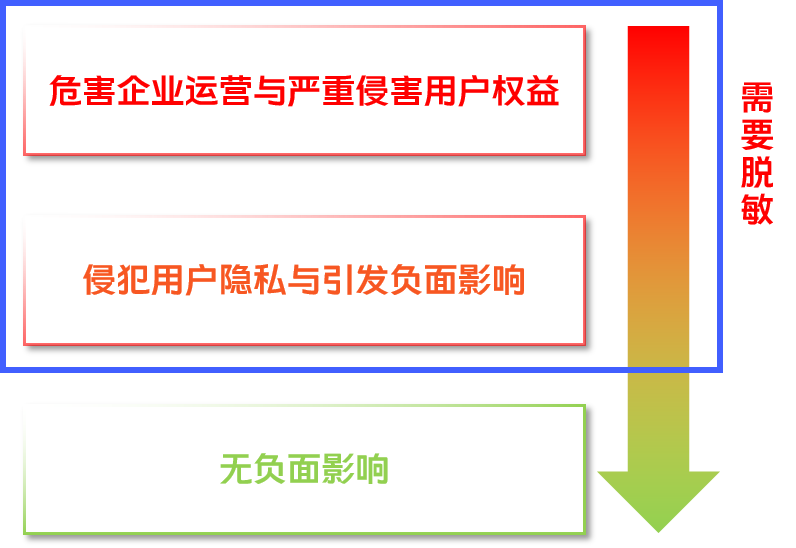
我们希望通过对不同的安全级别采用不同的操作策略,来确保数据安全风险可控。
2.3 现状与改进措施
在具备标准的规范级别后,我们需要对现存的和新增的数据进行定级分类,但当前存在以下问题:
对新的字段没有明确级别,往往需要使用后才进行定级分类;
数据字段识别引擎待优化,主要支持用户类型的识别,对非用户数据支持较差;
存量数据依赖人工判定,工作量大;
缺少衡量评价指标,质量不可控。
针对这些现状问题,在各个环节进行了优化改进,形成了完整的敏感数据字段自动发现的方案:

2.4 系统自动定级与订正
通过敏感数据识别引擎,对结构化数据进行整体扫描,自动识别出敏感数据,支撑其进行数据分类分级及数据治理,以便根据结果对敏感数据做进一步的安全防护和后续的精细化管理。
具体的环节中,我们通过系统定期扫描业务集群的库、表、集合、字段,对其中的字段进行分类分级,并根据已有的数据进行打分(准确率),再通过人工订正纠偏对评分系统进行反馈调整,达成一个长期的正向提升循环。
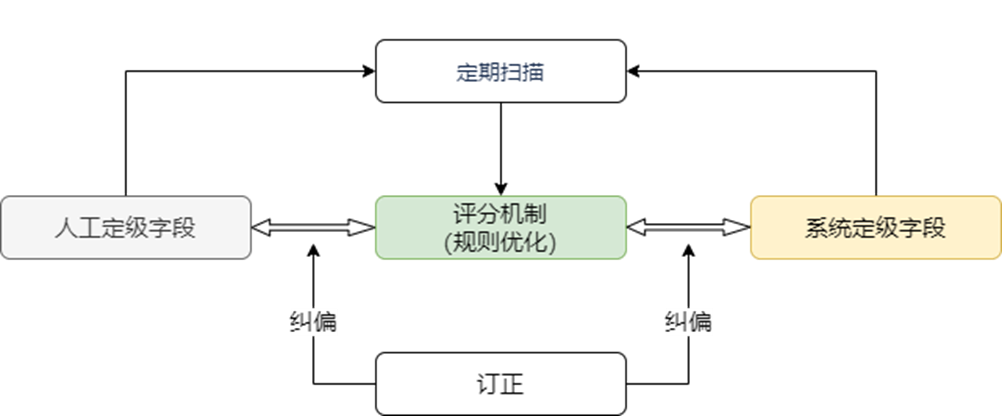
我们定义了两个指标用来支持评分机制的改进:
覆盖率:有分类分级的数据量/全部数据量;
准确率:用户数据分类分级正确的量*0.1/(抽检用户数据量*0.1+抽检非用户类别中用户类别的数据量*0.9)。
计算公式中的1:9关系,是由我们现存数据分类中用户数据和非用户数据占比核算得到,实际上是用于均衡计算实际的用户分类分级准确率,而这样设计的初衷,即尽可能减少误判用户数据为非用户数据的情况。
2.5 小结
最终,基于当前的能力现状,我们实现了:
对MySQL/TIDB/ElasticSearch/MongoDB在内的四种数据库的敏感字段识别;
支持全自动的实时敏感数据字段识别,包括对业务新建表、集合的扫描;
支持总共超过100类用户或非用户数据的分级分类,最终实践的定级准确率不低于85%;
基于这样建成的能力,我们可以达成敏感数据分类分级,以及即席查询这类场景下对敏感数据的保护能力。
那么,在我们解决了如何发现敏感字段的问题后,就需要对这些敏感数据进行处置,这也是本次专项治理的核心环节。
3.数据加解密
3.1 方案选型
针对具体的处置环节,需要考虑的要求相对就更多了,而且在不同的层面上,相关方关注的要点可能也不太一致,需要在这些要点间进行取舍。
对开发和运维而言,是希望接入简单,一次整改解决所有问题,基本保持现状一致,同时兼具稳定,有可用性保障,能支持更多类型数据库形成统一方案等。
对安全而言,是关注符合合规要求,规避可能的风险。
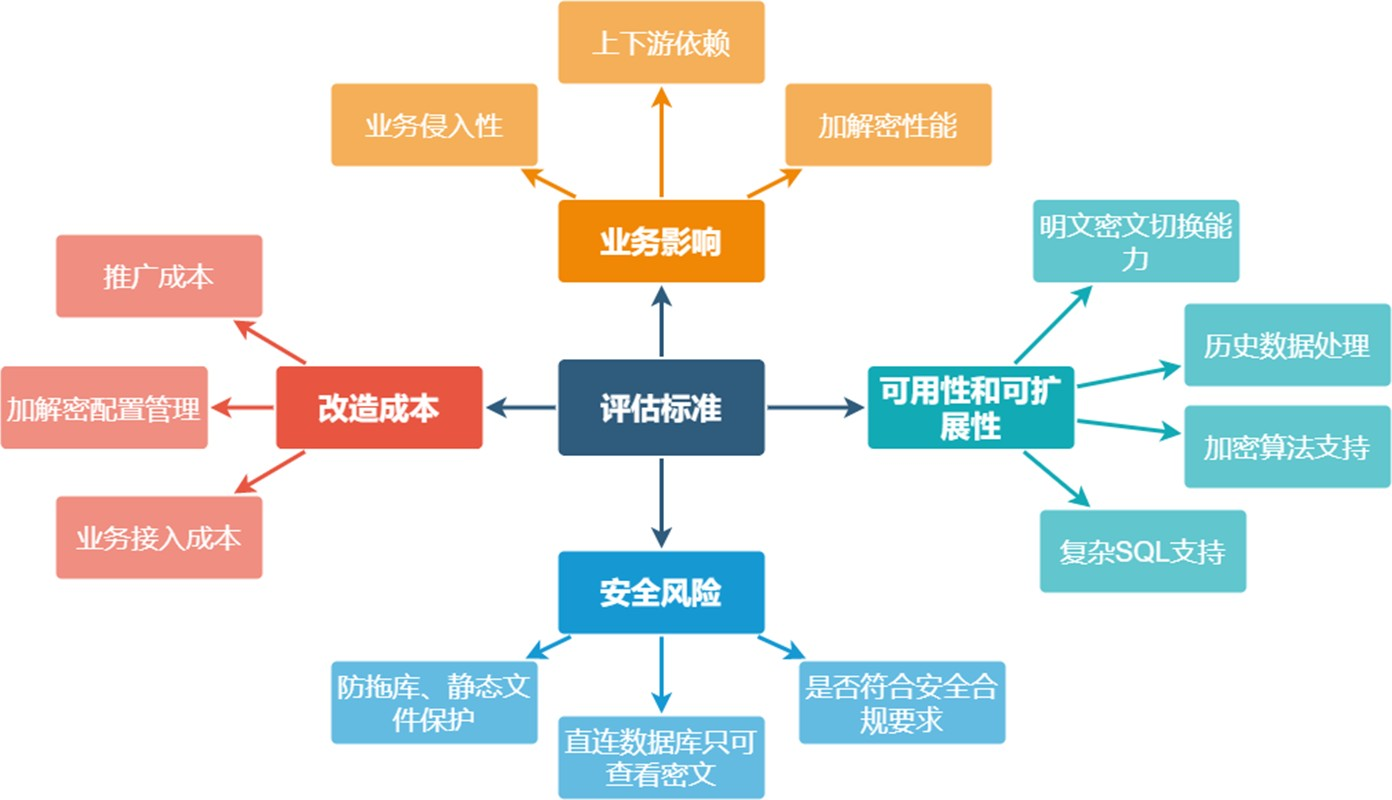
这里主要介绍MySQL方面的工作,我们内部的团队分别从多个方向入手,提供了对应的解决方案:
基于MyBatis插件的实现形式,业务可以使用定制的加解密方法在应用内部自行实现加解密;
基于shardingsphere实现的应用层加解密,业务通过改变接入层使用特殊的配置数据源;
基于使用的MySQL架构中存在的代理来实现通用的数据加解密,对应用层完全透明,同时限定访问解密数据的权限必须要通过代理。
3.2 方案对比
|
要求 |
SDK加解密(定制MyBatis插件) |
ShardingSphere中间件(vivo-JDBC) |
数据库透明加解密(Proxy) |
|
接入成本 |
高,需修改应用程序 |
高,需修改应用程序 |
低,无需修改代码,只需配置脱敏规则 |
|
维护成本 |
业务自维护代码 |
中间件团队维护 |
数据库团队维护 |
|
推广成本 |
高,只支持java语言 |
高,只支持java语言 |
低,属于MySQL架构一部分 |
|
高可用 |
应用服务本身决定 |
应用服务本身决定 |
MySQL高可用托管 |
|
客户端软件解密 |
不支持 |
不支持 |
支持 |
|
下游使用 |
不支持 |
不支持 |
支持,需接入Proxy |
从一些常规的角度,通过调研实际实现和业务反馈,我们对比了三种方案的成效,从成本以及上下游兼容性来看,Proxy具有相当的优势,综合起来我们内部是推荐使用使用Proxy做加解密,当然另外的方案也是具有可行性的,他们本质上都是同一种加解密算法的实现,可以在各个方案间无缝切换。
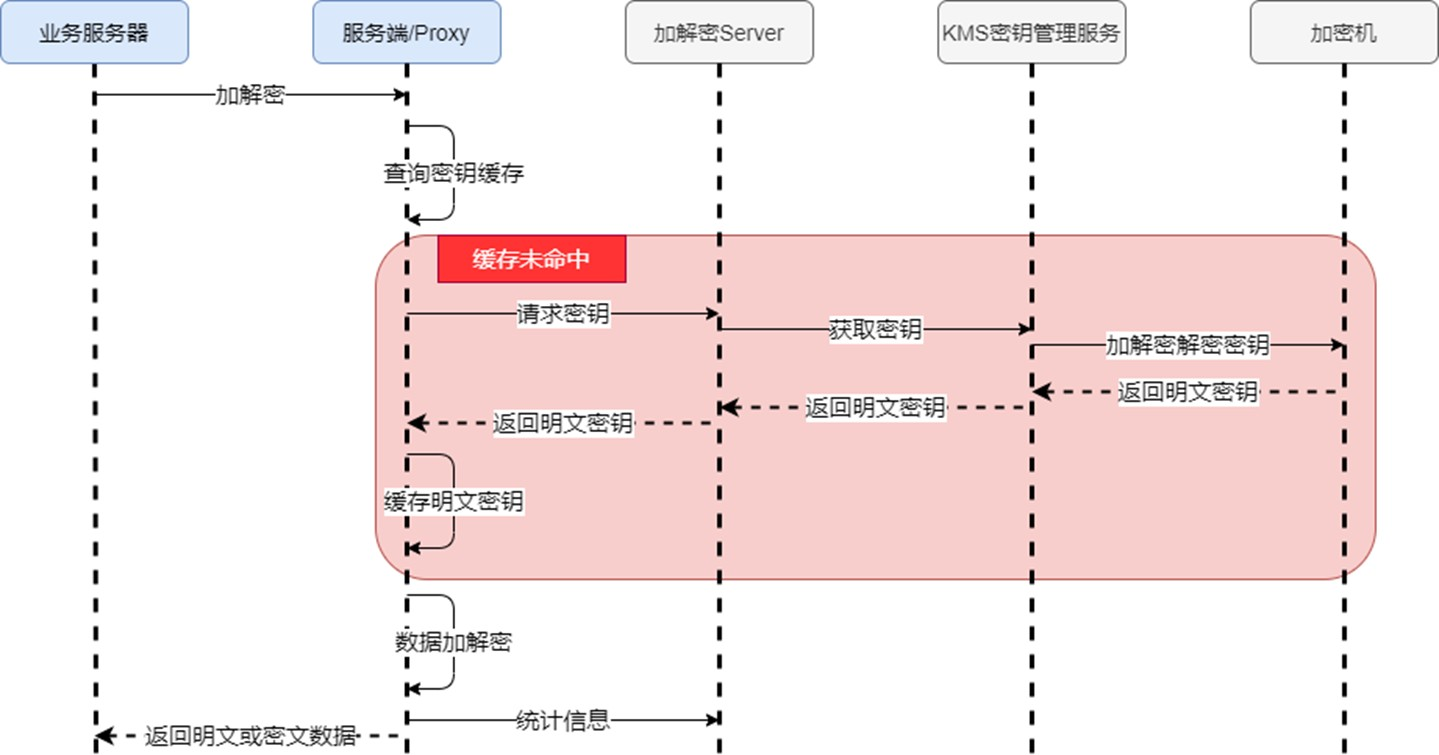
总的来说,这几种方案中,加解密发生的链路都位于发起服务端和数据库层之间;为了提高效率,中间执行具体转发请求的服务端或代理Proxy都会缓存对应的密文秘钥,所有的密文秘钥都托管于KMS服务平台,在无法查到或启动时进行请求,原则上不能中途修改密钥,这会导致历史数据被破坏。
3.3 Proxy加解密
3.3.1 原理
实现加解密的核心是在数据传输的过程中进行拦截,对SQL和结果集进行对应的改写;而这一操作是基于预设的脱敏规则:
逻辑字段:用户认识中的字段名称
明文字段:存储原始数据的字段
密文字段:存储加密密文数据的字段
设计上,明文字段和密文字段会在一定时间内共存,用来支持任意的明文密文切换,确保线上运行时的稳定和可回滚能力;
业务查询或写入是依赖逻辑字段,对应的规则会在传输中进行改写,包括将明文/密文字段改写为逻辑字段以及反向操作,分别对应读取包和写sql的两个阶段;
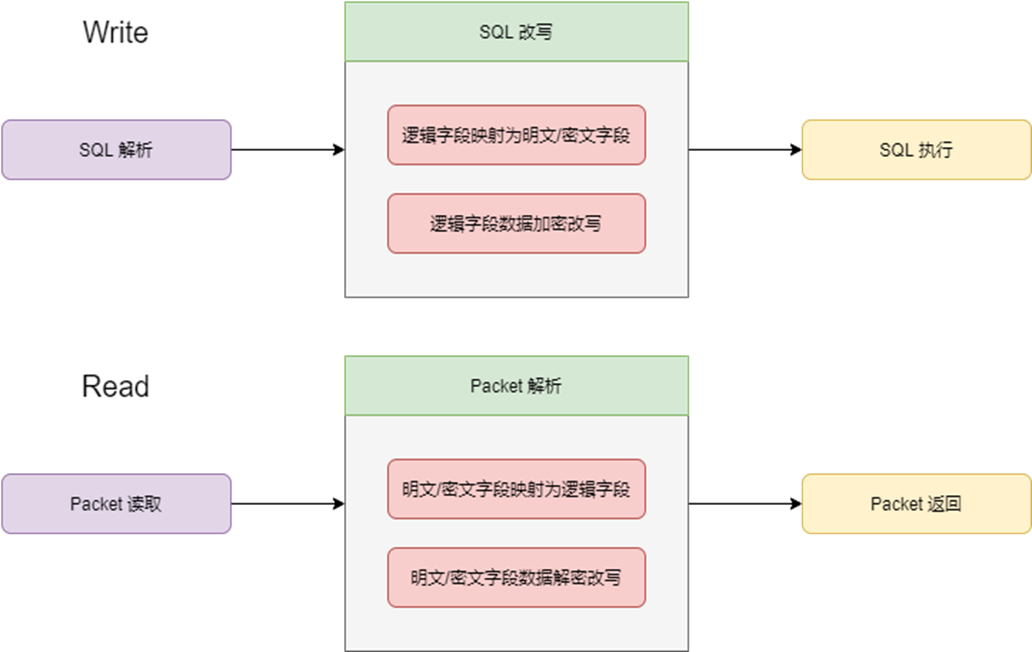
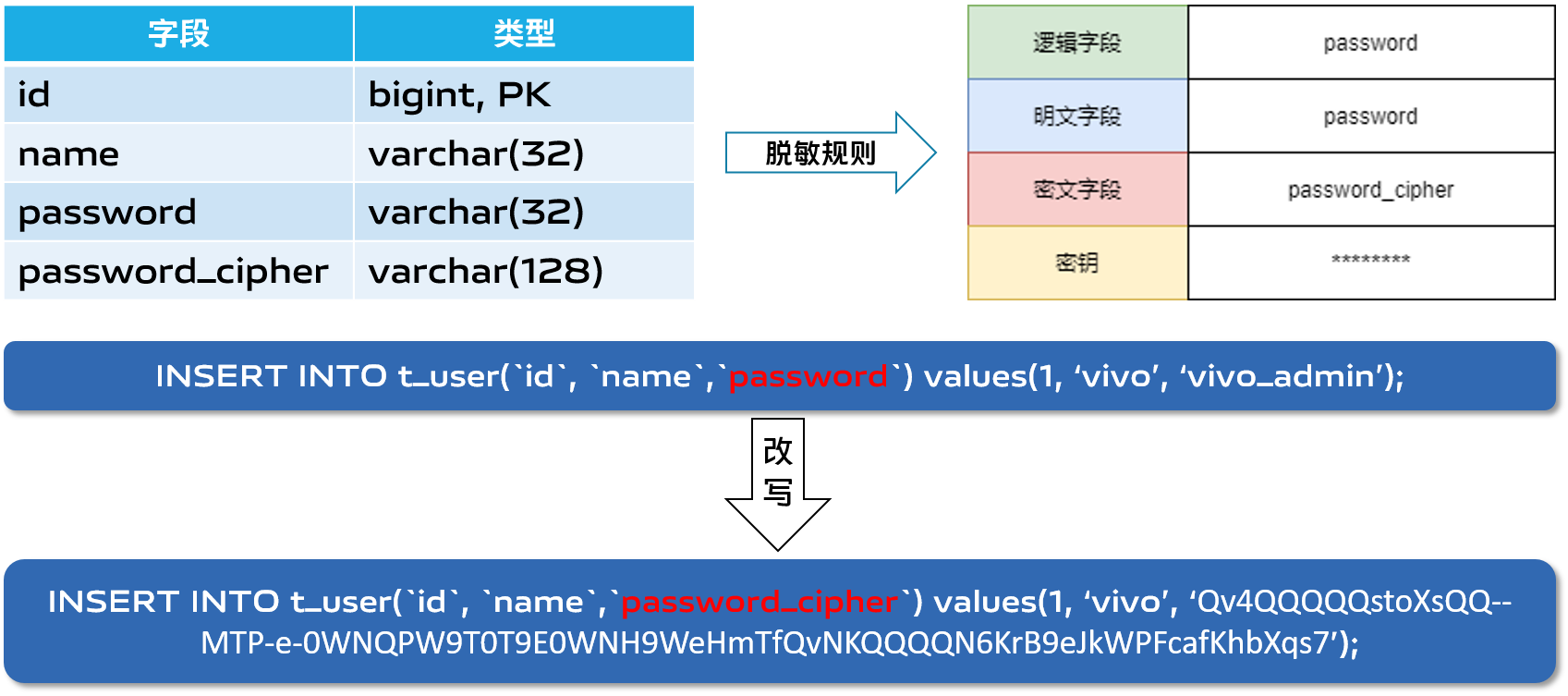
这里展示一个比较常规的数据写入模型,包含明文字段和密文字段password和password_cipher。脱敏规则中包含一个password和password_cipher字段, 那么Proxy在读取SQL时,就会将对应的字段和数据列进行改写,包含名称重新映射和数据加密处理改写。
3.3.2 优势与不足
Proxy本身是基于MySQL协议实现的代理层,相对于直接使用SDK或shardingsphere这样的偏向语言的方案,具有以下的优势:
它是MySQL架构中的一部分,这样可以使得加解密操作限定在“数据库架构”的范围内,对外部系统透明;
兼容所有使用MySQL协议的数据库,更容易应用在相关的场景中,没有接入阻碍;
支持各种语言,不存在限制。
但它本质上还是依赖加密列的实现,因为对原始语义的破坏和算法的局限,无法支持比较和计算操作。
总的来说,我们基于Proxy实现了通用的加解密方案,可以完成对敏感数据的处置,基于目前可行的发现和处置措施,就可以对目前的敏感数据进行整治。
3.4 存量数据处理
我们可以把现行的业务数据分为两大类:
归档或备份类型的冷数据,这类直接进行整个文件的加密,存储到oss系统即可符合要求;
在线数据,即业务会进行读写的数据,这类需要控制对业务的影响。
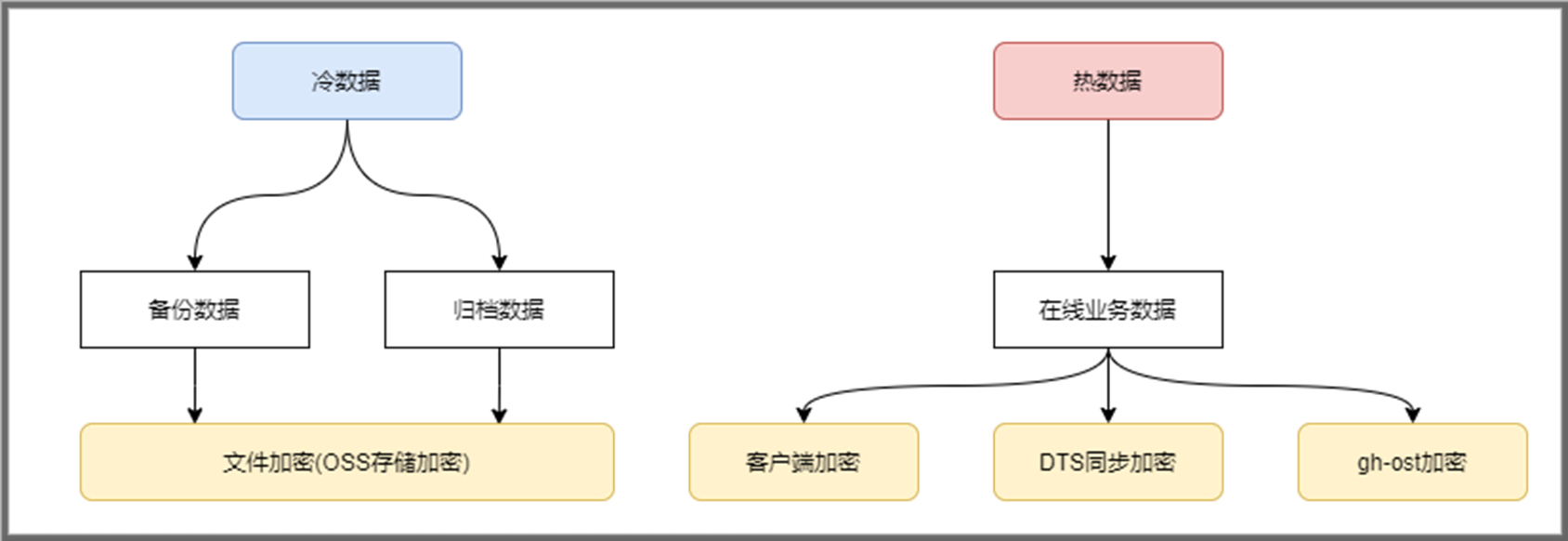
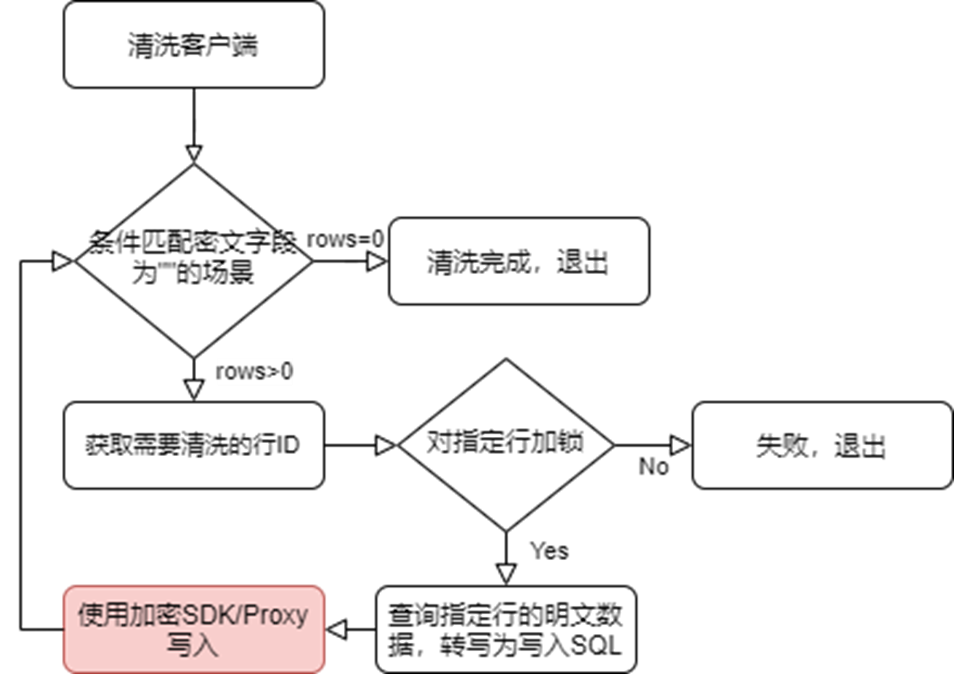
3.4.1 客户端加密存量数据
这个模式是典型的源写入加密,在新增密文字段后,可以反复地在表中使用条件匹配查找未写入密文的行,对找到的行加锁后可以查询对应行明文字段的数据,改写成一条写入的sql向具备加解密能力的SDK或Proxy执行,这样可以通过循环操作将缺失的密文数据进行补全;
这种方式,可以由业务自己执行,相对来说风险可控,虽然会明显地产生锁开销和额外的写入压力;
读取配置并获取需要清洗的数据表字段
查询加密列为NULL的行的主键值,比如(SELECT article,dealer FROM `test`.`shop` FORCE INDEX(`PRIMARY`) WHERE `article_cipher` IS NULL OR `dealer_cipher` IS NULL OR `price_cipher` IS NULL ORDER BY article,dealer ASC LIMIT 10;)
通过获取到的主键值,查询加密列的明文值,并对查询行加锁,比如:(SELECT article,dealer,price FROM `test`.`shop` FORCE INDEX (`PRIMARY`) WHERE `article` = 1 AND `dealer` = 'A' LIMIT 1 FOR UPDATE;)
获取到明文数据后,通过Proxy更新明文列,达到清洗数据目的,比如:(UPDATE `test`.`shop` SET `article` = 1,`dealer` = 'A',`price` = 3.530000 WHERE `article` = 1 AND `dealer` = 'A';)
提交清洗事务,循环执行2,3,4过程达到清洗全表数据,当步骤2查询返回空时结束
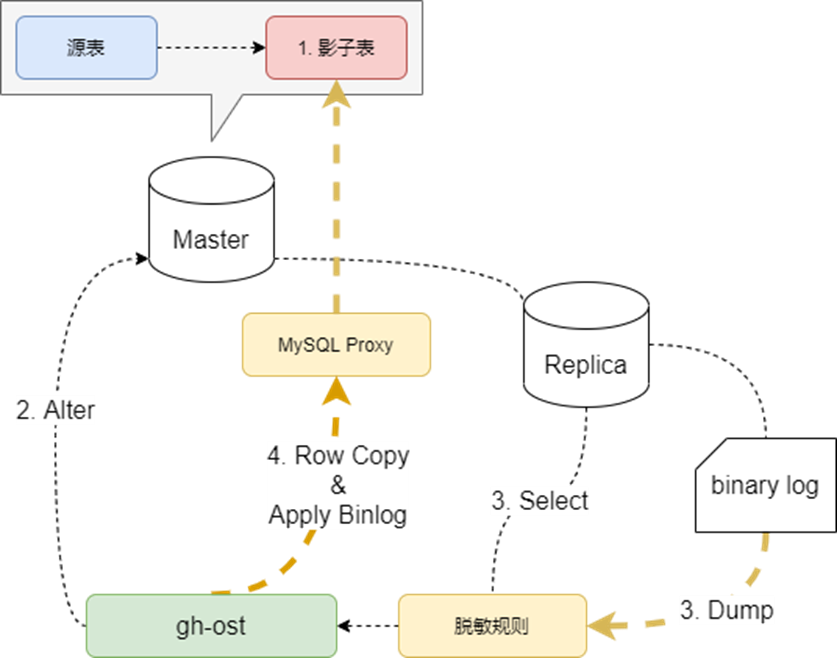
3.4.2 gh-ost工具加密(在线DDL变更工具+数据加密算法)
我们对MySQL表的在线变更是依赖gh-ost工具来实现的,它的机制上就是在原集群上创建一个影子表,通过select和Binlog row 复制,将原表的数据灌入到影子表中,最后通过一次锁切换,实现访问目标变更。
那么这个环节实际上可以和我们的对敏感数据治理的工作结合起来,因为实现上会要求建立密文字段(或者不建立亦可),所以可以将加密历史数据的环节直接放在新增密文字段操作发生时。
4.数据链路的上下游适配
4.1 业务接入改造
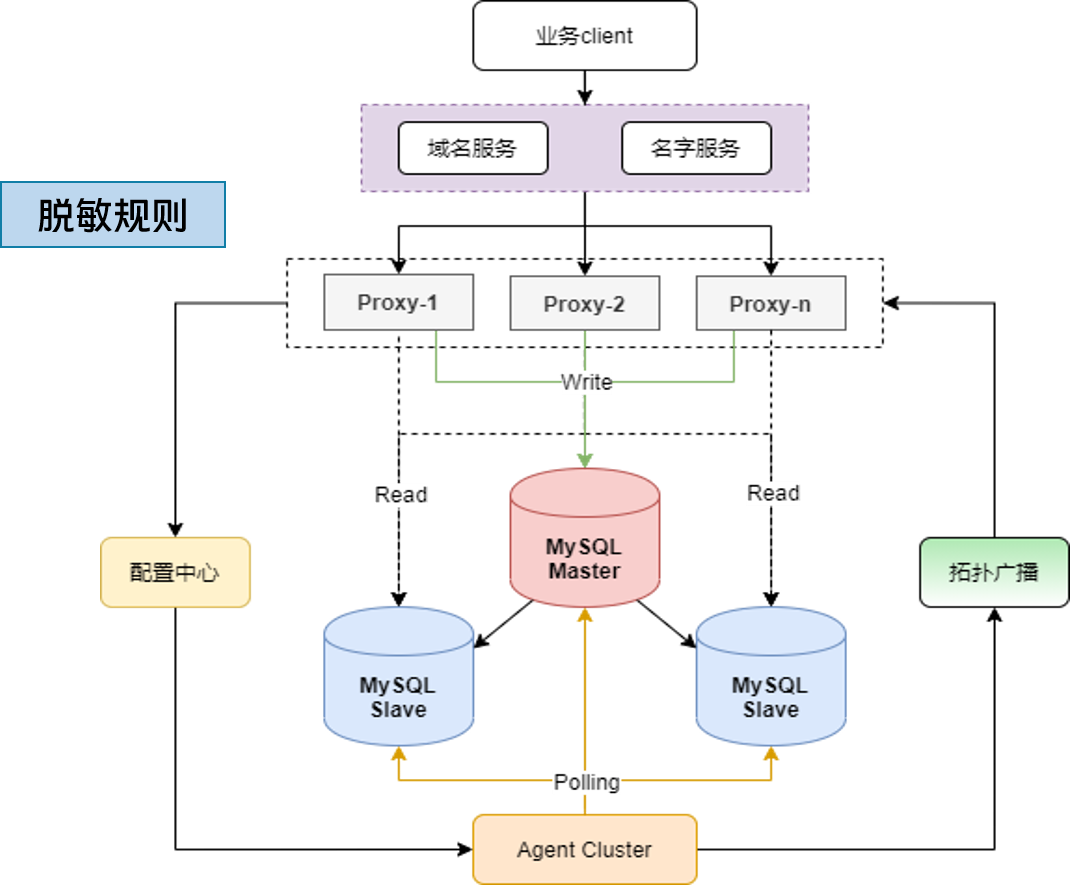
对于存在敏感数据治理的数据库的上游,显而易见就是涉及敏感数据的业务系统,我们做的一切工作就是为了帮助解决原本没有脱敏或不符合规范的数据落地;
那么对于常规业务接入,我们通过利用已经集成在MySQL架构内的代理,只需要在使用层增加 脱敏规则,就可以无缝将传输的流量进行加解密
计算层无损变更
确定并配置脱敏规则
开启用户级别的开关
自动透明加解密实现
4.2 实时采集
在实时采集任务原本的逻辑中,会从源取得实时数据变化对应的Binlog,解析成相对于的下游格式,放到es/Kafka或其它下游中。
因为加密使得数据库中实际存储密文,那么Binlog内的数据也会是密文数据,这一过程中就需要在采集层实现类似Proxy的解密能力,通过获取脱敏规则来改写密文字段的行数据,再向下游执行。

5.总结与展望
5.1 总结
从发现、处理敏感数据以及适配敏感数据治理的解决方案:

5.2 展望
5.2.1挑战
通用的脱敏方案仅针对支持MySQL协议的数据库;
无法支持列的计算和比较操作,SQL兼容性受限;
目前主要聚焦在存储层进行加密。
5.2.2优化规划
针对这些,主要在两方面规划:
提升SQL的兼容性,适配复杂的查询或写入场景;
强化目前局限于数据存储层的加密方案,扩展多源数据场景的治理方案,完成整个生态的统一加解密方案。
获取本期PPT,请添加群秘微信号:dbachen
↓点这里可回看本期直播
http://z-mz.cn/5RSl3








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721