
本篇文章通过场景驱动的方式来深度剖析 Kafka 生产级容量评估方案如何分析,申请和实施。
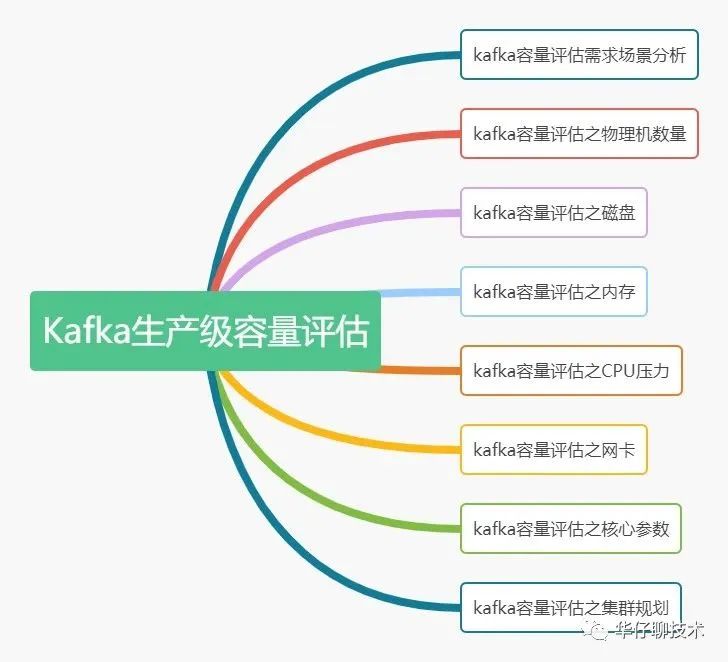
一、kafka容量评估需求场景分析
1、集群如何每天hold住10亿+请求
拿电商平台为例,kafka 集群每天需要承载10亿+请求流量数据,一天24小时,对于平台来说,晚上12点到凌晨8点这8个小时几乎没多少数据涌入的。这里我们使用「二八法则」来进行预估,也就是80%的数据(8亿)会在剩余的16个小时涌入,且8亿中的80%的数据(约6.4亿)会在这16个小时的20%时间 (约3小时)涌入。
通过上面的场景分析,可以得出如下:
QPS计算公式 = 640000000 ÷ (3 * 60 * 60) = 6万,也就是说高峰期集群需要扛住每秒6万的并发请求。
假设每条数据平均按20kb(生产端有数据汇总)来算, 那就是 1000000000 * 20kb = 18T,一般情况下我们都会设置3个副本,即54T,另外 kafka 数据是有保留时间周期的, 一般情况是保留最近3天的数据,即 54T * 3 = 162T。
2、场景总结
要搞定10亿+请求,高峰期要支撑6万QPS,需要大约162T的存储空间。
二、kafka容量评估之物理机数量
1、物理机 OR 虚拟机
一般对于Kafka,Mysql,Hadoop 等集群自建的时候,都会使用物理机来进行搭建,性能和稳定性相对虚拟机要强很多。
2、物理机数量计算
在第一步中我们分析得出系统高峰期的时候要支撑6万QPS,如果公司资金和资源充足的情况下,我们一般会让高峰期的QPS控制在集群总承载QPS能力的30%左右,这样的话可以得出集群能承载的总QPS能力约为20万左右,这样系统才会是安全的。
3、场景总结
根据经验可以得出每台物理机支撑4万QPS是没有问题的,从QPS角度分析,我们要支撑10亿+请求,大约需要5台物理机,考虑到消费者请求,需要增加约1.5倍机器,即7台物理机。
三、kafka容量评估之磁盘
1、机械硬盘 OR 固态硬盘SSD
两者主要区别如下:
SSD就是固态硬盘,它的优点是速度快,日常的读写比机械硬盘快几十倍上百倍。缺点是单位成本高,不适合做大容量存储。
HDD就是机械硬盘,它的优点是单位成本低,适合做大容量存储,但速度远不如SSD。
首先SSD硬盘性能好,主要是指的随机读写能力性能好,非常适合Mysql这样的集群,而SSD的顺序读写性能跟机械硬盘的性能是差不多的。
Kafka 写磁盘是顺序追加写的,所以对于 kafka 集群来说,我们使用普通机械硬盘就可以了。
2、每台服务器需要多少块硬盘
根据第一二步骤计算结果,我们需要7台物理机,一共需要存储162T数据,大约每台机器需要存储23T数据,根据以往经验一般服务器配置11块硬盘,这样每块硬盘大约存储2T的数据就可以了,另外为了服务器性能和稳定性,我们一般要保留一部分空间,保守按每块硬盘最大能存储3T数据。
3、场景总结
要搞定10亿+请求,需要7台物理机,使用普通机械硬盘进行存储,每台服务器11块硬盘,每块硬盘存储2T数据。
四、kafka容量评估之内存
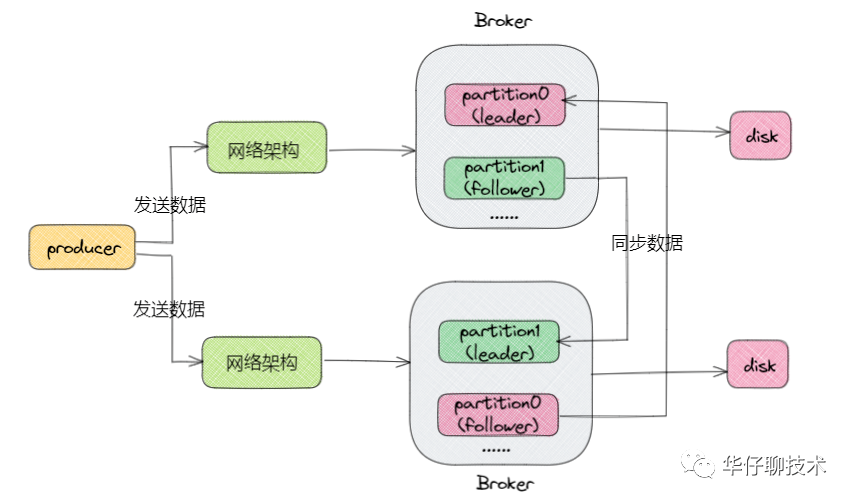
1、Kafka 写磁盘流程及内存分析
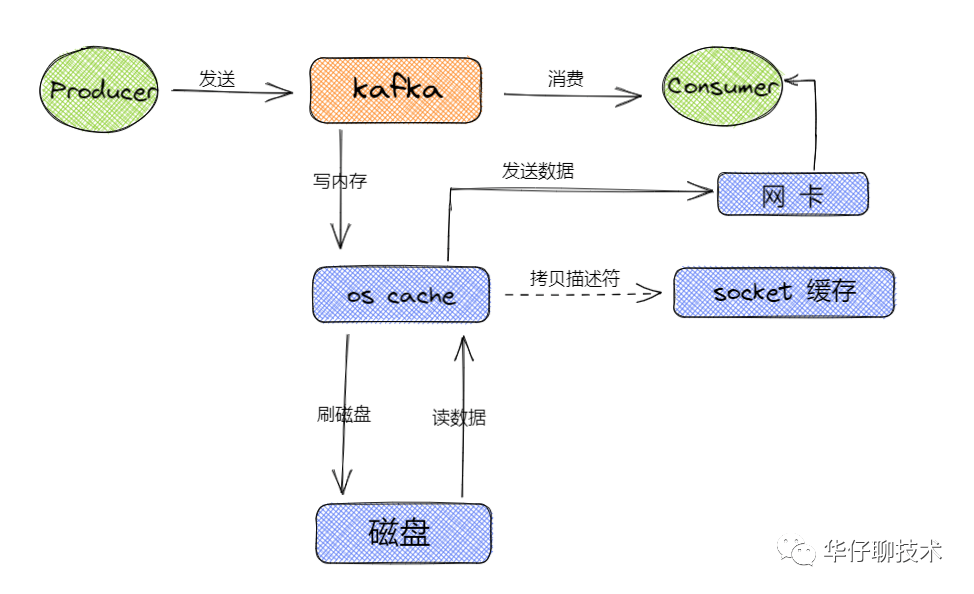
从上图可以得出 Kafka 读写数据的流程主要都是基于os cache,所以基本上 Kafka 都是基于内存来进行数据流转的,这样的话要分配尽可能多的内存资源给os cache。
kafka的核心源码基本都是用 scala 和 java (客户端)写的,底层都是基于 JVM 来运行的,所以要分配一定的内存给 JVM 以保证服务的稳定性。对于 Kafka 的设计,并没有把很多的数据结构存储到 JVM 中,所以根据经验,给 JVM 分配6~10G就足够了。
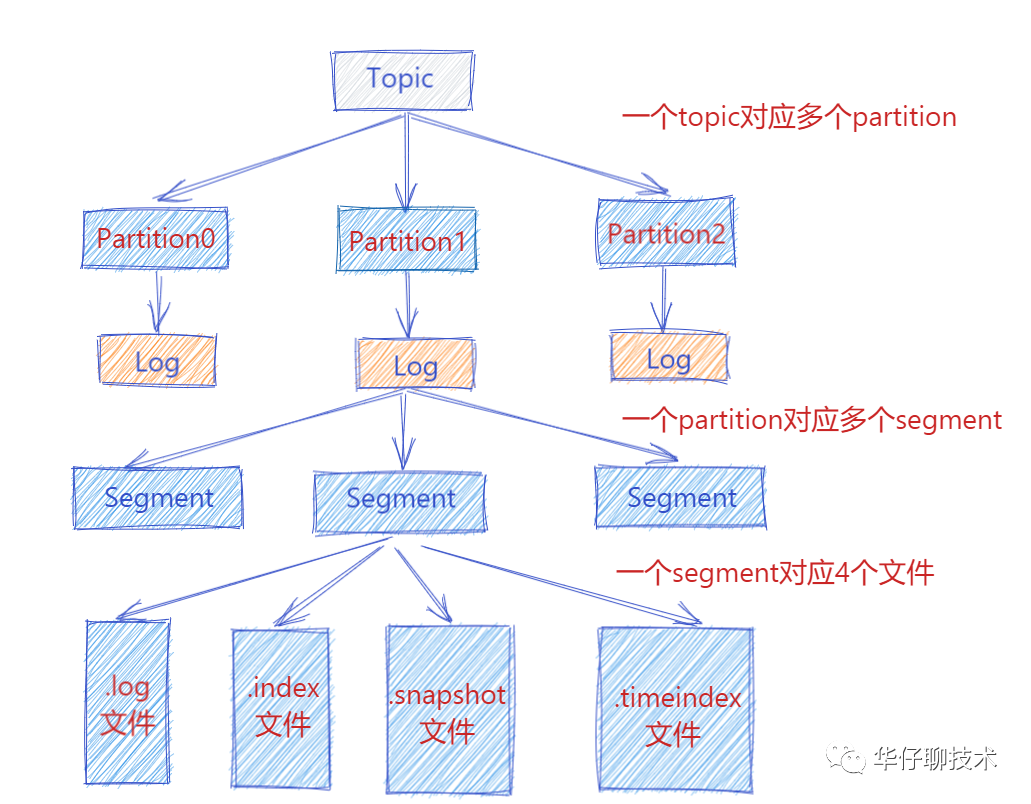
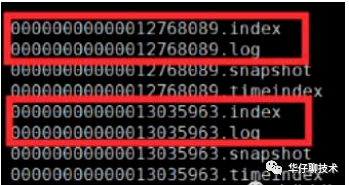
从上图可以看出一个 Topic 会对于多个 partition,一个 partition 会对应多个 segment ,一个 segment 会对应磁盘上4个log文件。假设我们这个平台总共100个 Topic ,那么总共有 100 Topic * 5 partition * 3 副本 = 1500 partition 。对于 partition 来说实际上就是物理机上一个文件目录, .log就是存储数据文件的,默认情况下一个.log日志文件大小为1G。
如果要保证这1500个 partition 的最新的 .log 文件的数据都在内存中,这样性能当然是最好的,需要 1500 * 1G = 1500 G内存,但是我们没有必要所有的数据都驻留到内存中,我们只保证25%左右的数据在内存中就可以了,这样大概需要 1500 * 250M = 1500 * 0.25G = 375G内存,通过第二步分析结果,我们总共需要7台物理机,这样的话每台服务器只需要约54G内存,外加上面分析的JVM的10G,总共需要64G内存。还要保留一部分内存给操作系统使用,故我们选择128G内存的服务器是非常够用了。
2、场景总结
要搞定10亿+请求,需要7台物理机,每台物理机内存选择128G内存为主,这样内存会比较充裕。
五、kafka容量评估之CPU压力
1、CPU Core分析
我们评估需要多少个 CPU Core,主要是看 Kafka 进程里会有多少个线程,线程主要是依托多核CPU来执行的,如果线程特别多,但是 CPU核很少,就会导致CPU负载很高,会导致整体工作线程执行的效率不高,性能也不会好。所以我们要保证CPU Core的充足,来保障系统的稳定性和性能最优。
2、Kafka 网络架构及线程数计算
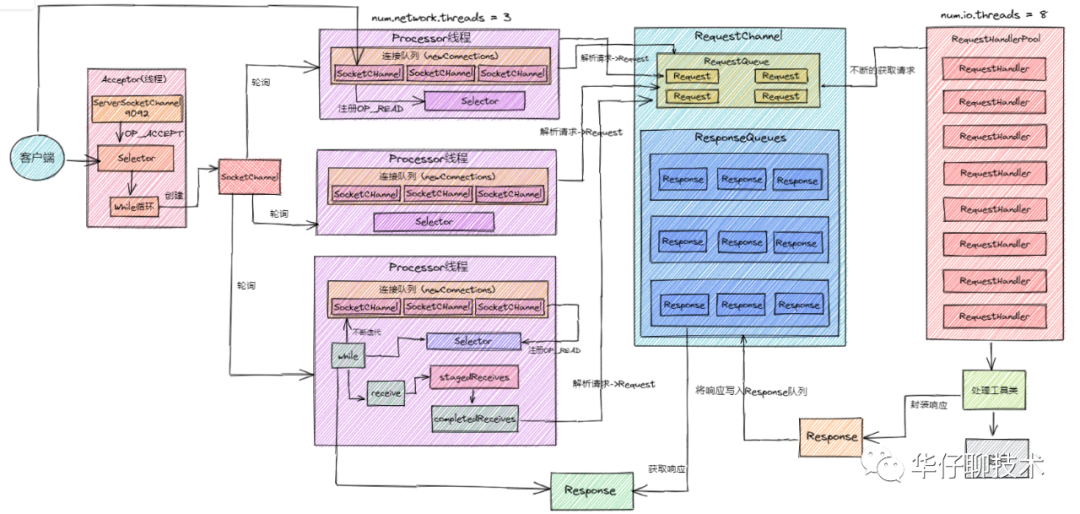
我们评估下 Kafka 服务器启动后会有多少线程在跑,其实这部分内容跟kafka超高并发网络架构密切相关,上图是Kafka 超高并发网络架构图,从图中我们可以分析得出:
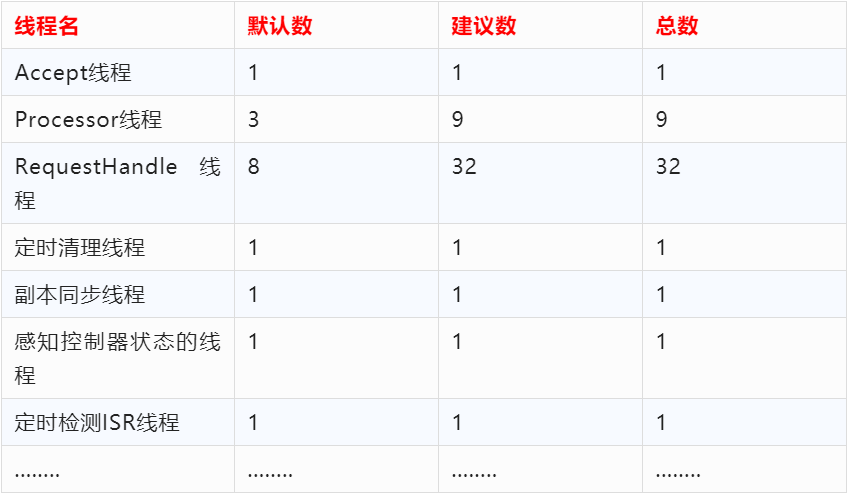
除了上图所列的还有其他一些线程,所以估算下来,一个 kafka 服务启动后,会有100多个线程在跑。

2、场景总结
要搞定10亿+请求,需要7台物理机,每台物理机内存选择128G内存为主,需要16个cpu core(32个性能更好)。
六、kafka容量评估之网卡
1、网卡对比分析

通过上图分析可以得出千兆网卡和万兆网卡的区别最大之处在于网口的传输速率的不同,千兆网卡的传输速率是1000Mbps,万兆网卡的则是10Gbps万兆网卡是千兆网卡传输速率的10倍。性能上讲,万兆网卡的性能肯定比千兆网卡要好。万兆网卡现在主流的是10G的,发展趋势正逐步面向40G、100G网卡。但还是要根据使用环境和预算来选择投入,毕竟千兆网卡和万兆网卡的性价比区间还是挺大的。
2、网卡选择分析
根据第一二步分析结果,高峰期的时候,每秒会有大约6万请求涌入,即每台机器约1万请求涌入(60000 / 7),每秒要接收的数据大小为: 10000 * 20 kb = 184 M/s,外加上数据副本的同步网络请求,总共需要 184 * 3 = 552 M/s。
一般情况下,网卡带宽是不会达到上限的,对于千兆网卡,我们能用的基本在700M左右,通过上面计算结果,千兆网卡基本可以满足,万兆网卡更好。
3、场景总结
要搞定10亿+请求,需要7台物理机,每台物理机内存选择128G内存为主,需要16个cpu core(32个性能更好),千兆网卡基本可以满足,万兆网卡更好。
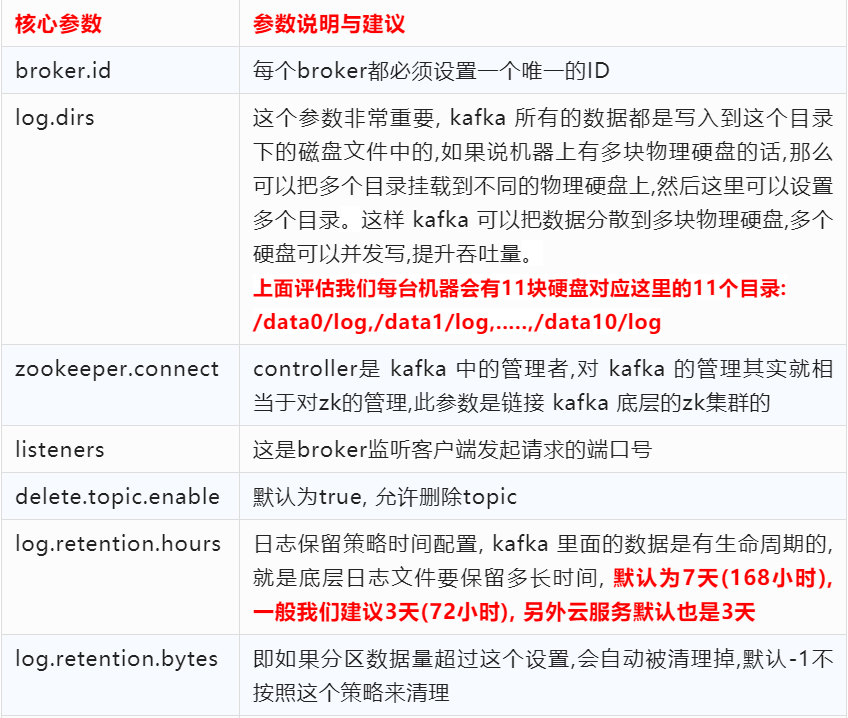
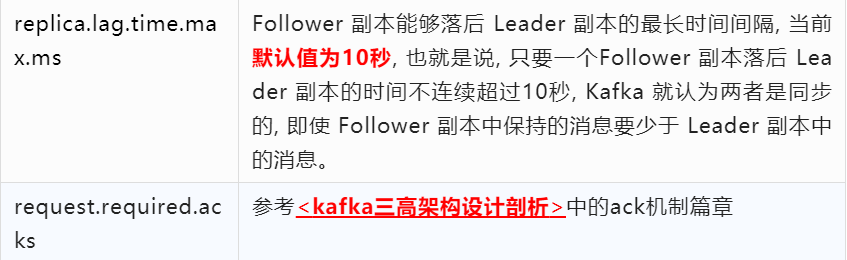
7、kafka容量评估之核心参数

8、kafka容量评估之集群规划
1、集群部署规划
这里我采用五台服务器来构建 Kafka 集群,集群依赖 ZooKeeper,所以在部署 Kafka 之前,需要部署好 ZooKeeper 集群。这里我将 Kafka 和 ZooKeeper 部署在了一起,Kafka 集群节点操作系统仍然采用 Centos 7.7 版本,各个主机角色和软件版本如下表所示:
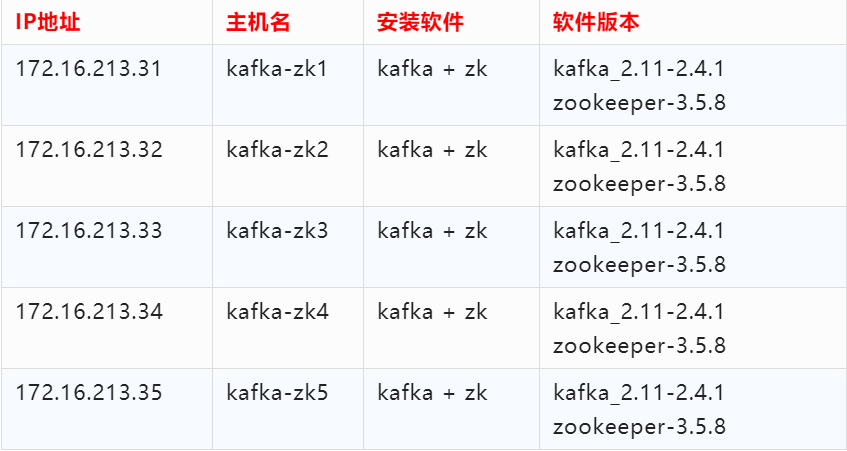
这里需要注意:Kafka 和 ZooKeeper 的版本,默认 Kafka2.11 版本自带的 ZooKeeper 依赖 jar 包版本为 3.5.7,因此 ZooKeeper 的版本至少在 3.5.7 及以上。
2、下载与安装
Kafka 需要安装 Java 运行环境,你可以点击Kafka官网
(https://kafka.apache.org/downloads)获取 Kafka 安装包,推荐的版本是 kafka_2.11-2.4.1.tgz。将下载下来的安装包直接解压到一个路径下即可完成 Kafka 的安装,这里统一将 Kafka 安装到 /usr/local 目录下,我以在 kafka-zk1 主机为例,基本操作过程如下:
[][]
这里我创建了一个 Kafka 用户,用来管理和维护 Kafka 集群,后面所有对 Kafka 的操作都通过此用户来完成,执行如下操作进行创建用户和授权:
[][]
在 kafka-zk1 节点安装完成 Kafka 后,先进行配置 Kafka,等 Kafka 配置完成,再统一打包复制到其他两个节点上。
broker.id=1listeners=PLAINTEXT://172.16.213.31:9092log.dirs=/usr/local/kafka/logsnum.partitions=6log.retention.hours=72log.segment.bytes=1073741824zookeeper.connect=172.16.213.31:2181,172.16.213.32:2181,172.16.213.33:2181auto.create.topics.enable=truedelete.topic.enable=truenum.network.threads=9num.io.threads=32message.max.bytes=10485760log.flush.interval.message=10000log.flush.interval.ms=1000replica.lag.time.max.ms=10
Kafka 配置文件修改完成后,接着打包 Kafka 安装程序,将程序复制到其他4个节点,然后进行解压即可。注意,在其他4个节点上,broker.id 务必要修改,Kafka 集群中 broker.id 不能有相同的(唯一的)。
3、启动集群
五个节点的 Kafka 配置完成后,就可以启动了,但在启动 Kafka 集群前,需要确保 ZooKeeper 集群已经正常启动。接着,依次在 Kafka 各个节点上执行如下命令即可:
[][][]21840 Kafka15593 Jps15789 QuorumPeerMain
这里将 Kafka 放到后台(deamon)运行,启动后,会在启动 Kafka 的当前目录下生成一个 nohup.out 文件,可通过此文件查看 Kafka 的启动和运行状态。通过 jps 指令,可以看到有个 Kafka 标识,这是 Kafka 进程成功启动的标志。
九、总结
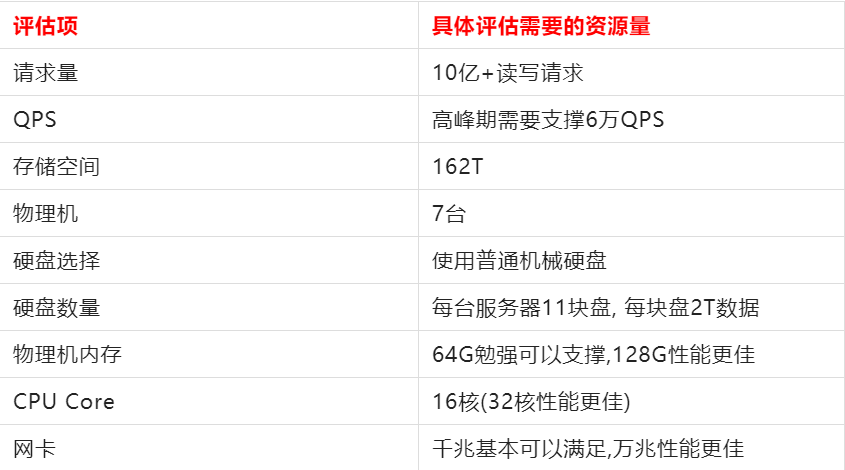
整个场景总结:
要搞定10亿+请求,经过上面深度剖析评估后需要以下资源:
作者丨王江华
来源丨公众号:华仔聊技术(ID:gh_97b8de4b5b34)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721