
本文根据林锋英老师在〖deeplus直播:大规模数据库运维的化繁为简之术〗线上分享演讲内容整理而成。(文末有回放的方式,不要错过)
作者介绍
林锋英,vivo互联网高级数据库研发工程师。
1.背景
近几年 vivo 数据库运维规模快速增长,从数量上看增长了几倍,达到了万级别的规模,与此同时 DBA 每日需要处理200多条告警。
随着运维规模越大,线上故障也就越多,DBA 对于每个故障的处理时效将会下降,如果没有强有力的工具能提高故障的排查和修复效率,那么线上的稳定性就得不到保障。因此我们的想法是,我们固然要不断提供更加丰富的工具,但无论工具再丰富,都需要人去主动使用,因此更重要的是改变以人为主、工具为辅的运维模式,引入自动化分析和自愈的手段来提升运维效率。
2.实现思路
目标确定后,接下来需要确定目标的实现思路。我们调研了业界的一些解决方案后,发现能力的发展可以总结为以下三个阶段:
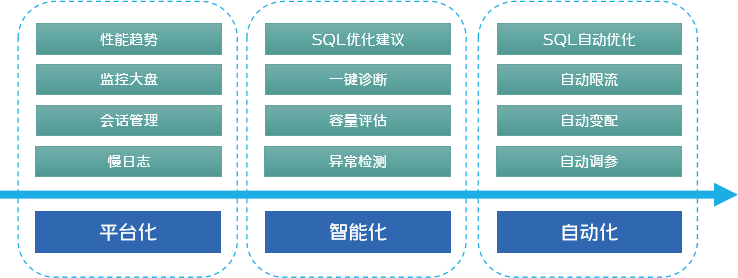
平台化:能够提供一些数据和统计信息,运维人员再基于这些信息来进行运维;
智能化:已经能够提供分析和建议,但是否采纳需要运维人员自行判断;
自动化:已经有部分场景可以实现自动恢复,无需人工参与了。
通常平台的发展过程如上所述,但是也需要结合我们自身的情况来决定,因为我们投入的人力较少,不是成团队地投入这个工作,因此不太可能遵循这么一个发展策略。因此基于人力投入的情况,我们定下的目标是,短期内我们要做投入产出比最高的工作,以求达到立竿见影的效果,但长期来看,图中成体系的基础能力还是需要建设起来。
为了短期达到立竿见影的效果,就需要寻找一个切入点。如果我们观察一个故障的生命周期的话,可以看到故障的生命周期分为故障前、故障中和故障后:
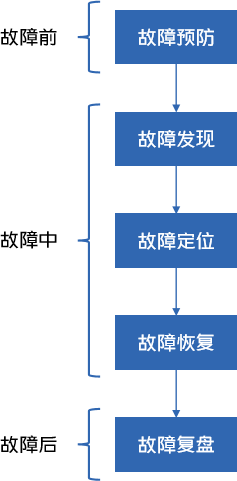
“故障前”包括故障预防 ;
“故障中”包括故障发现、故障定位和故障恢复;
“故障后”包括故障复盘。
那么从整个故障的生命周期来看的话,按照我们的经验,DBA 大部分时间都是消耗在故障定位和故障恢复上的,而因为每类故障具有相似的定位路径,所以比较容易去定义定位规则、沉淀专家经验。因此我们的想法是将重点放在故障定位和故障恢复这两个阶段上,去提高 DBA 的运维效率,优先找一些投入产出比高的场景去实现故障自愈。
结合前面提到的短期目标和长期目标,我们确定下来这么一个发展思路。
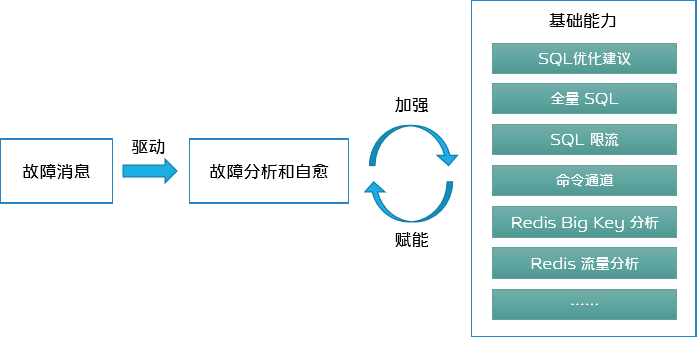
首先我们会重点去实现各类故障场景的自动分析和自愈,这些自动分析和自愈行为是由故障消息驱动的,这也是一个比较直观的方式,因为 DBA 通常也是收到故障消息后,才去进行故障定位等操作。然后当过程中需要某类基础能力时,就去重点发展该能力。
这样我们的短期目标和长期目标就都能兼顾到。
在实现方案前,需要先思考一个问题,即我们如何在实现过程中保证数据库的可用性?
之所以把数据库可用性单独提出来,是因为故障自愈是自动触发、自动执行的,而且过程中通常需要去触达数据库,比如查询数据库的状态或执行操作,那么这种自动的操作本身会带来比较大风险,因此更加需要考虑实现过程中,如何避免对数据库造成的可用性影响。那么如何避免可用性影响呢?我们的答案是将每个故障自愈方案上线的流程标准化。
3.具体实现
下图是我们以可用性为第一考量的前提下,确定下来的故障自愈方案上线流程。
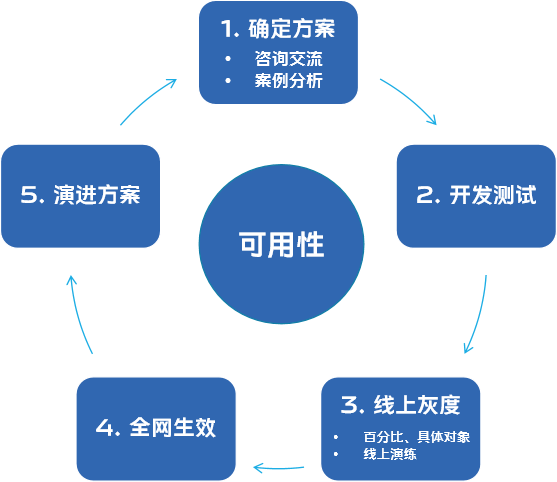
①确定方案:当有一个新的故障自愈场景需要实现时,首先需要把自愈方案确定下来,即确定在这个故障场景中,需要“做什么、怎么去做”。这里有两种确定方案的方式,可以和 DBA 进行咨询交流确定方案,也可以通过分析线上案例来确定方案
②开发测试:方案确定后进行程序的开发测试,此处不必赘述
③线上灰度:开发测试完成后,需进行线上灰度,这里我们支持针对具体对象进行灰度,比如某个集群经常发生该类故障,那么可以指定灰度该集 群。如果没有具体对象,也可以设置百分比随机灰度。当然如果某些故障场景发生的频率很低,我们一开始也会进行线上演练,通过在线上模拟故障的方式来进行验证
④全网生效:灰度完成后,开放全网生效
⑤演进方案:每个故障自愈方案不是上线后就是最终形态,还需要我们结合用户反馈以及后续案例来不断进行迭代优化
上述流程的五个步骤中,“确定方案”和“演进方案”是重点,因此下文展开介绍。
3.1.1 确定方案
在实践中,我们通过和 DBA 咨询交流以及分析线上案例的方式来确定故障自愈的方案。
咨询交流
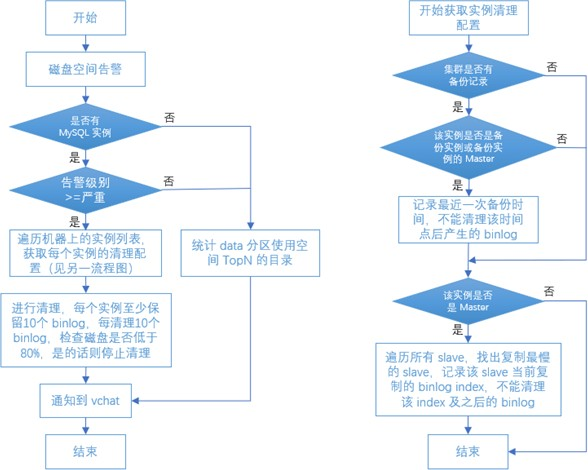
这里介绍下发生磁盘告警时自动清理 MySQL Binlog 的方案,通过和 DBA 咨询交流的方式,我们确定了该方案。具体方案流程如下图所示,其实整个方案就重点关注了两个问题:
第一个问题,如何确定哪些 Binlog 是不可以清理的?答案是未备份的 Binlog 不能清理,因为会影响增量备份;备库未同步的 Binlog 也不能清理,因为会影响复制同步。
第二个问题,如何保证删除过程中的系统可用性?这里我们采用分批删除、每次删除睡眠一秒的方式来平滑删除带来的 IO 压力。
案例分析
有时不是所有方案都能够通过咨询交流的方式确定下来,对于根因分析的场景,因为每个运维人员的运维经历有所差别,如果要把所有可能的情况枚举出 来,那么会导致方案十分冗长,因此一种更好的方法是通过分析线上真实案例来确定方案,这样产出的方案是最贴合线上情况的,后续也可以不断结合案例做迭代优化。
这里介绍下我们如何确定 SQL 类告警根因 SQL 分析方案。为了确定这个方案,我们分析了50个线上案例:首先找出哪些案例是能明显看出有根因 SQL 的, 再对有根因 SQL 的类别进行细化,最后得到根因 SQL 的判断步骤。

3.1.2 演进方案
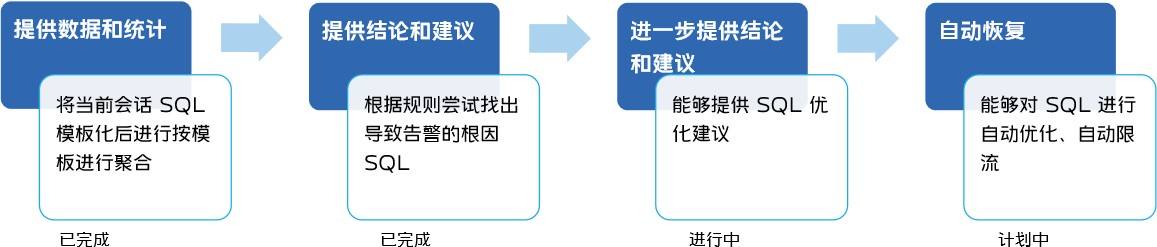
针对某个故障场景的方案通常不是一步到位、直接拥有自动恢复故障的能力的,而是在实践中不断演进。我们把方案演进的过程分为下图三个阶段:

那么为什么要分阶段去演进方案呢?
从效率的角度看,能够先快速上线比较简单的方案,可以快速地提高运维效率;
从可用性的角度看,前一阶段是后一阶段的基础,只有前一阶段验证成熟了,再去不断演进是比较安全的做法。
以 SQL 故障场景为例来演示方案的演进过程。我们的 SQL 故障场景方案一开始只是提供数据和统计,然后进一步地通过案例分析的方式,使其可以根据规则尝试找出导致告警的根因 SQL,目前正在实现对根因 SQL 的自动优化建议,最终目标是可以具备对问题 SQL 自动优化、自动限流的能力。
基于上述的思路,我们实现了一个故障消息驱动、基于规则的故障自愈流程。

首先我们监听了故障消息,当自愈系统接收到故障消息时,会根据这个消息类型去规则库中查找对应的自愈流程,再通过流程编排引擎运行起来。流程中会去调用相关基础能力,最后生成一个处理结果通知,发送到我们的工作沟通软件。同时也会将这次流程的运行信息保存到分析中心,用户后续可以在分析中心看到详细的现场快照、分析结果,还能对这次分析进行评价标注。
下面对流程中的重点组件进行介绍。
3.2.1 故障消息
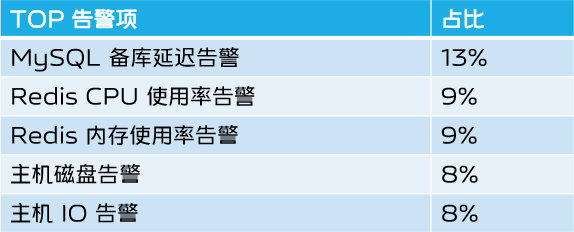
首先是故障消息,在一开始设计时,我们期望是可以支持接入各种故障消息,比如告警事件、巡检事件等,但是在实践中,我们还是优先针对 TOP 告警场景进行开发,因为故障消息中,绝大部分都是告警。而且据我们统计,TOP 5 的告警差不多占了所有告警的一半,优先针对 TOP 告警短期内能取得不错的效果。
3.2.2 规则库
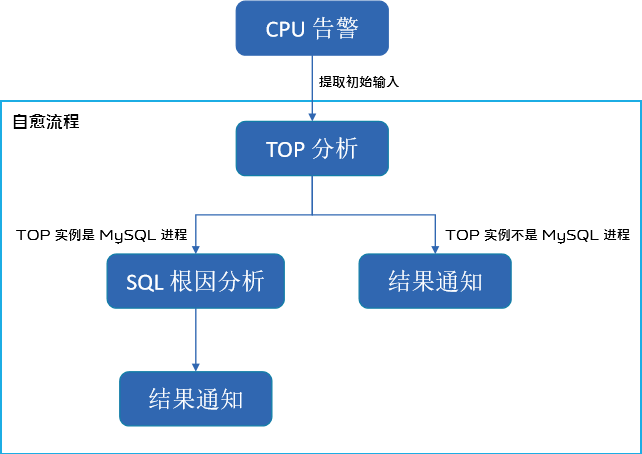
规则库保存了故障消息类型和自愈流程的绑定关系,自愈系统收到故障消息后,会根据这个消息类型去规则库中查找对应的自愈流程。这里我们实现了一个简单的流程编排功能,我们的想法是,先实现一些原子操作,再去将这些操作组合成一个流程,这样可以让操作具有的复用性,也更容易实现新的流程。
比如针对 CPU 告警,我们将 TOP 分析和 SQL 根因分析独立成两个原子操作,这样这两个操作也能复用在其他流程中。
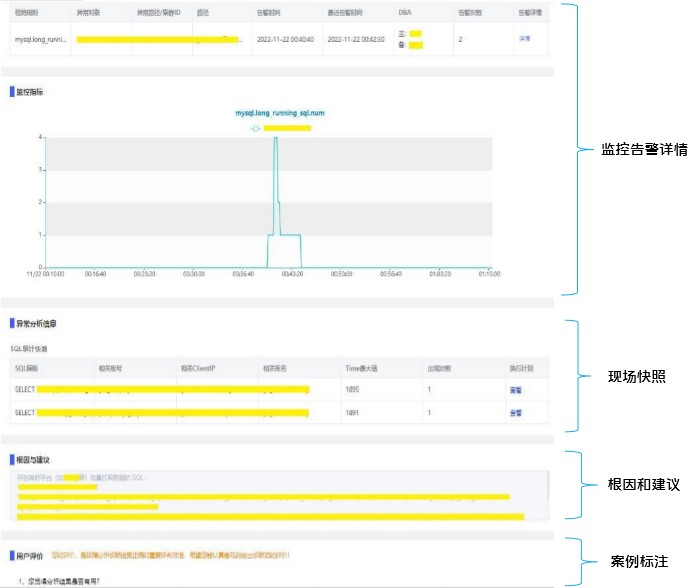
3.2.3 分析中心
在分析中心,用户可以看到监控告警详情、现场快照、分析的结果,还可以通过这里向我们反馈这个告警的原因、如何排查等信息,帮忙我们去进行迭代优化。这样自愈流程就不是一个黑盒了,也方便运维人员之间进行协作。
3.3.1 数据采集
故障自愈需要大量的数据支持,我们将数据分为三种类型。
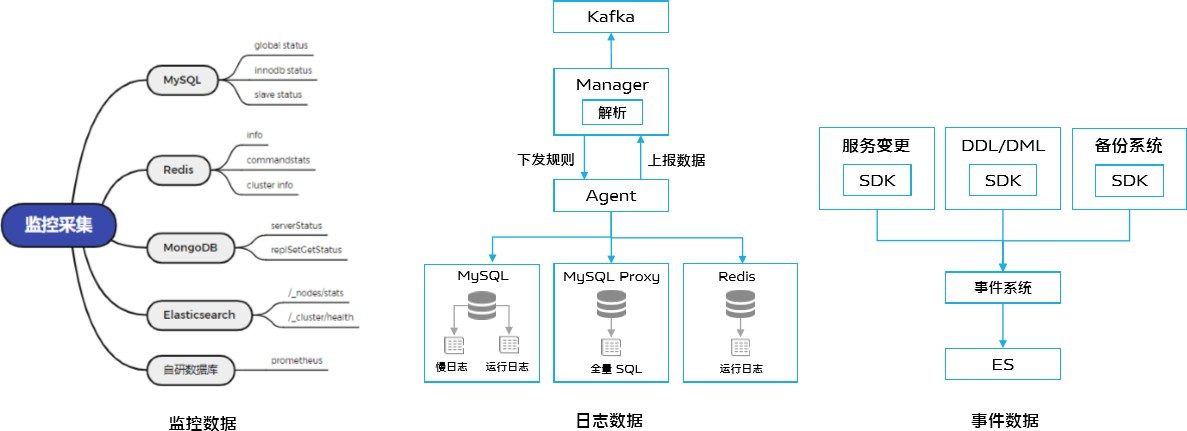
监控数据:我们这边的数据库种类比较多,每种数据库都有自己监控采集方式;
日志数据:采集流程中 Agent 先会向 Manager 查询自己需要采集哪些日志,然后以类似 tail 的方式一行一行地采集,再上报给 Manager,最后由 Manager 根据配置的正则表达式解析成结构化数据,写入 Kafka。这些日志包括慢日志、运行日志、全量日志等;
事件数据:我们开发了一个事件系统的 SDK,由各个服务使用这个 SDK,将自己服务的事件上报到事件系统。
3.3.2 数据计算
数据采集后,一些数据需要做计算处理。我们现在对数据做实时计算的场景比较少,下图是近期的全量 SQL 需求。
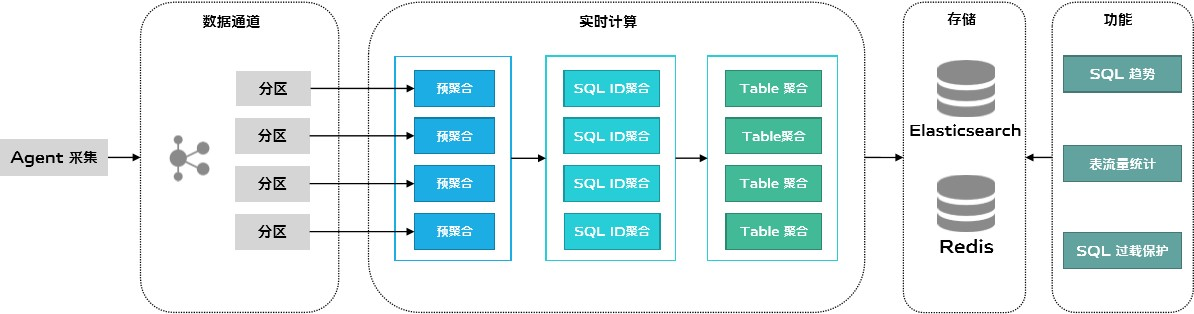
首先由 Agent 采集 SQL LOG 文件,进行批量上报,为了降低 Kafka 的带宽压力,上报的时候需要进行压缩。上报时指定实例地址作为 Kafka 分区 Key, 以保证同一个实例的数据能写到同一个 Kafka 分区,因此也就能保证在实时计算端,同一个实例的数据会落在同一个处理线程上,这样就能在接收到数据后,做一个预聚合,降低发往下游的网络流量。然后通过逐层聚合的方式,先聚合出每分钟每个 SQL_ID 的平均执行次数、平均响应时间等指标,再根据SQL_ID 的聚合数据,聚合出每分钟每个 Table 的平均访问次数指标。最后这份数据将用以支撑 SQL 趋势、表流量统计、SQL 过载保护等功能。
4.成果和案例
10+种故障场景分析和自愈能力:

使用6人月覆盖线上70%以上告警:

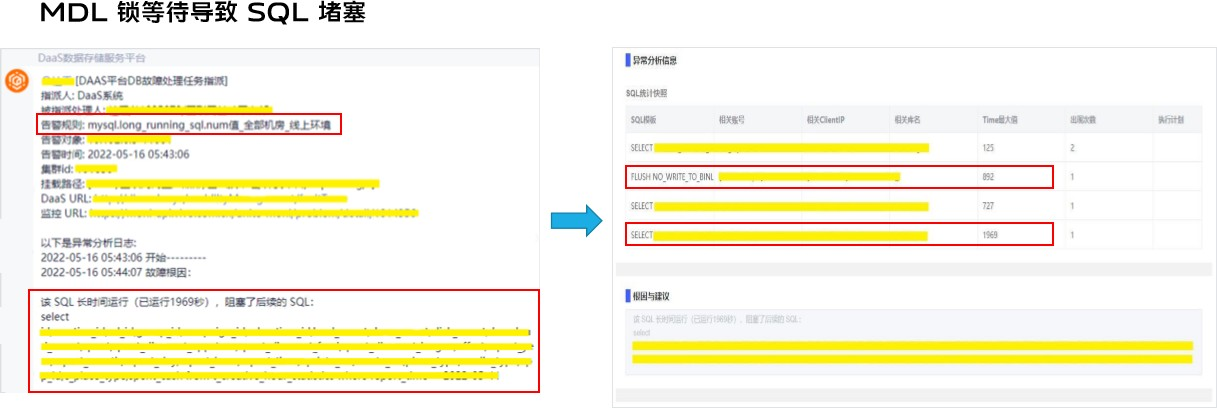
这里介绍一个案例:长时间执行的 SQL 数量达到阈值后,产生了告警,根据 SQL 根因分析得出,这是因为有一条长时间运行的 SQL 阻塞了其他 SQL,并把分析结果推送到故障处理群。从分析详情可以看出,这是一个 MDL 锁等待的经典场景,因为某条 SQL 长时间运行,备份进程执行 FLUSH 时请求 MDL 被阻塞,继而引发后续 SQL 请求 MDL 阻塞。
5.未来展望
展望未来,仍有许多事项需要逐步建设完善:
建立可观测、可跟踪的效果度量机制。目前可观测的指标只有告警覆盖率,而对于每次分析的有效性和正确率,现在还无法度量,因此需要建立一套效果度量机制;
仍有许多基础能力需要逐步建设完善,比如 SQL 优化建议、SQL 限流等功能;
基于规则的故障自愈方案容易碰到投入产出比降低、系统能力瓶颈等问题,因此需要借鉴业界方案,逐步使用 AI 技术,在各个功能场景进行尝试。
↓点这里可回看本期直播
http://z-mz.cn/5RSl3








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721