
一、事故背景
这次事故也是我们组里遇到的一次关于分页慢查询的典型例子,通过这篇文章,你可以很清晰地跟随我们还原事故现场,以及每一步遇到问题做出的调整和改动。
二、事故问题现场
16:00 收到同事反馈,融合系统分⻚查询可⽤率降低
16:05 查询接⼝UMP监控,发现接⼝TP99异常彪⾼
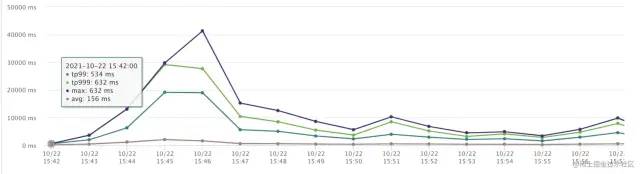
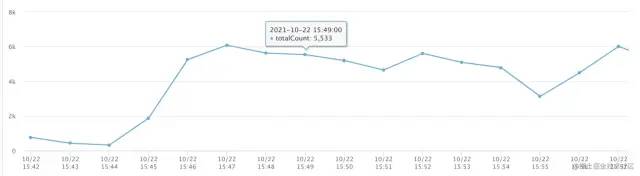
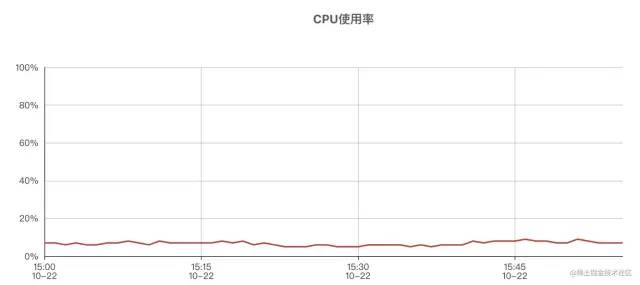
打开机器监控,发现⼏乎所有机器的TP999都异常的⾼,观察机器CPU监控,发现CPU使⽤率并不⾼
16:10 查看数据库监控,发现数据库CPU异常彪⾼,定位到是数据库问题,同时收到了⼤量的慢SQL邮件。

定位到这里,我们基本确定这个不是几分钟能解决的问题,于是我们分成两步去处理。
第一步:打开限流,防止更多的慢sql请求进行
第二步:分析慢sql,进行改造上线
查看慢SQL,⼤部分都是融合系统分⻚查询接⼝涉及到的SQL,同时由于上游系统在15:35左右对于该接⼝调⽤流量激增,和数据库CPU暴涨,接⼝TP999暴涨的时间吻合,推测是由于库存对于该接⼝的调⽤对于数据库造成了压⼒,导致接⼝耗时增加。但是该接⼝的调⽤量并不⾼,再次查看慢SQL,发现有⼤量已经遍历到⼏百⻚的慢SQL。推测是深分⻚的问题。
16:15 排查⽇志发现,⼤部分SQL都指向商家xxxx,查询发现其下有10W条数据(占⽤总数量的⼗分之⼀),MQ发现有⼤量重试,分⻚查询接⼝超时时间发现配置的是2S。推测是慢查询导致的⾼频次重试将数据库的性能拖垮。
16:25 观察代码后,确定了是深分页问题,确定下来了优化⽅案。为了避免库存修改接口,⾸先我们优化SQL将其优化为子查询的形式。即先通过pageNo和pageSize查询出ID,然后取出当中的最小值和最大值,然后使⽤范围查询去查询出来全表数据。由于线上持续对数据库造成压力,先让上游把MQ的消费暂停消费。
17:40 优化代码上线,上游重新打开MQ消费,但是由于消费积累的消息⽐较多,直接打开后,还是对融合数据库造成了压⼒。接⼝的TP99再次飙升,数据库CPU再次飙到100%。
18:00 复盘了下,决定不再优化旧接⼝,⽽是开发新接⼝,基于滚动ID进⾏分⻚查询。需要推动上游⼀起参与开发和联调。
22:20 新接⼝上线,重新放开MQ消费,上游积压了⼤量消息的情况下,新接⼝表现平稳,“问题解决”
三、问题原因和解决⽅法
问题SQL:
select * from table where org_code = xxxx limit 1000,100
以上⾯的SQL为例,MySQL的limit⼯作原理就是先读取前⾯1000条记录,然后抛弃前1000条,读后⾯100条想要的,所以⻚码越⼤,偏移量越⼤,性能就越差。
1)查询ID+基于ID查询
即先使⽤查询条件查询出来id,再通过id进⾏范围查询,也就是说我第⼀次优化的时候使⽤的⽅法
⾸先查询出来ID,以上⾯的SQL为例
select id from table where org_code = xxxx limit 1000,5
然后查询出来id后,使⽤id进⾏in查询,由于是直接基于主键的in查询,所以效率较⾼
select * from table where id in (1,2,3,4,5);
2)基于ID查询优化
由于在第⼀次查询已经查询出来了所有符合条件的ID了,可以使⽤范围查询来替代in查询,效率更⾼(in
查询需要和集合里面的元素进⾏⽐对,但是范围查询只需要⽐较最大和最小即可)
select * from table where org_code = xxxx and id >= 1 and id <= 5;
使用子查询
select a.id,a.dj_sku_id,a.jd_sku_id from table a join (select id fromjd_spu_sku where org_code = xxxx limit 1000,5) bon a.id = b.id;
使用子查询可以减少和数据库的IO交互,也是⼀种常⽤的解决深分页的⽅法。
3)使用滚动查询
每次接⼝都会返回查询出来的数据的最⼤的id(游标),下⼀次查询传⼊这个游标,服务端只需要根据这个游标,取出id⼤于这个游标的n个数据即可。n为每⻚展示条数。
select * from table where org_code = xxxx and id > 0 limit 10;
这种⽅式服务端实现起来⽐较简单且性能很好。缺点是需要客户端修改,且需要保证ID是自增有序且结果需要是按照ID排序的。
最终定下的是使用滚动查询的方法。
最终优化SQL上线后,表现平稳。第⼆周和库存⼀起重新优化了⾮多规格SKU的SQL。如下:
SELECT id,dj_org_code,dj_sku_id,jd_sku_id,yn FROM table whereorg_code = xxxx and id > 0 order by id asc limit 500
测试了没问题后上线。观察线上监控稳定。
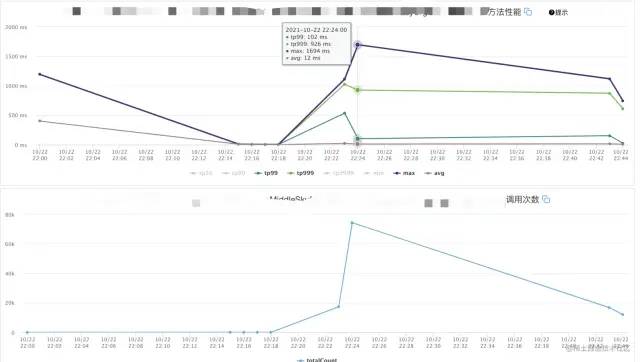
本以为高枕无忧的时候,⼀周之后,数据库再次出现了⼤量的慢查询,数据库CPU报警,观察接⼝监控:
可以看到在调用量并不⼤的前提下,接⼝的耗时达到了60S。联系运维同学帮忙排查,发现了大量的慢SQL:
SELECT id,dj_org_code,dj_sku_id,jd_sku_id,yn FROM table whereorg_code = xxxx and id > 0 order by id asc limit 500
可以看出来,这就是我们优化后的SQL。运维同学explain这条sql后发现,这条SQL⾛了主键索引,没有⾛我们以为应该要⾛的org_code的索引。
和运维初步沟通后得出结论,在某些情况下,主键索引的优先级是会⾼于普通索引的。
四、最终解决方案
因为我们使用了主键索引进⾏排序,且查询了不在索引树只在叶子节点中的字段。因此mysql认为主键索引更优,因为既可以排序,⼜不⽤回表,所以就使⽤主键索引最终导致了全表扫描。
最终使用了先查询ID(不查询叶子节点字段保证使⽤索引),在通过join,使用查询出来的ID来查询对应的数据的SQL:
select a.id AS id,a.dj_org_code AS djOrgCode,a.dj_sku_id ASdjSkuId,a.jd_sku_id AS jdSkuId,a.yn AS yn fromtable a join(SELECT id FROM table where org_code = xxxx and id > 0 orderby id asc limit 500) t on a.id=t.id;
再次explain了下,可以发现⾛了我们既定的索引:
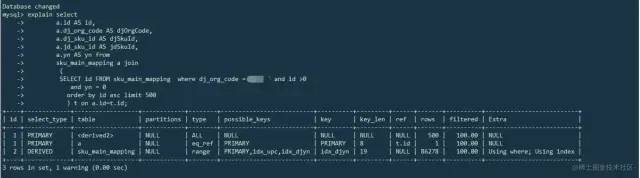
于是上线,解决问题。
上线稳定后,分析之前的问题SQL,执⾏下⾯两条语句,同样的SQL,不同的商家,MYSQL的执⾏结果也是不⼀样的。

查阅资料得知:
MYSQL会将limit的数量和where条件⾥查询出的数量进行比对,如果limit数量占比较小(例如某些商家的sku数⽬⽐较多),则会"优化"为主键索引,因为MYSQL此时认为⾛主键索引会减少⼀次索引树的查询,且可以在较短时间⾥⾯得到结果。(没有LIMIT不会⾛主键索引)
因此在where 索引A order by 主键索引 limit N的这种SQL,需要考虑MYSQL优化主键索引的情况。
除了上面最终上线后的优化SQL,也可以通过force index强制使⽤索引:
SELECT id,dj_org_code,dj_sku_id,jd_sku_id,yn FROM table forceindex(idx_upc) where org_code = xxxx and id > 0 order by id asc limit500
但是这种写死了索引名称的⽅式,如果以后修改了索引名,容易导致安全隐患。
五、问题总结
1)B端系统也需要考虑对自己系统的保护,接⼊限流等,防止异常流量或者异常调用把自己的系统调死。这次幸亏上游系统是通过MQ调⽤融合API的,可以暂停消费,如果是⽤API调⽤,且流量较⼤,持续让数据库处于⾼压状态,会影响到融合系统的整体稳定性。
2)针对可能出现的风险点绝不姑息。这次这个分页查询sku的接⼝,之前就看到过,但是当时觉得这个接⼝在数据量较少的情况下性能也还好,而且也有了商家维度的索引,就放过了,考虑后续优化。结果现在就爆出了问题。
3)针对SQL的优化,上线前要谨慎,而且需要同⼀条SQL,需要针对不同的边界情况(例如这次的多SKU的商家)进⾏反复测试,调整。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721